Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:✅ Ingeniería de datos y ciencia de datos en Microsoft Fabric
Al crear Microsoft Fabric desde el Azure Portal, se agrega automáticamente al inquilino de Fabric asociado a la suscripción usada para crear la capacidad. Con la configuración simplificada en Microsoft Fabric, no es necesario vincular la capacidad al inquilino de Fabric. Dado que la capacidad recién creada se mostrará en el panel de configuración del administrador. Esta configuración proporciona una experiencia más rápida para que los administradores empiecen a configurar la capacidad de sus equipos de análisis empresarial.
Para realizar cambios en la configuración de Ingeniería de datos/ciencia en una capacidad, debe tener el rol de administrador para esa capacidad. Para obtener más información sobre los roles que puede asignar a los usuarios en una capacidad, consulte Roles en capacidades.
Siga estos pasos para administrar la configuración de Ingeniería de datos/Ciencia para la capacidad de Microsoft Fabric:
Seleccione la opción Configuración para abrir el panel de configuración de su cuenta de Fabric. Seleccione Portal de administración en la sección Gobernanza e información.
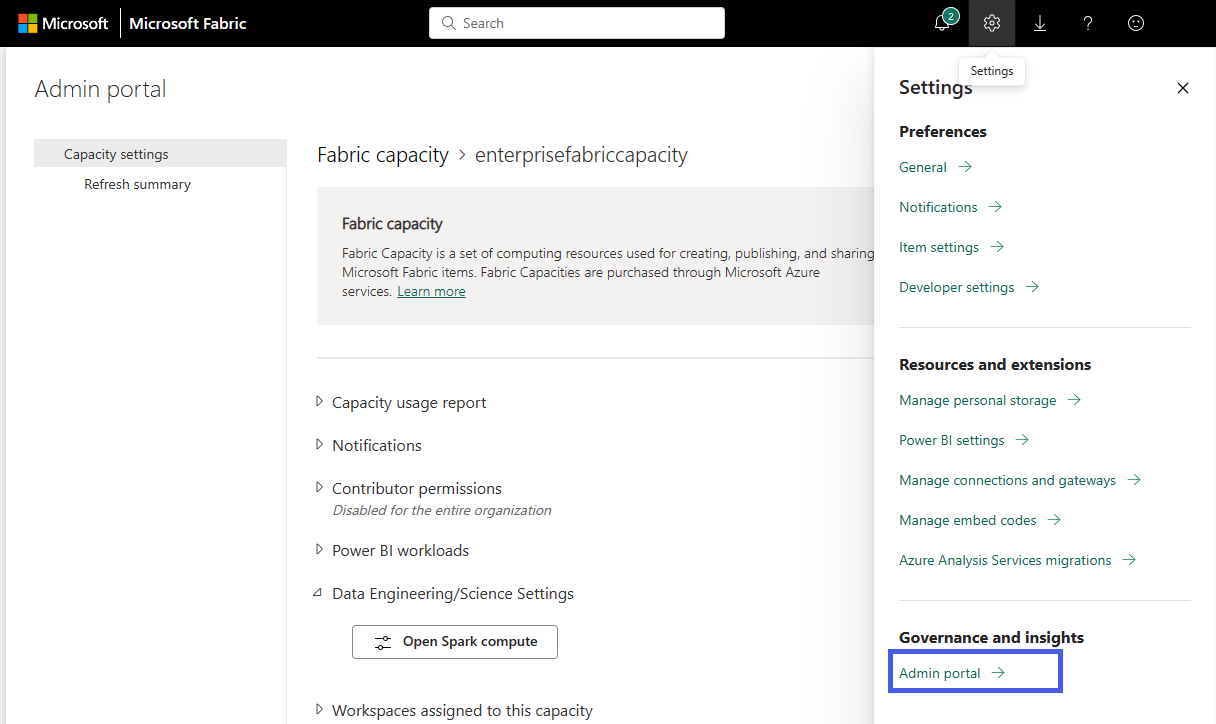
Elija la opción Configuración de capacidad para expandir el menú y seleccione la pestaña Capacidad de Fabric. Aquí debería ver las capacidades que ha creado en su tenant. Elija la capacidad que desea configurar.
