Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
XML (lenguaje de marcado extensible) es un formato basado en texto para el intercambio de datos estructurado. En este artículo se describe cómo configurar el formato XML como origen en una canalización de actividad de copia en Data Factory en Microsoft Fabric.
Capacidades compatibles
El formato XML se admite para las siguientes actividades y conectores como origen.
| Categoría | Conector/Actividad |
|---|---|
| Conector admitido | Amazon S3 |
| Compatible con Amazon S3 | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen2 | |
| Archivos de Azure | |
| Sistema de archivos | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Archivos de Lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Actividad compatible | Actividad de copia (origen/-) |
| Actividad de búsqueda | |
| Actividad GetMetadata | |
| Eliminar actividad |
Formato XML en la actividad de copia
Para configurar el formato XML, elija la conexión en el origen de una actividad de copia de canalización y seleccione XML en la lista desplegable Formato de archivo. Seleccione Configuración para una configuración adicional de este formato.
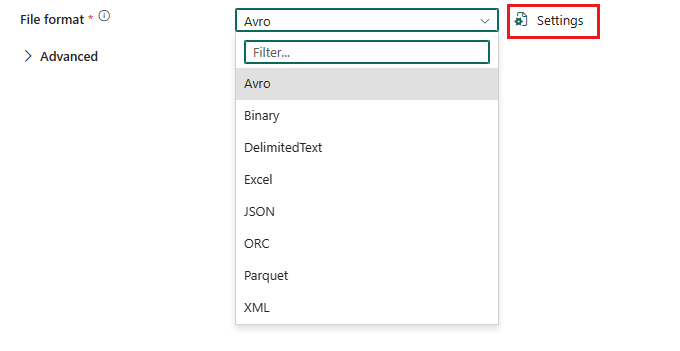
XML como origen
Después de seleccionar Configuración en la sección Formato de archivo , se muestran las siguientes propiedades en el cuadro de diálogo emergente Configuración de formato de archivo .
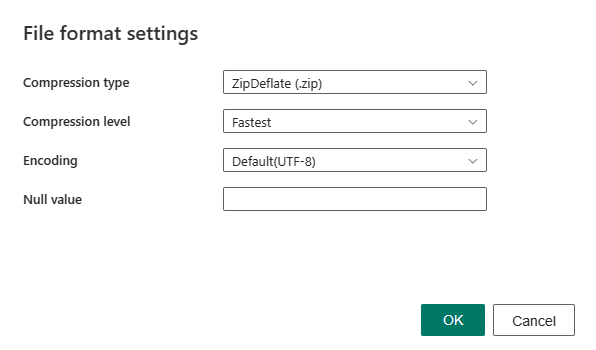
Tipo de compresión: códec de compresión utilizado para leer archivos XML. Puede elegir entre los tipos Ninguno, bzip2, gzip, deflate, ZipDeflate , TarGZip o tar en la lista desplegable.
Si selecciona ZipDeflate como tipo de compresión, Conservar el nombre del archivo zip como carpeta aparecerá en la configuración Avanzada de la pestaña Origen.
-
Conservar el nombre del archivo zip como carpeta: Indica si se debe conservar el nombre del archivo zip de origen como estructura de carpetas durante la copia.
- Si esta casilla está marcada (predeterminado), el servicio escribe los archivos descomprimidos en
<specified file path>/<folder named as source zip file>/. - Si esta casilla no está marcada, el servicio escribe los archivos descomprimidos directamente en
<specified file path>. Asegúrese de que no tenga nombres de archivo duplicados en diferentes archivos ZIP de origen para evitar condiciones de carrera o comportamientos inesperados.
- Si esta casilla está marcada (predeterminado), el servicio escribe los archivos descomprimidos en
Si selecciona TarGZip/tar como tipo de compresión, se muestra la opción Conservar el nombre del archivo de compresión como carpeta en la configuración Avanzada de la pestaña Origen.
-
Conservar el nombre del archivo de compresión como carpeta: Indica si se debe conservar el nombre del archivo de compresión de origen como estructura de carpetas durante la copia.
- Si esta casilla está marcada (predeterminado), el servicio escribe los archivos descomprimidos en
<specified file path>/<folder named as source compressed file>/. - Si esta casilla no está marcada, el servicio escribe los archivos descomprimidos directamente en
<specified file path>. Asegúrese de que no haya nombres de archivo duplicados en distintos archivos de origen para evitar condiciones de carrera o comportamientos inesperados.
- Si esta casilla está marcada (predeterminado), el servicio escribe los archivos descomprimidos en
-
Conservar el nombre del archivo zip como carpeta: Indica si se debe conservar el nombre del archivo zip de origen como estructura de carpetas durante la copia.
Nivel de compresión: especifique la relación de compresión al seleccionar un tipo de compresión. Puede elegir entre Más rápido u Óptimo.
- Más rápido: la operación de compresión debe completarse lo más rápido posible, incluso si el archivo resultante no se comprime de manera óptima.
- Optimal: la operación de compresión se debe comprimir óptimamente, incluso si tarda más tiempo en completarse. Para obtener más información, consulte el tema Nivel de compresión .
