Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se explica cómo funcionan las canalizaciones de integración e implementación de Git para funciones de datos de usuario en Microsoft Fabric. Las funciones de datos de usuario de Fabric ofrecen integración de Git para el control de código fuente con repositorios de Azure DevOps. Con la integración de Git es posible controlar la versión del elemento de funciones de datos de usuario, colaborar con ramas de Git y administrar el ciclo de vida de contenido de las funciones de datos de usuario completamente dentro de Fabric.
Obtenga más información sobre el proceso de integración de Git con el área de trabajo de Microsoft Fabric en Conceptos básicos de la integración de Git.
Configuración de una conexión
Desde la configuración del área de trabajo, puede configurar fácilmente una conexión al repositorio para confirmar y sincronizar los cambios. Para configurar la conexión, consulte Introducción a la integración de Git. Una vez conectados, los elementos, incluyendo las funciones de datos de usuario, aparecerán en el panel Control de código fuente.

Después de confirmar correctamente los elementos de las funciones de datos de usuario en el repositorio de Git, verá las carpetas de funciones de datos de usuario en el repositorio. Ya podrá ejecutar operaciones futuras, como la creación de una solicitud de incorporación de cambios.
Representación de funciones de datos de usuario en Git
En la imagen siguiente se muestra un ejemplo de la estructura de archivos de cada elemento de funciones de datos de usuario del repositorio:

La estructura de carpetas incluye los siguientes elementos:
.platform: el archivo
.platformcontiene los atributos siguientes: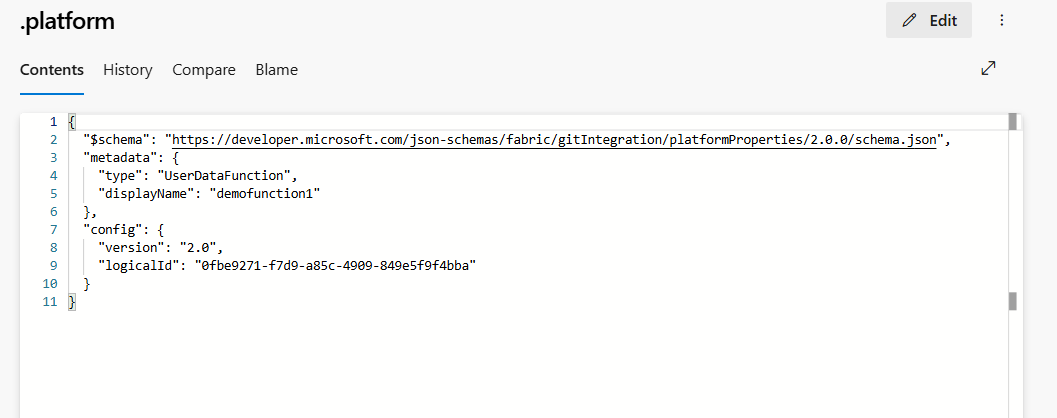
- versión: número de versión de los archivos del sistema. Este número se usa para habilitar la compatibilidad con versiones anteriores. El número de versión del elemento podría ser diferente.
- logicalId: un identificador entre áreas de trabajo generado automáticamente que representa un elemento y su representación de control de código fuente.
-
tipo:
UserDataFunctiones el tipo para definir un elemento de funciones de datos de usuario. - displayName: representa el nombre del elemento. Cuando se cambia el nombre del elemento de funciones de datos de usuario, se actualiza este displayName.
definitions.json: este archivo comparte todas las definiciones de elementos de funciones de datos de usuario, como conexiones, bibliotecas, etc. como una representación de las propiedades de elemento de funciones de datos de usuario.