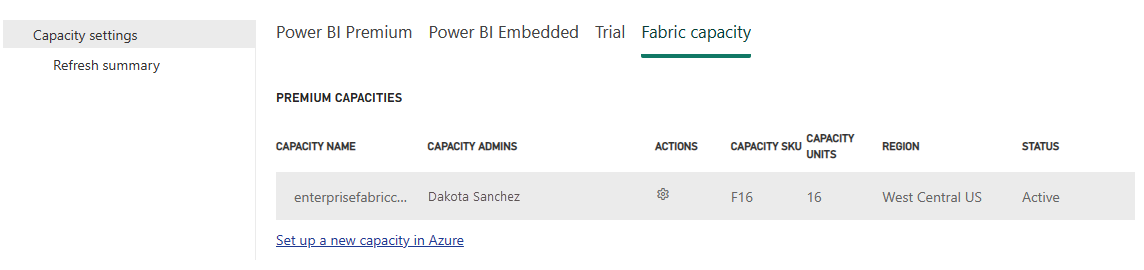
Se le dirigirá al panel de detalles de capacidad, donde puede ver el uso y otros controles de administración de la capacidad. Vaya a la sección Configuración de ingeniería/ciencia de datos y seleccione Abrir Spark Compute. Configure los siguientes parámetros:


Nota:
Al menos un área de trabajo debe adjuntarse a la capacidad de Fabric para explorar la configuración de ingeniería y ciencia de datos desde el portal de administración de capacidad de Fabric.
Control de administrador: Deshabilitar el uso del grupo de inicio
Los administradores de capacidad ahora pueden optar por deshabilitar el uso del grupo de inicio en las áreas de trabajo asociadas a la capacidad. Cuando se deshabilita, los usuarios y los administradores del área de trabajo ya no podrán ver el Starter Pool como una opción de cálculo. En su lugar, deben usar grupos personalizados creados y administrados explícitamente por el administrador de capacidad.
Esta característica proporciona una gobernanza centralizada para el uso del proceso, lo que garantiza un mayor control sobre el tamaño de proceso, el costo y el comportamiento de programación.
Sugerencia
Esta configuración es especialmente útil en organizaciones grandes que desean estandarizar patrones de proceso y evitar el consumo arbitrario a través de grupos de inicio predeterminados.
Control de administración: conmutador de expansión de nivel de trabajo
Microsoft Fabric admite 3× expansión para núcleos virtuales de Spark, lo que permite que un único trabajo use temporalmente más núcleos de proceso que la capacidad base proporciona. Esto mejora el rendimiento del trabajo durante las ráfagas de actividad al permitir el uso total de la capacidad.
Como administrador de capacidad, ahora puede controlar este comportamiento mediante el modificador "Deshabilitar expansión de nivel de trabajo" disponible en el Portal de administración:
Ubicación:
Admin Portal → Capacity Settings → [Select Capacity] → Data Engineering/Science Settings → Spark ComputeComportamiento:
- Habilitado (valor predeterminado): un único trabajo de Spark puede consumir el límite de ráfaga completo (hasta 3× núcleos virtuales de Spark).
- Deshabilitado: los trabajos individuales de Spark están limitados a la asignación de capacidad base, conservando la simultaneidad y evitando la monopolización.
Nota:
Este interruptor solo está disponible cuando se ejecutan trabajos de Spark en Fabric Capacity. Si la opción Facturación de escalado automático está habilitada, este conmutador se deshabilita automáticamente porque:
- La facturación de escalabilidad automática sigue un modelo puro de pago por uso.
- No hay ninguna ventana de suavizado para permitir las ráfagas de uso y equilibrarlas durante 24 horas.
- La expansión es una característica de capacidad reservada, no de proceso de escalabilidad automática a petición.
Casos de uso y ejemplos
| Escenario | Configuración | Comportamiento |
|---|---|---|
| Carga de trabajo de ETL intensiva | Ráfagas habilitadas (valor predeterminado) | El trabajo puede usar toda la capacidad de ráfaga (por ejemplo, 384 núcleos virtuales de Spark en F64). |
| Cuadernos interactivos de varios usuarios | Expansión deshabilitada | El uso del trabajo está limitado (por ejemplo, 128 núcleos virtuales de Spark en F64), lo que mejora la simultaneidad. |
| La facturación de escalabilidad automática está habilitada | Control de expansión no disponible | Todo el uso de Spark se factura bajo demanda; no hay rebasamiento de la capacidad base. |
Sugerencia
Use este modificador para optimizar el rendimiento o la simultaneidad:
- Mantenga habilitada la ráfaga para trabajos y canalizaciones de gran tamaño.
- Deshabilite para entornos interactivos o compartidos con muchos usuarios.
