Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La deduplicación busca y quita los registros duplicados de un cliente de una tabla de origen, de modo que cada cliente esté representado por una sola fila en cada tabla. Cada tabla se deduplica por separado mediante reglas para identificar los registros de un cliente determinado.
Cada regla de deduplicación se ejecuta en cada fila. Si la primera regla coincide con las filas 1 y 2, y la regla 2 coincide con las filas 2 y 3, entonces las filas 1, 2 y 3 coinciden. Cuando se encuentran filas coincidentes, se selecciona una fila ganadora para representar a ese cliente en función de las preferencias de Combinar (Más lleno, Más reciente o Menos reciente). Utilice la opción Avanzado para crear una fila ganadora seleccionando campos de las distintas filas coincidentes, como el correo electrónico más reciente, pero la dirección más completa.
Customer Insights - Data automáticamente realiza las siguientes acciones:
- Deduplica registros con el mismo valor de clave principal, seleccionando la primera fila del conjunto de datos como ganadora.
- Deduplica registros usando las reglas de coincidencia definidas para la tabla cuando haga coincidir filas entre tablas.
Definir reglas de desduplicación
Una buena regla identifica a un cliente único. Considere sus datos. Puede ser suficiente identificar a los clientes basándose en un campo como el correo electrónico. Sin embargo, si desea diferenciar a los clientes que comparten un correo electrónico, puede optar por tener una regla con dos condiciones, que coincidan con Correo electrónico + Nombre. Para más información, consulte Procedimiento recomendado de desduplicación.
En la página Reglas de deduplicación, seleccione una tabla y seleccione Agregar regla para definir las reglas de deduplicación.
Propina
Si enriqueció tablas en el nivel origen de datos para ayudar a mejorar sus resultados de unificación, seleccione Usar tablas enriquecidas en la parte superior de la página. Para obtener más información, consulte Enriquecimiento de orígenes de datos.
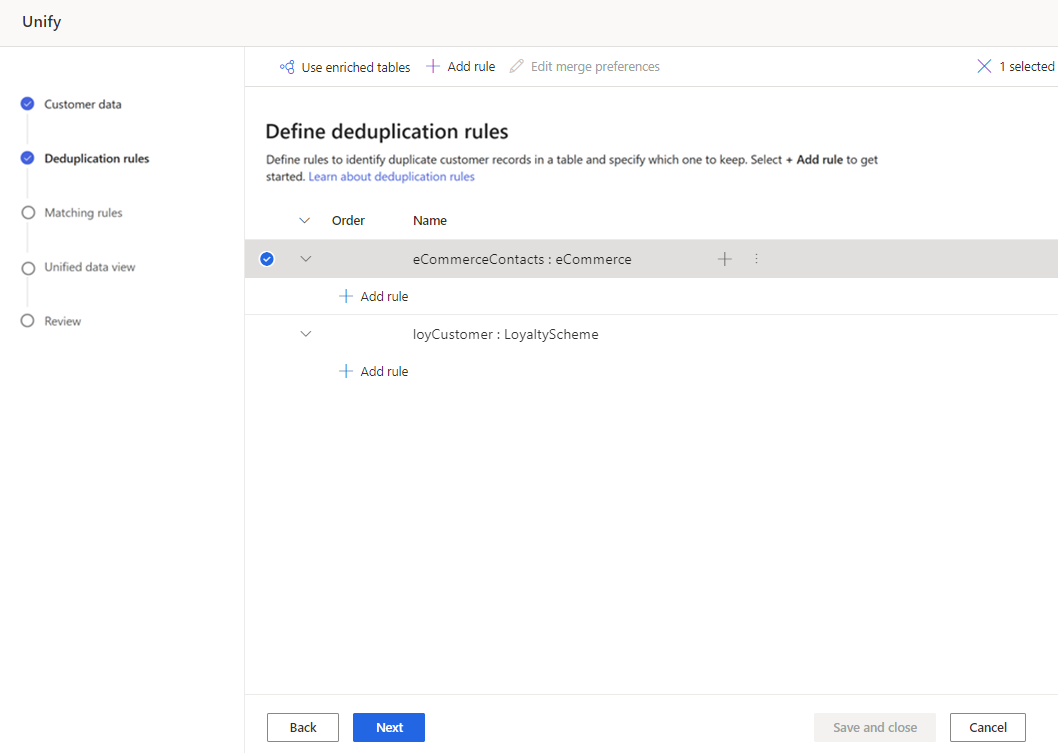
En el panel Agregar regla, introduzca la siguiente información:
Seleccionar campo: elija de la lista de campos disponibles de la tabla que desea verificar si hay duplicados. Elija campos que probablemente sean únicos para cada cliente. Por ejemplo, una dirección de correo electrónico o la combinación de nombre, ciudad y número de teléfono.
