Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Scott Allen
Publicación: mayo de 2010
Introducción
En este informe técnico se describe y demuestra cómo escribir código comprobable con ADO.NET Entity Framework 4.0 y Visual Studio 2010. Este documento no se centra en una metodología de prueba específica, como el diseño controlado por pruebas (TDD) o el diseño controlado por comportamientos (BDD). Más bien, se centra en cómo escribir código que use ADO.NET Entity Framework, pero siga siendo fácil de aislar y probar de forma automatizada. Veremos patrones de diseño comunes que facilitan las pruebas en escenarios de acceso a datos y cómo aplicar esos patrones al usar el marco. También veremos características específicas del marco para conocer el funcionamiento de esas características en código comprobable.
¿Qué es el código comprobable?
La capacidad de comprobar un fragmento de software mediante pruebas unitarias automatizadas ofrece muchas ventajas deseables. Es bien sabido que hacer pruebas de calidad reducirá el número de defectos de software en una aplicación y aumentará la calidad de la aplicación, pero las pruebas unitarias van mucho más allá de encontrar errores.
Un buen conjunto de pruebas unitarias permite a un equipo de desarrollo ahorrar tiempo y mantener el control del software que crea. Un equipo puede realizar cambios en el código existente, refactorizar, rediseñar y reestructurar software para satisfacer nuevos requisitos y agregar nuevos componentes a una aplicación, sabiendo que, además, el conjunto de pruebas les permite comprobar el comportamiento de la aplicación. Las pruebas unitarias forman parte de un ciclo de información rápido para facilitar el cambio y conservar la capacidad de mantenimiento del software a medida que aumenta la complejidad.
Sin embargo, las pruebas unitarias tienen un coste. Un equipo tiene que invertir el tiempo para crear y mantener pruebas unitarias. La cantidad de esfuerzo necesaria para crear estas pruebas está directamente relacionada con la capacidad de prueba del software subyacente. ¿Es el software fácil de probar? Un equipo que diseñe software para que sea comprobable creará pruebas eficaces más rápido que uno que trabaje con software no comprobable.
Microsoft diseñó la ADO.NET Entity Framework 4.0 (EF4) teniendo en cuenta la capacidad de prueba. Esto no significa que los desarrolladores escriban pruebas unitarias en el propio código de marco. En su lugar, los objetivos de capacidad de prueba para EF4 facilitan la creación de código comprobable que se basa en el marco. Antes de examinar ejemplos específicos, vale la pena comprender las cualidades del código comprobable.
Las cualidades del código comprobable
Un código que es fácil de probar siempre mostrará al menos dos rasgos. En primer lugar, será fácil de observar. Dados algunos conjuntos de entradas, debería ser fácil observar la salida del código. Por ejemplo, probar el siguiente método es fácil, porque devuelve directamente el resultado de un cálculo.
public int Add(int x, int y) {
return x + y;
}
Probar un método es difícil si el método escribe el valor calculado en un socket de red, una tabla de base de datos o un archivo como el código siguiente. La prueba tiene que realizar un trabajo adicional para recuperar el valor.
public void AddAndSaveToFile(int x, int y) {
var results = string.Format("The answer is {0}", x + y);
File.WriteAllText("results.txt", results);
}
En segundo lugar, debe ser fácil de aislar. Vamos a usar el siguiente pseudocódigo como ejemplo incorrecto de código comprobable.
public int ComputePolicyValue(InsurancePolicy policy) {
using (var connection = new SqlConnection("dbConnection"))
using (var command = new SqlCommand(query, connection)) {
// business calculations omitted ...
if (totalValue > notificationThreshold) {
var message = new MailMessage();
message.Subject = "Warning!";
var client = new SmtpClient();
client.Send(message);
}
}
return totalValue;
}
El método es fácil de observar, pues podemos pasar una póliza de seguro y comprobar que el valor devuelto coincide con el resultado que esperamos. Sin embargo, para probar el método, es necesario tener instalada una base de datos con el esquema correcto y configurar el servidor SMTP en caso de que el método intente enviar un correo electrónico.
La prueba unitaria simplemente comprueba la lógica de cálculo dentro del método, pero la prueba podría producir un error porque el servidor de correo electrónico está sin conexión o porque el servidor de base de datos se cambió de lugar. Ambos errores no están relacionados con el comportamiento que la prueba quiere comprobar. El comportamiento es difícil de aislar.
Los desarrolladores de software que quieren escribir código comprobable a menudo se esfuerzan por mantener una separación de distintos problemas potenciales en el código que escriben. El método anterior debe centrarse en los cálculos empresariales y delegar los detalles de implementación de la base de datos y el correo electrónico a otros componentes. Robert C. Martin llama a esto el principio de responsabilidad única. Un objeto debe tener una sola responsabilidad específica, como calcular el valor de una póliza. El resto de la base de datos y el trabajo de notificación deben ser responsabilidad de algún otro objeto. Un código así escrito es más fácil de aislar, porque se centra en una sola tarea.
En .NET tenemos las abstracciones que necesitamos seguir el principio de responsabilidad única y lograr este aislamiento. Podemos usar definiciones de interfaz y forzar el código para usar la abstracción de interfaz en lugar de un tipo concreto. Más adelante en este documento veremos cómo un método como el ejemplo incorrecto presentado anteriormente puede funcionar con interfaces que parezcan hablar con la base de datos. Sin embargo, a la hora de probar podemos usar una implementación ficticia ("dummy") que no habla con la base de datos, sino que contiene datos en memoria. Esta implementación ficticia aislará el código de problemas no relacionados en el código de acceso a datos o la configuración de la base de datos.
El aislamiento incluye ventajas adicionales. El cálculo empresarial en el último método solo debe tardar unos milisegundos en ejecutarse, pero la prueba en sí podría ejecutarse durante varios segundos, ya que el código va por la red y se comunica con varios servidores. Las pruebas unitarias deben ejecutarse rápidamente para facilitar pequeños cambios. Las pruebas unitarias también deben poder repetirse y no producir errores cuando un componente no relacionado con la prueba tenga un problema. Un código que sea fácil de observar y aislar facilita a los desarrolladores escribir pruebas para el código, dedicar menos tiempo a esperar a que se ejecuten las pruebas y, lo que es más importante, dedicar menos tiempo a seguir errores que, en realidad, no existen.
Esperamos que pueda apreciar las ventajas de las pruebas y comprender las virtudes de un código comprobable. Estamos a punto de abordar cómo escribir código observable y fácil de aislar que funcione con EF4 para guardar datos en una base de datos. Pero antes, limitaremos nuestro enfoque a analizar los diseños comprobables para el acceso a datos.
Modelos de diseño para la persistencia de datos
Ambos ejemplos incorrectos presentados anteriormente tenían demasiadas responsabilidades. El primer ejemplo incorrecto tenía que realizar un cálculo y escribir en un archivo. El segundo ejemplo incorrecto tenía que leer datos de una base de datos y realizar un cálculo empresarial y enviar correo electrónico. Al diseñar métodos más pequeños que separan los problemas potenciales y delegan la responsabilidad de otros componentes, se realizarán grandes avances en la escritura de código comprobable. El objetivo es aumentar la funcionalidad al crear acciones a partir de abstracciones pequeñas y específicas.
Cuando se trata de la persistencia de datos, las abstracciones pequeñas y específicas que buscamos son tan comunes que se han documentado en modelos de diseño. El libro de Martin Fowler "Patterns of Enterprise Application Architecture" fue el primero en describir estos patrones. Se proporcionará una breve descripción de estos patrones en las secciones siguientes antes de mostrar cómo se implementan en ADO.NET Entity Framework y cómo funcionan.
The Repository Pattern (El modelo de repositorio)
Fowler dice que un repositorio "media entre el dominio y las capas de asignación de datos mediante una interfaz similar a una colección para acceder a objetos de dominio". El objetivo del patrón de repositorio es aislar el código de los detalles triviales del acceso a datos y, como vimos anteriormente, el aislamiento es necesario para la capacidad de prueba.
La clave del aislamiento es cómo el repositorio expone objetos mediante una interfaz similar a una colección. La lógica que escribe para usar el repositorio no tiene en cuenta cómo materializará los objetos que solicite. Es posible que el repositorio hable con una base de datos o que simplemente devuelva objetos de una colección en memoria. Todo el código debe saber que el repositorio parece mantener la colección y puede recuperar, agregar y eliminar objetos de la colección.
