Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Conceptos básicos que respaldan el ajuste de tamaño, la optimización y la solución de problemas. Lea esto primero si no está familiarizado con Spark en Fabric.
Normas Generales: Qué hacer y qué no hacer
Escenario: eres nuevo en Spark. ¿Cuáles son los consejos y advertencias?
| Caso de uso | procedimientos recomendados |
|---|---|
| Uso de formatos serializados optimizados | Do: Prefiere formatos como Avro, Parquet o Columnar de fila optimizado (ORC) porque insertan esquema, son compactos y optimizan el almacenamiento y el procesamiento. En Azure Fabric, use el formato Delta para garantizar la atomicidad, coherencia, aislamiento y durabilidad (ACID), además de beneficios de rendimiento. |
| Tenga cuidado con XML/JSON | No se base en la inferencia de esquema para archivos grandes de notación de objetos JavaScript (JSON) o lenguaje de marcado extensible (XML), ya que Spark lee todo el conjunto de datos para inferir el esquema, lo que ralentiza el procesamiento y consume memoria de forma intensiva. Proporcione un esquema principal estático al leer JSON/XML o use .option("samplingRatio", 0.1) para acelerar las lecturas, pero tenga en cuenta que si el ejemplo no representa el conjunto de datos completo, es posible que se produzca un error en las lecturas. Un enfoque más seguro deduce el esquema de un ejemplo representativo y lo conserva para todas las lecturas.Evite analizar archivos XML grandes. El análisis XML se ejecuta intrínsecamente más lento debido al procesamiento de etiquetas y la conversión de tipos. |
| Optimización de combinaciones y filtrado | Do: Aplique la eliminación de columnas y el filtrado de nivel de fila antes de las uniones para reducir el uso de memoria y la reorganización. El optimizador Catalyst controla automáticamente el empuje del predicado cuando se usan las API DataFrame. Evite las API de conjuntos de datos distribuidos resistentes (RDD) porque omiten las optimizaciones de Catalyst. |
| Preferir DataFrames en lugar de RDDs | Haz lo siguiente: Usa DataFrames en lugar de RDDs en la mayoría de las operaciones. DataFrames usan el optimizador de Catalyst y el motor de ejecución de Tungsten para una ejecución eficaz. |
| Habilitación de la ejecución de consultas adaptables (AQE) | Do: Active AQE para optimizar dinámicamente las particiones de intercambio y gestionar automáticamente los datos sesgados. |
Administración de memoria del ejecutor
Escenario: quiere comprender la administración de memoria del ejecutor para el ajuste del rendimiento.
Incluso si un ejecutor está configurado con 56 GB de memoria, Spark no permite que todos se usen directamente para los datos de usuario. Spark Core divide y administra la memoria del ejecutor:
Memoria reservada: Una parte fija reservada para la sobrecarga interna del sistema y de Spark (por ejemplo, Máquina virtual Java (JVM), componentes internos).
Memoria del usuario: Almacena funciones definidas por el usuario (UDF), variables locales, estructuras de datos (listas, mapas, diccionarios) y objetos creados durante el cálculo.
Memoria de almacenamiento: Contiene datos almacenados en caché o persistentes, variables de transmisión y datos de mezclado que pueden ser almacenados en caché.
Memoria de ejecución: Se usa para la computación intermedia (clasificaciones, uniones, ordenaciones, agregaciones).
Uso compartido de memoria dinámica: El límite entre almacenamiento y memoria de ejecución es extraíble. Spark puede tomar prestado memoria de una región a otra, lo que permite un uso flexible de memoria.
Desbordamiento: Se produce cuando la demanda de memoria de almacenamiento o ejecución supera la memoria disponible después de haber consumido memoria adicional. Esto fuerza los datos al disco, lo que puede afectar al rendimiento.


Errores de memoria insuficiente (OOM)
Escenario: los trabajos de Spark fallan con errores de falta de memoria (OOM).
Controlador OOM:
Los errores de OOM del controlador se producen cuando el controlador de Spark supera su memoria asignada.
Causa común: operaciones con muchos controladores, como collect(), countByKey()o llamadas grandes toPandas() que extraen demasiado datos en la memoria del controlador.
Mitigación: evite las operaciones que requieren mucho del controlador siempre que sea posible. Si es inevitable, aumente el tamaño del controlador y la prueba comparativa para encontrar la configuración óptima.
Ejecutor insuficiente de memoria (OOM):
Los errores de OOM del ejecutor se producen cuando un ejecutor de Spark supera su memoria asignada.
Causa común: transformaciones con uso intensivo de memoria y computación en conjuntos de datos grandes (por ejemplo, joins extendidos, agregaciones, barajadas) o conjuntos de datos almacenados en caché o persistidos que superan la memoria disponible del ejecutor (ejecución más regiones de almacenamiento).
Mitigación: aumente la memoria del ejecutor si es necesario, ajuste las fracciones de memoria de Spark (spark.memory.fraction, spark.memory.storageFraction) y persista de forma selectiva. Asegúrese de que los datos almacenados en caché se ajusten a la memoria disponible.
Asimetría de datos
Síntomas de asimetría:
- Algunas tareas tardan más que otras en la interfaz de usuario de Spark (las tareas de etapa muestran cola pesada).
- Gran brecha entre los tiempos medio y máximo de tareas en las métricas de fase.
