Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aprenda a crear un modelo de detección de objetos con ML.NET Model Builder y Azure Machine Learning para detectar y localizar señales de detención en las imágenes.
En este tutorial aprenderá a:
- Preparar y entender los datos
- Crear un archivo de configuración Model Builder
- Elegir el escenario
- Elegir el entorno de entrenamiento
- Carga de los datos
- Entrenar el modelo
- Evaluar el modelo
- Usar el modelo para las predicciones
Prerrequisitos
Para obtener una lista de los requisitos previos e instrucciones de instalación, visite la Guía de instalación del Generador de modelos.
Información general sobre la detección de objetos con Model Builder
La detección de objetos es un problema de visión informática. Si bien está estrechamente relacionada con la clasificación de imágenes, la detección de objetos realiza la clasificación de imágenes a una escala más granular. La detección de objetos ubica y categoriza entidades dentro de las imágenes. Los modelos de detección de objetos se entrenan normalmente mediante el aprendizaje profundo y las redes neuronales. Consulte Aprendizaje profundo frente a aprendizaje automático para obtener más información.
Use la detección de objetos cuando las imágenes contengan varios objetos de tipos diferentes.

Entre algunos casos de uso para la detección de objetos se incluyen:
- Automóviles sin conductor
- Robótica
- Detección facial
- Seguridad en el lugar de trabajo
- Recuento de objetos
- Reconocimiento de actividades
En este ejemplo se crea una aplicación de consola en C# de .NET Core que detecta señales de detención en las imágenes mediante un modelo de aprendizaje automático creado con Model Builder. Puede encontrar el código fuente para este tutorial en el repositorio dotnet/machinelearning-samples de GitHub.
Preparar y entender los datos
El conjunto de datos de señales de detención consta de 50 imágenes descargadas de Unsplash, cada una de las cuales contiene al menos una señal de detención.
Creación de un proyecto de VoTT
Descargue el conjunto de datos de 50 imágenes de señales de detención y descomprímalo.
Descargue VoTT (Visual Object Tagging Tool).
Abra VoTT y seleccione New Project (Nuevo proyecto).
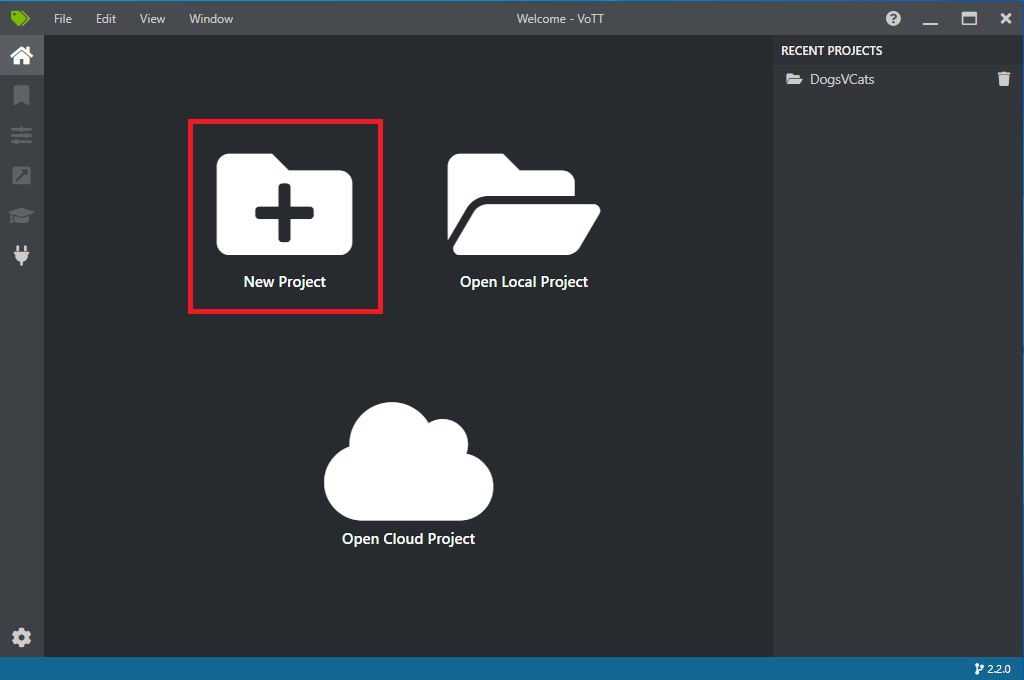
En Project Settings (Configuración del proyecto), cambie el nombre para mostrar (Display Name) a "StopSignObjDetection".
Cambie el valor de Security Token (Token de seguridad) a Generate New Security Token (Generar un token de seguridad).
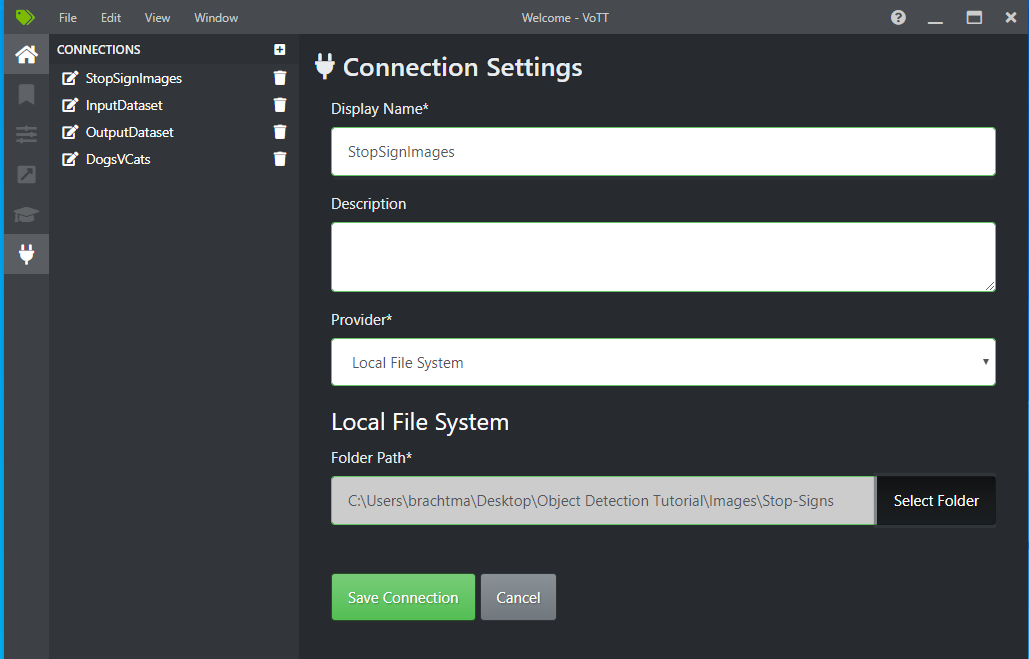
Junto a Source Connection (Conexión de origen), seleccione Add Connection (Agregar conexión).
