Receta: Servicios de Azure AI: detección de anomalías multivariante
Esta receta muestra cómo puede usar SynapseML y servicios de Azure AI en Apache Spark para la detección de anomalías multivariante. La detección de anomalías multivariante permite la detección de anomalías entre muchas variables o series de tiempo, teniendo en cuenta todas las correlaciones y dependencias entre las distintas variables. En este escenario, usamos SynapseML para entrenar un modelo para la detección de anomalías multivariante mediante servicios de Azure AI y, a continuación, usamos el modelo para deducir anomalías multivariantes dentro de un conjunto de datos que contiene medidas sintéticas de tres sensores de IoT.
Importante
A partir del 20 de septiembre de 2023, no podrá crear nuevos recursos de Anomaly Detector. El servicio Anomaly Detector se retira el 1 de octubre de 2026.
Para obtener más información sobre Detector de anomalía de Azure AI, consulte esta página de documentación.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
- Adjunte el cuaderno a un almacén de lago. En el lado izquierdo, seleccione Añadir para añadir un almacén de lago existente o crear uno.
Configuración
Siga las instrucciones para crear un recurso Anomaly Detector mediante Azure Portal o, como alternativa, también puede usar la CLI de Azure para crear este recurso.
Después de configurar un Anomaly Detector, puede explorar los métodos de control de datos de varios formularios. El catálogo de servicios de Azure AI proporciona varias opciones: Visión, Voz, Lenguaje, Búsqueda web, Decisión, Traducción e Inteligencia de documentos.
Creación de un recurso de Anomaly Detector
- En Azure Portal, seleccione Crear en el grupo de recursos y, a continuación, escriba Anomaly Detector. Seleccione el recurso Anomaly Detector.
- Asigne un nombre al recurso e, idealmente, use la misma región que el resto del grupo de recursos. Use las opciones predeterminadas para el resto, seleccione Revisar y crear y, a continuación, Crear.
- Una vez creado el recurso Anomaly Detector, ábralo y seleccione el panel
Keys and Endpointsen el panel de navegación izquierdo. Copie la clave del recurso Anomaly Detector en la variable de entornoANOMALY_API_KEYo almacénela en la variableanomalyKey.
Creación de un recurso de cuenta de almacenamiento
Para guardar los datos intermedios, debe crear una cuenta de Azure Blob Storage. Dentro de esa cuenta de almacenamiento, cree un contenedor para almacenar los datos intermedios. Anote el nombre del contenedor y copie la cadena de conexión en ese contenedor. La necesitará más adelante para rellenar la variable containerName y la variable de entorno BLOB_CONNECTION_STRING.
Escriba las claves del servicio.
Comencemos con la configuración de las variables de entorno para nuestras claves de servicio. La celda siguiente establece las variables de entorno ANOMALY_API_KEY y BLOB_CONNECTION_STRING en función de los valores almacenados en nuestra instancia de Azure Key Vault. Si está ejecutando este tutorial en su propio entorno, asegúrese de establecer estas variables de entorno antes de continuar.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Ahora, vamos a leer las variables de entorno ANOMALY_API_KEY y BLOB_CONNECTION_STRING y establecer las variables containerName y location.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
En primer lugar, nos conectamos a nuestra cuenta de almacenamiento para que el detector de anomalías pueda guardar los resultados intermedios allí:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Vamos a importar todos los módulos necesarios.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Ahora, vamos a leer los datos de ejemplo en un DataFrame de Spark.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Ahora podemos crear un objeto estimator, que se usa para entrenar el modelo. Especificamos las horas de inicio y finalización de los datos de entrenamiento. También se especifican las columnas de entrada que se van a usar y el nombre de la columna que contiene las marcas de tiempo. Por último, especificamos el número de puntos de datos que se van a usar en la ventana deslizante de detección de anomalías y establecemos la cadena de conexión en la cuenta de Azure Blob Storage.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Ahora que hemos creado estimator, vamos a ajustarlo a los datos:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Cuando llamamos a .show(5) en la celda anterior, nos mostró las cinco primeras filas del dataframe. Los resultados fueron todos null porque no estaban dentro de la ventana de inferencia.
Para mostrar los resultados solo para los datos inferidos, vamos a seleccionar las columnas que necesitamos. Después, podemos ordenar las filas del dataframe por orden ascendente y filtrar el resultado para mostrar solo las filas que se encuentran en el intervalo de la ventana de inferencia. En nuestro caso inferenceEndTime es el mismo que la última fila del dataframe, por lo que puede ignorarlo.