Normalizar: seleccione entre las opciones de normalización para la columna. La normalización solo afecta el paso de coincidencia y no cambia los datos.
Normalización Ejemplos Números Convierte muchos símbolos Unicode que representan números en números simples.
Ejemplos: ❽ y Ⅷ están normalizados al número 8.
Nota: Los símbolos deben estar codificados en formato de puntos Unicode.Símbolos Elimina símbolos y caracteres especiales.
Ejemplos: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ]Texto en minúsculas Convierte los caracteres en mayúscula a minúscula.
Ejemplo: 'ESTO ES uN EJemplo' se convierte en 'esto es un ejemplo'Tipo: Teléfono Convierte teléfonos en varios formatos a dígitos y tiene en cuenta las variaciones en la forma en que se presentan los códigos de país y las extensiones. Los símbolos y los espacios en blanco se ignoran. Los dígitos '0' iniciales en los códigos de país/región se ignoran, coincidiendo con +1 y +01. Las extensiones indicadas por un prefijo con letras se ignoran (X 123). El código de país normalizado es significativo, por lo que un teléfono con un código de país no coincidirá con un teléfono sin un código de país.
Ejemplo: +01 425.555.1212 coincide con 1 (425) 555-1212
+01 425.555.1212 no coincidirá con (425) 555-1212Tipo: Nombre Convierte más de 500 variaciones de nombres y títulos comunes.
Ejemplos: "debby" -> "deborah" "prof" y "profesor" -> "Prof."Tipo: Dirección Convierte partes comunes de direcciones
Ejemplos: "calle" -> "C." y "noroeste" -> "NO"Tipo: Organización Elimina alrededor de 50 'palabras irrelevantes' de nombres de empresas, como "co", "corp", "corporación" y "ltd". Unicode a ASCII Convierte los caractertes Unicode en su equivalente ASCII
Ejemplo: Los caracteres 'à,' 'á,' 'â,' 'À,' 'Á,' 'Â,' 'Ã,' 'Ä,' 'Ⓐ,' y 'A' se convierten todos en 'a'.Espacio en blanco Elimina todos los espacios en blanco Asignación de alias Le permite cargar una lista personalizada de pares de cadenas que luego se pueden usar para indicar cadenas que siempre deben considerarse una coincidencia exacta.
Utilice la asignación de alias cuando tenga ejemplos de datos específicos que crea que deberían coincidir y no coincidan utilizando uno de los otros patrones de normalización.
Ejemplo: Scott y Scooter, o MSFT y Microsoft.Omisión personalizada Le permite cargar una lista personalizada de cadenas que luego se pueden usar para indicar cadenas que nunca deben ser coincidencia.
La omisión personalizada es útil cuando tiene datos con valores comunes que deben ignorarse, como un número de teléfono ficticio o un correo electrónico ficticio.
Ejemplo: nunca haga coincidir el teléfono 555-1212, o test@contoso.com
Precisión: establezca el nivel de precisión. La precisión se usa para la coincidencia exacta y la coincidencia aproximada, y determina qué tan cerca deben estar dos cadenas para que se consideren una coincidencia.
- Básico: se escoge entre Bajo (30 %), Medio (60 %), Alto (80 %) y Exacto (100 %). Seleccione Exacto para hacer coincidir solo los registros que coincidan al 100 por ciento.
- Personalizado: establezca el porcentaje con el que los registros deben coincidir. El sistema solo hace coincidir los registros que superen este umbral.
Nombre: Nombre de la regla.