En las aplicaciones .NET existentes, un repositorio concreto a menudo hereda de una interfaz genérica como la siguiente:
public interface IRepository<T> {
IEnumerable<T> FindAll();
IEnumerable<T> FindBy(Expression<Func\<T, bool>> predicate);
T FindById(int id);
void Add(T newEntity);
void Remove(T entity);
}
Realizaremos algunos cambios en la definición de interfaz cuando proporcionemos una implementación para EF4, pero el concepto básico seguirá siendo el mismo. El código puede usar un repositorio concreto que implemente esta interfaz para recuperar una entidad por su valor de clave principal, para recuperar una colección de entidades basadas en la evaluación de un predicado o simplemente recuperar todas las entidades disponibles. El código también puede agregar y quitar entidades a través de la interfaz del repositorio.
Dado un objeto IRepository de Employee, el código puede realizar las siguientes operaciones.
var employeesNamedScott =
repository
.FindBy(e => e.Name == "Scott")
.OrderBy(e => e.HireDate);
var firstEmployee = repository.FindById(1);
var newEmployee = new Employee() {/*... */};
repository.Add(newEmployee);
Dado que el código usa una interfaz (IRepository de Employee), podemos proporcionar el código con diferentes implementaciones de la interfaz. Una implementación podría ser una implementación respaldada por EF4 y conservar objetos en una base de datos de Microsoft SQL Server. Una implementación diferente —una que usamos durante las pruebas— podría estar respaldada por objetos List of Employee en memoria. La interfaz ayudará a lograr el aislamiento en el código.
Observe que la interfaz IRepository<T> no expone una operación Guardar. ¿Cómo actualizamos los objetos existentes? Es posible que se produzcan definiciones de IRepository que incluyan la operación Guardar y las implementaciones de estos repositorios deberán conservar inmediatamente un objeto en la base de datos. Sin embargo, en muchas aplicaciones no queremos conservar objetos individualmente, sino que queremos usarlos. Quizás acceder a ellos desde repositorios diferentes, modificarlos como parte de una actividad empresarial y, a continuación, conservar todos los objetos como parte de una sola operación atómica. Afortunadamente, hay un patrón para permitir este tipo de comportamiento.
Patrón de unidad de trabajo
Fowler dice que una unidad de trabajo "mantiene una lista de objetos afectados por una transacción empresarial y coordina la escritura de cambios y la resolución de problemas de simultaneidad". Es responsabilidad de la unidad de trabajo seguir los cambios en los objetos que usamos desde un repositorio y conservar los cambios realizados en los objetos cuando se indica a la unidad de trabajo que confirme los cambios. También es responsabilidad de la unidad de trabajo tomar los nuevos objetos que hemos agregado a todos los repositorios e insertar los objetos en una base de datos, así como la gestión de la eliminación.
Si alguna vez ha realizado algún trabajo con ADO.NET DataSets, ya conocerá la unidad de patrón de trabajo. ADO.NET DataSets tenía la capacidad de seguir nuestras actualizaciones, eliminaciones e inserción de objetos DataRow y podía (con la ayuda de TableAdapter) conciliar todos nuestros cambios en una base de datos. Sin embargo, los objetos DataSet modelan un subconjunto desconectado de la base de datos subyacente. La unidad de patrón de trabajo muestra el mismo comportamiento, pero funciona con objetos empresariales y objetos de dominio que están aislados del código de acceso a datos y no tienen en cuenta la base de datos.
Una abstracción para modelar la unidad de trabajo en el código de .NET podría ser similar a la siguiente:
public interface IUnitOfWork {
IRepository<Employee> Employees { get; }
IRepository<Order> Orders { get; }
IRepository<Customer> Customers { get; }
void Commit();
}
Al exponer las referencias del repositorio desde la unidad de trabajo, podemos garantizar que una sola unidad de objeto de trabajo tenga la capacidad de seguir todas las entidades materializadas durante una transacción empresarial. La implementación del método Commit para una unidad de trabajo real es donde se produce el trabajo real de conciliar los cambios en memoria con la base de datos.
Dada una referencia de IUnitOfWork, el código puede realizar cambios en los objetos empresariales recuperados de uno o varios repositorios y guardar todos los cambios mediante la operación de Commit atómica.
var firstEmployee = unitofWork.Employees.FindById(1);
var firstCustomer = unitofWork.Customers.FindById(1);
firstEmployee.Name = "Alex";
firstCustomer.Name = "Christopher";
unitofWork.Commit();
Modelo de carga diferida
Fowler usa el nombre carga diferida para describir "un objeto que no contiene todos los datos que necesita, pero sabe cómo obtenerlos". La carga diferida transparente es una característica importante a la hora de escribir código empresarial comprobable y trabajar con una base de datos relacional. Por ejemplo, considere el código siguiente.
var employee = repository.FindById(id);
// ... and later ...
foreach(var timeCard in employee.TimeCards) {
// .. manipulate the timeCard
}
¿Cómo se rellena la colección TimeCards? Hay dos respuestas posibles. Una respuesta es que el repositorio de empleados, cuando se le pide que capture un empleado, emite una consulta para recuperar el empleado junto con la información de la tarjeta de tiempo asociada del empleado. En las bases de datos relacionales, esto normalmente requiere una consulta con una cláusula JOIN y puede recuperar más información de la que necesita una aplicación. ¿Qué ocurre si la aplicación nunca necesita tocar la propiedad TimeCards?
Una segunda respuesta es cargar la propiedad TimeCards "a petición". Esta carga diferida es implícita y transparente para la lógica de negocios porque el código no invoca API especiales para recuperar información de tarjeta de tiempo. El código supone que la información de la tarjeta de tiempo está presente cuando sea necesario. Hay una cierta "magia" en la carga diferida que generalmente implica la interceptación en tiempo de ejecución de invocaciones de métodos. El código de interceptación es responsable de comunicarse con la base de datos y recuperar la información de la tarjeta de tiempo mientras deja que la lógica de negocios sea simplemente la lógica de negocios. Esta magia de carga diferida permite que el código empresarial se aísle de las operaciones de recuperación de datos y da como resultado código más comprobable.
El inconveniente de una carga diferida es que cuando una aplicación sí necesita la información de la tarjeta de tiempo, el código ejecutará una consulta adicional. Esto no es un problema para muchas aplicaciones, pero para aplicaciones sensibles al rendimiento o aplicaciones que recorren una serie de objetos de empleado y ejecutan una consulta para recuperar tarjetas de tiempo durante cada iteración del bucle (un problema que se conoce a menudo como problema de consulta N+1), la carga diferida puede ser ineficiente. En estos escenarios, una aplicación podría preferir hacer una carga diligente de la información de la tarjeta de tiempo de la manera más eficaz posible.
Afortunadamente, veremos cómo EF4 admite tanto cargas diferidas implícitas como cargas diligentes eficientes a medida que avanzamos a la siguiente sección e implementamos estos patrones.
Implementación de patrones con Entity Framework
Todos los modelos de diseño descritos en la última sección son sencillos de implementar con EF4. Para demostrarlo, vamos a usar una aplicación ASP.NET MVC sencilla que editará y mostrará los empleados, y su información de tarjeta de tiempo asociada. Comenzaremos usando los siguientes "objetos CRL estándar" (los POCO).
public class Employee {
public int Id { get; set; }
public string Name { get; set; }
public DateTime HireDate { get; set; }
public ICollection<TimeCard> TimeCards { get; set; }
}
public class TimeCard {
public int Id { get; set; }
public int Hours { get; set; }
public DateTime EffectiveDate { get; set; }
}
Estas definiciones de clase cambiarán ligeramente a medida que exploramos diferentes enfoques y características de EF4, pero la intención es que estas clases sean ignorantes de persistencia (PI) tanto como sea posible. Un objeto PI no sabe cómo, o incluso si el estado que contiene reside dentro de una base de datos. Los objetos PI y POCO se adaptan muy bien al software comprobable. Los objetos que usan un enfoque POCO están menos restringidos, y son más flexibles y fáciles de probar porque pueden funcionar sin una base de datos presente.