Por último, para poder trazar mejor los resultados, vamos a convertir el dataframe de Spark en un dataframe de Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Dé formato a la columna contributors que almacena la puntuación de contribución de cada sensor a las anomalías detectadas. La celda siguiente da formato a estos datos y divide la puntuación de contribución de cada sensor en su propia columna.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Magnífico. Ahora tenemos las puntuaciones de contribución de los sensores 1, 2 y 3 en las columnas series_0, series_1 y series_2 respectivamente.
Ejecute la celda siguiente para trazar los resultados. El parámetro minSeverity especifica la gravedad mínima de las anomalías que se van a trazar.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
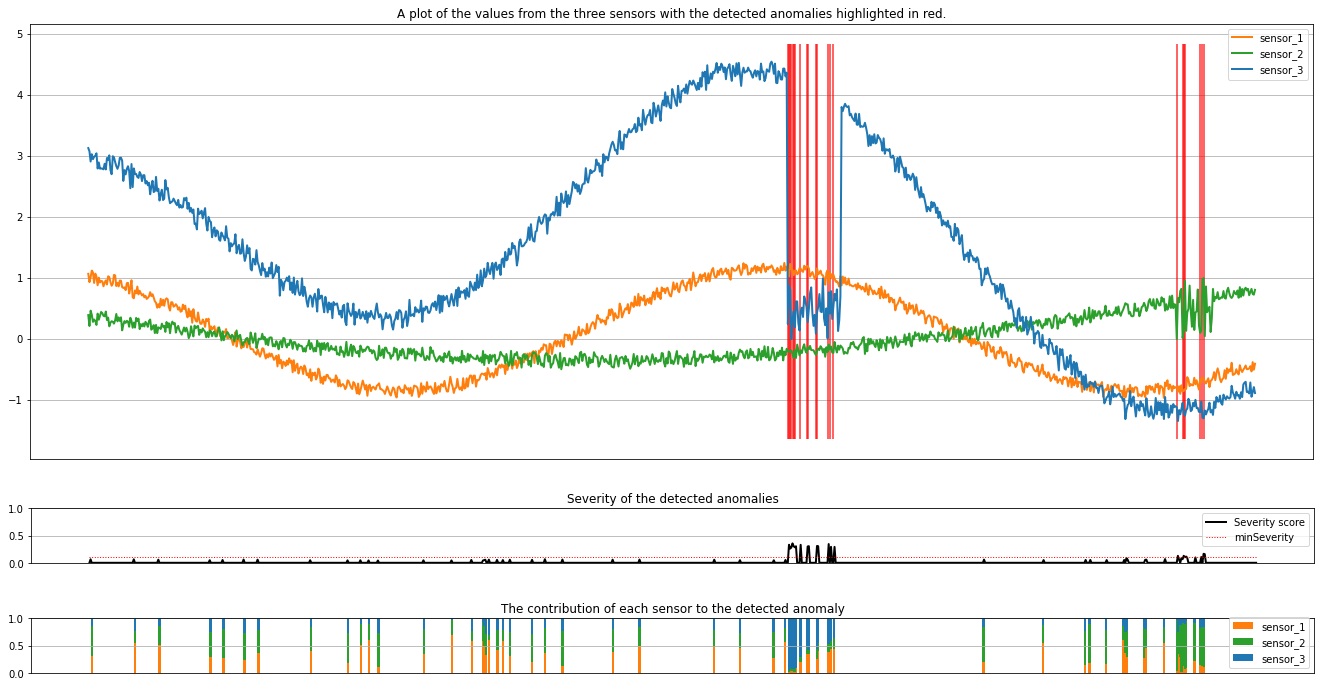
Los trazados muestran los datos sin procesar de los sensores (dentro de la ventana de inferencia) en naranja, verde y azul. Las líneas verticales rojas de la primera ilustración muestran las anomalías detectadas que tienen una gravedad mayor o igual a minSeverity.
En el segundo trazado se muestra la puntuación de gravedad de todas las anomalías detectadas, y el umbral minSeverity se muestra en la línea roja punteada.
Por último, el último gráfico muestra la contribución de los datos de cada sensor a las anomalías detectadas. Nos ayuda a diagnosticar y comprender la causa más probable de cada anomalía.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de