Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se proporciona información general sobre los tipos que ayudan a leer datos que se ejecutan en varios búferes. Se utilizan principalmente para soportar objetos PipeReader.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> es un contrato para la escritura sincrónica en búfer. En el nivel más bajo, la interfaz:
- Es básico y no es difícil de usar.
- Permite el acceso a Memory<T> o Span<T>. Es posible escribir en
Memory<T>oSpan<T>y se puede determinar cuántos elementosTse escribieron.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
El método anterior:
- Solicita un búfer de al menos 5 bytes del
IBufferWriter<byte>medianteGetSpan(5). - Escribe los bytes de la cadena ASCII "Hola" en el elemento
Span<byte>devuelto. - Llama IBufferWriter<T> para indicar cuántos bytes se escribieron en el buffer.
Este método de escritura usa el Memory<T>/Span<T> búfer proporcionado por el IBufferWriter<T>. Como alternativa, el método de extensión Write se puede usar para copiar un búfer existente a IBufferWriter<T>.
Write realiza el trabajo de llamar GetSpan/Advance según corresponda, por lo que no es necesario llamar Advance después de escribir:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> es una implementación de IBufferWriter<T> cuyo almacén de respaldo es una única matriz contigua.
Problemas comunes de IBufferWriter
-
GetSpanyGetMemorydevuelven un búfer con al menos la cantidad de memoria solicitada. No asumas tamaños exactos de buffer. - No hay ninguna garantía de que las llamadas sucesivas devuelvan el mismo búfer o un búfer del mismo tamaño.
- Se debe solicitar un nuevo búfer después de llamar
Advancepara continuar escribiendo más datos. No se puede escribir en un búfer adquirido previamente después de llamar aAdvance.
ReadOnlySequence<T>
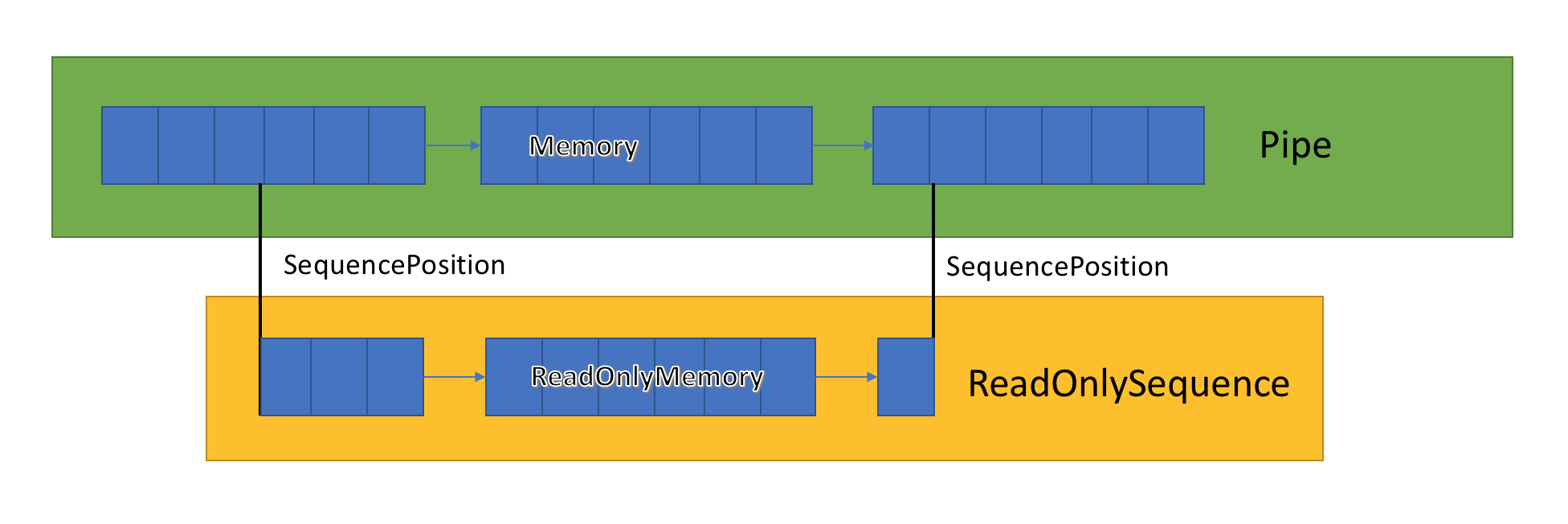
ReadOnlySequence<T> es una estructura que puede representar una secuencia contigua o no contigua de T. Se puede construir a partir de:
- Una operación
T[] - Una operación
ReadOnlyMemory<T> - Un par de nodos de lista enlazada y un índice para representar la posición inicial y final de la secuencia.