Con los POCO implementados, podemos crear un modelo de datos de entidad (EDM) en Visual Studio (vea la figura 1). No generaremos código para nuestras entidades con el EDM. En su lugar, usaremos entidades creadas por nosotros mismos. Solo usaremos el EDM para generar el esquema de la base de datos y proporcionar los metadatos que EF4 necesita para asignar objetos a la base de datos.
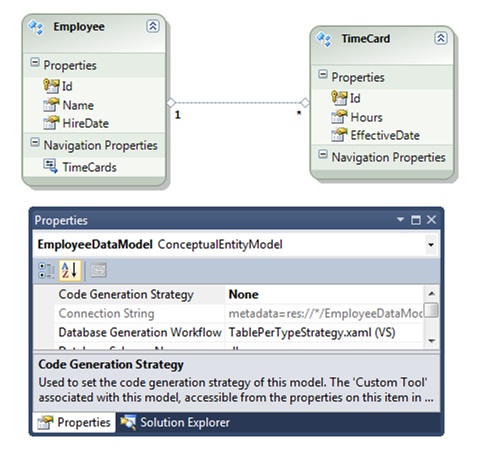
Figura 1
Nota: Si desea desarrollar primero el modelo EDM, es posible generar código POCO limpio a partir del EDM. Puede hacerlo con una extensión de Visual Studio 2010 proporcionada por el equipo de programación de datos. Para descargar la extensión, inicie el Administrador de extensiones desde el menú Herramientas de Visual Studio y busque la galería en línea de plantillas para "POCO" (vea la figura 2). Hay varias plantillas POCO disponibles para EF. Para obtener más información sobre el uso de la plantilla, consulte "Tutorial: Plantilla POCO para Entity Framework".
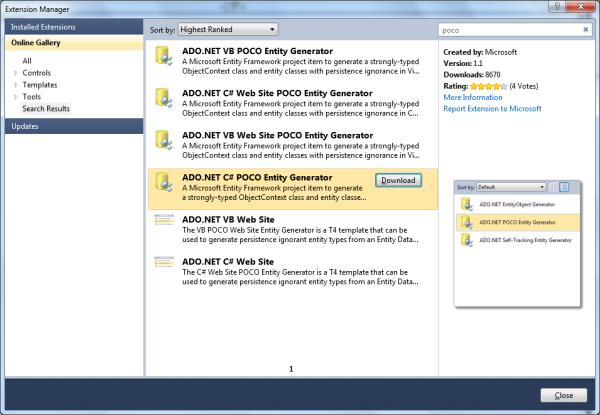
Figura 2
Desde este punto de partida de POCO exploraremos dos enfoques diferentes para crear un código comprobable. Al primer enfoque le llamaremos EF, porque aprovecha abstracciones de Entity Framework API para implementar unidades de trabajo y repositorios. En el segundo enfoque, crearemos nuestras propias abstracciones de repositorio personalizadas y, a continuación, veremos las ventajas y desventajas de cada enfoque. Comenzaremos explorando el enfoque de EF.
Una implementación centrada en EF
Tenga en cuenta la siguiente acción de controlador de un proyecto de ASP.NET MVC. La acción recupera un objeto Employee y devuelve un resultado para mostrar una vista detallada del empleado.
public ViewResult Details(int id) {
var employee = _unitOfWork.Employees
.Single(e => e.Id == id);
return View(employee);
}
¿Es el código comprobable? Para comprobar el comportamiento de la acción, necesitamos al menos dos pruebas. En primer lugar, una prueba sencilla: comprobar que la acción devuelva la vista correcta. También queremos escribir una prueba para comprobar que la acción recupera el empleado correcto y nos gustaría hacerlo sin ejecutar código para consultar la base de datos. Recuerde que queremos aislar el código sometido a prueba. El aislamiento garantizará que la prueba no produzca un error debido a un problema con el código de acceso a datos o la configuración de la base de datos. Si se produce un error en la prueba, sabemos que tenemos un error en la lógica del controlador y no en algún componente del sistema de nivel inferior.
Para lograr el aislamiento, necesitaremos algunas abstracciones como las interfaces que presentamos anteriormente para repositorios y unidades de trabajo. Recuerde que el patrón de repositorio está diseñado para mediar entre objetos de dominio y la capa de asignación de datos. En este escenario, EF4 es la capa de asignación de datos y ya proporciona una abstracción similar a un repositorio denominada IObjectSet<T> (desde el espacio de nombres System.Data.Objects). La definición de interfaz es similar a la siguiente.
public interface IObjectSet<TEntity> :
IQueryable<TEntity>,
IEnumerable<TEntity>,
IQueryable,
IEnumerable
where TEntity : class
{
void AddObject(TEntity entity);
void Attach(TEntity entity);
void DeleteObject(TEntity entity);
void Detach(TEntity entity);
}
IObjectSet<T> cumple los requisitos de un repositorio porque se parece a una colección de objetos (a través de IEnumerable<T>) y proporciona métodos para agregar y quitar objetos de la colección simulada. Los métodos Attach y Detach exponen funcionalidades adicionales de la API de EF4. Para usar IObjectSet<T> como interfaz para los repositorios, necesitamos una unidad de abstracción de trabajo para enlazar repositorios juntos.
public interface IUnitOfWork {
IObjectSet<Employee> Employees { get; }
IObjectSet<TimeCard> TimeCards { get; }
void Commit();
}
Una implementación concreta de esta interfaz se comunicará con SQL Server y es fácil de crear mediante la clase ObjectContext de EF4. La clase ObjectContext es la unidad real de trabajo en la API de EF4.
public class SqlUnitOfWork : IUnitOfWork {
public SqlUnitOfWork() {
var connectionString =
ConfigurationManager
.ConnectionStrings[ConnectionStringName]
.ConnectionString;
_context = new ObjectContext(connectionString);
}
public IObjectSet<Employee> Employees {
get { return _context.CreateObjectSet<Employee>(); }
}
public IObjectSet<TimeCard> TimeCards {
get { return _context.CreateObjectSet<TimeCard>(); }
}
public void Commit() {
_context.SaveChanges();
}
readonly ObjectContext _context;
const string ConnectionStringName = "EmployeeDataModelContainer";
}
Usar un IObjectSet<T> solo requiere invocar el método CreateObjectSet del objeto ObjectContext. En segundo plano, el marco usará los metadatos proporcionados en el EDM para generar un ObjectSet<T> concreto. Vamos a seguir devolviendo la interfaz del ObjectSet<T>, ya que ayudará a conservar la capacidad de prueba en el código de cliente.
Esta implementación concreta es útil en producción, pero debemos centrarnos en cómo usaremos nuestra abstracción IUnitOfWork para facilitar las pruebas.
Los dobles de prueba
Para aislar la acción del controlador, necesitaremos la capacidad de cambiar entre la unidad de trabajo real (respaldada por ObjectContext) y una unidad de trabajo doble o "emulación" de prueba (realizando operaciones en memoria). El enfoque común para realizar este tipo de conmutación es no permitir que el controlador MVC cree una instancia de una unidad de trabajo, sino que, en su lugar, pase la unidad de trabajo al controlador como parámetro de constructor.
class EmployeeController : Controller {
publicEmployeeController(IUnitOfWork unitOfWork) {
_unitOfWork = unitOfWork;
}
...
}
El código anterior es un ejemplo de inserción de dependencias. No permitimos que el controlador cree su dependencia (la unidad de trabajo), sino que insertamos la dependencia en el controlador. En un proyecto de MVC es habitual usar un generador de controladores personalizados en combinación con un contenedor de inversión de control (IoC) para automatizar la inserción de dependencias. Estos temas están fuera del ámbito de este artículo, pero puede leer más sobre esto en las referencias al final de este artículo.
La implementación de una unidad de trabajo de emulación que podemos usar para las pruebas podría ser como la siguiente.
public class InMemoryUnitOfWork : IUnitOfWork {
public InMemoryUnitOfWork() {
Committed = false;
}
public IObjectSet<Employee> Employees {
get;
set;
}
public IObjectSet<TimeCard> TimeCards {
get;
set;
}
public bool Committed { get; set; }
public void Commit() {
Committed = true;
}
}
Observe que la unidad de trabajo de emulación expone una propiedad Commited. A veces resulta útil agregar características a una clase de emulación que facilite las pruebas. En este caso, es fácil observar si el código confirma una unidad de trabajo: solo tiene que comprobar la propiedad Commited.
