Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo usar la actividad de copia en la canalización de datos para copiar datos desde y hacia un almacenamiento de datos.
Configuración admitida
Para la configuración de cada pestaña en la actividad de copia, vaya a las secciones siguientes respectivamente.
General
Para la configuración de la pestaña General , vaya a General.
Fuente
Las siguientes propiedades se admiten para el almacenamiento de datos como Origen en una actividad de copia.
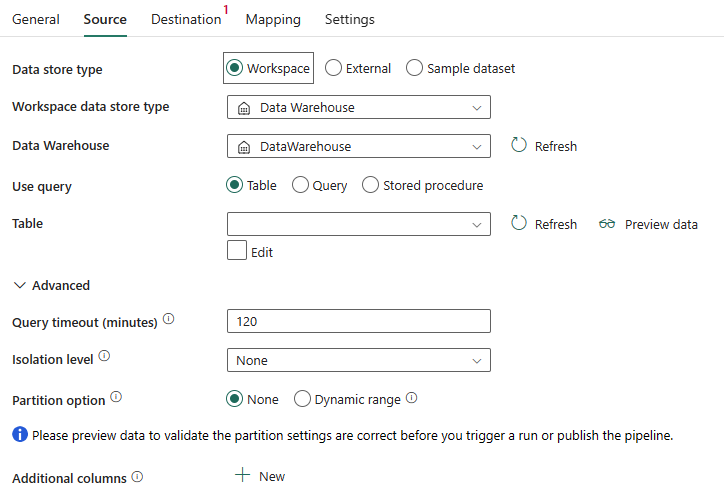
Las siguientes propiedades son obligatorias:
Tipo de banco de datos : seleccione Espacio de trabajo.
Tipo de almacén de datos del área de trabajo: seleccione Almacenamiento de datos en la lista de tipos de almacén de datos.
Almacenamiento de datos: seleccione un almacenamiento de datos existente en el área de trabajo.
Usar consulta: seleccione Tabla, Consulta o Procedimiento almacenado.
Si selecciona Tabla, elija una tabla existente en la lista de tablas o especifique manualmente un nombre de tabla seleccionando el cuadro Editar.

Si selecciona Consulta, use el editor de consulta SQL personalizado para escribir una consulta SQL que recupere los datos de origen.

Si selecciona Procedimiento almacenado, elija un procedimiento almacenado existente en la lista desplegable o especifique un nombre de procedimiento almacenado como origen seleccionando el cuadro Editar.

En Avanzado, puede especificar los campos siguientes:
Tiempo de espera de consulta (minutos): tiempo de espera para la ejecución del comando de consulta; con el valor predeterminado de 120 minutos. Si se establece esta propiedad, los valores permitidos tienen el formato de un intervalo de tiempo, como "02:00:00" (120 minutos).
Nivel de aislamiento: especifique el comportamiento de bloqueo de transacciones para el origen de SQL.
Opción de partición: especifique las opciones de partición de datos usadas para cargar datos del almacenamiento de datos. Puede seleccionar Ninguno o Intervalo dinámico.
Si selecciona Rango dinámico, se necesita el parámetro de partición por rangos (
?AdfDynamicRangePartitionCondition) al usar la consulta con la opción paralela habilitada. Consulta de ejemplo:SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition.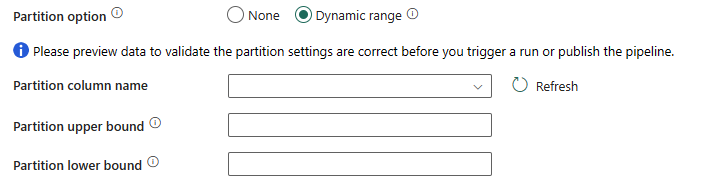
-
Nombre de la columna de origen: especifique el nombre de la columna de origen de tipo entero o fecha/hora (
int,smallint,bigint,date,smalldatetime,datetime,datetime2odatetimeoffset) que usa la creación de particiones por rangos para la copia paralela. Si no se especifica, el índice o la clave primaria de la tabla se detectan automáticamente y se usan como columna de partición. - Límite superior de la partición: el valor máximo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian.
- Límite inferior de la partición: el valor mínimo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian.
-
Nombre de la columna de origen: especifique el nombre de la columna de origen de tipo entero o fecha/hora (
Columnas adicionales: agregue columnas de datos adicionales a la ruta de acceso relativa o al valor estático de los archivos de origen. La expresión se admite para este último.


Destino
Las siguientes propiedades se admiten para el almacenamiento de datos como Destino en una actividad de copia.