La tercera representación es la más interesante, ya que tiene implicaciones de rendimiento en varias operaciones en ReadOnlySequence<T>:
| Representación | Operación | Complejidad |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
Debido a esta representación mixta, ReadOnlySequence<T> expone índices como SequencePosition en lugar de un entero.
SequencePosition:
- es un valor opaco que representa un índice en la estructura
ReadOnlySequence<T>donde se originó. - Consta de dos partes, un entero y un objeto . Lo que representan estos dos valores están vinculados a la implementación de
ReadOnlySequence<T>.
Acceso a los datos
ReadOnlySequence<T> expone los datos como un enumerable de ReadOnlyMemory<T>. La enumeración de cada uno de los segmentos se puede realizar mediante un foreach básico:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
El método anterior busca en cada segmento un byte específico. Si necesita realizar un seguimiento de cada segmento SequencePosition, ReadOnlySequence<T>.TryGet es más adecuado. En el ejemplo siguiente se cambia el código anterior para devolver un SequencePosition valor en lugar de un entero. Devolver SequencePosition tiene la ventaja de permitir que el autor de la llamada evite un segundo examen para obtener los datos en un índice específico.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
La combinación de SequencePosition y TryGet actúa como un enumerador. El campo de posición se modifica al principio de cada iteración para que sea el inicio de cada segmento dentro de ReadOnlySequence<T>.
El método anterior existe como un método de extensión en ReadOnlySequence<T>.
PositionOf se puede usar para simplificar el código anterior:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Procesamiento de ReadOnlySequence<T>
El procesamiento de un ReadOnlySequence<T> elemento puede ser difícil, ya que los datos se pueden dividir entre varios segmentos dentro de la secuencia. Para obtener el mejor rendimiento, divida el código en dos rutas de acceso:
- Una ruta de acceso rápida que se ocupa del caso de un único segmento.
- Camino lento que se ocupa de la división de datos entre segmentos.
Hay algunos enfoques que se pueden usar para procesar datos en secuencias de varios segmentos:
- Use
SequenceReader<T> - Analice los datos segmento por segmento, haciendo un seguimiento de
SequencePositiony del índice dentro del segmento analizado. Esto evita asignaciones innecesarias, pero puede ser ineficiente, especialmente para los buffers pequeños. - Copie el
ReadOnlySequence<T>en una matriz contigua y trátelo como un único búfer.- Si el tamaño de
ReadOnlySequence<T>es pequeño, puede ser razonable copiar los datos en un búfer asignado por la pila mediante el operador stackalloc. - Copie
ReadOnlySequence<T>en una matriz agrupada mediante ArrayPool<T>.Shared. - Utilice
ReadOnlySequence<T>.ToArray(). Este método no se recomienda en las rutas de acceso activas, ya que asigna un nuevo elementoT[]en el montón.
