Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: 2016
2016  2019 Subscription Edition
2019 Subscription Edition
Con cada nueva versión de Exchange Server para nuestros clientes locales, actualizamos nuestra arquitectura preferida y analizamos los cambios que nos gustaría que nuestros clientes tuvieran en cuenta. Exchange Server 2013 nos trajo la primera de las arquitecturas preferidas en la historia moderna de Exchange y luego se siguió con una actualización para Exchange Server 2016 proporcionando refinamientos para los cambios que se produjeron con la versión de 2016. Con esta actualización de Exchange Server 2019, recorreremos en iteración la pa anterior para aprovechar las nuevas tecnologías y mejoras.
La arquitectura preferida
La PA es la recomendación de procedimientos recomendados del equipo de ingeniería de Exchange Server para lo que creemos que es la mejor arquitectura de implementación para Exchange Server 2019 en un entorno local.
Aunque Exchange 2019 ofrece una amplia variedad de opciones arquitectónicas para implementaciones locales, la arquitectura que se describe aquí es la más examinada. Aunque hay otras arquitecturas de implementación admitidas, no son nuestra práctica recomendada.
Seguir la PA ayuda a los clientes a convertirse en miembros de una comunidad de organizaciones con implementaciones Exchange Server similares. Esta estrategia permite un uso compartido de conocimientos más fácil y proporciona una respuesta más rápida a circunstancias imprevesas. Nuestra propia organización de soporte técnico es consciente del aspecto que debe tener una implementación de PA Exchange Server e impide que pase largos ciclos aprendiendo y entendiendo el entorno altamente personalizado de un cliente antes de trabajar con ellos para una resolución de casos de soporte técnico.
El PA está diseñado teniendo en cuenta varios requisitos empresariales, como el requisito de que la arquitectura sea capaz de:
Incluir alta disponibilidad en el centro de datos y resistencia del sitio entre centros de datos
Admite varias copias de cada base de datos, lo que permite una activación rápida.
Reducir el costo de la infraestructura de mensajería
Aumentar la disponibilidad mediante la optimización de los dominios de error y la reducción de la complejidad
La naturaleza prescriptiva específica de la PA significa que no todos los clientes podrán implementarlo palabra por palabra. Por ejemplo, no todos nuestros clientes tienen varios centros de datos. Algunos de nuestros clientes pueden tener diferentes requisitos empresariales o directivas internas a las que deben cumplir y que necesitan una arquitectura de implementación diferente. Si se divide en esas categorías y desea implementar Exchange local, todavía hay ventajas de cumplir lo más estrechamente posible con la PA y desviarse solo cuando sus requisitos o directivas le obligan a diferir. Como alternativa, siempre puede tener en cuenta Microsoft 365 o Office 365 donde ya no debe implementar ni administrar un gran número de servidores.
La PA quita la complejidad y la redundancia cuando sea necesario para impulsar la arquitectura a un modelo de recuperación predecible: cuando se produce un error, se activa otra copia de la base de datos afectada.
La PA abarca las cuatro áreas de enfoque siguientes:
Para Exchange Server 2019, no hay cambios en tres de las cuatro categorías de la arquitectura preferida de Exchange Server 2016. Las áreas de diseño de espacios de nombres, diseño de Datacenter y diseño de DAG no reciben cambios importantes. Nos hemos mostrado satisfechos con las implementaciones de clientes que han seguido de cerca la pa de Exchange Server 2016 y no vemos ninguna necesidad de desviarse de las recomendaciones en esas áreas.
Los cambios más notables en la pa de Exchange Server 2019 se centran en el área de diseño del servidor debido a algunas tecnologías nuevas y emocionantes.
Diseño del espacio de nombres
En los artículos Principios de planeación y equilibrio de carga de espacios de nombres para Exchange Server 2016, Ross Smith IV describió las distintas opciones de configuración que estaban disponibles con Exchange 2016 y estos conceptos siguen aplicándose para Exchange Server 2019. Para el espacio de nombres, las opciones son implementar un espacio de nombres enlazado (con una preferencia para que los usuarios funcionen fuera de un centro de datos específico) o un espacio de nombres sin enlazar (que los usuarios se conecten a cualquier centro de datos sin preferencias).