En Connection Settings (Configuración de conexión), cambie el nombre para mostrar (Display Name) de la conexión de origen a "StopSignImages" y seleccione Local File System (Sistema de archivos local) en Provider (Proveedor). En la Folder Path (Ruta de la carpeta), seleccione la carpeta Stop-Signs que contiene las 50 imágenes de entrenamiento y, a continuación, seleccione Save Connection (Guardar conexión).
En Project Settings (Configuración del proyecto), cambie el valor de Source Connection (Conexión de origen) a StopSignImages (la conexión que acaba de crear).
Cambie también el valor de Target Connection (Conexión de destino) a StopSignImages. La configuración del proyecto debería tener ahora un aspecto similar al de esta captura de pantalla:
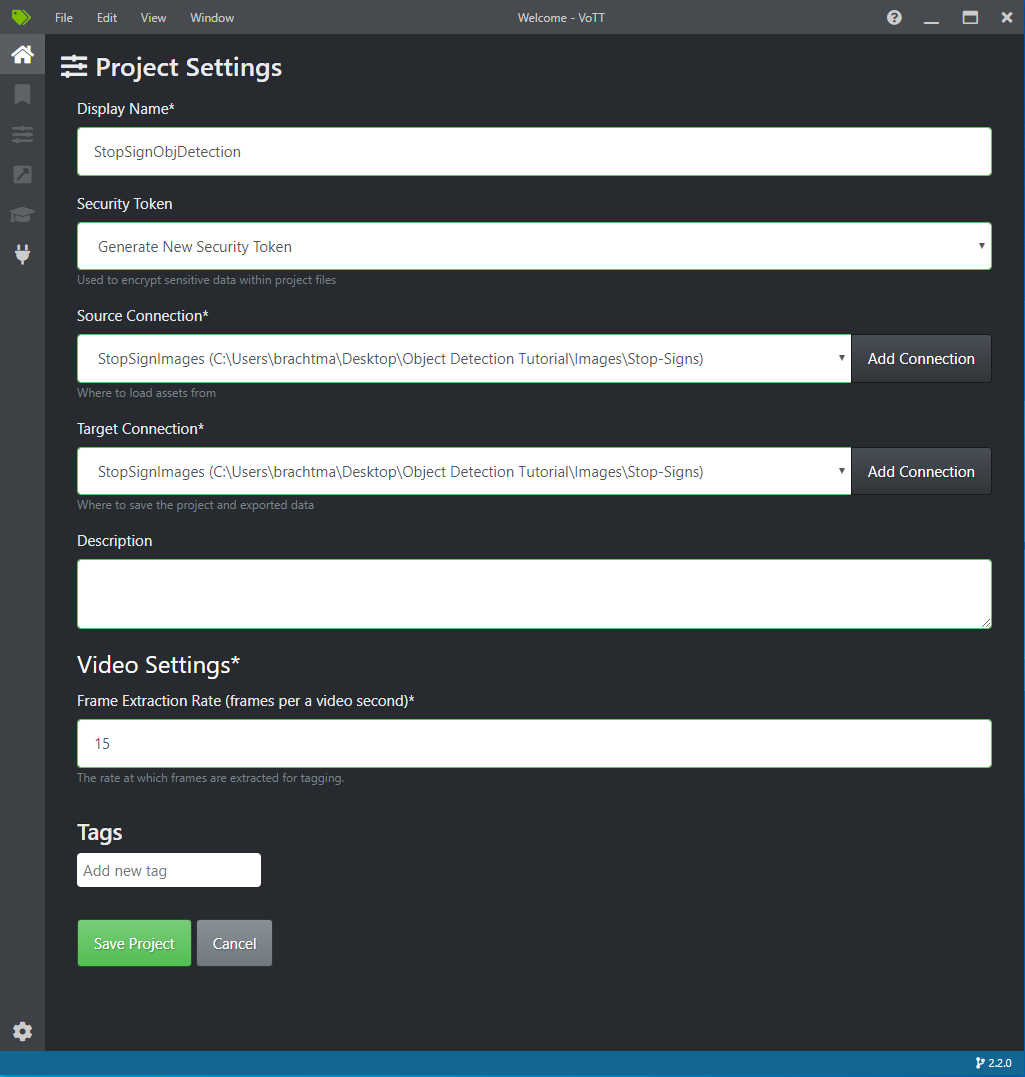
Seleccione Save Project (Guardar proyecto).
Incorporación de etiquetas y etiquetado de imágenes
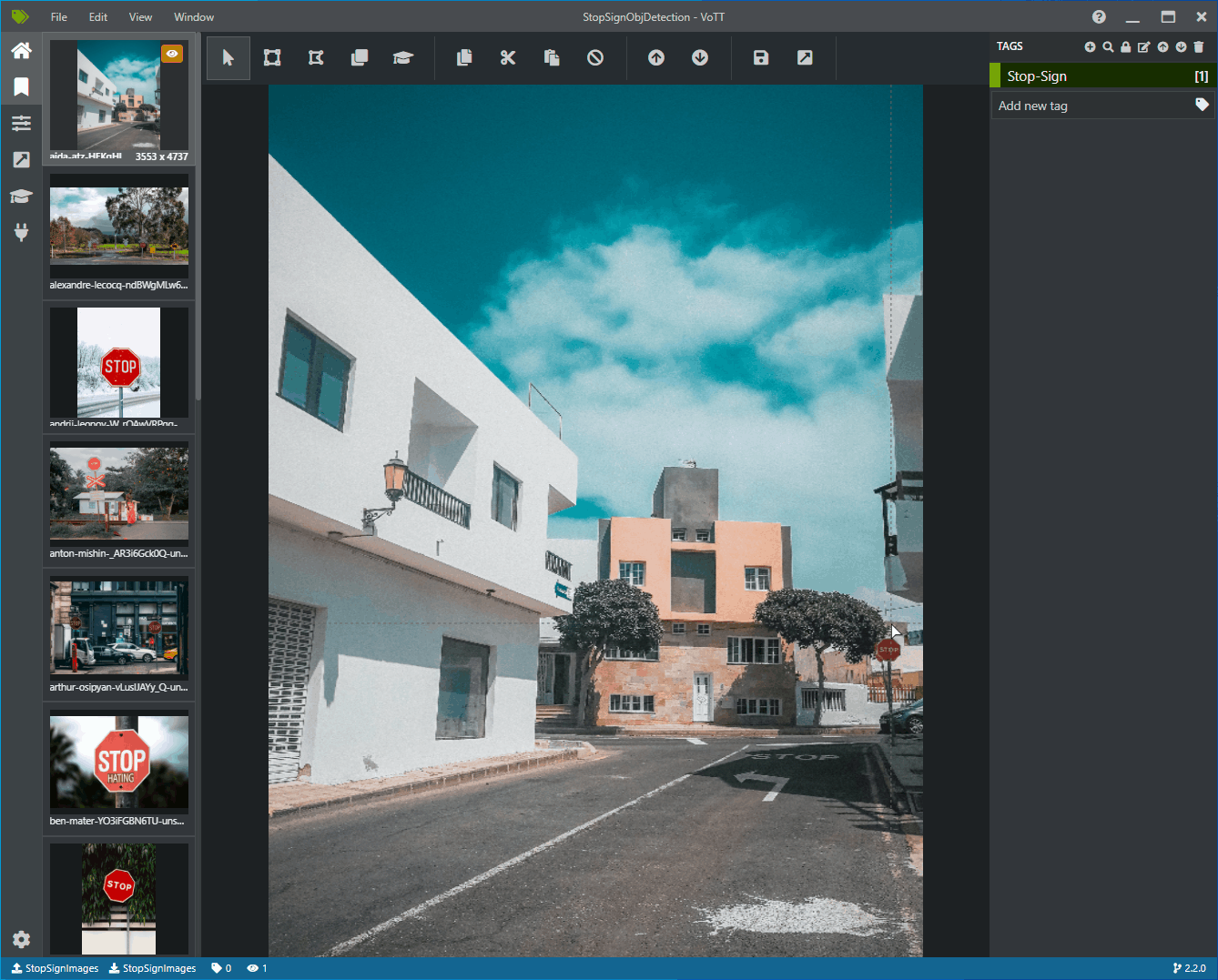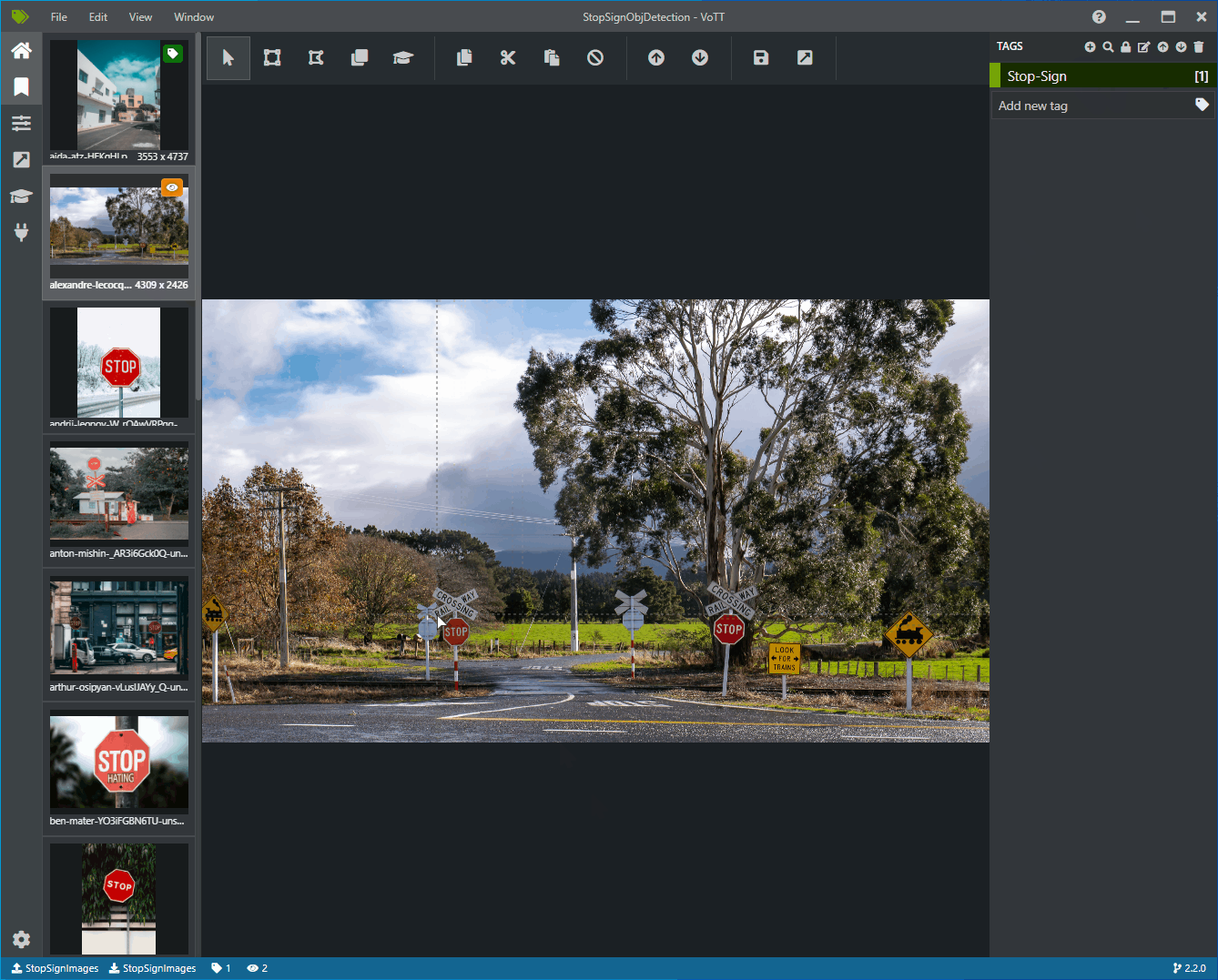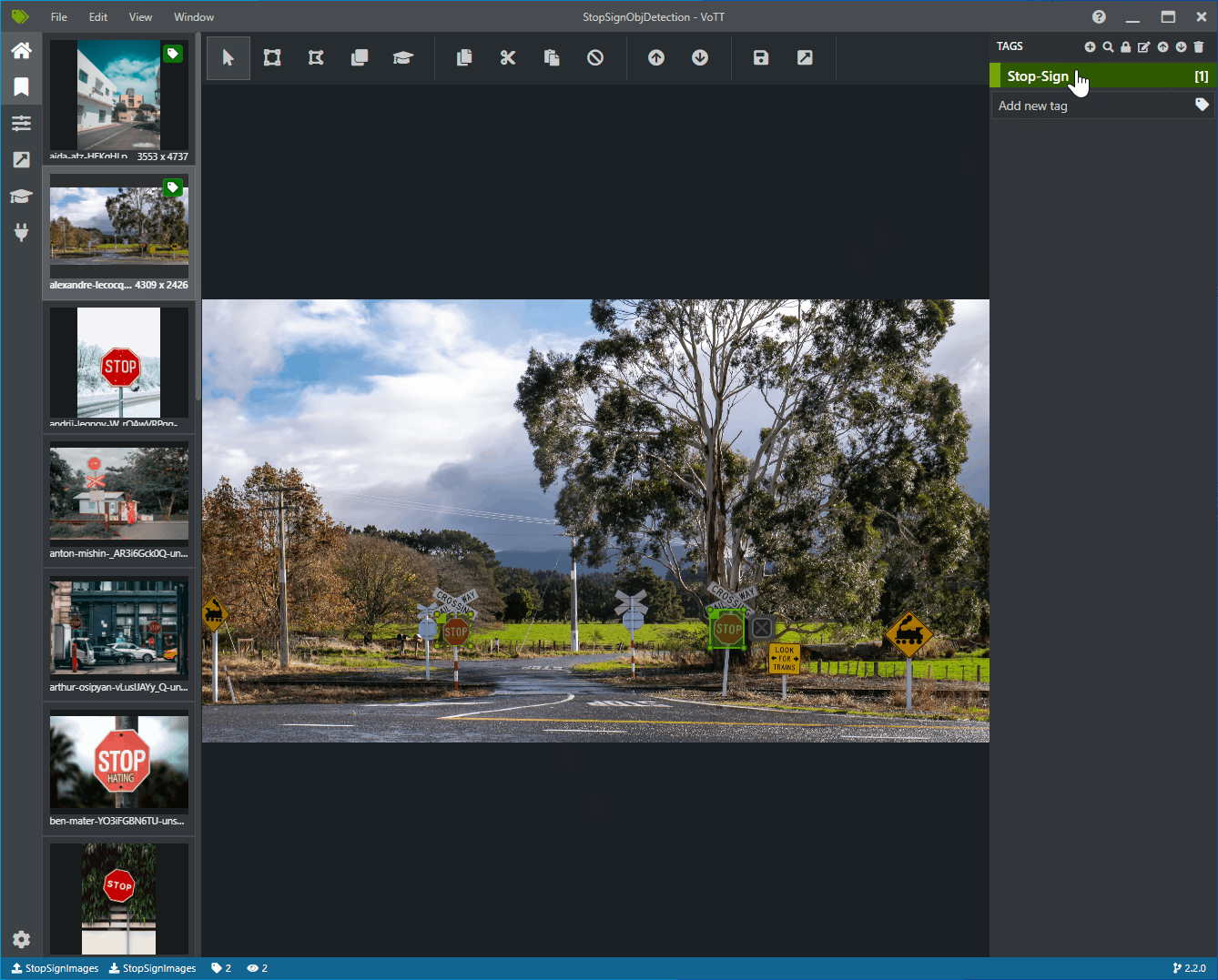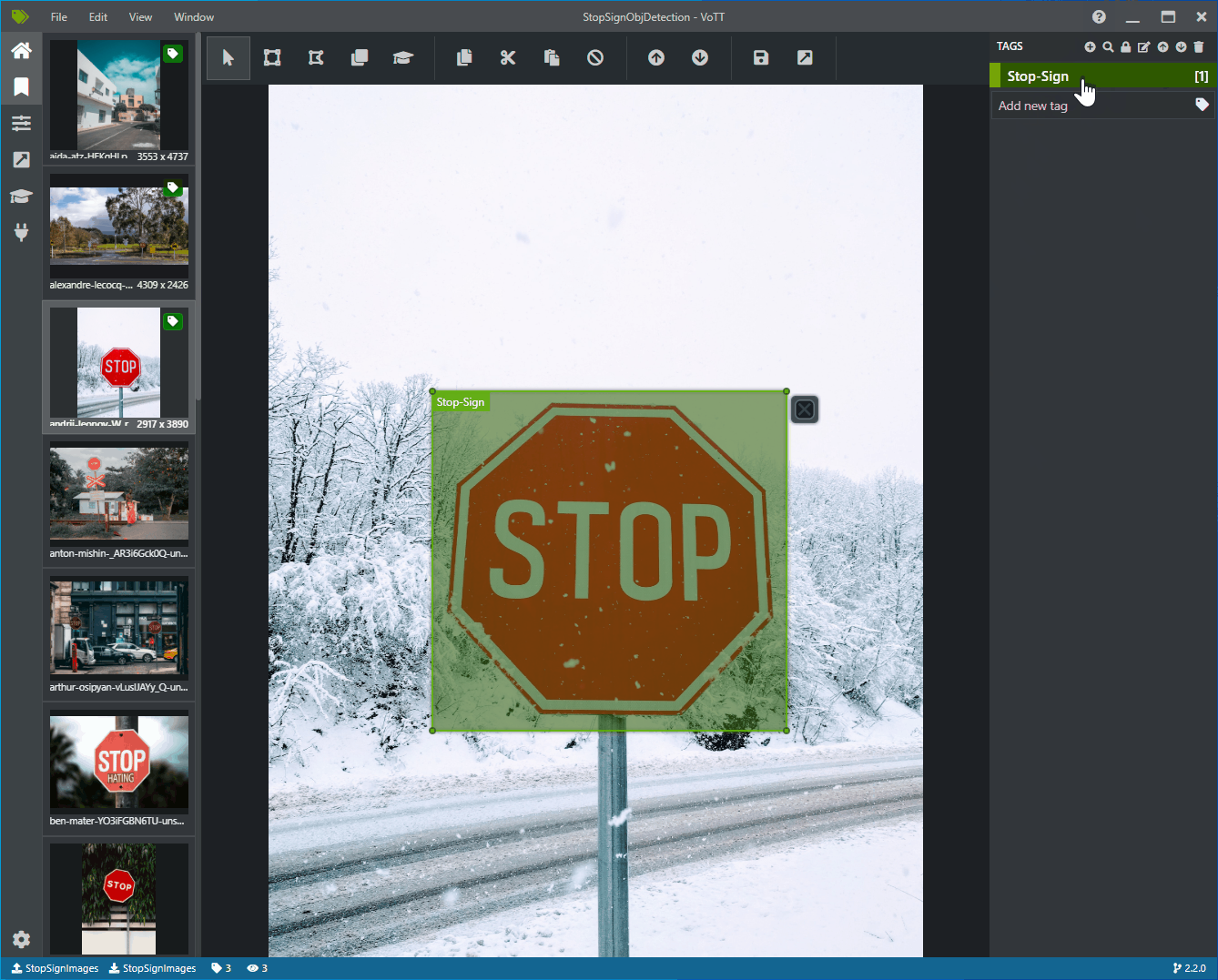
Ahora debería ver una ventana con imágenes de vista previa de todas las imágenes de entrenamiento a la izquierda, una vista previa de la imagen seleccionada en el centro y una columna Tags (Etiquetas) a la derecha. Esta pantalla es el editor de etiquetas.
Seleccione el primer icono (con forma de más) en la barra de herramientas Tags (Etiquetas) para agregar una nueva etiqueta.

Asigne el nombre "STOP-Sign" a la etiqueta y presione Entrar en el teclado.

Haga clic y arrastre para dibujar un rectángulo alrededor de cada señal de detención de la imagen. Si el cursor no permite dibujar un rectángulo, intente seleccionar la herramienta Draw Rectangle (Dibujar rectángulo) en la barra de herramientas de la parte superior o use el método abreviado de teclado R.