También necesitaremos un IObjectSet<T> de emulación para almacenar objetos Employee y TimeCard en la memoria. Podemos proporcionar una sola implementación mediante genéricos.
public class InMemoryObjectSet<T> : IObjectSet<T> where T : class
public InMemoryObjectSet()
: this(Enumerable.Empty<T>()) {
}
public InMemoryObjectSet(IEnumerable<T> entities) {
_set = new HashSet<T>();
foreach (var entity in entities) {
_set.Add(entity);
}
_queryableSet = _set.AsQueryable();
}
public void AddObject(T entity) {
_set.Add(entity);
}
public void Attach(T entity) {
_set.Add(entity);
}
public void DeleteObject(T entity) {
_set.Remove(entity);
}
public void Detach(T entity) {
_set.Remove(entity);
}
public Type ElementType {
get { return _queryableSet.ElementType; }
}
public Expression Expression {
get { return _queryableSet.Expression; }
}
public IQueryProvider Provider {
get { return _queryableSet.Provider; }
}
public IEnumerator<T> GetEnumerator() {
return _set.GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator() {
return GetEnumerator();
}
readonly HashSet<T> _set;
readonly IQueryable<T> _queryableSet;
}
Esta prueba doble delega la mayor parte de su trabajo a un objeto HashSet<T> subyacente. Tenga en cuenta que IObjectSet<T> requiere una restricción genérica que exige T como una clase (un tipo de referencia) y también nos obliga a implementar IQueryable<T>. Es fácil hacer que una colección en memoria aparezca como un IQueryable<T> con el operador LINQ estándar AsQueryable.
Las pruebas
Las pruebas unitarias tradicionales usarán una sola clase de prueba para contener todas las pruebas de todas las acciones de un único controlador MVC. Podemos escribir estas pruebas, o cualquier tipo de prueba unitaria, con las emulaciones en memoria que hemos creado. Sin embargo, para este artículo evitaremos un enfoque de clase de prueba monolítica y, en su lugar, agruparemos nuestras pruebas para centrarnos en una parte específica de la funcionalidad. Por ejemplo, "crear un nuevo empleado" podría ser la funcionalidad que queremos probar, por lo que usaremos una sola clase de prueba para comprobar la acción de controlador único responsable de crear un nuevo empleado.
Para todas estas clases de prueba específicas, necesitamos un código de configuración en común. Por ejemplo, siempre es necesario crear nuestros repositorios en memoria y una unidad de trabajo de emulación. También necesitamos una instancia del controlador de empleados con la unidad de trabajo de emulación insertada. Compartiremos este código de configuración común entre las clases de prueba mediante una clase base.
public class EmployeeControllerTestBase {
public EmployeeControllerTestBase() {
_employeeData = EmployeeObjectMother.CreateEmployees()
.ToList();
_repository = new InMemoryObjectSet<Employee>(_employeeData);
_unitOfWork = new InMemoryUnitOfWork();
_unitOfWork.Employees = _repository;
_controller = new EmployeeController(_unitOfWork);
}
protected IList<Employee> _employeeData;
protected EmployeeController _controller;
protected InMemoryObjectSet<Employee> _repository;
protected InMemoryUnitOfWork _unitOfWork;
}
El "objeto madre" que usamos en la clase base es un patrón común para crear datos de prueba. Un objeto madre contiene métodos de fábrica para crear instancias de entidades de prueba para su uso en varios accesorios de prueba.
public static class EmployeeObjectMother {
public static IEnumerable<Employee> CreateEmployees() {
yield return new Employee() {
Id = 1, Name = "Scott", HireDate=new DateTime(2002, 1, 1)
};
yield return new Employee() {
Id = 2, Name = "Poonam", HireDate=new DateTime(2001, 1, 1)
};
yield return new Employee() {
Id = 3, Name = "Simon", HireDate=new DateTime(2008, 1, 1)
};
}
// ... more fake data for different scenarios
}
Podemos usar EmployeeControllerTestBase como clase base para una serie de accesorios de prueba (vea la figura 3). Cada accesorio de prueba probará una acción de controlador específica. Por ejemplo, un accesorio de prueba se centrará en probar la acción Crear usada durante una solicitud HTTP GET (para mostrar la vista para crear un empleado) y un accesorio diferente se centrará en la acción Create usada en una solicitud HTTP POST (para tomar información enviada por el usuario para crear un empleado). Cada clase derivada solo es responsable de la configuración necesaria en su contexto específico y de proporcionar las aserciones necesarias para comprobar los resultados para su contexto de prueba específico.
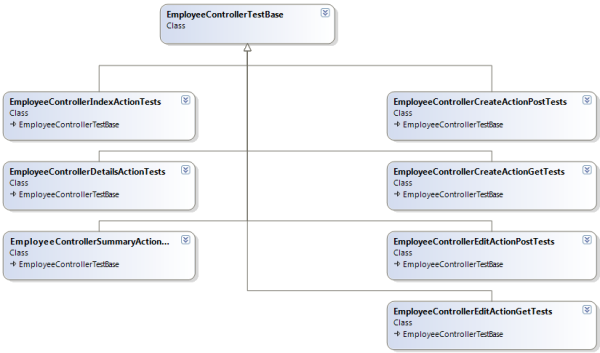
Ilustración 3
La convención de nomenclatura y el estilo de prueba que se presentan aquí no son necesarios para el código comprobable, son solo una de las opciones posibles. En la figura 4 se muestran las pruebas que se ejecutan en el complemento de ejecutor de pruebas de Jet Brains Resharper para Visual Studio 2010.
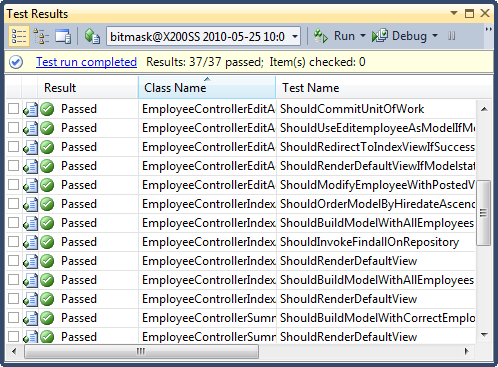
Ilustración 4
Con una clase base para controlar el código de configuración compartido, las pruebas unitarias para cada acción del controlador son pequeñas y fáciles de escribir. Las pruebas se ejecutarán rápidamente (porque estamos realizando operaciones en memoria) y no se deberían producir errores debido a problemas de entorno o infraestructura no relacionados (ya que hemos aislado la unidad en prueba).
[TestClass]
public class EmployeeControllerCreateActionPostTests
: EmployeeControllerTestBase {
[TestMethod]
public void ShouldAddNewEmployeeToRepository() {
_controller.Create(_newEmployee);
Assert.IsTrue(_repository.Contains(_newEmployee));
}
[TestMethod]
public void ShouldCommitUnitOfWork() {
_controller.Create(_newEmployee);
Assert.IsTrue(_unitOfWork.Committed);
}
// ... more tests
Employee _newEmployee = new Employee() {
Name = "NEW EMPLOYEE",
HireDate = new System.DateTime(2010, 1, 1)
};
}
En estas pruebas, la clase base realiza la mayor parte del trabajo de configuración. Recuerde que el constructor de clase base crea el repositorio en memoria, una unidad de trabajo de emulación y una instancia de la clase EmployeeController. La clase de prueba se deriva de esta clase base y se centra en los detalles de probar el método Create. En este caso, los detalles se reducen a los pasos "organización, acción y aserción" que verá en cualquier procedimiento de prueba unitaria:
- Cree un objeto newEmployee para simular datos entrantes.
- Invoque la acción Create de EmployeeController y pase el newEmployee.
- Compruebe que la acción Create genera los resultados esperados (el empleado aparece en el repositorio).
Lo que hemos creado nos permite probar cualquiera de las acciones EmployeeController. Por ejemplo, al escribir pruebas para la acción Index del controlador Employee, podemos heredar de la clase base de prueba para establecer la misma configuración base para nuestras pruebas. De nuevo, la clase base creará el repositorio en memoria, la unidad de trabajo de emulación y una instancia de EmployeeController. Las pruebas de la acción Index solo deben centrarse en invocar la acción Index y probar las cualidades del modelo que devuelve la acción.
