Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial, utilizarás notebooks con el Entorno de ejecución de Spark para transformar y preparar los datos sin procesar en el almacén de datos tipo lakehouse.
Requisitos previos
Antes de comenzar, debe completar los tutoriales anteriores de esta serie:
- Crear un Lakehouse
- Ingesta de datos en un lago de datos
- Asegúrese de que los esquemas de lakehouse estén habilitados en su lakehouse.
Preparar los datos
En los pasos anteriores del tutorial, tiene datos sin procesar ingeridos desde el origen a la sección Archivos de lakehouse. Ahora puede transformar esos datos y prepararlos para crear tablas delta.
Descargue los cuadernos de la carpeta Código fuente del tutorial de Lakehouse.
En el explorador, vaya al área de trabajo de Fabric en el portal de Fabric.
Seleccione Importar>Notebook>desde este equipo.
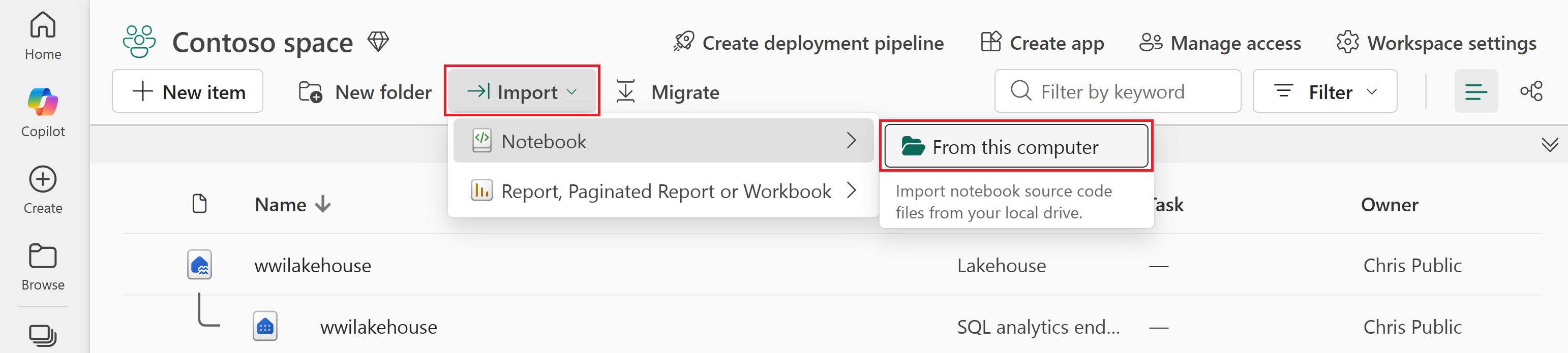
Seleccione Cargar en el panel Estado de importación que se abre en el lado derecho de la pantalla.
Seleccione solo el cuaderno que coincida con el lenguaje de codificación que prefiera.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Seleccione Abrir. Una notificación que indica el estado de la importación aparece en la esquina superior derecha de la ventana del explorador.
Una vez que la importación se haya realizado correctamente, vaya a la vista de elementos del área de trabajo para comprobar el cuaderno importado.
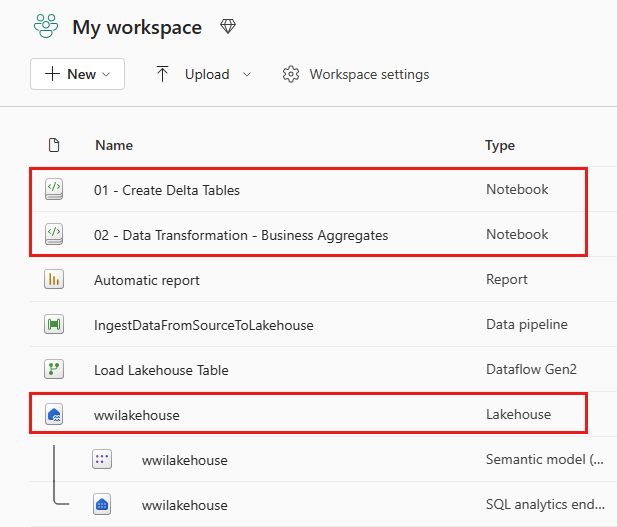
Seleccione wwilakehouse lakehouse para abrirlo, de modo que el cuaderno que abra a continuación esté vinculado a él.
En el menú de navegación superior, seleccione Abrir cuaderno>existente.
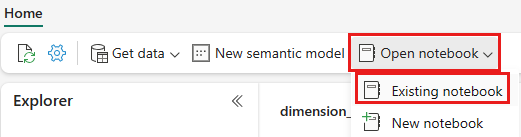
Seleccione el cuaderno importado para PySpark o Spark SQL y seleccione Abrir. El cuaderno ya está vinculado a la instancia de lakehouse abierta, como se muestra en el Explorador de lakehouse.