Después de dibujar el rectángulo, seleccione la etiqueta Stop-Sign que creó en los pasos anteriores para agregar la etiqueta al rectángulo de selección.
Haga clic en la imagen de vista previa en la imagen siguiente del conjunto de datos y repita este proceso.
Siga repitiendo los pasos 3 y 4 en cada señal de detención y en cada imagen.
Exportación del archivo JSON de VoTT
Una vez que haya etiquetado todas las imágenes de entrenamiento, puede exportar el archivo que usará Model Builder para el entrenamiento.
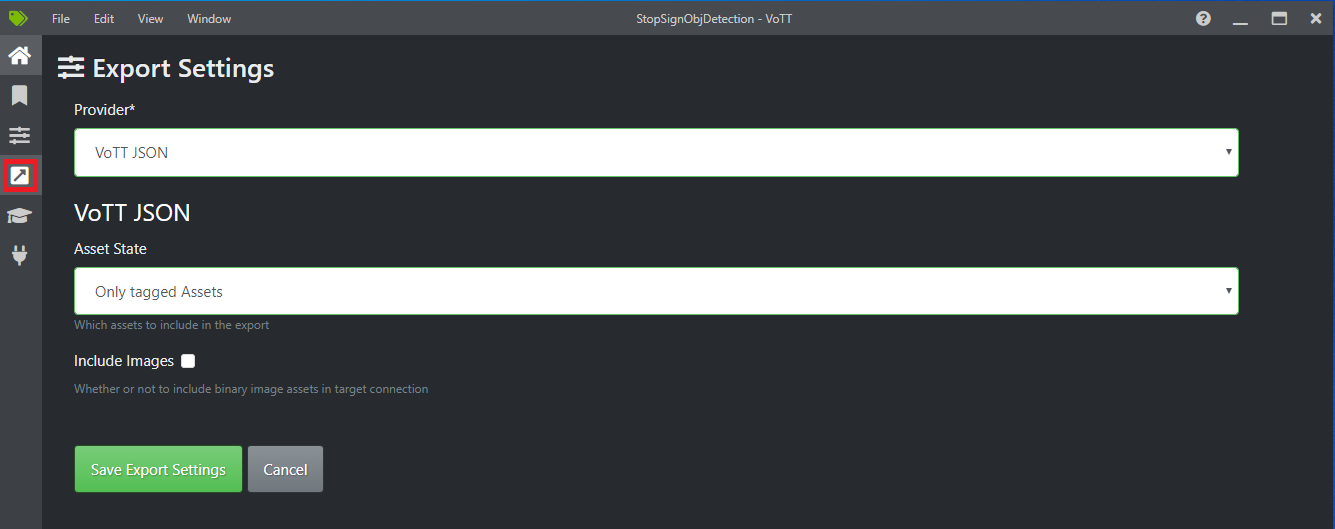
Seleccione el cuarto icono en la barra de herramientas izquierda (el que tiene la flecha diagonal en un cuadro) para ir a Export Settings (Configuración de exportación).
Deje el valor de Provider (Proveedor) como VoTT JSON (JSON de VoTT).
Cambie Asset State (Estado del recurso) a Only tagged Assets (Solo los recursos etiquetados).
Desactive la casilla Include Images (Incluir imágenes). Si incluye las imágenes, las imágenes de entrenamiento se copiarán en la carpeta de exportación que se genera, lo cual no es necesario.
Seleccione Save Export Settings (Guardar configuración de exportación).
Vuelva al editor de etiquetas (el segundo icono de la barra de herramientas izquierda con forma de cinta). En la barra de herramientas superior, seleccione el icono de Export Project (Exportar proyecto) (el último icono con forma de flecha en un cuadro) o use el método abreviado de teclado Ctrl+E.

Esta exportación creará una nueva carpeta denominada vott-json-export en la carpeta Stop-Sign-Images y generará un archivo JSON denominado StopSignObjDetection-export en esa nueva carpeta. Usará este archivo JSON en los pasos siguientes para entrenar un modelo de detección de objetos en Model Builder.
Creación de una aplicación de consola
En Visual Studio, cree una aplicación de consola en C# de .Net Core denominada StopSignDetection.
Creación de un archivo mbconfig
- En el Explorador de soluciones, haga clic con el botón derecho en el proyecto StopSignDetection y seleccione Agregar>Modelo de Machine Learning... para abrir la interfaz de usuario de Model Builder.
- En el cuadro de diálogo, asigne el nombre StopSignDetection al proyecto de Model Builder y haga clic en Agregar.
Elección de un escenario
En este ejemplo, el escenario es la detección de objetos. En el paso Escenario de Model Builder, seleccione el escenario Detección de objetos.
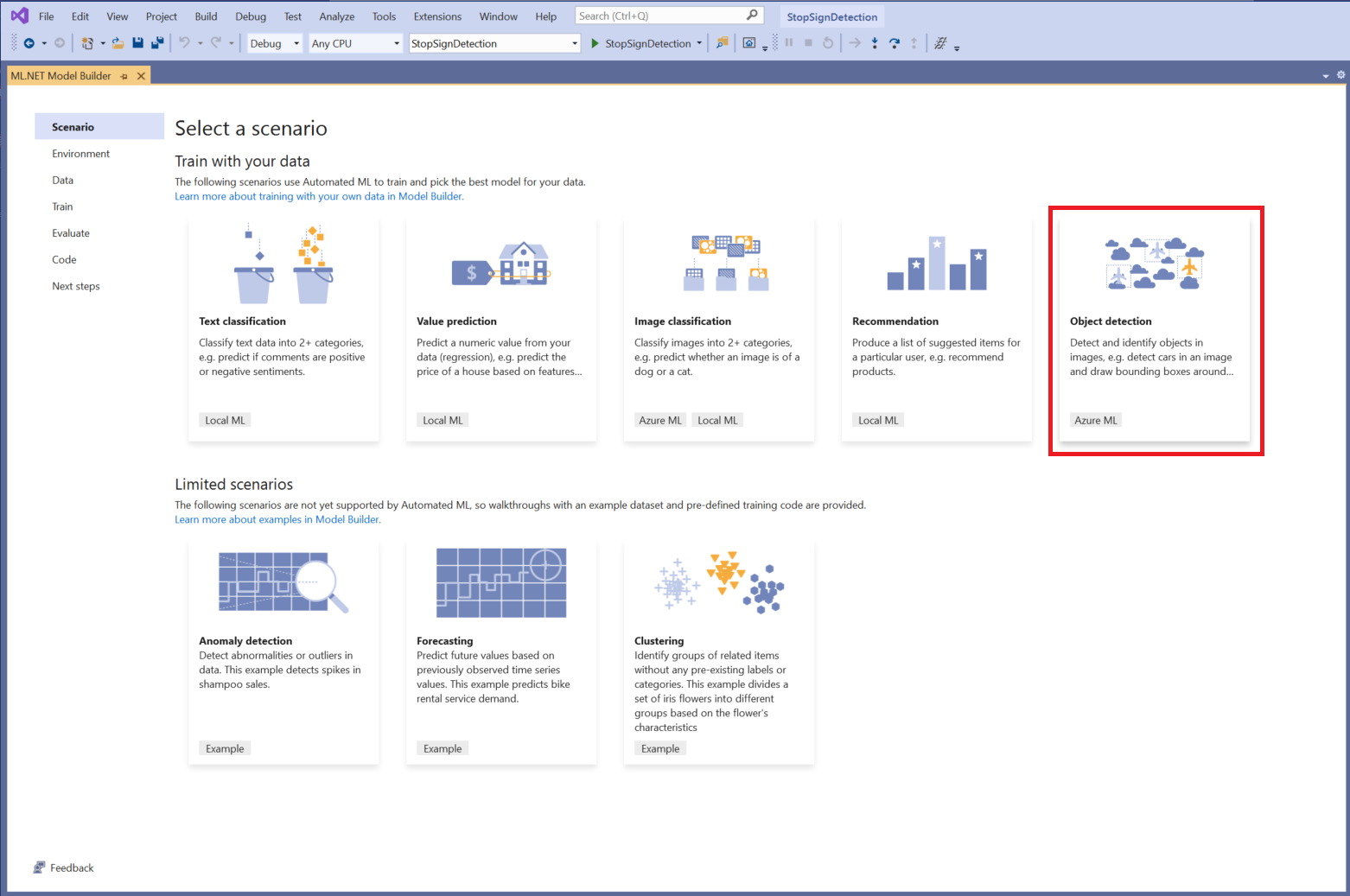
Si no ve Detección de objetos en la lista de escenarios, es posible que tenga que actualizar la versión de Model Builder.