El enfoque recomendado es usar el modelo sin enlazar, implementando un único espacio de nombres de Exchange por protocolo de cliente para el par de centros de datos resistentes al sitio (donde se supone que cada centro de datos representa su propio sitio de Active Directory; vea más detalles sobre esto a continuación). Por ejemplo:
Para el servicio de detección automática: autodiscover.contoso.com
Para clientes HTTP: mail.contoso.com
Para clientes IMAP: imap.contoso.com
Para clientes SMTP: smtp.contoso.com
Cada espacio de nombres de Exchange tiene un equilibrio de carga entre ambos centros de datos en una configuración de nivel 7 que no usa afinidad de sesión, lo que da lugar a que el 50 % del tráfico se proxye entre los centros de datos. El tráfico se distribuye igualmente entre los centros de datos en el par resistente al sitio, a través de DNS round robin, DNS geográfico u otras soluciones similares. Desde nuestra perspectiva, la solución más sencilla es la menos compleja y fácil de administrar, por lo que nuestra recomendación es usar DNS round robin.
Una precaución que tenemos para los clientes es asegurarse de asignar un valor de TTL (tiempo de vida) bajo para cualquier registro DNS asociado a la arquitectura de Exchange. Si se produce una interrupción completa del centro de datos cuando se usa DNS round robin, debe mantener la capacidad de actualizar rápidamente los registros DNS. Tendrá que quitar las direcciones IP del centro de datos sin conexión para que no se devuelvan para las consultas DNS. Por ejemplo, si los registros DNS tienen un valor de TTL más largo de 24 horas, las cachés DNS de nivel inferior pueden tardar hasta un día en actualizarse correctamente. Si no realiza este paso, es posible que algunos clientes no puedan realizar correctamente la transición a las direcciones IP que todavía están disponibles en el centro de datos restante. No olvide volver a agregar las direcciones IP a los registros DNS cuando el centro de datos anteriormente sin conexión se recupere y esté listo para hospedar los servicios una vez más.
La afinidad del centro de datos es necesaria para las granjas de Office Online Server, por lo que se implementa un espacio de nombres por centro de datos con el equilibrador de carga que usa la capa 7 y mantiene la afinidad de sesión mediante persistencia basada en cookies.
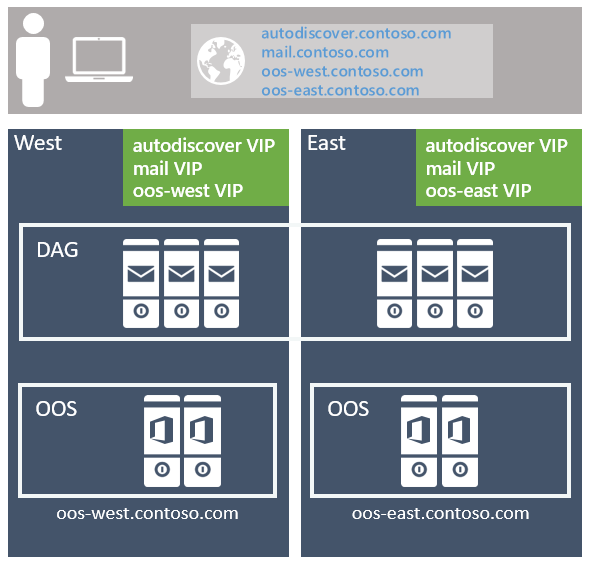
Si tiene varios pares de centros de datos resistentes al sitio en su entorno, deberá decidir si desea tener un único espacio de nombres en todo el mundo o si desea controlar el tráfico a cada centro de datos específico mediante espacios de nombres regionales. La decisión depende de la topología de red y del costo asociado con el uso de un modelo sin enlazar; Por ejemplo, si tiene centros de datos ubicados en Norteamérica y Sudáfrica, es posible que el vínculo de red entre estas regiones no solo sea costoso, sino que también tenga una latencia alta, lo que puede presentar problemas operativos y de dolor del usuario. En ese caso, tiene sentido implementar un modelo enlazado con un espacio de nombres independiente para cada región. Sin embargo, opciones como DNS geográfico le ofrecen la capacidad de implementar un único espacio de nombres unificado, incluso cuando tiene vínculos de red costosos; geo-DNS permite que los usuarios se dirijan al centro de datos más cercano en función de la dirección IP de su cliente.