- Fases con tamaños de lectura o escritura aleatorios grandes para algunas particiones.
Causas comunes:
- Distribución desigual de datos para las claves de combinación o grupo (claves de acceso rápido).
- Particiones incorrectas o muy pocas particiones para el volumen de datos.
- Anomalías de datos ascendentes que producen registros grandes o muchas claves nulas o vacías.
Mitigación:
- Repartición o fusión para aumentar el paralelismo de partición y los tamaños de equilibrio.
- Aplique la sal de claves o la creación de particiones personalizadas para distribuir las claves activas entre particiones.
- Use AQE (ejecución de consultas adaptativa) para combinar particiones posteriores al barajado y habilitar optimizaciones de unión de datos sesgados.
- Usa uniones de difusión para tablas de búsqueda pequeñas y así evitar los reordenamientos por completo.
- Conserve los conjuntos de datos intermedios equilibrados antes de las fases costosas y vuelva a ejecutar el trabajo.
Procedimientos recomendados de UDF
Escenario: debe aplicar lógica personalizada que no se pueda expresar a través de funciones de DataFrame integradas.
Use las API de DataFrame de Spark siempre que sea posible. El optimizador catalyst optimiza las funciones integradas y las ejecuta de forma nativa en la JVM, por lo que ofrecen el mejor rendimiento.
Si debe usar una UDF (función definida por el usuario), evite las UDF de Python normales de PySpark. En su lugar, tenga en cuenta las siguientes alternativas:
UDF de Pandas (también conocidas como UDF vectorizadas): use Apache Arrow para una transferencia de datos eficaz entre JVM y Python. Las UDF de Pandas permiten operaciones vectorizadas, lo que mejora significativamente el rendimiento en comparación con las UDF de Python de fila a fila.
UDF de Scala/Java: ejecute directamente en la JVM, lo que evita la sobrecarga de serialización de Python. Las UDF de Scala/Java suelen superar las UDF de Python.
Tenga cuidado con las UDF de Python. Cada ejecutor inicia un proceso de Python independiente, lo que requiere serialización y deserialización de datos entre JVM y Python. Esto crea un cuello de botella en el rendimiento, especialmente a gran escala.
Registro de errores
Escenario: Procedimientos recomendados para el registro de errores en Fabric Spark
Use
log4jen lugar deprint(), lo que sobrecarga al conductor significativamente. Conlog4j, puede acceder a los registros de los registros de controladores y buscarlos (con el nombre del registrador, por ejemplo: PySparkLogger).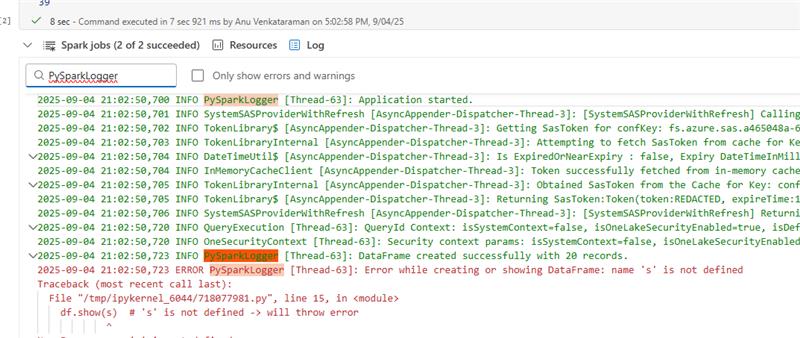
Encapsular lecturas, escrituras y transformaciones en bloques try y except. Use
logger.errorpara excepciones ylogger.infopara mensajes de progreso.Registro de Python: Ideal para las operaciones de registro, las actualizaciones de estado o la información de depuración del código que solo se ejecuta en el controlador de Spark. El módulo de registro de Python no se propaga a los registros del ejecutor. Consulte la documentación de desarrollo, ejecución y administración de cuadernos.
Spark log4j: El estándar para el registro sólido de aplicaciones de nivel de producción en Spark a medida que se integra de forma nativa con los registros del controlador o ejecutor de Spark.
Uso de log4j de ejemplo en PySpark:
import traceback # Get log4j logger log4jLogger = spark._jvm.org.apache.log4j logger = log4jLogger.LogManager.getLogger("PySparkLogger") logger.info("Application started.") try: # Create DataFrame with 20 records data = [(f"Name{i}", i) for i in range(1, 21)] # 20 records df = spark.createDataFrame(data, ["name", "age"]) logger.info("DataFrame created successfully with 20 records.") df.show(s) # 's' is not defined -> will throw error but the application will not fail except Exception as e: logger.error(f"Error while creating or showing DataFrame: {str(e)}\n{traceback.format_exc()}")Centralizar la supervisión de errores:
Utilice la extensión del emisor de diagnóstico (Supervisar las aplicaciones de Apache Spark con Azure Log Analytics) en el entorno y asóciela a los cuadernos que ejecutan aplicaciones de Spark. El emisor puede enviar registros de eventos, registros personalizados (como log4j) y métricas a Azure Log Analytics/Azure Storage/Azure Event Hubs. Pase el nombre log4j a la propiedad :
spark.synapse.diagnostic.emitter.\<destination\>.filter.loggerName.match.Además, para la depuración, también puede recopilar filas o registros con errores en las tablas de Lakehouse (LH) para la captura de datos erróneos a nivel de registro.