Selección del entorno de entrenamiento
Actualmente, Model Builder solo admite modelos de detección de objetos de entrenamiento con Azure Machine Learning (Azure ML), por lo que el entorno de entrenamiento de Azure está seleccionado de forma predeterminada.
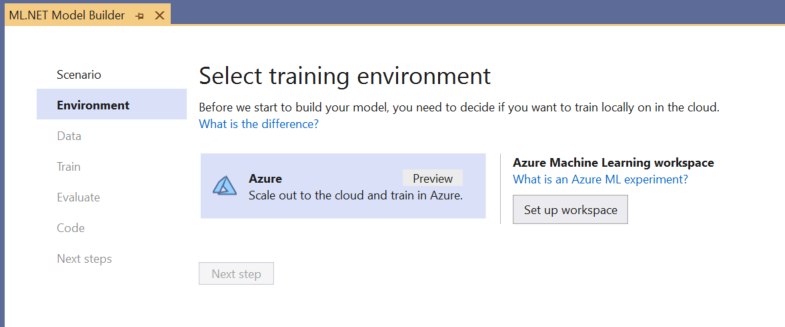
Para entrenar un modelo con Azure ML, debe crear un experimento de Azure ML desde Model Builder.
Un experimento de Azure ML es un recurso que encapsula la configuración y los resultados de una o varias ejecuciones de aprendizaje automático.
Para crear un experimento de Azure ML, primero debe configurar el entorno en Azure. Un experimento necesita los siguientes componentes para ejecutarse:
- Una suscripción de Azure
- Un área de trabajo, que es un recurso de Azure ML que proporciona una ubicación central para todos los artefactos y recursos de Azure ML creados como parte de la ejecución de entrenamiento.
- Un proceso de Azure ML, que es una máquina virtual Linux basada en la nube que se usa para el entrenamiento. Obtenga más información sobre los tipos de proceso que admite Model Builder.
Configuración de un área de trabajo de Azure ML
Para configurar el entorno, siga estos pasos:
Seleccione el botón Set up workspace (Configurar área de trabajo).
En el cuadro de diálogo Create new experiment (Crear experimento), seleccione su suscripción de Azure.
Cree un área de trabajo de Azure ML o seleccione una que ya exista.
Al crear un área de trabajo, se aprovisionan automáticamente los siguientes recursos:
- Área de trabajo de Azure Machine Learning
- Azure Storage
- Azure Application Insights
- Azure Container Registry
- Azure Key Vault
Como resultado, este proceso puede tardar unos minutos.
Cree un proceso de Azure ML o seleccione uno que ya exista. Este proceso puede tardar unos minutos.
Deje el nombre del experimento y seleccione Create (Crear).
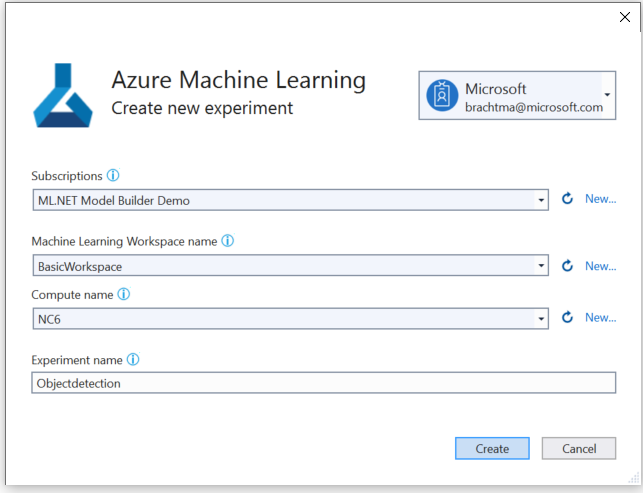
La primera vez que se crea un experimento, su nombre se registra en el área de trabajo. Todas las ejecuciones posteriores (si se usa el mismo nombre del experimento) se registran como parte del mismo experimento. De lo contrario, se crea un nuevo experimento.
Si le parece bien la configuración, seleccione el botón Next step (Siguiente paso) en Model Builder para desplazarse al paso Data (Pasos).
Carga de los datos
En el paso Data (Datos) de Model Builder, seleccionará el conjunto de datos de entrenamiento.
Importante
Model Builder solo acepta actualmente el formato JSON generado por VoTT.