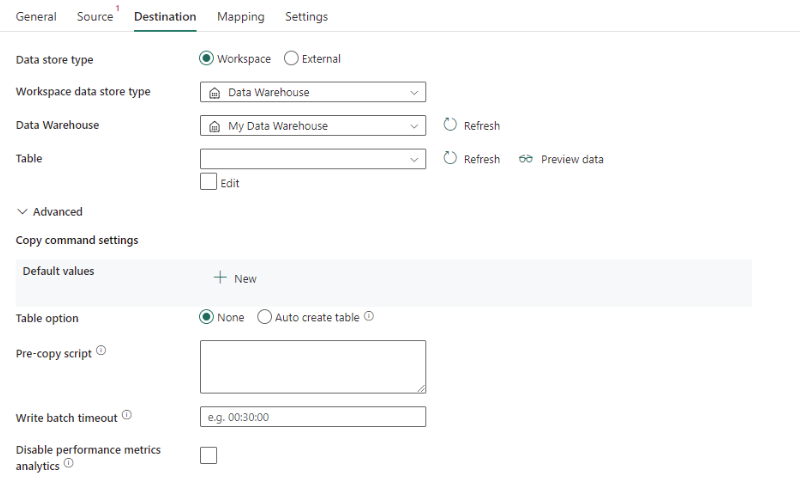
Las siguientes propiedades son obligatorias:
- Tipo de banco de datos : seleccione Espacio de trabajo.
- Tipo de almacén de datos del área de trabajo: seleccione Almacenamiento de datos en la lista de tipos de almacén de datos.
- Almacenamiento de datos: seleccione un almacenamiento de datos existente en el área de trabajo.
- Tabla: elija una tabla existente de la lista de tablas o especifique un nombre de tabla como destino.
En Avanzado, puede especificar los campos siguientes:
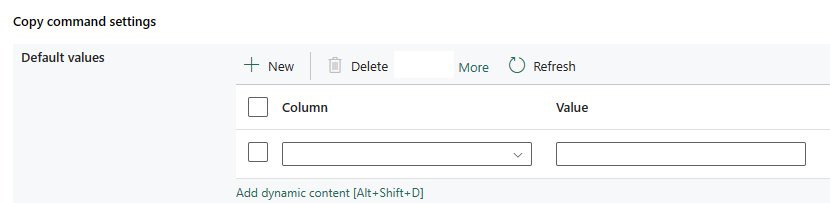
Configuración del comando de copia: especifique las propiedades del comando de copia.
Opciones de tabla: especifique si se debe crear automáticamente la tabla de destino si no existe ninguna según el esquema de origen. Puede seleccionar Ninguno o Crear tabla automáticamente.
Script de precopia: especifique una consulta SQL para que se ejecute antes de escribir datos en el almacenamiento de datos en cada ejecución. Esta propiedad se usa para limpiar los datos cargados previamente.
Tiempo de espera de escritura por lotes: el tiempo que se concede a la operación de inserción por lotes para que finalice antes de que se agote el tiempo de espera. Los valores permitidos tienen el formato de un intervalo de tiempo. El valor predeterminado es "00:30:00" (30 minutos).
Deshabilitar el análisis de métricas de rendimiento: el servicio recopila métricas para la optimización del rendimiento de copia y la obtención de recomendaciones. Si le preocupa este comportamiento, desactive esta característica.
copia directa
La instrucción COPY es la forma principal de ingerir datos en tablas de almacenamiento. El comando COPY de almacenamiento de datos admite directamente Azure Blob Storage y Azure Data Lake Storage Gen2 como almacenes de datos de origen. Si los datos de origen cumplen los criterios descritos en esta sección, use el comando COPU para copiar directamente desde el almacén de datos de origen en el almacenamiento de datos.
Los datos de origen y el formato contienen los siguientes tipos y métodos de autenticación:
Tipo de almacén de datos de origen admitido Formato admitido Tipo de autenticación de origen admitido Azure Blob Storage (Servicio de almacenamiento de blobs de Azure) Texto delimitado
ParquetAutenticación anónima
Autenticación de clave de cuenta
Autenticación con firma de acceso compartidoAzure Data Lake Storage Gen2 Texto delimitado
ParquetAutenticación de clave de cuenta
Autenticación con firma de acceso compartidoSe puede establecer la siguiente configuración de formato:
- Para Parquet: el tipo de compresión puede ser Ninguno, snappy o gzip.
- Para DelimitedText:
- Delimitador de fila: al copiar texto delimitado en el almacenamiento de datos mediante el comando COPY directo, especifique el delimitador de fila explícitamente (\r; \n; o \r\n). Solo cuando el delimitador de filas del archivo de origen es \r\n, el valor predeterminado (\r, \n o \r\n) funciona. De lo contrario, habilite el almacenamiento provisional para su escenario.