function-app.py: este archivo es el código de las funciones. Los cambios de código que realice en el elemento de funciones de datos de usuario se sincronizan en el repositorio con este archivo. Es posible realizar varias operaciones de Git para administrar el ciclo de desarrollo de código.
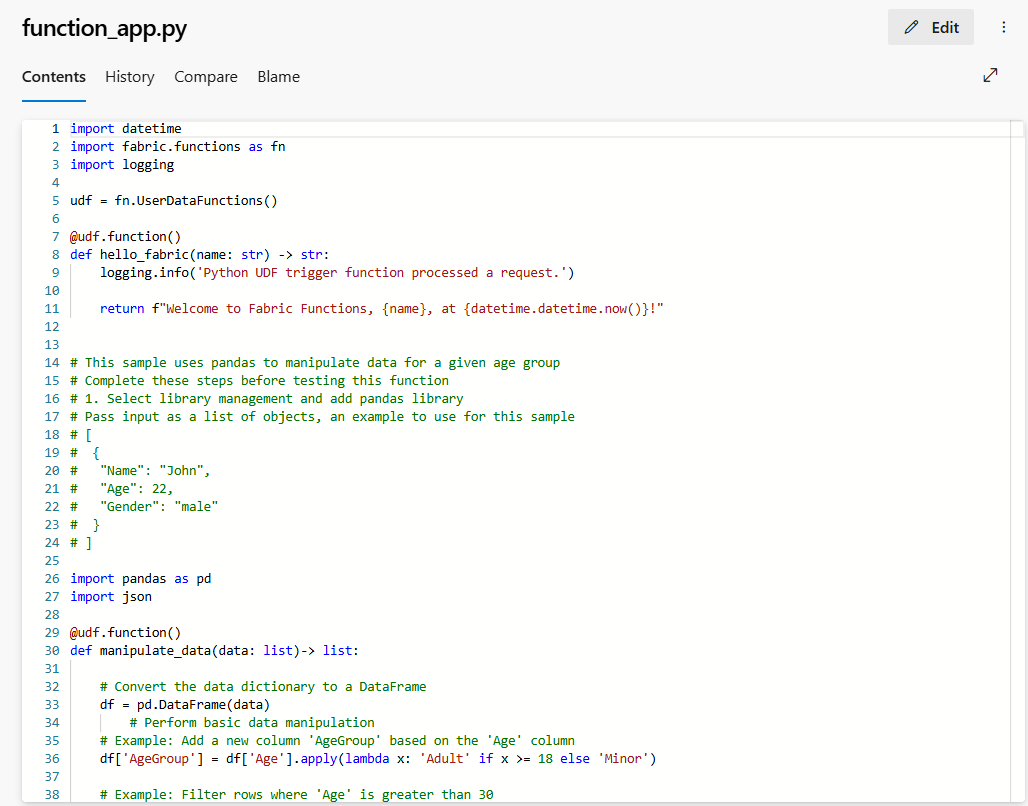
recursos: la carpeta contiene un archivo functions.json con todos los metadatos, como conexiones, bibliotecas y funciones dentro de este elemento. NO ACTUALICE ESTE ARCHIVO manualmente.
functions.jsonpermite a Fabric crear o volver a crear el elemento de funciones de datos de usuario en un área de trabajo.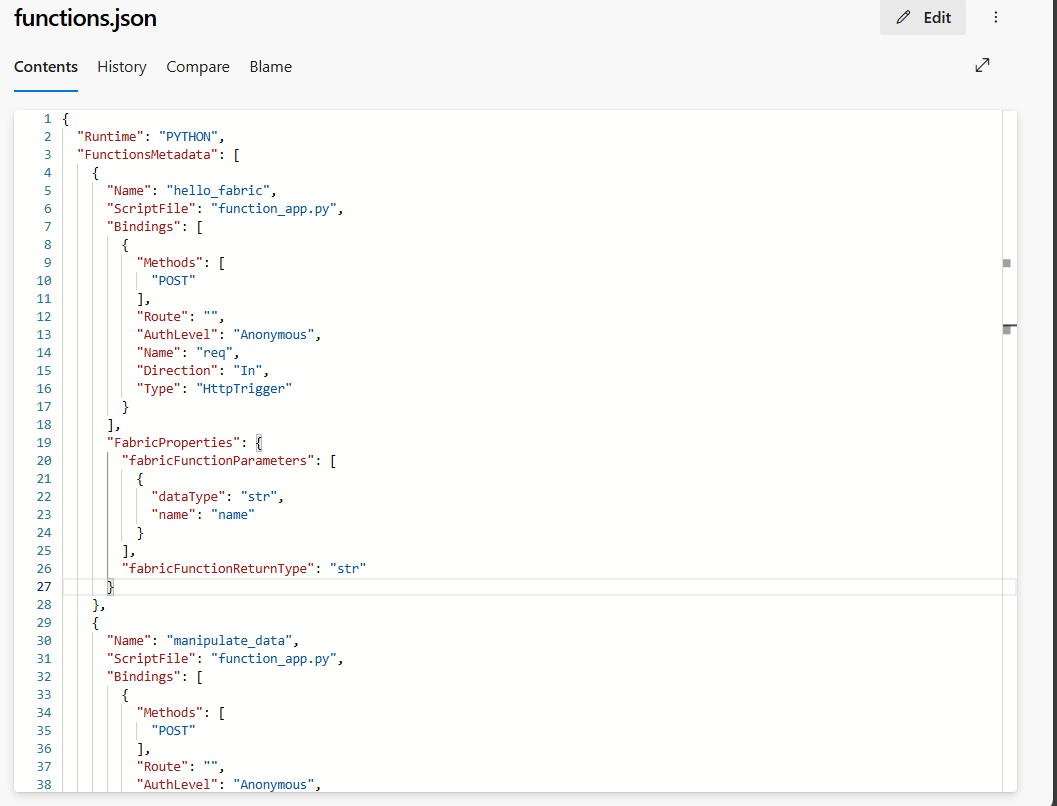




Funciones de datos de usuario en canalizaciones de implementación
También es posible usar canalizaciones de implementación para implementar el código de funciones de datos de usuario en distintos entornos, como desarrollo, prueba y producción. Esta característica le permitirá simplificar el proceso de desarrollo, garantizar la calidad y la coherencia, y reducir los errores manuales con operaciones ligeras con poco código.
Nota:
Todas las conexiones y bibliotecas se agregan a los nuevos elementos de funciones de datos de usuario creados en otros entornos.
Siga estos pasos para completar la implementación del cuaderno mediante la canalización de implementación.
Cree una nueva canalización de implementación o abra una canalización de implementación existente. Consulte Introducción a las canalizaciones de implementación para obtener más información.
Asigne áreas de trabajo a distintas fases según los objetivos de implementación.
Seleccione, vea y compare elementos, incluyendo los elementos de funciones de datos de usuario entre distintas fases.
Seleccione Implementar para implementar el elemento de funciones de datos de usuario en el entorno de prueba. Agregue una nota para proporcionar detalles sobre los cambios de esta implementación. Del mismo modo, es posible insertar cambios en las fases de desarrollo, prueba y producción.
Supervise el estado de implementación del historial de implementación.