Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Se trata de un patrón para amasar datos incrementalmente con Dataflow Gen2. Esto no es lo mismo que la actualización incremental. La actualización incremental es una característica que está actualmente en desarrollo. Esta característica es una de las ideas más votadas en nuestro sitio web de ideas. Puede votar por esta característica en el sitio de Fabric Ideas.
Este tutorial dura 15 minutos y describe cómo amasar datos de forma incremental en una instancia de LakeHouse mediante Dataflow Gen2.
El amasado incremental de datos en un destino de datos requiere una técnica para cargar solo datos nuevos o actualizados en el destino de datos. Esta técnica se puede realizar mediante una consulta para filtrar los datos en función del destino de datos. En este tutorial se muestra cómo crear un flujo de datos para cargar datos de un origen de OData en una instancia de LakeHouse y cómo agregar una consulta al flujo de datos para filtrar los datos en función del destino de datos.
Los pasos generales de este tutorial son los siguientes:
- Cree un flujo de datos para cargar datos de un origen de OData en una instancia de LakeHouse.
- Agregue una consulta al flujo de datos para filtrar los datos en función del destino de datos.
- (Opcional) volver a cargar datos mediante cuadernos y canalizaciones.
Requisitos previos
Debe tener un área de trabajo habilitada para Microsoft Fabric. Si aún no tiene una, consulte el artículo Crear un área de trabajo. Además, en el tutorial se asume que utilizas la vista de diagrama en Dataflow Gen2. Para comprobar si usa la vista de diagrama, en la cinta superior vaya a Ver y asegúrese de que la vista de Diagrama está seleccionada.
Creación de un flujo de datos para cargar datos de un origen de OData en una instancia de LakeHouse
En esta sección, creará un flujo de datos para cargar datos de un origen de OData en un lago.
Cree una nueva instancia de LakeHouse en el área de trabajo.
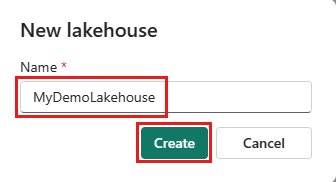
Cree un nuevo flujo de datos Gen2 en el área de trabajo.
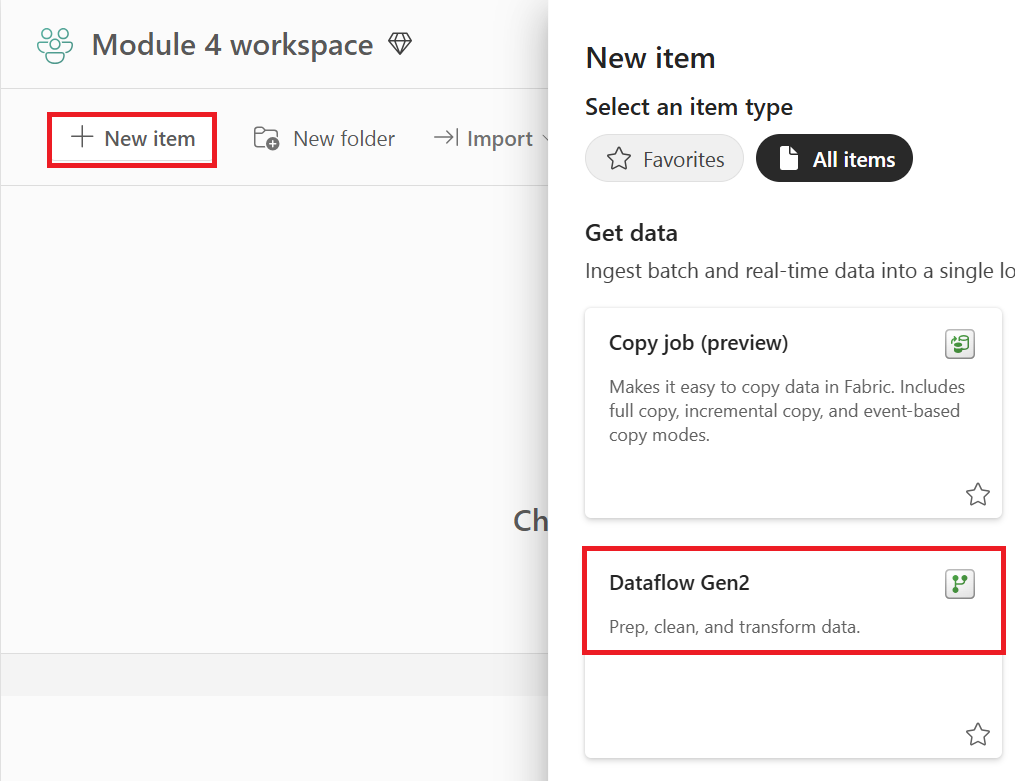
Agregue un nuevo origen al flujo de datos. Seleccione la fuente OData e introduzca la siguiente URL:
https://services.OData.org/V4/Northwind/Northwind.svc
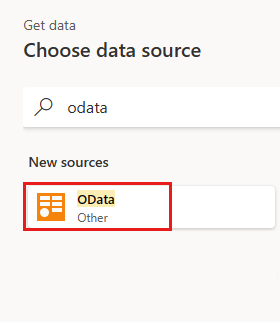
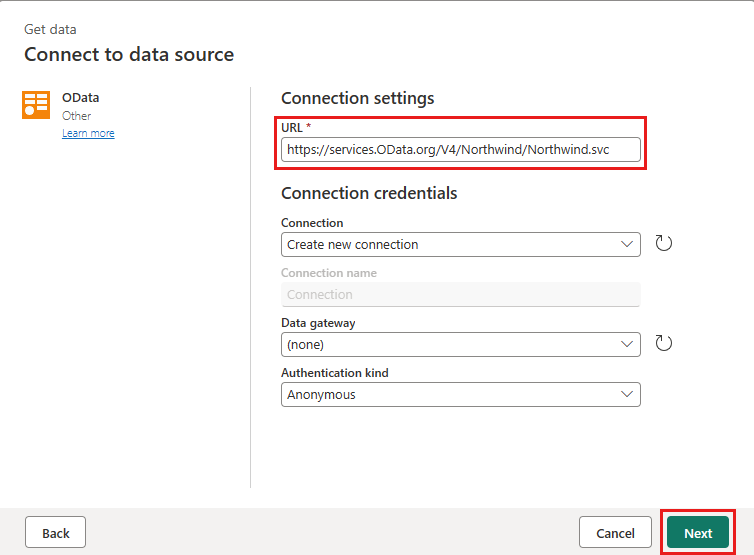
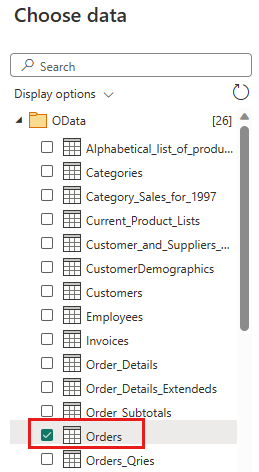
Seleccione la tabla Pedidos y seleccione Next.
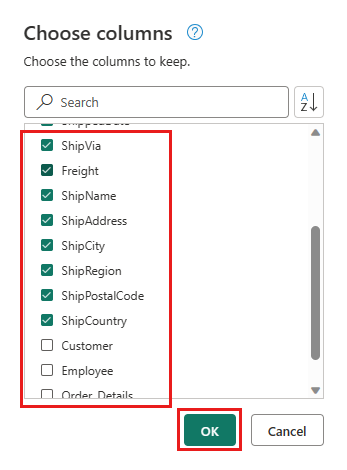
Seleccione las columnas siguientes para mantener:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Cambie el tipo de datos de
OrderDate,RequiredDateyShippedDateadatetime.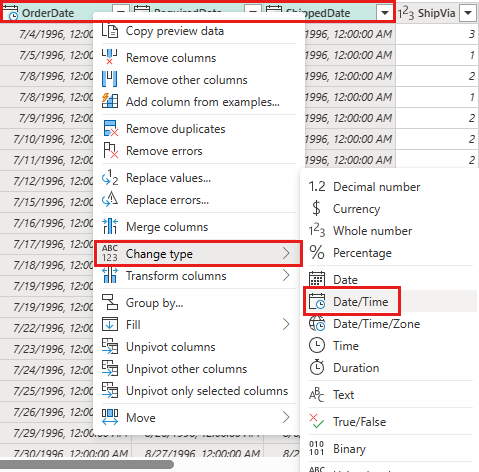
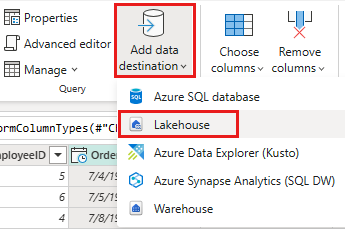
Configure el destino de datos en lakehouse con la siguiente configuración:
- destino de los datos:
Lakehouse - Lakehouse: seleccione el lago que creó en el paso 1.