Diseño del par de centros de datos resistentes al sitio
Para lograr una arquitectura resistente al sitio y de alta disponibilidad, debe tener dos o más centros de datos que estén bien conectados (idealmente, quiere una latencia de red de ida y vuelta baja; de lo contrario, la replicación y la experiencia del cliente se ven afectadas negativamente). Además, los centros de datos deben conectarse a través de rutas de acceso de red redundantes proporcionadas por diferentes operadores operativos.
Aunque se admite la ampliación de un sitio de Active Directory entre varios centros de datos, para la PA se recomienda que cada centro de datos sea su propio sitio de Active Directory. Hay dos motivos:
La resistencia del sitio de transporte a través de la redundancia de Shadow en Exchange Server y Safety Net en Exchange Server solo se puede lograr cuando el DAG tiene miembros ubicados en más de un sitio de Active Directory.
Active Directory ha publicado instrucciones que indican que las subredes deben colocarse en diferentes sitios de Active Directory cuando la latencia de ida y vuelta es mayor que 10 ms entre las subredes.
Diseño del servidor
En la PA, todos los servidores son servidores físicos y usan almacenamiento conectado localmente. El hardware físico se implementa en lugar del hardware virtualizado por dos motivos:
Los servidores se escalan para usar el 80 % de los recursos durante el modo de peor error.
La virtualización incluye una ligera penalización del rendimiento y agrega una capa adicional de administración y complejidad, lo que introduce modos de recuperación adicionales que no agregan valor, especialmente porque Exchange Server proporciona de forma nativa la misma funcionalidad.
Servidores de mercancías
Las plataformas de servidor de mercancías se usan en la PA. Las plataformas de productos básicos actuales son e incluyen:
2U, servidores de doble socket con hasta 48 núcleos de procesador físico (un aumento de 24 núcleos en Exchange 2016)
Hasta 256 GB de memoria (un aumento de 192 GB en Exchange 2016)
Un controlador de caché de escritura con respaldo de batería
12 o más bahías de unidad dentro del chasis del servidor
La capacidad de combinar el almacenamiento de bandeja rotativa tradicional (HDD) y el almacenamiento de estado sólido (SSD) dentro del mismo chasis.
Teoría de escala
Es importante tener en cuenta, aunque hayamos aumentado la capacidad de procesador y memoria permitida en Exchange Server 2019, la recomendación de Exchange Server PG sigue siendo escalar horizontalmente en lugar de subir. El escalado horizontal frente al escalado vertical significa que preferiríamos implementar un mayor número de servidores con un número ligeramente menor de recursos por servidor en lugar de un número menor de servidores densos que usan el máximo de recursos y se rellenan con un gran número de buzones. Al localizar un número razonable de buzones dentro de un servidor, se reduce el impacto de cualquier interrupción planeada o no planeada y se reduce el riesgo de detectar otros cuellos de botella del sistema.
Un aumento de los recursos del sistema no debería dar lugar a la suposición de que verá mejoras de rendimiento lineales en Exchange Server 2019 mediante el uso del máximo de recursos permitidos al compararlo con los recursos máximos permitidos de Exchange 2016. Cada nueva versión de Exchange trae nuevos procesos y actualizaciones que, a su vez, dificultan la comparación de una versión actual con una versión anterior. Siga todas y cada una de las instrucciones de ajuste de tamaño de Microsoft al determinar el diseño del servidor.
Almacenamiento
Las bahías de unidad adicionales se pueden asociar directamente por servidor en función del número de buzones, el tamaño del buzón y la escalabilidad de recursos del servidor.
Cada servidor contiene un único par de discos RAID1 para el sistema operativo, los archivos binarios de Exchange, los registros de protocolo/cliente y la base de datos de transporte.
El almacenamiento restante se configura como JBOD (solo un montón de discos). Tenga en cuenta que algunos controladores de almacenamiento de hardware pueden requerir que cada disco se configure como un grupo RAID0 de disco único para que se use el almacenamiento en caché de escritura. Consulte con el fabricante de hardware para confirmar la configuración adecuada del sistema que garantiza que se usará la caché de escritura.
La novedad de la PA de Exchange Server 2019 es la recomendación de tener dos clases de almacenamiento para todo lo que no se encuentra en el par de discos RAID1 mencionado anteriormente.