Codificación: especifique el tipo de codificación usado para leer archivos de texto. Seleccione un tipo de la lista desplegable. El valor predeterminado es UTF-8.
Valor nulo : especifica la representación de cadena del valor nulo. El valor predeterminado es una cadena vacía.
En la configuración Avanzada de la pestaña Origen, se muestran las siguientes propiedades relacionadas con el formato XML.
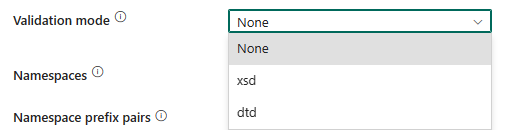
Modo de validación: especifica si debe validarse el esquema XML. Seleccione un modo en la lista desplegable.
- Ninguno: seleccione esta opción para no usar ningún modo de validación.
- xsd: seleccione esta opción para validar el esquema XML con XSD.
- dtd: seleccione esta opción para validar el esquema XML con DTD.
Espacios de nombres: indica si debe habilitarse el espacio de nombres cuando se analizan los archivos XML. Esta opción está seleccionada de forma predeterminada.
Pares de prefijo de espacio de nombres: si la opción Espacios de nombres está activada, seleccione + Nuevo y especifique la Dirección URL y el Prefijo. Para agregar más pares, seleccione + Nuevo.
El mapeo de URI de espacio de nombres a prefijo se utiliza para nombrar los campos al analizar el archivo XML. Si un archivo XML tiene un espacio de nombres y este está habilitado, de forma predeterminada, el nombre del campo es el mismo que en el documento XML. Si hay un elemento definido para el URI del espacio de nombres en este mapa, el nombre del campo esprefix:fieldName.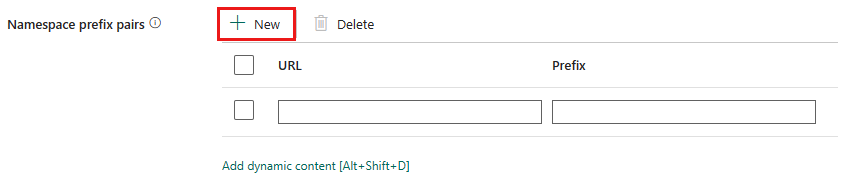
Detectar tipo de datos: especifique si deben detectarse los tipos de datos entero, doble y booleano. Esta opción está seleccionada de forma predeterminada.
Propiedades de la actividad de copia XML
XML como origen
Las siguientes propiedades se admiten en la sección Origen de la actividad de copia cuando se utiliza el formato XML.
| Nombre | Descripción | Valor | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Formato de archivo | El formato de archivo que quiere usar. | XML | Sí | tipo (debajo de datasetSettings):Xml |
| Tipo de compresión | Códec de compresión usado para leer archivos XML. |
Ninguna bzip2 gzip deflate ZipDeflate TarGZip tar |
No | tipo (en compression):bzip2 gzip desinflar ZipDeflate TarGZip tar |
| Nivel de compresión | La razón de compresión. |
Más rápida Optimal |
No | nivel (debajo de compression):Más rápido Óptimo |
| Encoding | Tipo de codificación que se usa para leer archivos de texto. | "UTF-8" (de manera predeterminada), "UTF-8 sin BOM", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | No | nombreDeCodificación |
| Conservar el nombre del archivo ZIP como carpeta | Indica si se debe conservar el nombre del archivo ZIP de origen como estructura de carpetas durante la copia. | Seleccionado (predeterminado) o no seleccionado | No | preservarNombreDeArchivoZipComoCarpeta (debajo de compressionProperties->type como ZipDeflateReadSettings):true (valor predeterminado) o false |
| Conservar el nombre del archivo de compresión como carpeta | Indica si, durante la copia, debe conservarse el nombre del archivo de origen comprimido como una estructura de carpetas. | Seleccionado (predeterminado) o no seleccionado | No | preserveCompressionFileNameAsFolder (en compressionProperties->type como TarGZipReadSettings o TarReadSettings):true (valor predeterminado) o false |
| Valor null | La representación en cadena del valor nulo. |
<el valor NULL> cadena vacía (de forma predeterminada) |
No | valor nulo |
| Modo de validación | Indica si debe validarse el esquema XML. |
Ninguna xsd dtd |
No | validationMode: xsd dtd |
| Espacios de nombres | Indica si habilitar el namespace al analizar los archivos XML. | Seleccionado (valor predeterminado) o no seleccionado | No | namespaces: true (valor predeterminado) o false |
| Pares de prefijo de espacio de nombres | Mapeo de URI de nombres de espacio a prefijo, que se utiliza para nombrar los campos al analizar el archivo XML. Si un archivo XML tiene un espacio de nombres y este está habilitado, de forma predeterminada, el nombre del campo es el mismo que en el documento XML. Si hay un elemento definido para el URI del espacio de nombres en este mapa, el nombre del campo es prefix:fieldName. |
<url>:<prefix> | No | namespacePrefixes: <url>:<prefix> |
| Detectar tipo de datos | Si se van a detectar tipos de datos enteros, dobles y booleanos. | Seleccionado (valor predeterminado) o no seleccionado | No | detectarTipoDeDato: true (valor predeterminado) o false |