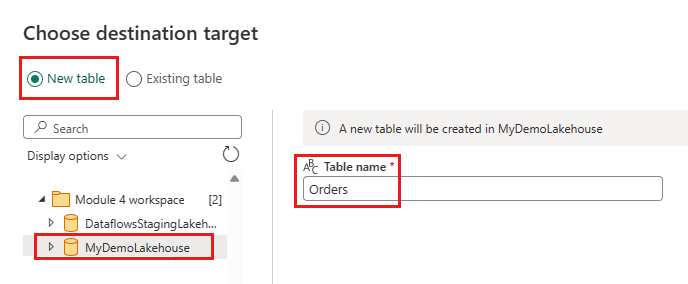
- Nombre de la nueva tabla:
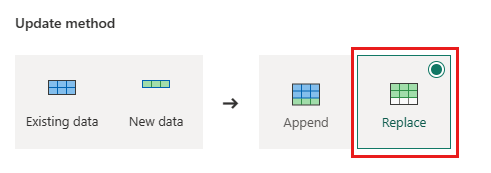
Orders - Método de actualización:
Replace
- destino de los datos:
Seleccione Siguiente y publique el flujo de datos.



Ahora ha creado un flujo de datos para cargar datos de un origen de OData en una instancia de LakeHouse. Este flujo de datos se usa en la sección siguiente para agregar una consulta al flujo de datos para filtrar los datos en función del destino de los datos. Después, puede usar el flujo de datos para volver a cargar datos mediante cuadernos y canalizaciones.
Agregar una consulta al flujo de datos para filtrar los datos en función del destino de datos
En esta sección se agrega una consulta al flujo de datos para filtrar los datos en función de los datos del lago de destino. La consulta obtiene el máximo OrderID en el almacén al principio de la actualización del flujo de datos y utiliza el OrderId máximo para obtener únicamente los pedidos con un OrderId más alto del origen para añadirlos a su destino de datos. Se supone que los pedidos se agregan al origen en orden ascendente de OrderID. Si no es así, puede usar una columna diferente para filtrar los datos. Por ejemplo, puede usar la OrderDate columna para filtrar los datos.
Nota:
Los filtros de OData se aplican dentro de Fabric después de recibir los datos del origen de datos; sin embargo, para orígenes de base de datos como SQL Server, el filtro se aplica en la consulta enviada al origen de datos back-end y solo se devuelven filas filtradas al servicio.
Una vez que se actualice el flujo de datos, vuelva a abrir el flujo de datos que creó en la sección anterior.
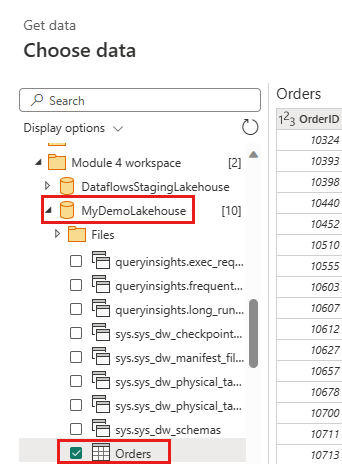
Cree una nueva consulta llamada
IncrementalOrderIDy obtenga los datos de la tabla Pedidos en el lago que creó en la sección anterior.
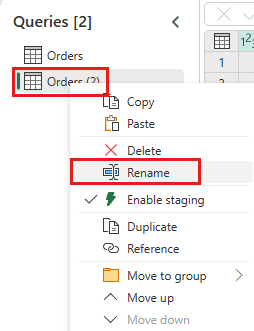
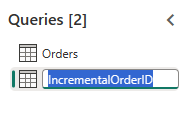
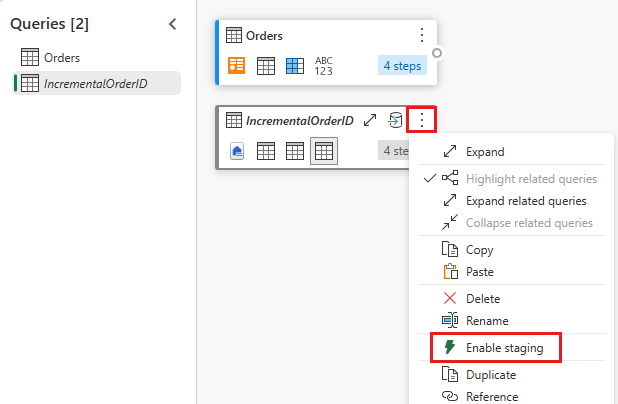
Deshabilite el almacenamiento provisional de esta consulta.