[TestClass]
public class EmployeeControllerIndexActionTests
: EmployeeControllerTestBase {
[TestMethod]
public void ShouldBuildModelWithAllEmployees() {
var result = _controller.Index();
var model = result.ViewData.Model
as IEnumerable<Employee>;
Assert.IsTrue(model.Count() == _employeeData.Count);
}
[TestMethod]
public void ShouldOrderModelByHiredateAscending() {
var result = _controller.Index();
var model = result.ViewData.Model
as IEnumerable<Employee>;
Assert.IsTrue(model.SequenceEqual(
_employeeData.OrderBy(e => e.HireDate)));
}
// ...
}
Las pruebas que estamos creando con emulaciones en memoria están orientadas a probar el estado del software. Por ejemplo, al probar la acción Create, queremos inspeccionar el estado del repositorio después de que se ejecute la acción de creación (es decir, ¿el repositorio contiene al nuevo empleado?)
[TestMethod]
public void ShouldAddNewEmployeeToRepository() {
_controller.Create(_newEmployee);
Assert.IsTrue(_repository.Contains(_newEmployee));
}
Más adelante veremos las pruebas basadas en la interacción. Las pruebas basadas en interacciones preguntarán si el código sometido a prueba invocó los métodos adecuados en nuestros objetos y pasó los parámetros correctos. Por ahora, pasaremos a cubrir otro modelo de diseño, la carga diferida.
Carga diligente y carga diferida
En algún momento de la aplicación web de ASP.NET MVC, es posible que deseemos mostrar información de un empleado e incluir las tarjetas de tiempo asociadas de los empleados. Por ejemplo, es posible que tengamos una presentación de resumen de tarjeta de tiempo que muestre el nombre del empleado y el número total de tarjetas de tiempo en el sistema. Hay varios enfoques para implementar esta característica.
Proyección
Un enfoque sencillo para crear el resumen es construir un modelo dedicado a la información que queremos mostrar en la vista. En este escenario, el modelo podría ser similar al siguiente.
public class EmployeeSummaryViewModel {
public string Name { get; set; }
public int TotalTimeCards { get; set; }
}
Tenga en cuenta que EmployeeSummaryViewModel no es una entidad. En otras palabras, no lo queremos conservar en la base de datos. Solo vamos a usar esta clase para ordenar aleatoriamente los datos en la vista de una manera fuertemente tipada. El modelo de vista es como un objeto de transferencia de datos (DTO), porque no contiene ningún comportamiento (sin métodos), sino solo propiedades. Las propiedades contendrán los datos que necesitamos mover. Es fácil crear una instancia de este modelo de vista mediante el operador de proyección estándar LINQ del operador, Select.
public ViewResult Summary(int id) {
var model = _unitOfWork.Employees
.Where(e => e.Id == id)
.Select(e => new EmployeeSummaryViewModel
{
Name = e.Name,
TotalTimeCards = e.TimeCards.Count()
})
.Single();
return View(model);
}
Hay dos características importantes para el código anterior. En primer lugar, el código es fácil de probar porque sigue siendo fácil de observar y aislar. El operador Select funciona igual de bien con nuestras emulaciones en memoria, ya que lo hace en contra de la unidad real de trabajo.
[TestClass]
public class EmployeeControllerSummaryActionTests
: EmployeeControllerTestBase {
[TestMethod]
public void ShouldBuildModelWithCorrectEmployeeSummary() {
var id = 1;
var result = _controller.Summary(id);
var model = result.ViewData.Model as EmployeeSummaryViewModel;
Assert.IsTrue(model.TotalTimeCards == 3);
}
// ...
}
La segunda característica notable es cómo el código permite a EF4 generar una única consulta eficaz para ensamblar la información de empleado y la tarjeta de tiempo conjuntamente. Hemos cargado la información de los empleados y la información de la tarjeta de tiempo en el mismo objeto sin usar ninguna API especial. El código simplemente expresó la información que requiere el uso de operadores LINQ estándar que funcionan con orígenes de datos en memoria, así como con orígenes de datos remotos. EF4 pudo traducir los árboles de expresión generados por la consulta LINQ y el compilador de C# en una sola consulta T-SQL eficaz.
SELECT
[Limit1].[Id] AS [Id],
[Limit1].[Name] AS [Name],
[Limit1].[C1] AS [C1]
FROM (SELECT TOP (2)
[Project1].[Id] AS [Id],
[Project1].[Name] AS [Name],
[Project1].[C1] AS [C1]
FROM (SELECT
[Extent1].[Id] AS [Id],
[Extent1].[Name] AS [Name],
(SELECT COUNT(1) AS [A1]
FROM [dbo].[TimeCards] AS [Extent2]
WHERE [Extent1].[Id] =
[Extent2].[EmployeeTimeCard_TimeCard_Id]) AS [C1]
FROM [dbo].[Employees] AS [Extent1]
WHERE [Extent1].[Id] = @p__linq__0
) AS [Project1]
) AS [Limit1]
Hay otras ocasiones en las que no queremos trabajar con un modelo de vista o un objeto DTO, sino con entidades reales. Cuando sabemos que necesitamos un empleado y las tarjetas de tiempo del empleado, podemos cargar diligentemente los datos relacionados de una manera discreta y eficaz.
Carga diligente explícita
Cuando queremos cargar diligentemente la información de entidad relacionada, necesitamos algún mecanismo para la lógica de negocios (o en este escenario, la lógica de acción del controlador) para expresar su deseo al repositorio. La clase ObjectQuery<T> de EF4 define un método Include para especificar los objetos relacionados que se van a recuperar durante una consulta. Recuerde que ObjectContext de EF4 expone entidades a través de la clase concreta ObjectSet<T> que hereda de ObjectQuery<T>. Si usamos referencias de ObjectSet<T> en nuestra acción del controlador, podríamos escribir el código siguiente para especificar una carga diligente de información de tarjeta de tiempo para cada empleado.
_employees.Include("TimeCards")
.Where(e => e.HireDate.Year > 2009);
Sin embargo, dado que estamos intentando mantener el código comprobable, no estamos exponiendo ObjectSet<T> desde fuera de la unidad real de clase de trabajo. En su lugar, nos basamos en la interfaz IObjectSet<T>, que es más fácil de emular, pero IObjectSet<T> no define un método Include. Lo mejor de LINQ es que podemos crear nuestro propio operador Include.
public static class QueryableExtensions {
public static IQueryable<T> Include<T>
(this IQueryable<T> sequence, string path) {
var objectQuery = sequence as ObjectQuery<T>;
if(objectQuery != null)
{
return objectQuery.Include(path);
}
return sequence;
}
}
Note cómo este operador Include se define como un método de extensión para IQueryable<T> en lugar de IObjectSet<T>. Esto nos da la capacidad de usar el método con una gama más amplia de tipos posibles, incluidos IQueryable<T>, IObjectSet<T>, ObjectQuery<T> y ObjectSet<T>. En caso de que la secuencia subyacente no sea un objeto original ObjectQuery<T> de EF4, no se produce ningún daño y el operador Include es una operación no operativa. Si la secuencia subyacente es un objeto ObjectQuery<T> (o derivado de ObjectQuery<T>), EF4 verá nuestro requisito para obtener datos adicionales y formular la consulta SQL adecuada.
Con este nuevo operador establecido, podemos solicitar explícitamente una carga diligente de información de tarjeta de tiempo del repositorio.
public ViewResult Index() {
var model = _unitOfWork.Employees
.Include("TimeCards")
.OrderBy(e => e.HireDate);
return View(model);
}
Cuando se ejecuta en un objeto ObjectContext real, el código genera la siguiente consulta única. La consulta recopila suficiente información de la base de datos en un viaje para materializar los objetos de empleado y rellenar completamente su propiedad TimeCards.