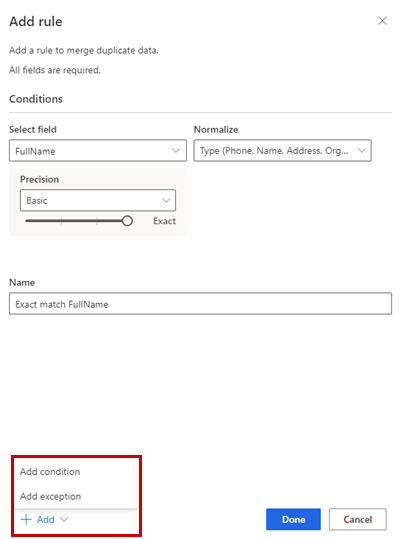
Opcionalmente, seleccione Agregar>Agregar condición para agregar más condiciones a la regla. Las condiciones están conectadas con un operador AND lógico y, por lo tanto, solo se ejecutan si se cumplen todas las condiciones.
Opcionalmente, Agregar>Añadir excepción para añadir excepciones a la regla. Las excepciones se utilizan para abordar casos raros de falsos positivos y falsos negativos.
Seleccione Hecho para crear la regla.
Opcionalmente, agregue más reglas.

Seleccionar preferencias de combinación
Cuando se ejecutan reglas y se identifican registros duplicados para un cliente, se selecciona una "fila ganadora" en función de la directiva de combinación. La fila ganadora representa al cliente en el siguiente paso de unificación que hace coincidir los registros entre tablas. Los datos de las filas no ganadoras ("alternativas") se utilizan en el paso Unificación de reglas de coincidencia para hacer coincidir registros de otras tablas con la fila ganadora. Este enfoque mejora los resultados de coincidencia al permitir que información como números de teléfono anteriores ayude a identificar registros coincidentes. La fila ganadora se puede configurar para que sea la más llena, la más reciente o la menos reciente de los registros duplicados encontrados.
Seleccione una tabla y luego Editar preferencias de combinación. Aparece el panel Combinar preferencias.
Elija una de las tres opciones para determinar qué registro conservar si se encuentra un duplicado:
- Más rellenado: identifica el registro con las columnas más rellenadas como el registro ganador. Es la opción de combinación predeterminada.
- Más reciente: identifica el registro ganador basado en el más reciente. Requiere una fecha o un campo numérico para definir la antigüedad.
- Menos reciente: identifica el registro ganador basado en el menos reciente. Requiere una fecha o un campo numérico para definir la antigüedad.
Si hay empate, el registro ganador es el que tiene el valor de clave principal MAX(PK) o mayor.
Opcionalmente, para definir preferencias de combinación en columnas individuales de una tabla, seleccione Avanzado en la parte inferior del panel. Por ejemplo, puede optar por mantener el correo electrónico más reciente Y la dirección más completa de diferentes registros. Expanda la tabla para ver todas sus columnas y defina qué opción usar para columnas individuales.. Si elige una opción basada en la antigüedad, también debe especificar un campo de fecha/hora que defina la antigüedad.
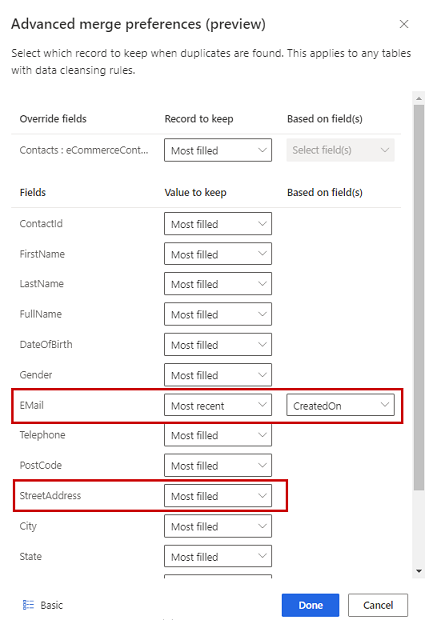
Seleccione Listo para aplicar las preferencias de combinación.
Después de definir las reglas de deduplicación y las preferencias de combinación, seleccione Siguiente.