Clase de almacenamiento tradicional
Esta clase de almacenamiento contiene Exchange Server archivos de base de datos y archivos de registro de transacciones Exchange Server. Estos discos son discos SCSI conectados en serie (SAS) de gran capacidad a 7,2 K RPM. Aunque los discos SATA también están disponibles, observamos una mejor E/S y una tasa de errores anualizada menor mediante el equivalente de SAS.
Para garantizar que la capacidad y la E/S de cada disco se usan de la manera más eficaz posible, se implementan hasta cuatro copias de base de datos por disco. El diseño de copia en tiempo de ejecución normal garantiza que no haya más de una sola copia de base de datos activa por disco.
Al menos un disco del grupo de discos de almacenamiento tradicional se reserva como reserva activa. AutoReseed está habilitado y restaura rápidamente la redundancia de la base de datos después de un error de disco activando la reserva activa e iniciando las reinserciones de copia de base de datos.
Clase de almacenamiento de estado sólido
Esta clase de almacenamiento contiene los nuevos archivos de base de datos de MetaCache (MCDB) de Exchange 2019. Estas unidades de estado sólido pueden presentar diferentes factores de forma, como, entre otros, las unidades tradicionales conectadas a SAS de 2,5"/3,5" o pcIe M.2.
Los clientes deben esperar implementar aproximadamente entre un 5 y un 10 % de almacenamiento adicional como almacenamiento de estado sólido. Por ejemplo, si se espera que un único servidor contenga 28 TB de archivos de base de datos de buzón de correo en el almacenamiento tradicional, también se recomienda un almacenamiento adicional de 1,4-2,8 TB de almacenamiento de estado sólido como almacenamiento adicional para el mismo servidor.
Los discos de estado sólido y tradicional deben implementarse en una proporción de 3:1 siempre que sea posible. Por cada tres discos tradicionales dentro del servidor, se implementará un único disco de estado sólido. Estos discos de estado sólido almacenarán los MCDB para todos los DB dentro de los tres discos tradicionales asociados. Esta recomendación limita el dominio de error que un error de unidad de estado sólido puede imponer en un sistema. Cuando se produce un error en una SSD, Exchange 2019 conmutará por error todas las copias de base de datos que usan ese SSD para su MCDB en otro nodo DAG con recursos de MCDB correctos para la base de datos afectada. La limitación del número de conmutaciones por error de base de datos reduce la posibilidad de afectar a los usuarios si muchas más bases de datos comparten un número menor de unidades de estado sólido.
Si hay un error de unidad de estado sólido en el servicio de alta disponibilidad de Exchange, intentará montar las bases de datos afectadas en distintos nodos DAG donde todavía exista un MCDB correcto para cada base de datos afectada. Si por alguna razón no existen MCDB en buen estado para una de las bases de datos afectadas, los servicios de alta disponibilidad de Exchange dejarán la copia de la base de datos afectada local en ejecución sin las ventajas de rendimiento de MCDB.
Por ejemplo, si un cliente implementara un sistema capaz de contener 20 unidades, puede tener un diseño similar al siguiente.
2 HDD para reflejo del sistema operativo, archivos binarios de Exchange y base de datos de transporte
12 HDD para el almacenamiento de bases de datos de Exchange
1 HDD como reserva de AutoReseed
4 SSD para MCDB de Exchange que proporcionan entre el 5 y el 10 % de la capacidad de almacenamiento acumulado de la base de datos.
Opcionalmente, un cliente puede optar por agregar un SSD de reserva o una segunda unidad AutoReseed.