En la vista previa de datos, haga clic con el botón derecho en la
OrderIDcolumna y seleccione Explorar en profundidad.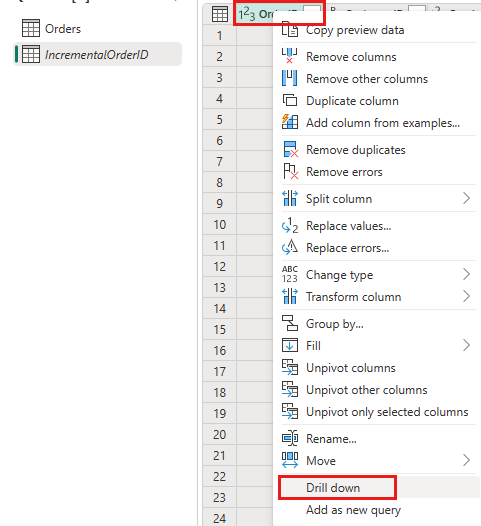
En la cinta de opciones, seleccione Herramientas de lista ->Estadísticas ->Máximo.
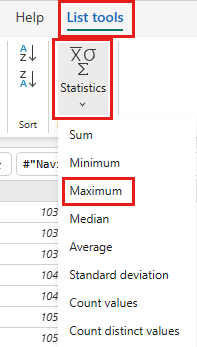
Ahora tiene una consulta que devuelve el valor máximo de OrderID en lakehouse. Esta consulta se usa para filtrar los datos del origen de OData. En la sección siguiente se agrega una consulta al flujo de datos para filtrar los datos del origen de OData según el valor máximo de OrderID en el lago.
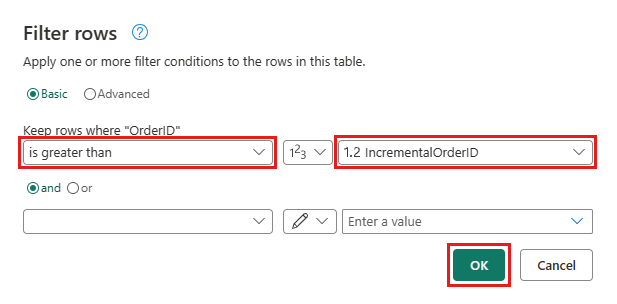
Volver a la consulta Pedidos y agregue un nuevo paso para filtrar los datos. Use la configuración siguiente:
- Columna:
OrderID - Operación de
Greater than: - Valor: parámetro
IncrementalOrderID

- Columna:
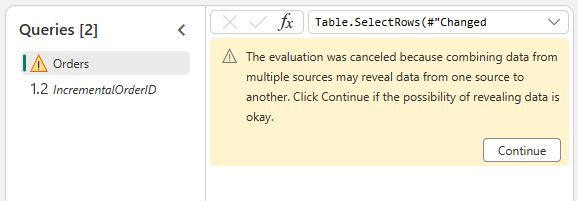
Permite combinar los datos del origen de OData y lakehouse mediante la confirmación del cuadro de diálogo siguiente:
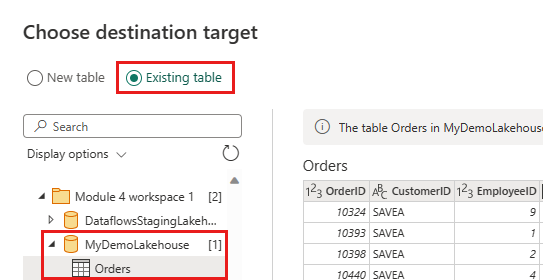
Actualice el destino de datos para usar la siguiente configuración:
- Método de actualización:
Append

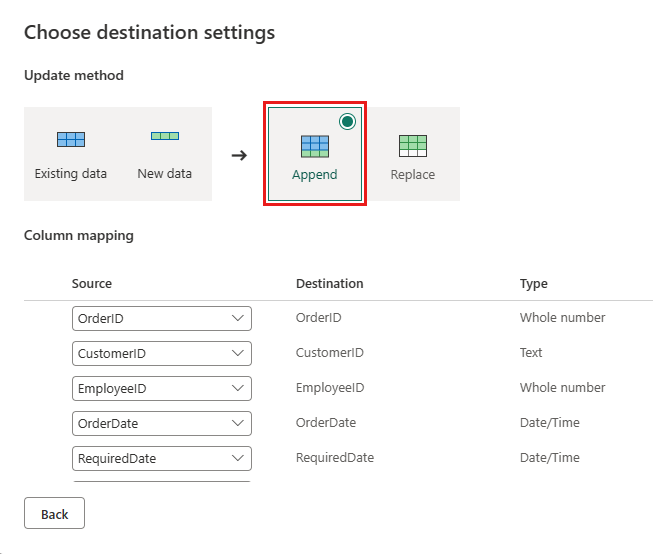
- Método de actualización:
Publicar el flujo de datos.