Seleccione el botón situado en la sección Entrada y use el Explorador de archivos para buscar
StopSignObjDetection-export.json, que debería estar en el directorio Stop-Signs/vott-json-export.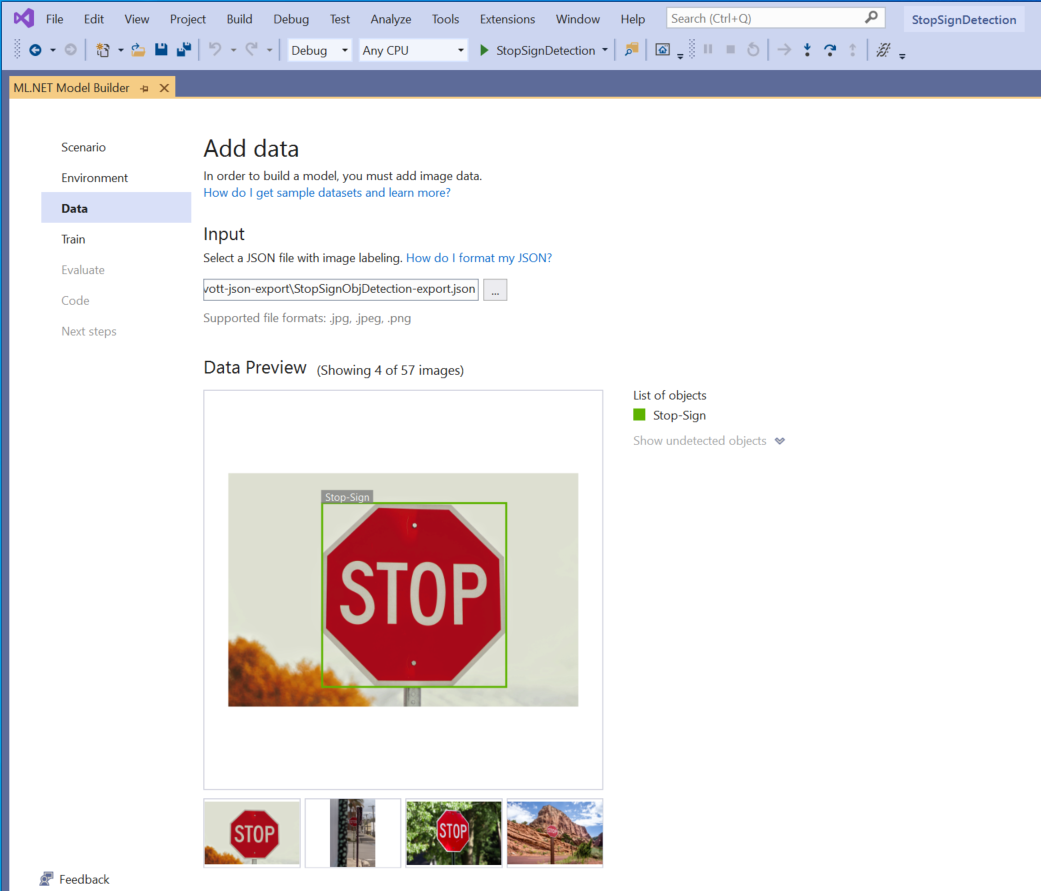
Si los datos parecen correctos en Data Preview(Vista previa de datos), seleccione Next step (Siguiente paso) para avanzar al paso Train (Entrenar).
Entrenamiento del modelo
El siguiente paso consiste en entrenar el modelo.
En la pantalla Train (Entrenar) de Model Builder, seleccione el botón Start training (Iniciar entrenamiento).
En este punto, los datos se cargan en Azure Storage y el proceso de entrenamiento comienza en Azure ML.
El proceso de entrenamiento tarda algún tiempo, y la duración puede variar en función del tamaño del proceso seleccionado, así como de la cantidad de datos. La primera vez que se entrena un modelo en Azure, es probable que el tiempo de entrenamiento sea ligeramente mayor porque se deben aprovisionar los recursos. Para este ejemplo de 50 imágenes, el entrenamiento tardó aproximadamente 16 minutos.
Puede realizar un seguimiento del progreso de las ejecuciones en Azure Machine Learning seleccionando el vínculo Monitor current run in Azure portal (Supervisar la ejecución actual en Azure Portal) en Visual Studio.
Una vez completado el entrenamiento, seleccione el botón Next step (Siguiente paso) para avanzar al paso Evaluate (Evaluar).
Evaluación del modelo
En la pantalla Evaluate (Evaluar), obtendrá información general sobre los resultados del proceso de entrenamiento, incluida la precisión del modelo.
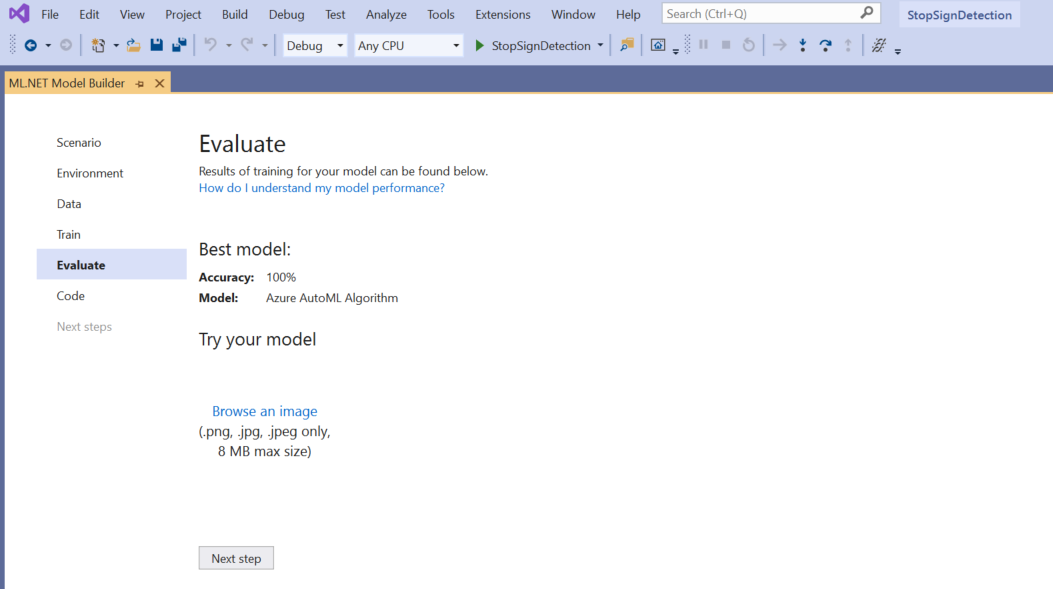
En este caso, se indica que la precisión es del 100 %, lo que significa que lo más probable es que el modelo se sobreajuste debido a que hay demasiadas imágenes en el conjunto de datos.
Puede usar la experiencia Try your model (Probar el modelo) para comprobar rápidamente si el modelo funciona según lo previsto.
Seleccione Browse an image (Examinar una imagen) y proporcione una imagen de prueba, preferiblemente una que el modelo no haya utilizado como parte del entrenamiento.