Grupos de capacidad para la ingeniería de datos y la ciencia de datos en Microsoft Fabric
En la sección Lista de Pools de Configuraciones de Spark, haga clic en Agregar para crear un Pool Personalizado para su Capacidad de Fabric.
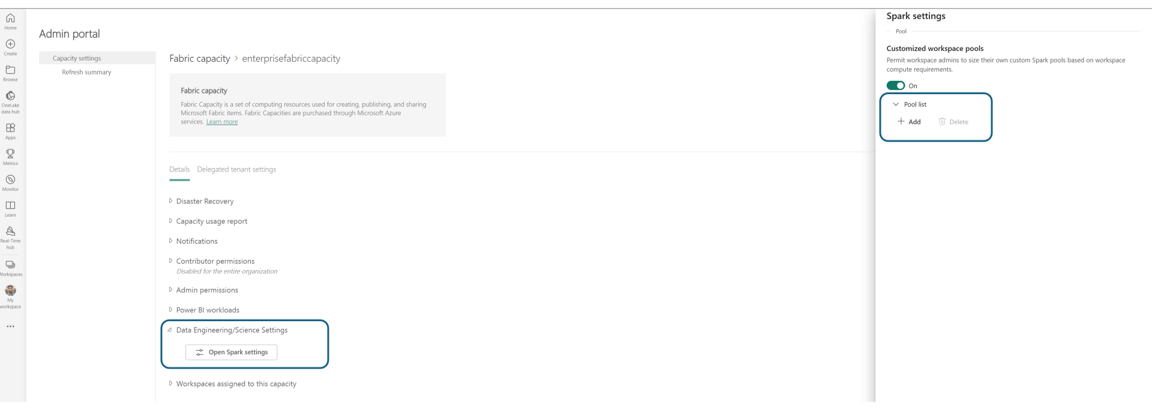
Se le dirigirá a la página de creación del grupo, donde puede:
- Especifica el nombre del grupo
- Selección de la familia de nodos y el tamaño del nodo
- Establecer nodos Min y Max
- Habilitar o deshabilitar la escalabilidad automática y la asignación dinámica de ejecutores
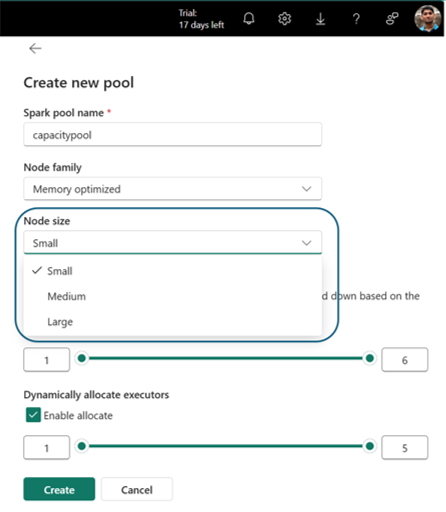
Seleccione Crear para guardar la configuración.



Nota:
Los grupos personalizados de nivel de capacidad tienen una latencia de inicio de 2 a 3 minutos. Para un inicio de sesión de Spark más rápido (<5 segundos), use grupos de inicio si está habilitado.