- Si el tamaño de
En los ejemplos siguientes se muestran algunos casos comunes para procesar ReadOnlySequence<byte>:
Procesamiento de datos binarios
En el siguiente ejemplo se analiza una longitud de entero bid endian de 4 bytes desde el inicio de ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Procesar datos de texto
En el ejemplo siguiente:
- Busca la primera línea nueva (
\r\n) enReadOnlySequence<byte>y la devuelve a través del parámetro "line". - Recorta esa línea, excluyendo el
\r\ndel búfer de entrada.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Segmentos vacíos
Es válido almacenar segmentos vacíos dentro de un ReadOnlySequence<T>. Es posible que se produzcan segmentos vacíos al enumerar segmentos explícitamente:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
El código anterior crea un ReadOnlySequence<byte> objeto con segmentos vacíos y muestra cómo afectan esos segmentos vacíos a las distintas API:
-
ReadOnlySequence<T>.Slicecon un valorSequencePositionque apunta a un segmento vacío conserva ese segmento. -
ReadOnlySequence<T>.Slicecon un valor entero omite los segmentos vacíos. - Al enumerar
ReadOnlySequence<T>, se enumeran los segmentos vacíos.
Posibles problemas con ReadOnlySequence<T> y SequencePosition
Hay varios resultados inusuales al tratar con un ReadOnlySequence<T>/SequencePosition frente a un ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int normal:
-
SequencePositiones un marcador de posición para un elemento específicoReadOnlySequence<T>, no una posición absoluta. Dado que es relativo a un específicoReadOnlySequence<T>, no tiene significado si se usa fuera delReadOnlySequence<T>lugar donde se originó. - No se puede realizar aritmética en
SequencePositionsin elReadOnlySequence<T>. Eso significa que hacer cosas básicas, comoposition++, se escribeposition = ReadOnlySequence<T>.GetPosition(1, position). -
GetPosition(long)no admite índices negativos. Esto significa que es imposible obtener del segundo al último carácter sin recorrer todos los segmentos. - No se pueden comparar dos
SequencePosition, lo que dificulta lo siguiente:- Sepa si una posición es mayor o menor que otra.
- Escriba algunos algoritmos de análisis.
-
ReadOnlySequence<T>es mayor que una referencia de objeto y debe pasarse por in o ref siempre que sea posible. El paso deReadOnlySequence<T>porinorefreduce las copias de la estructura. - Segmentos vacíos:
- Son válidos dentro de
ReadOnlySequence<T>. - Pueden aparecer cuando se recorre en iteración mediante el método
ReadOnlySequence<T>.TryGet. - Pueden aparecer segmentando la secuencia mediante el método
ReadOnlySequence<T>.Slice()con objetosSequencePosition.
- Son válidos dentro de
SequenceReader<T>
- Es un nuevo tipo que se introdujo en .NET Core 3.0 para simplificar el procesamiento de un
ReadOnlySequence<T>. - Unifica las diferencias entre un único segmento
ReadOnlySequence<T>y varios segmentosReadOnlySequence<T>. - Proporciona asistentes para leer datos binarios y de texto (
byteychar) que pueden o no dividirse entre segmentos.
Hay métodos integrados para tratar el procesamiento de datos binarios y delimitados. En la sección siguiente se muestra el aspecto de los mismos métodos con el SequenceReader<T>:
Acceso a los datos
SequenceReader<T> tiene métodos para enumerar directamente los datos dentro de ReadOnlySequence<T>. El siguiente código es un ejemplo de procesamiento de un ReadOnlySequence<byte> a byte a la vez.
while (reader.TryRead(out byte b))
{
Process(b);
}
CurrentSpan expone el valor Span del segmento actual, que es similar a lo que se hizo en el método manualmente.
Uso de la posición
El siguiente código es un ejemplo de implementación de FindIndexOf usando el SequenceReader<T>.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Procesamiento de datos binarios
En el siguiente ejemplo se analiza una longitud de entero bid endian de 4 bytes desde el inicio de ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Procesar datos de texto
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Problemas comunes de SequenceReader<T>
- Dado que
SequenceReader<T>es una estructura mutable, siempre debe pasarse por referencia. -
SequenceReader<T>es una estructura ref , por lo que solo se puede usar en métodos sincrónicos y no se puede almacenar en campos. Para más información, consulte Cómo evitar asignaciones. -
SequenceReader<T>está optimizado para su uso como lector de solo avance.Rewindestá diseñado para copias de seguridad pequeñas que no se pueden abordar mediante otras APIRead,Peek, yIsNext.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.