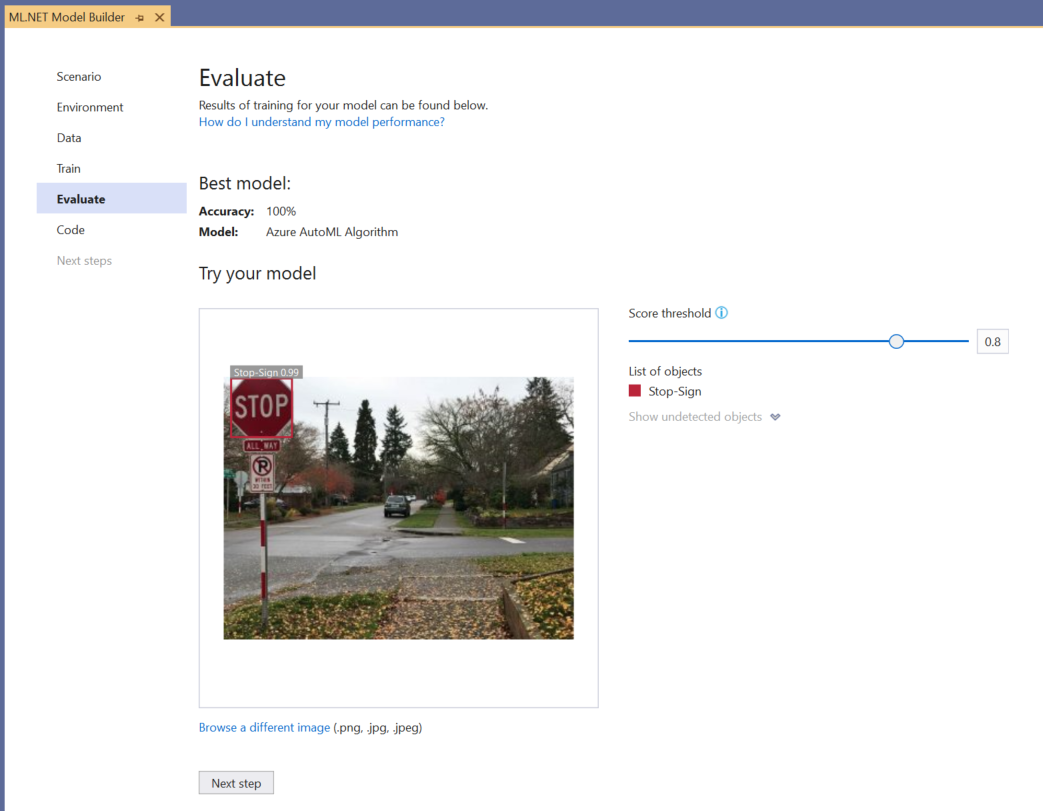
La puntuación mostrada en cada rectángulo de selección detectado indica la confianza del objeto detectado. Por ejemplo, en la captura de pantalla anterior, la puntuación del rectángulo de selección alrededor de la señal de detención indica que hay un 99 % de probabilidades en el modelo de que el objeto detectado sea una señal de detención.
El umbral de puntuación, cuyo valor puede aumentarse o disminuirse con el control deslizante, agregará y quitará objetos detectados según las puntuaciones. Por ejemplo, si el umbral es 0,51, el modelo solo mostrará los objetos que tengan una puntuación de confianza de 0,51 o superior. A medida que aumente el umbral, verá menos objetos detectados y, a medida que lo disminuya, verá más objetos detectados.
Si no le parecen bien las métricas de precisión, una forma sencilla de intentar mejorar la precisión del modelo es usar más datos. En caso contrario, seleccione el vínculo Paso siguiente para avanzar al paso Consumir de Model Builder.
(Opcional) Consumo del modelo
Este paso tendrá plantillas de proyecto que puede usar para consumir el modelo. Es opcional y puede elegir el método que mejor se adapte a sus necesidades sobre cómo atender el modelo.
- Aplicación de consola
- API Web
Aplicación de consola
Al agregar una aplicación de consola a la solución, se le pedirá que asigne un nombre al proyecto.
Asigne el nombre StopSignDetection_Console al proyecto de consola.
Haga clic en Agregar a la solución para agregar el proyecto a la solución actual.
Ejecute la aplicación.
La salida generada por el programa debe ser similar al siguiente fragmento de código:
Predicted Boxes: Top: 73.225296, Left: 256.89764, Right: 533.8884, Bottom: 484.24243, Label: stop-sign, Score: 0.9970765
API Web
Al agregar una API web a la solución, se le pedirá que asigne un nombre al proyecto.
Asigne el nombre StopSignDetection_API al proyecto de API web.
Haga clic en Agregar a la solución para agregar el proyecto a la solución actual.
Ejecute la aplicación.
Abra PowerShell y escriba el código siguiente, donde PORT es el puerto donde escuchar la aplicación.
$body = @{ ImageSource = <Image location on your local machine> } Invoke-RestMethod "https://localhost:<PORT>/predict" -Method Post -Body ($body | ConvertTo-Json) -ContentType "application/json"Si se realiza correctamente, la salida debería ser similar al texto a continuación.
boxes labels scores boundingBoxes ----- ------ ------ ------------- {339.97797, 154.43184, 472.6338, 245.0796} {1} {0.99273646} {}- En la columna
boxesse proporcionan las coordenadas del rectángulo delimitador del objeto que se ha detectado. Los valores de aquí pertenecen a las coordenadas izquierda, superior, derecha e inferior, respectivamente. labelsson el índice de las etiquetas predichas. En este caso, el valor 1 es una señal de stop.scoresdefine la confianza del modelo en que el rectángulo de selección pertenece a esa etiqueta.
Nota:
(Opcional) Las coordenadas del rectángulo de selección se normalizan para un ancho de 800 píxeles y un alto de 600 píxeles. Para modificar la escala de las coordenadas del rectángulo de selección de la imagen en un posprocesamiento adicional, debe hacer lo siguiente:
- Multiplique las coordenadas superior e inferior por el alto de la imagen original y multiplique las coordenadas izquierda y derecha por el ancho.
- Divida las coordenadas superior e inferior entre 600 y las coordenadas izquierda y derecha entre 800.
Por ejemplo, dadas las dimensiones de la imagen original,
actualImageHeightyactualImageWidth, y un objetoModelOutputdenominadoprediction, en el siguiente fragmento de código se muestra cómo modificar la escala de las coordenadasBoundingBox:var top = originalImageHeight * prediction.Top / 600; var bottom = originalImageHeight * prediction.Bottom / 600; var left = originalImageWidth * prediction.Left / 800; var right = originalImageWidth * prediction.Right / 800;Una imagen puede tener más de un rectángulo de selección, por lo que se debe aplicar el mismo proceso a cada uno de los rectángulos de selección de la imagen.
- En la columna
¡Enhorabuena! Ha creado correctamente un modelo de aprendizaje automático para detectar señales de detención en imágenes mediante Model Builder. Puede encontrar el código fuente para este tutorial en el repositorio dotnet/machinelearning-samples de GitHub.
Recursos adicionales
Para más información sobre los temas mencionados en este tutorial, visite estos recursos:
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.