- El valor null se deja como valor predeterminado o se establece en cadena vacía ("").
- La codificación se deja como valor predeterminado o se establece en UTF-8 o UTF-16.
- El número de líneas ignoradas se deja como predeterminado o se establece en 0.
- El tipo de compresión puede ser Ninguno o gzip.
Si el origen es una carpeta, debe activar la casilla Recursivamente.
La Hora de inicio (UTC) y la Hora de finalización (UTC) en Filtrar por última modificación, Prefijo, Habilitar detección de particiones y Columnas adicionales no se especifican.
Para obtener información sobre cómo ingerir datos en el almacenamiento de datos mediante el comando COPY, consulte este artículo.
Si el formato y el almacén de datos de origen no es compatible originalmente con el comando COPY, use en su lugar la característica Copia almacenada provisionalmente mediante el comando COPY. Convierte automáticamente los datos en un formato compatible con el comando COPY y, a continuación, llama a un comando COPY para cargar datos en el almacenamiento de datos.
copia almacenada provisionalmente
Si sus datos de origen no son compatibles de forma nativa con el comando COPY, active la copia de datos a través de un almacenamiento provisional. En este caso, el servicio convierte automáticamente los datos para satisfacer los requisitos del formato de datos del comando COPY. Después invoca el comando COPY para cargar los datos en el Data Warehouse. Por último, limpia los datos temporales del almacenamiento.
Para usar la copia almacenada provisionalmente, vaya a Configuración pestaña y seleccione Habilitar almacenamiento provisional. Puede elegir Área de trabajo para usar el almacenamiento provisional creado automáticamente en Fabric. En el caso de External, Azure Blob Storage y Azure Data Lake Storage Gen2 se admiten como almacenamiento provisional externo. En primer lugar, debe crear una conexión Azure Blob Storage o Azure Data Lake Storage Gen2 y, a continuación, seleccionar la conexión de la lista desplegable para utilizar el almacenamiento provisional.
Tenga en cuenta que debe asegurarse de que el intervalo IP del almacenamiento de datos se ha permitido correctamente desde el almacenamiento provisional.
Asignación
Para la configuración de la pestaña Asignación, si no aplica la tabla Almacén de datos con creación automática como destino, vaya a Asignación.
Si aplica la tabla Almacén de datos con creación automática como destino, salvo la configuración en Asignación, puede editar el tipo para las columnas de destino. Después de seleccionar Importar esquemas, puede especificar el tipo de columna en el destino.
Por ejemplo, el tipo de la columna ID de origen es int y puede cambiarlo a tipo float al asignarlo a la columna de destino.
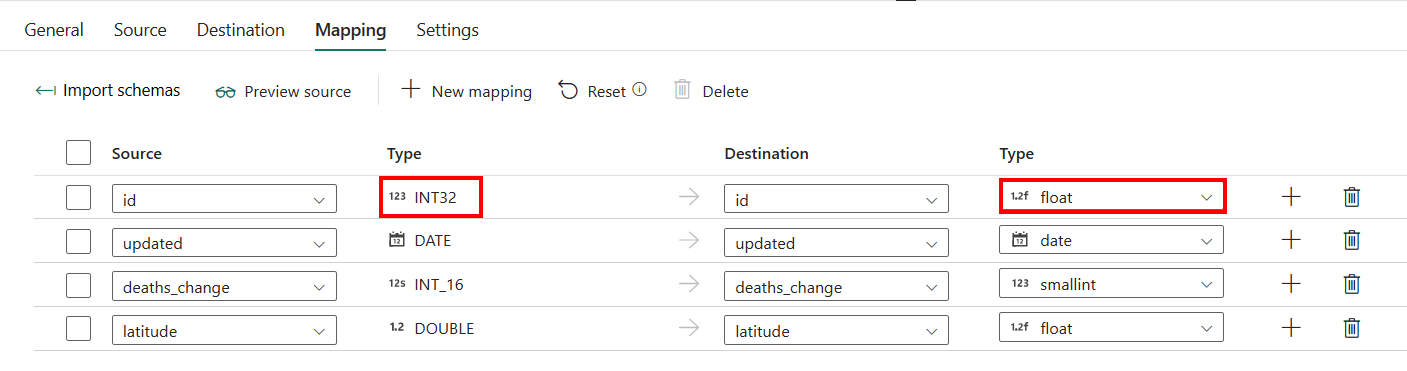
Si elige tipo varchar o varbinary para la columna de destino, puede especificar la longitud del tipo. La longitud debe ser mayor que 0 y menor que 8000 o ser MAX (indica un tamaño máximo de almacenamiento de 2³¹-1 bytes). El valor predeterminado es 8000. Para más información, consulte este artículo.