SELECT
[Project1].[Id] AS [Id],
[Project1].[Name] AS [Name],
[Project1].[HireDate] AS [HireDate],
[Project1].[C1] AS [C1],
[Project1].[Id1] AS [Id1],
[Project1].[Hours] AS [Hours],
[Project1].[EffectiveDate] AS [EffectiveDate],
[Project1].[EmployeeTimeCard_TimeCard_Id] AS [EmployeeTimeCard_TimeCard_Id]
FROM ( SELECT
[Extent1].[Id] AS [Id],
[Extent1].[Name] AS [Name],
[Extent1].[HireDate] AS [HireDate],
[Extent2].[Id] AS [Id1],
[Extent2].[Hours] AS [Hours],
[Extent2].[EffectiveDate] AS [EffectiveDate],
[Extent2].[EmployeeTimeCard_TimeCard_Id] AS
[EmployeeTimeCard_TimeCard_Id],
CASE WHEN ([Extent2].[Id] IS NULL) THEN CAST(NULL AS int)
ELSE 1 END AS [C1]
FROM [dbo].[Employees] AS [Extent1]
LEFT OUTER JOIN [dbo].[TimeCards] AS [Extent2] ON [Extent1].[Id] = [Extent2].[EmployeeTimeCard_TimeCard_Id]
) AS [Project1]
ORDER BY [Project1].[HireDate] ASC,
[Project1].[Id] ASC, [Project1].[C1] ASC
La buena noticia es que el código dentro del método de acción sigue siendo totalmente comprobable. No es necesario proporcionar características adicionales para nuestras emulaciones, con el fin de admitir el operador Include. La mala noticia es que tuvimos que usar el operador Include dentro del código en el que queríamos mantener la ignorancia de persistencia. Este es un ejemplo ilustrativo del tipo de ventajas y desventajas que deberá sopesar al compilar código comprobable. Hay ocasiones en las que es necesario dejar que los problemas potenciales de persistencia salgan de la abstracción del repositorio para cumplir los objetivos de rendimiento.
La alternativa a la carga diligente es la carga diferida. La carga diferida significa que no necesitamos nuestro código empresarial para anunciar explícitamente el requisito de datos asociados. En su lugar, usamos nuestras entidades en la aplicación y, si se necesitan datos adicionales, Entity Framework cargará los datos a petición.
Carga diferida
Es fácil imaginar un escenario en el que no sabemos qué datos necesitará una parte de la lógica de negocios. Es posible que sepamos que la lógica necesita un objeto de empleado, pero podemos expandirnos en diferentes rutas de ejecución en las que algunas de esas rutas requieren información de tarjeta de tiempo del empleado y algunas no. Los escenarios como este son perfectos para la carga implícita diferida porque los datos aparecen mágicamente según sea necesario.
La carga diferida aplica algunos requisitos a nuestros objetos de entidad. Si los POCO tuvieran una verdadera ignorancia de persistencia no se enfrentarían a ningún requisito de la capa de persistencia, pero la verdadera ignorancia de persistencia es prácticamente imposible de lograr. En su lugar, medimos la ignorancia de persistencia en grados relativos. Sería una pena si necesitamos heredar de una clase base orientada a persistencia o usar una colección especializada para lograr la carga diferida en POCO. Afortunadamente, EF4 tiene una solución menos intrusiva.
Virtualmente no detectable
Al usar objetos POCO, EF4 puede generar dinámicamente servidores proxy en tiempo de ejecución para entidades. Estos servidores proxy encapsulan invisiblemente los POCO materializados y proporcionan servicios adicionales al interceptar cada operación de obtención y establecimiento de propiedades para realizar trabajo adicional. Uno de estos servicios es la característica de carga diferida que estamos buscando. Otro servicio es un mecanismo eficaz de seguimiento de cambios que puede registrar cuando el programa cambia los valores de propiedad de una entidad. La lista de cambios se usa en ObjectContext durante el método SaveChanges para conservar las entidades modificadas mediante comandos UPDATE.
Sin embargo, para que estos servidores proxy funcionen, necesitan una manera de enlazar a las operaciones Get y Set de propiedad en una entidad, y los servidores proxy logran este objetivo reemplazando los miembros virtuales. Por lo tanto, si queremos tener una carga diferida implícita y un seguimiento de cambios eficaz, debemos volver a nuestras definiciones de clase POCO y marcar propiedades como virtuales.
public class Employee {
public virtual int Id { get; set; }
public virtual string Name { get; set; }
public virtual DateTime HireDate { get; set; }
public virtual ICollection<TimeCard> TimeCards { get; set; }
}
Todavía podemos decir que la entidad Employee es principalmente ignorante de persistencia. El único requisito es usar miembros virtuales y esto no afecta a la capacidad de prueba del código. No es necesario derivar de ninguna clase base especial o incluso usar una colección especial dedicada a la carga diferida. Como se muestra en el código, cualquier clase que implemente ICollection<T> está disponible para contener entidades relacionadas.
También hay un cambio menor que necesitamos realizar dentro de nuestra unidad de trabajo. La carga diferida se desactiva de forma predeterminada cuando se trabaja directamente con un objeto ObjectContext. Hay una propiedad que podemos establecer en la propiedad ContextOptions para habilitar la carga diferida y podemos establecer esta propiedad dentro de nuestra unidad de trabajo real si queremos habilitar la carga diferida en todas partes.
public class SqlUnitOfWork : IUnitOfWork {
public SqlUnitOfWork() {
// ...
_context = new ObjectContext(connectionString);
_context.ContextOptions.LazyLoadingEnabled = true;
}
// ...
}
Con la carga diferida implícita habilitada, el código de aplicación puede usar un empleado y las tarjetas de tiempo asociadas de los empleados, sin tener en absoluto en cuenta el trabajo necesario para que EF cargue los datos adicionales.
var employee = _unitOfWork.Employees
.Single(e => e.Id == id);
foreach (var card in employee.TimeCards) {
// ...
}
La carga diferida facilita la escritura del código de la aplicación y, con la magia del proxy, el código permanece completamente comprobable. Las emulaciones en memoria de la unidad de trabajo simplemente pueden cargar previamente entidades de emulación con datos asociados cuando sea necesario durante una prueba.
Ahora, centrémonos en la creación de repositorios mediante IObjectSet<T> y examinemos las abstracciones para ocultar todos los signos del marco de persistencia.
Repositorios personalizados
Cuando presentamos por primera vez el patrón de diseño de unidad de trabajo en este artículo, proporcionamos código de ejemplo para mostrar el aspecto típico de la unidad de trabajo. Vamos a volver a presentar esta idea original con el mismo escenario de los empleados y sus tarjeta de tiempo con el que ya hemos trabajado.
public interface IUnitOfWork {
IRepository<Employee> Employees { get; }
IRepository<TimeCard> TimeCards { get; }
void Commit();
}
La principal diferencia entre esta unidad de trabajo y la unidad de trabajo que creamos en la última sección es que esta unidad de trabajo no usa abstracciones del marco EF4 (no hay ningún IObjectSet<T>). IObjectSet<T> funciona bien como una interfaz de repositorio, pero la API que expone podría no alinearse perfectamente con las necesidades de la aplicación. Con este enfoque, representaremos repositorios mediante una abstracción IRepository<T> personalizada.
Muchos desarrolladores que siguen el diseño controlado por pruebas, el diseño controlado por comportamientos y el diseño de metodologías controladas por dominios prefieren el enfoque de IRepository<T> por varias razones. En primer lugar, la interfaz IRepository<T> representa una "capa contra daños". Tal y como describe Eric Evans en su libro Domain Driven Design, una capa contra daños mantiene el código de dominio alejado de las API de infraestructura, como una API de persistencia. En segundo lugar, los desarrolladores pueden crear métodos en el repositorio que satisfagan las necesidades exactas de una aplicación (como se detecta al escribir pruebas). Por ejemplo, es posible que con frecuencia necesitemos buscar una sola entidad mediante un valor de identificador, por lo que podemos agregar un método FindById a la interfaz del repositorio. Nuestra definición de IRepository<T> tendrá un aspecto similar al siguiente.
public interface IRepository<T>
where T : class, IEntity {
IQueryable<T> FindAll();
IQueryable<T> FindWhere(Expression<Func\<T, bool>> predicate);
T FindById(int id);
void Add(T newEntity);
void Remove(T entity);
}
Observe que volveremos a usar una interfaz de IQueryable>T< para exponer colecciones de entidades. IQueryable<T> permite que los árboles de expresiones LINQ fluyan al proveedor EF4 y proporcionen al proveedor una vista holística de la consulta. Una segunda opción sería devolver IEnumerable<T>, lo que significa que el proveedor LINQ de EF4 solo verá las expresiones compiladas dentro del repositorio. Ninguna agrupación, ordenación y proyección realizada fuera del repositorio se añadirá al comando SQL enviado a la base de datos, lo que podría afectar al rendimiento. Por otro lado, un repositorio que devuelve solo resultados IEnumerable<T> nunca le sorprenderá con un nuevo comando SQL. Ambos enfoques funcionarán y seguirán siendo comprobables.