Esta configuración se puede visualizar mediante el diagrama siguiente:
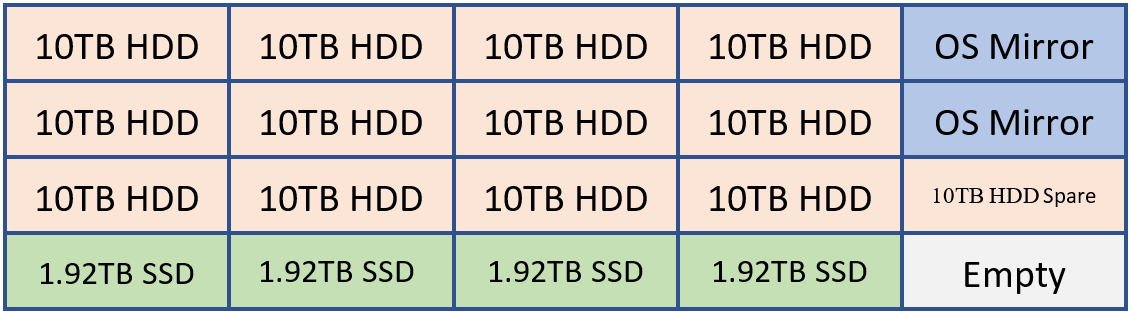
En el ejemplo anterior, tenemos 120 TB de almacenamiento de base de datos de Exchange y 7,68 TB de almacenamiento MCDB que es aproximadamente el 6,4 % del espacio de almacenamiento de base de datos tradicional. Con esta cantidad de almacenamiento mcbd, estamos perfectamente alineados dentro de la guía del 5 al 10 %. Cada una de las unidades de 10 TB contendrá cuatro copias de base de datos y cada unidad MCDB contendrá 12 MCDB.
Configuración de almacenamiento común
Tanto si son tradicionales como de estado sólido, todos los discos que hospedan datos de Exchange tienen el formato ReFS (con la característica de integridad deshabilitada) y el DAG está configurado de forma que AutoReseed dé formato a los discos con ReFS:
Set-DatabaseAvailabilityGroup -Identity <DAGIdentity> -FileSystem ReFS
BitLocker se usa para cifrar cada disco, lo que proporciona cifrado de datos en reposo y mitiga los problemas relacionados con el robo de datos o el reemplazo de disco. Para obtener más información, consulte Habilitación de BitLocker en servidores exchange.
Diseño del grupo de disponibilidad de base de datos
Dentro de cada par de centros de datos resistentes al sitio, tendrá uno o más DAG. No se recomienda ampliar un DAG en más de dos centros de datos.
Configuración de DAG
Al igual que con el modelo de espacio de nombres, cada DAG dentro del par de centros de datos resistentes al sitio funciona en un modelo sin enlazar con copias activas distribuidas por igual entre todos los servidores del DAG. Este modelo:
Garantiza que la pila completa de servicios de cada miembro del DAG (conectividad de cliente, canalización de replicación, transporte, etc.) se valida durante las operaciones normales.
Distribuye la carga entre tantos servidores como sea posible durante un escenario de error, lo que solo aumenta incrementalmente el uso de recursos entre los miembros restantes del DAG.
Cada centro de datos es simétrico, con un número igual de miembros de DAG en cada centro de datos. Esto significa que cada DAG tiene un número par de servidores y usa un servidor testigo para el mantenimiento de cuórum.
El DAG es el bloque de creación fundamental de Exchange 2019. Con respecto al tamaño del DAG, un DAG con un mayor número de nodos miembros participantes proporciona más redundancia y recursos. Dentro de la PA, el objetivo es implementar DAG con un mayor número de nodos miembros, normalmente empezando con un DAG de ocho miembros y aumentando el número de servidores según sea necesario para cumplir sus requisitos. Solo debe crear nuevos DAG cuando la escalabilidad presente preocupaciones sobre el diseño de copia de base de datos existente.
Diseño de red de DAG
La PA usa una única interfaz de red sin equipo para la conectividad de cliente y la replicación de datos. Una única interfaz de red es todo lo que se necesita porque, en última instancia, nuestro objetivo es lograr un modelo de recuperación estándar independientemente del error: si se produce un error de servidor o si se produce un error de red, el resultado es el mismo: se activa una copia de base de datos en otro servidor dentro del DAG. Este cambio arquitectónico simplifica la pila de red y evita la necesidad de eliminar manualmente la conversación cruzada de latidos.
Selección de ubicación del servidor testigo
La ubicación del servidor testigo determina si la arquitectura puede proporcionar funcionalidades automáticas de conmutación por error del centro de datos o si necesitará una activación manual para habilitar el servicio si se produce un error en el sitio.
Si su organización tiene una tercera ubicación con una infraestructura de red aislada de errores de red que afectan al par de centros de datos resistentes al sitio en el que se implementa el DAG, la recomendación es implementar el servidor testigo del DAG en esa tercera ubicación. Esta configuración proporciona al DAG la capacidad de conmutar automáticamente por error las bases de datos al otro centro de datos en respuesta a un evento de error de nivel de centro de datos, independientemente de qué centro de datos tenga la interrupción.