Configuración
Para los ajustes de la pestaña Configuración, vaya a Configuración.
Resumen de tabla
Las tablas siguientes contienen más información sobre una actividad de copia en el almacenamiento de datos.
Información de origen
| Nombre | Descripción | Importancia | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Tipo de almacén de datos | El tipo de almacén de datos. | Área de trabajo | Sí | / |
| Tipo de almacén de datos del área de trabajo | Sección para seleccionar el tipo de almacén de datos del área de trabajo. | Almacén de datos | Sí | tipo |
| Almacén de datos | El almacenamiento de datos que desea usar. | <su almacenamiento de datos> | Sí | punto final ID del artefacto |
| Usar consulta | La manera de leer datos del almacenamiento de datos. | • Tablas • Consulta • Procedimiento almacenado |
No |
(en typeProperties ->source)• typeProperties: esquema tabla • sqlReaderQuery • sqlReaderStoredProcedureName |
| Tiempo de espera de consulta (minutos) | Tempo de espera para la ejecución del comando de consulta; con el valor predeterminado de 120 minutos. Si se establece esta propiedad, los valores permitidos tienen el formato de un intervalo de tiempo, como "02:00:00" (120 minutos). | lapso de tiempo | No | queryTimeout |
| Nivel de aislamiento | El comportamiento de bloqueo de transacción para el origen. | • Ninguno •Captura instantánea |
No | nivel de aislamiento |
| Opción de partición | Las opciones de creación de particiones de datos que se usan para cargar datos desde el almacenamiento de datos. | • Ninguno • Intervalo dinámico |
No | Opción de partición |
| Nombre de columna de partición | El nombre de la columna de origen de tipo entero o date/datetime* (int, smallint, bigint, date, smalldatetime, datetime, datetime2 o datetimeoffset) que se usa en la creación de particiones por rangos para la copia en paralelo. Si no se especifica, el índice o la clave primaria de la tabla se detectan automáticamente y se usan como columna de partición. |
<nombre de columna de partición> | No | partitionColumnName |
| Límite superior de partición | Valor máximo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. | <límite superior de partición> | No | partitionUpperBound |
| Límite inferior de partición | Valor mínimo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. | <límite inferior de partición> | No | partitionLowerBound |
| Columnas adicionales | Agregue columnas de datos adicionales para almacenar la ruta de acceso relativa o el valor estático de los archivos de origen. | • Nombre • Valor |
No | columnas adicionales: • nombre • valor |
Información de destino
| Nombre | Descripción | Importancia | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Tipo de almacén de datos | El tipo de almacén de datos. | Área de trabajo | Sí | / |
| Tipo de almacén de datos del área de trabajo | Sección para seleccionar el tipo de almacén de datos del área de trabajo. | Almacén de datos | Sí | tipo |
| Almacén de datos | El almacenamiento de datos que desea usar. | <su almacenamiento de datos> | Sí | punto final ID del artefacto |
| Tabla | Tabla de destino para escribir datos. | <nombre de la tabla de destino> | Sí | esquema tabla |
| Configuración del comando de copia | Configuración de la propiedad del comando de copia. Contiene la configuración de valor predeterminada. | Valor predeterminado: • Columna • Valor |
No | copyCommandSettings: defaultValues: • columnName • valor por defecto |
| Opción de tabla | Si desea crear automáticamente la tabla de destino si no existe ninguna basada en el esquema de origen. | • Ninguno • Crear tabla automáticamente |
No | opción de tabla: • AutoCrear |
| Pre-copy script (Script anterior a la copia) | Una consulta SQL para que se ejecute antes de escribir datos en el almacenamiento de datos en cada ejecución. Esta propiedad se usa para limpiar los datos cargados previamente. | <script anterior a la copia> | No | preCopyScript |
| Tiempo de espera de escritura por lotes | El tiempo que se concede a la operación de inserción por lotes para que finalice antes de que se agote el tiempo de espera. Los valores permitidos tienen el formato de un intervalo de tiempo. El valor predeterminado es "00:30:00" (30 minutos). | lapso de tiempo | No | writeBatchTimeout |
| Desactivar análisis de métricas de rendimiento | El servicio recopila métricas para la optimización del rendimiento de copia y la obtención de recomendaciones, que proporcionan acceso adicional a la base de datos maestra. | seleccionar o anular la selección | No | disableMetricsCollection: true o false |