Es sencillo proporcionar una sola implementación de la interfaz IRepository<T> mediante genéricos y la API ObjectContext de EF4.
public class SqlRepository<T> : IRepository<T>
where T : class, IEntity {
public SqlRepository(ObjectContext context) {
_objectSet = context.CreateObjectSet<T>();
}
public IQueryable<T> FindAll() {
return _objectSet;
}
public IQueryable<T> FindWhere(
Expression<Func\<T, bool>> predicate) {
return _objectSet.Where(predicate);
}
public T FindById(int id) {
return _objectSet.Single(o => o.Id == id);
}
public void Add(T newEntity) {
_objectSet.AddObject(newEntity);
}
public void Remove(T entity) {
_objectSet.DeleteObject(entity);
}
protected ObjectSet<T> _objectSet;
}
El enfoque IRepository<T> proporciona un control adicional sobre nuestras consultas porque un cliente tiene que invocar un método para llegar a una entidad. Dentro del método podríamos proporcionar comprobaciones adicionales y operadores LINQ para aplicar restricciones de aplicación. Observe que la interfaz tiene dos restricciones en el parámetro de tipo genérico. La primera restricción es la de clase requerida por ObjectSet<T> y la segunda restricción obliga a nuestras entidades a implementar IEntity, una abstracción creada para la aplicación. La interfaz IEntity obliga a las entidades a tener una propiedad Id legible y, a continuación, podemos usar esta propiedad en el método FindById. IEntity se define con el código siguiente.
public interface IEntity {
int Id { get; }
}
IEntity podría considerarse una pequeña infracción de la ignorancia de persistencia, ya que nuestras entidades son necesarias para implementar esta interfaz. Recuerde que la ignorancia de persistencia tiene ventajas y desventajas. Para muchos, la funcionalidad que ofrece FindById compensará la restricción impuesta por su interfaz. La interfaz no tiene ningún impacto en la capacidad de prueba.
La creación de instancias de un IRepository<T> activo requiere un ObjectContext de EF4, por lo que una unidad de trabajo concreta debe administrar la creación de instancias.
public class SqlUnitOfWork : IUnitOfWork {
public SqlUnitOfWork() {
var connectionString =
ConfigurationManager
.ConnectionStrings[ConnectionStringName]
.ConnectionString;
_context = new ObjectContext(connectionString);
_context.ContextOptions.LazyLoadingEnabled = true;
}
public IRepository<Employee> Employees {
get {
if (_employees == null) {
_employees = new SqlRepository<Employee>(_context);
}
return _employees;
}
}
public IRepository<TimeCard> TimeCards {
get {
if (_timeCards == null) {
_timeCards = new SqlRepository<TimeCard>(_context);
}
return _timeCards;
}
}
public void Commit() {
_context.SaveChanges();
}
SqlRepository<Employee> _employees = null;
SqlRepository<TimeCard> _timeCards = null;
readonly ObjectContext _context;
const string ConnectionStringName = "EmployeeDataModelContainer";
}
Uso del repositorio personalizado
El uso de nuestro repositorio personalizado no es significativamente diferente del uso del repositorio basado en IObjectSet<T>. En lugar de aplicar operadores LINQ directamente a una propiedad, primero es necesario invocar uno de los métodos del repositorio para obtener una referencia de IQueryable<T>.
public ViewResult Index() {
var model = _repository.FindAll()
.Include("TimeCards")
.OrderBy(e => e.HireDate);
return View(model);
}
Observe que el operador Include personalizado implementado anteriormente funcionará sin cambios. El método FindById del repositorio quita la lógica duplicada de las acciones que intentan recuperar una sola entidad.
public ViewResult Details(int id) {
var model = _repository.FindById(id);
return View(model);
}
No hay ninguna diferencia significativa en la capacidad de prueba de los dos enfoques que hemos examinado. Podríamos proporcionar implementaciones de emulaciones de IRepository<T> mediante la creación de clases concretas respaldadas por HashSet<Employee>, igual que lo que hicimos en la última sección. Sin embargo, algunos desarrolladores prefieren usar objetos ficticios y marcos de objetos ficticios en lugar de crear emulaciones. Examinaremos el uso de objetos ficticios para probar nuestra implementación y analizaremos las diferencias entre los objetos ficticios y las emulaciones en la sección siguiente.
Pruebas con objetos ficticios
Hay diferentes enfoques para crear lo que Martin Fowler llama un "doble de prueba". Un doble de prueba es como un doble en el mundo del cine: un objeto que se crea para ocupar el lugar de objetos de producción reales durante las pruebas. Los repositorios en memoria que hemos creado son dobles de prueba para los repositorios que hablan con SQL Server. Hemos visto cómo usar estos dobles de prueba durante las pruebas unitarias para aislar el código y que las pruebas se ejecuten rápidamente.
Los dobles de prueba que hemos creado tienen implementaciones reales y funcionales. En segundo plano, cada uno almacena una colección concreta de objetos, y agregará y quitará objetos de esta colección a medida que manipulamos el repositorio durante una prueba. A algunos desarrolladores les gusta compilar sus pruebas de esta manera: con implementaciones reales de código y trabajo. Estas dobles de prueba son lo que llamamos emulaciones. Tienen implementaciones de trabajo, pero no son suficientes para su uso en producción. El repositorio de emulación no escribe realmente en la base de datos. El servidor SMTP de emulación no envía realmente un mensaje de correo electrónico a través de la red.
Objetos ficticios frente a emulaciones
Hay otro tipo de doble de prueba conocido como ficticio. Mientras que las emulaciones tienen implementaciones de trabajo, los objetos ficticios no incluyen ninguna implementación. Con la ayuda de un marco de objetos ficticios, creamos estos objetos ficticios en tiempo de ejecución y los usamos como dobles de prueba. En esta sección usaremos el marco de trabajo ficticio de código abierto Moq. Este es un ejemplo sencillo del uso de Moq para crear dinámicamente un doble de prueba para un repositorio de empleados.
Mock<IRepository<Employee>> mock =
new Mock<IRepository<Employee>>();
IRepository<Employee> repository = mock.Object;
repository.Add(new Employee());
var employee = repository.FindById(1);
Pedimos a Moq una implementación de IRepository<Employee> y este crea una dinámicamente. Podemos obtener al objeto que implementa IRepository<Employee> accediendo a la propiedad Object del objeto Mock<T>. Es este objeto interno lo que podemos pasar a nuestros controladores, que no sabrán si se trata de una prueba doble o del repositorio real. Podemos invocar métodos en el objeto igual que invocaríamos métodos en un objeto con una implementación real.
En este momento, puede que se pregunte qué hará el repositorio ficticio al invocar el método Add. Puesto que no hay ninguna implementación detrás del objeto ficticio, Add no hace nada. No hay ninguna colección concreta en segundo plano como tuvimos con las emulaciones que escribimos, por lo que el empleado se descarta. ¿Qué ocurre con el valor devuelto de FindById? En este caso, el objeto ficticio hace lo único que puede hacer: devolver un valor predeterminado. Puesto que se devuelve un tipo de referencia (un empleado), el valor devuelto es un valor NULL.
Hasta ahora puede parecerle que los objetos ficticios no valen para mucho. Sin embargo, tienen dos características más de las que no hemos hablado. En primer lugar, el marco Moq registra todas las llamadas realizadas en el objeto ficticio. Más adelante en el código podemos preguntar a Moq si alguien invocó el método Add o si alguien invocó el método FindById. Veremos más adelante cómo podemos usar esta característica de grabación de "caja negra" en las pruebas.
La segunda característica interesante es cómo podemos usar Moq para programar un objeto ficticio con expectativas. Una expectativa indica al objeto ficticio cómo responder a cualquier interacción determinada. Por ejemplo, podemos programar una expectativa en nuestro objeto ficticio y decirle que devuelva un objeto de empleado cuando alguien invoca FindById. El marco Moq usa una API de instalación y expresiones lambda para programar estas expectativas.