Una vez creado, el grupo de capacidad estará disponible en:
- Lista desplegable Selección de grupo en la configuración del área de trabajo
- Página Configuración de proceso del entorno en áreas de trabajo
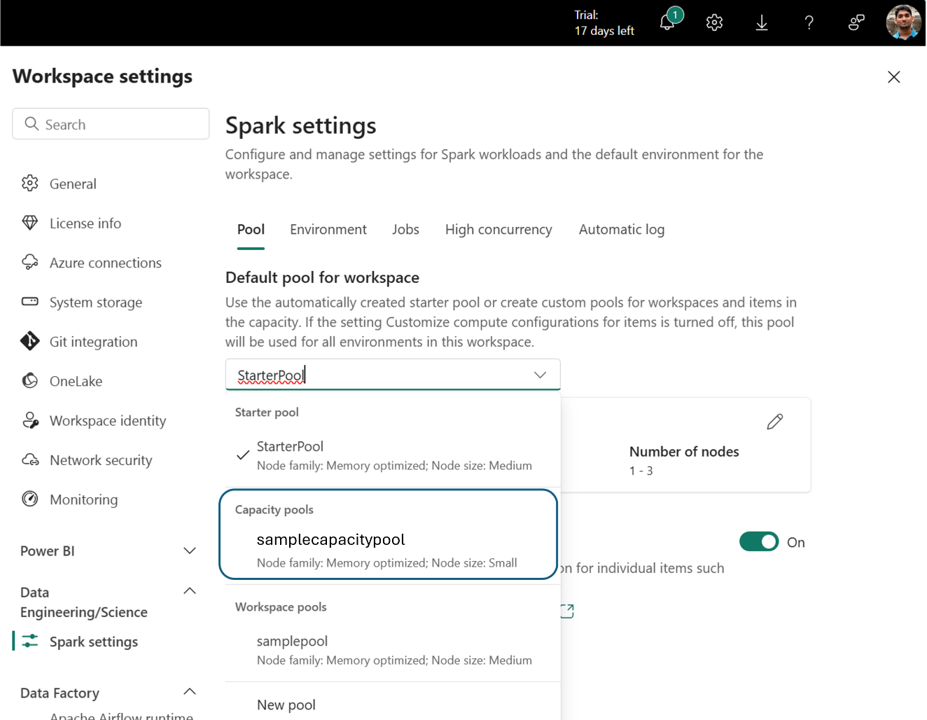
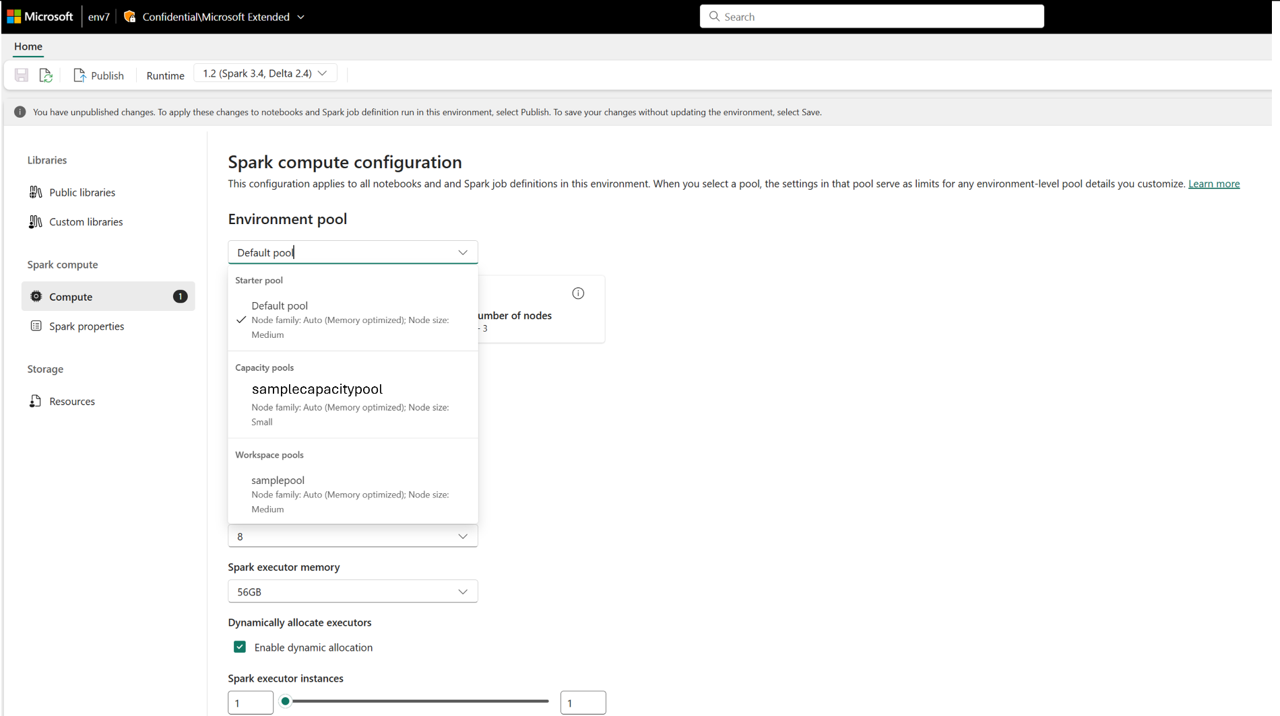
Esto permite la gobernanza centralizada de la computación. Los administradores pueden crear grupos estandarizados y, opcionalmente, deshabilitar la personalización de nivel de área de trabajo, lo que impide que los administradores de las áreas de trabajo modifiquen la configuración del grupo o creen sus propios.