Si su organización no tiene una tercera ubicación, considere la posibilidad de colocar el testigo del servidor en Azure; como alternativa, coloque el servidor testigo en uno de los centros de datos dentro del par de centros de datos resistentes al sitio. Si tiene varios DAG dentro del par de centros de datos resistentes al sitio, coloque el servidor testigo para todos los DAG en el mismo centro de datos (normalmente, el centro de datos donde se encuentran físicamente la mayoría de los usuarios). Además, asegúrese de que el Administrador activo principal (PAM) de cada DAG también se encuentra en el mismo centro de datos.
Exchange Server 2019 y todas las versiones anteriores no admiten el uso de la característica Testigo en la nube que se introdujo por primera vez en Windows Server 2016 clúster de conmutación por error.
Resiliencia de datos
La resistencia de los datos se logra mediante la implementación de varias copias de base de datos. En la PA, las copias de base de datos se distribuyen entre el par de centros de datos resistentes al sitio, lo que garantiza que los datos del buzón estén protegidos contra errores de software, hardware e incluso del centro de datos.
Cada base de datos tiene cuatro copias, con dos copias en cada centro de datos, lo que significa que, como mínimo, la PA requiere cuatro servidores. De estas cuatro copias, tres de ellas están configuradas como de alta disponibilidad. La cuarta copia (la copia con el número de preferencia de activación más alto) se configura como una copia de base de datos retrasada. Debido al diseño del servidor, cada copia de una base de datos está aislada de sus otras copias, lo que reduce los dominios de error y aumenta la disponibilidad general de la solución, como se describe en DAG: Más allá de la "A".
El propósito de la copia de base de datos retrasada es proporcionar un mecanismo de recuperación para el raro evento de daños lógicos catastróficos en todo el sistema. No está pensado para la recuperación individual del buzón de correo o la recuperación de elementos de buzón de correo.
La copia de base de datos retrasada se configura con un ReplayLagTime de siete días. Además, replay Lag Manager también está habilitado para proporcionar reproducción dinámica de archivos de registro para copias retrasadas cuando la disponibilidad está en peligro debido a la pérdida de copias no retrasadas.
Al usar la copia de base de datos retrasada de esta manera, es importante comprender que la copia de base de datos retrasada no es una copia de seguridad a un momento dado garantizada. La copia de base de datos retrasada tendrá un umbral de disponibilidad, normalmente alrededor del 90 %, debido a períodos en los que el disco que contiene una copia retrasada se pierde debido a un error de disco, la copia retrasada se convierte en una copia de alta disponibilidad (debido a la reproducción automática) y, los períodos en los que la copia de base de datos retrasada está recompilando la cola de reproducción.
Para protegerse frente a la eliminación accidental (o malintencionada) de elementos, se usan tecnologías de recuperación de elementos únicos o retención local y la ventana Retención de elementos eliminados se establece en un valor que cumple o supera cualquier Acuerdo de Nivel de Servicio de recuperación de nivel de elemento definido.
Con todas estas tecnologías en juego, las copias de seguridad tradicionales son innecesarias; como resultado, la PA usa Exchange Native Data Protection.
diseño de Office Online Server
Como mínimo, querrá implementar una granja de Office Online Server (OOS) con al menos dos nodos OOS en cada centro de datos que hospede servidores de Exchange 2019. Cada Office Online Server debe tener al menos 8 núcleos de procesador, 32 GB de memoria y al menos 40 GB de espacio dedicado para los archivos de registro. Los servidores de buzones de Exchange 2019 deben configurarse para depender de la granja de OOS local de su centro de datos a fin de garantizar la latencia más baja posible y el mayor ancho de banda posible entre los servidores para representar contenido de archivo a los usuarios.
Resumen
Exchange Server 2019 sigue mejorando en las inversiones introducidas en versiones anteriores de Exchange e introduce tecnologías adicionales originalmente inventadas para su uso en Microsoft 365 y Office 365.
Al alinearse con la arquitectura preferida, aprovechará estos cambios y proporcionará la mejor experiencia de usuario local posible. Seguirá con la tradición de tener una implementación de Exchange altamente confiable, predecible y resistente.