[TestMethod]
public void MockSample() {
Mock<IRepository<Employee>> mock =
new Mock<IRepository<Employee>>();
mock.Setup(m => m.FindById(5))
.Returns(new Employee {Id = 5});
IRepository<Employee> repository = mock.Object;
var employee = repository.FindById(5);
Assert.IsTrue(employee.Id == 5);
}
En este ejemplo, pedimos a Moq que compile dinámicamente un repositorio y, a continuación, programamos el repositorio con una expectativa. La expectativa indica al objeto ficticio que devuelva un nuevo objeto de empleado con un valor Id de 5 cuando alguien invoca el método FindById pasando un valor de 5. Esta prueba se supera y no es necesario crear una implementación completa para IRepository<T> de emulación.
Volvamos a revisar las pruebas que hemos escrito anteriormente y a modificarlas para usar objetos ficticios en lugar de emulaciones. Al igual que antes, usaremos una clase base para configurar las partes comunes de la infraestructura que necesitamos para todas las pruebas del controlador.
public class EmployeeControllerTestBase {
public EmployeeControllerTestBase() {
_employeeData = EmployeeObjectMother.CreateEmployees()
.AsQueryable();
_repository = new Mock<IRepository<Employee>>();
_unitOfWork = new Mock<IUnitOfWork>();
_unitOfWork.Setup(u => u.Employees)
.Returns(_repository.Object);
_controller = new EmployeeController(_unitOfWork.Object);
}
protected IQueryable<Employee> _employeeData;
protected Mock<IUnitOfWork> _unitOfWork;
protected EmployeeController _controller;
protected Mock<IRepository<Employee>> _repository;
}
El código de instalación sigue siendo el mismo. En lugar de usar emulaciones, usaremos Moq para construir objetos ficticios. La clase base organiza la unidad de trabajo ficticia para devolver un repositorio ficticio cuando el código invoca la propiedad Employees. El resto de la configuración ficticia tendrá lugar dentro de los accesorios de prueba dedicados a cada escenario específico. Por ejemplo, el accesorio de prueba de la acción Index configurará el repositorio ficticio para devolver una lista de empleados cuando la acción invoca el método FindAll del repositorio ficticio.
[TestClass]
public class EmployeeControllerIndexActionTests
: EmployeeControllerTestBase {
public EmployeeControllerIndexActionTests() {
_repository.Setup(r => r.FindAll())
.Returns(_employeeData);
}
// .. tests
[TestMethod]
public void ShouldBuildModelWithAllEmployees() {
var result = _controller.Index();
var model = result.ViewData.Model
as IEnumerable<Employee>;
Assert.IsTrue(model.Count() == _employeeData.Count());
}
// .. and more tests
}
Excepto para las expectativas, nuestras pruebas son similares a las que teníamos antes. Sin embargo, con la capacidad de grabación del marco ficticio podemos abordar las pruebas desde un ángulo diferente. Veremos esta nueva perspectiva en la sección siguiente.
Estado frente a pruebas de interacción
Puede usar diferentes técnicas para probar software con objetos ficticios. Un enfoque consiste en usar pruebas basadas en estado, que es lo que hemos hecho en este documento hasta ahora. Las pruebas basadas en estado realizan aserciones sobre el estado del software. En la última prueba se invocó un método de acción en el controlador y se realizó una aserción sobre el modelo que debe compilar. Estos son algunos otros ejemplos de estado de prueba:
- Compruebe que el repositorio contiene el nuevo objeto de empleado después de ejecutar Create.
- Compruebe que el modelo contiene una lista de todos los empleados después de que se ejecute Index.
- Compruebe que el repositorio no contiene un empleado determinado después de que se ejecute Delete.
Otro enfoque que verá con objetos ficticios es comprobar las interacciones. Aunque las pruebas basadas en estado realizan aserciones sobre el estado de los objetos, las pruebas basadas en interacciones realizan aserciones sobre cómo interactúan los objetos. Por ejemplo:
- Compruebe que el controlador invoca el método Add del repositorio cuando se ejecuta Create.
- Compruebe que el controlador invoca el método FindAll del repositorio cuando se ejecuta Index.
- Compruebe que el controlador invoca la unidad de trabajo del método Commit para guardar los cambios cuando se ejecuta Edit.
Las pruebas de interacción a menudo requieren menos datos de prueba, ya que no estamos curioseando dentro de colecciones y comprobando recuentos. Por ejemplo, si sabemos que la acción Details invoca un método FindById del repositorio con el valor correcto, es probable que la acción se comporte correctamente. Podemos comprobar este comportamiento sin configurar ningún dato de prueba que se devuelva desde FindById.
[TestClass]
public class EmployeeControllerDetailsActionTests
: EmployeeControllerTestBase {
// ...
[TestMethod]
public void ShouldInvokeRepositoryToFindEmployee() {
var result = _controller.Details(_detailsId);
_repository.Verify(r => r.FindById(_detailsId));
}
int _detailsId = 1;
}
La única configuración necesaria en el accesorio de prueba anterior es la configuración proporcionada por la clase base. Al invocar la acción del controlador, Moq registrará las interacciones con el repositorio ficticio. Con la API Verify de Moq, podemos preguntar a Moq si el controlador invocó FindById con el valor de identificador adecuado. Si el controlador no invocó el método o invocó el método con un valor de parámetro inesperado, el método Verify producirá una excepción y se producirá un error en la prueba.
Este es otro ejemplo para comprobar que la acción Create invoca Commit en la unidad de trabajo actual.
[TestMethod]
public void ShouldCommitUnitOfWork() {
_controller.Create(_newEmployee);
_unitOfWork.Verify(u => u.Commit());
}
Un riesgo con las pruebas de interacción es la tendencia a especificar en exceso las interacciones. La capacidad del objeto ficticio para registrar y comprobar cada interacción con el objeto ficticio no significa que la prueba intente comprobar cada interacción. Algunas interacciones son detalles de implementación y solo debe comprobar las interacciones necesarias para satisfacer la prueba actual.
La elección entre objetos ficticios o emulaciones depende en gran medida del sistema que está probando y de sus preferencias personales (o las de su equipo). Los objetos ficticios pueden reducir drásticamente la cantidad de código que necesita para implementar dobles de prueba, pero puede haber miembros de su equipo que no se sientan cómodos programando expectativas y comprobando interacciones.
Conclusiones
En este informe, hemos mostrado varios enfoques para crear código comprobable al usar ADO.NET Entity Framework para la persistencia de datos. Podemos aprovechar abstracciones integradas como IObjectSet<T> o crear nuestras propias abstracciones como IRepository<T>. En ambos casos, la compatibilidad con POCO en ADO.NET Entity Framework 4.0 permite que los consumidores de estas abstracciones sigan siendo ignorantes de persistencia y altamente comprobables. Otras características de EF4, como la carga diferida implícita, permiten que el código del servicio de aplicaciones y empresariales funcione sin preocuparse por los detalles de un almacén de datos relacional. Por último, las abstracciones que creamos son fáciles de realizar de forma ficticia o con emulaciones dentro de las pruebas unitarias, y podemos usar estos dobles de prueba para lograr pruebas rápidas de ejecución que son altamente aisladas y fiables.
Recursos adicionales
- Martin Fowler, Catalog of Patterns de Patterns of Enterprise Application Architecture
- Griffin Caprio, "Dependency Injection"
- Data Programmability Blog, "Walkthrough: Test Driven Development with the Entity Framework 4.0".
- Data Programmability Blog, "Using Repository and Unit of Work patterns with Entity Framework 4.0"
- Aaron Jensen, "Introducing Machine Specifications"
- Eric Lee, "BDD with MSTest"
- Eric Evans, "Domain Driven Design"
- Martin Fowler, "Mocks Aren't Stubs"
- Martin Fowler, "Test Double"
- Moq
Biografía
Scott Allen es miembro del personal técnico de Pluralsight y fundador de OdeToCode.com. En sus 15 años de experiencia con el desarrollo de software comercial, Scott ha trabajado en soluciones para todo, desde dispositivos insertados de 8 bits hasta aplicaciones web de ASP.NET altamente escalables. Puede comunicarse con Scott en su blog en OdeToCode o en Twitter en https://twitter.com/OdeToCode.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.