Ya está listo para ejecutar las celdas del cuaderno que crean y transforman las tablas delta.
En las secciones siguientes, ejecute las celdas del cuaderno secuencialmente. Para ejecutar una celda, seleccione el icono Ejecutar que aparece a la izquierda de la celda al mantener el puntero. También puede seleccionar Ejecutar todo en la cinta de opciones superior (Inicio) para ejecutar todas las celdas en secuencia.
Importante
Este tutorial requiere que se habiliten los esquemas de lakehouse. Si los esquemas no están habilitados, el código de este tutorial no funcionará según lo previsto.
En el cuaderno importado, verá las secciones Path 1 y Path 2 . Para este tutorial, use Path 1 (esquemas de lakehouse habilitados) y ignore Path 2 (esquemas de lakehouse no habilitados).
Creación de tablas Delta
En esta sección, ejecutas las celdas del cuaderno para crear tablas Delta a partir de los datos sin procesar.
Las tablas siguen un esquema de estrella, que es un patrón común para organizar los datos analíticos:
- Una tabla de hechos (
fact_sale) contiene los eventos medibles de la empresa, en este caso, transacciones de ventas individuales con cantidades, precios y beneficios. -
Las tablas de dimensiones (
dimension_city,dimension_customer,dimension_date,dimension_employee,dimension_stock_item) contienen los atributos descriptivos que proporcionan contexto a los hechos, como dónde ocurrió una venta, quién lo hizo y cuándo.
En esta página del tutorial, seleccione la pestaña que coincide con el cuaderno que importó y siga usando esa misma pestaña para todos los pasos. Las pestañas se encuentran en este artículo, no en el cuaderno.
Celda 1: configuración de sesión de Spark. Esta celda habilita dos características de Fabric que optimizan cómo se escriben y leen los datos en celdas posteriores. V-order optimiza el diseño del archivo parquet para lecturas más rápidas y una mejor compresión. Optimizar la escritura reduce el número de archivos escritos y aumenta el tamaño de archivo individual.
Ejecute esta celda y espere a que finalice antes de pasar al paso siguiente.
Celda 2 - Hecho - Venta. Esta celda lee datos de parquet sin procesar de
Files/wwi-raw-data/full/fact_sale_1y_full, agrega columnas de elementos de fecha (Año, Trimestre y Mes) y escribefact_salecomo una tabla Delta con particiones por Año y Trimestre.Ejecute esta celda y espere a que finalice antes de pasar al paso siguiente.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Celda 3 - Dimensiones. Esta celda lee los conjuntos de datos parquet de cinco dimensiones y los convierte en tablas Delta (
dimension_city,dimension_customer,dimension_date,dimension_employee, ydimension_stock_item) bajoTables/dbo/....Ejecute esta celda y espere a que finalice antes de pasar al paso siguiente.
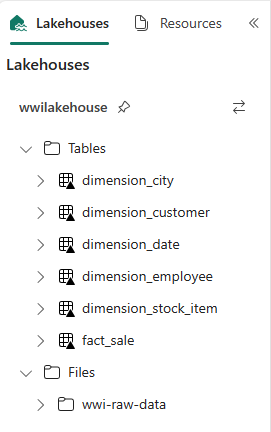
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Para validar las tablas creadas, haga clic con el botón derecho en wwilakehouse lakehouse en el explorador y seleccione Actualizar. Aparecen las tablas.

Transformación de datos para agregados empresariales
En esta sección, continuarás utilizando el mismo cuaderno y ejecutarás las siguientes celdas para crear tablas agregadas a partir de las tablas Delta que creaste en la sección anterior.
Asegúrese de que el cuaderno sigue vinculado a wwilakehouse.
Celda 4: Carga de tablas de origen para la transformación (solo PySpark). Si usa el cuaderno de PySpark, ejecute esta celda para cargar tablas Delta en DataFrames para los pasos de agregación que se indican a continuación.
Ejecute esta celda y espere a que finalice antes de pasar al paso siguiente.
Celda 5: Crear
aggregate_sale_by_date_city. Esta celda combina los datos de ventas, fecha y ciudad y, a continuación, crea la tabla agregada de nivel de ciudad.Ejecute esta celda y espere a que finalice antes de pasar al paso siguiente.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Celda 6: Crear
aggregate_sale_by_date_employee. Esta celda combina los datos de ventas, fecha y empleado y, a continuación, crea la tabla agregada de nivel de empleado.Ejecute esta celda y espere a que finalice antes de pasar al paso siguiente.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Para validar las tablas creadas, haga clic con el botón derecho en wwilakehouse lakehouse en el explorador y seleccione Actualizar. Aparecen las tablas agregadas.

En este tutorial se escriben datos como archivos Delta Lake. Fabric detecta y registra automáticamente estas tablas en el metastore, por lo que no es necesario ejecutar instrucciones independientes CREATE TABLE .