El flujo de datos ahora contiene una consulta que filtra los datos del origen de OData según el valor máximo de OrderID en la instancia de LakeHouse. Esto significa que solo se cargan datos nuevos o actualizados en el lago. En la sección siguiente se usa el flujo de datos para volver a cargar los datos mediante cuadernos y canalizaciones.
(Opcional) volver a cargar datos mediante cuadernos y canalizaciones
Opcionalmente, puede volver a cargar datos específicos mediante cuadernos y canalizaciones. Con el código de Python personalizado en el cuaderno, quite los datos antiguos de lakehouse. Después, cree una canalización en la que ejecute primero el cuaderno y ejecute secuencialmente el flujo de datos, vuelva a cargar los datos del origen de OData en el lago. Los cuadernos admiten varios lenguajes, pero en este tutorial se usa PySpark. Pyspark es una API de Python para Spark y se usa en este tutorial para ejecutar consultas de Spark SQL.
Creación de un nuevo cuaderno en el área de trabajo.
Añade el siguiente código PySpark a tu cuaderno:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Ejecute el cuaderno para comprobar que los datos se quitan de lakehouse.
Cree una canalización en el área de trabajo.
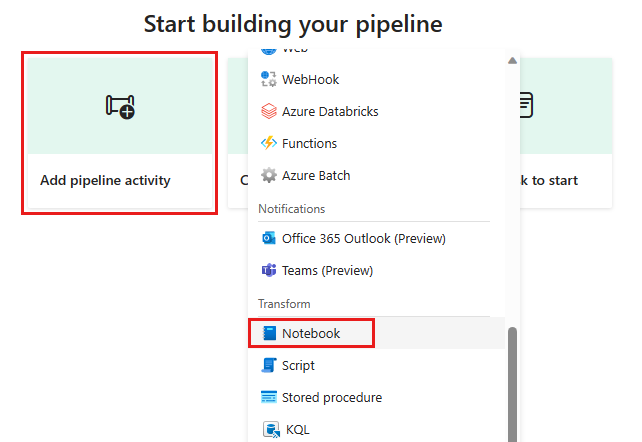
Agregue una nueva actividad de cuaderno a la canalización y seleccione el cuaderno que creó en el paso anterior.
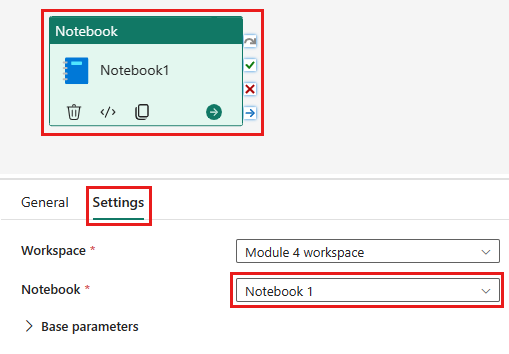
Agregue una nueva actividad de flujo de datos a la canalización y seleccione el flujo de datos que creó en la sección anterior.
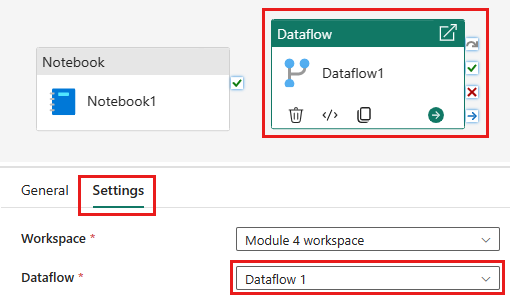
Vincule la actividad del cuaderno a la actividad de flujo de datos con un desencadenador correcto.
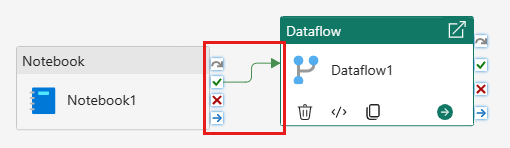
Guarde y ejecute la canalización.


Ahora tiene una canalización que quita los datos antiguos de lakehouse y vuelve a cargar los datos del origen de OData en lakehouse. Con esta configuración, puede volver a cargar los datos desde el origen de OData al almacén de lago de datos con regularidad.