Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Microsoft Fabric permite poner en marcha modelos machine learning mediante la función PREDICT escalable. Esta función admite la puntuación por lotes en cualquier motor de proceso. Puede generar predicciones por lotes directamente desde un cuaderno de Microsoft Fabric o desde la página de elementos de un modelo de ML determinado.
En este artículo, aprenderá a aplicar PREDICT escribiendo código usted mismo o mediante el uso de una experiencia de interfaz de usuario guiada que controla la puntuación por lotes automáticamente.
Requisitos previos
Obtenga una suscripción Microsoft Fabric. O bien, regístrese para obtener una prueba gratuita Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Cambie a Fabric mediante el conmutador de experiencia en el lado inferior izquierdo de la página principal.

Limitaciones
- La función PREDICT admite actualmente solo los siguientes tipos de modelo de ML:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT requiere que guarde los modelos de ML en el formato MLflow, con sus firmas rellenadas.
- PREDICT no admite modelos de aprendizaje automático con entradas o salidas multitensor.
Llamar a PREDICT desde un notebook
PREDICT admite modelos empaquetados de MLflow en el registro de Microsoft Fabric. Si ya existe un modelo de Machine Learning entrenado y registrado en el área de trabajo, puede ir directamente al paso 2. Si no es así, el paso 1 proporciona código de ejemplo para guiarle a través del entrenamiento de un modelo de regresión logística de ejemplo. Use este modelo para generar predicciones por lotes al final del procedimiento.
Entrene un modelo de Machine Learning y regístrelo con MLflow. En el ejemplo de código siguiente se usa la API de MLflow para crear un experimento de machine learning y, a continuación, se inicia una ejecución de MLflow para un modelo de regresión logística scikit-learn. A continuación, la versión del modelo se almacena y registra en el registro de Microsoft Fabric. Para obtener más información sobre los modelos de entrenamiento y el seguimiento de sus propios experimentos, consulte cómo entrenar modelos de ML con scikit-learn.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Cargue datos de prueba como un DataFrame de Spark. Para generar predicciones por lotes con el modelo de Machine Learning entrenado en el paso anterior, necesita datos de prueba en forma de un DataFrame de Spark. En el código siguiente, sustituya el valor de la variable
testpor sus propios datos.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Cree un objeto
MLFlowTransformerpara cargar el modelo de Machine Learning para la inferencia. Para crear unMLFlowTransformerobjeto para generar predicciones por lotes, realice estas acciones:- Especifique las
testcolumnas DataFrame que necesita como entradas del modelo (en este caso, todas ellas). - Elija un nombre para la nueva columna de salida (en este caso,
predictions). - Proporcione el nombre de modelo y la versión del modelo correctos para la generación de esas predicciones.
Si usa su propio modelo, sustituya los valores de las columnas de entrada, el nombre de la columna de salida, el nombre del modelo de Machine Learning y la versión del modelo.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- Especifique las
Genere predicciones mediante la función PREDICT. Para invocar la función PREDICT, use la API Transformer, la API Spark SQL o una función definida por el usuario (UDF) de PySpark. En las secciones siguientes se muestra cómo generar predicciones por lotes con los datos de prueba y el modelo de Machine Learning definidos en los pasos anteriores mediante los distintos métodos para invocar la función PREDICT.
PREDICT con la API Transformer
Este código invoca la función PREDICT con la API Transformer. Si usa su propio modelo de Machine Learning, sustituya los valores del modelo y los datos de prueba.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT con la API Spark SQL
Este código llama a la función PREDICT mediante la API de SQL de Spark. Si usa su propio modelo de ML, reemplace los valores de model_name, model_versiony features por el nombre del modelo, la versión del modelo y las columnas de características.
Nota:
Cuando se usa la Spark SQL API para generar predicciones, todavía debe crear un objeto MLFlowTransformer, como se muestra en el paso 3.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT con una función definida por el usuario
Este código llama a la función PREDICT mediante una UDF de PySpark. Si usa su propio modelo de ML, reemplace los valores del modelo y las características.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generación de código PREDICT desde la página de elementos de un modelo de Machine Learning
En la página de elementos de cualquier modelo de ML, puede elegir una de estas opciones para iniciar la generación de predicciones por lotes para una versión de modelo específica mediante la función PREDICT:
- Copie una plantilla de código en un cuaderno y personalice los parámetros usted mismo.
- Use una experiencia de interfaz de usuario guiada para generar código PREDICT.
Uso de una experiencia de interfaz de usuario guiada
La experiencia de la interfaz de usuario guiada le guía por estos pasos:
- Seleccione los datos de origen para puntuar.
- Asigne los datos correctamente a las entradas del modelo de aprendizaje automático.
- Especifique el destino de las salidas del modelo.
- Cree un cuaderno que use PREDICT para generar y almacenar resultados de predicción.
Para utilizar la experiencia asistida,
Vaya a la página de elementos de una versión de modelo de ML determinada.
En la lista desplegable Aplicar esta versión, seleccione Aplicar este modelo en el asistente.
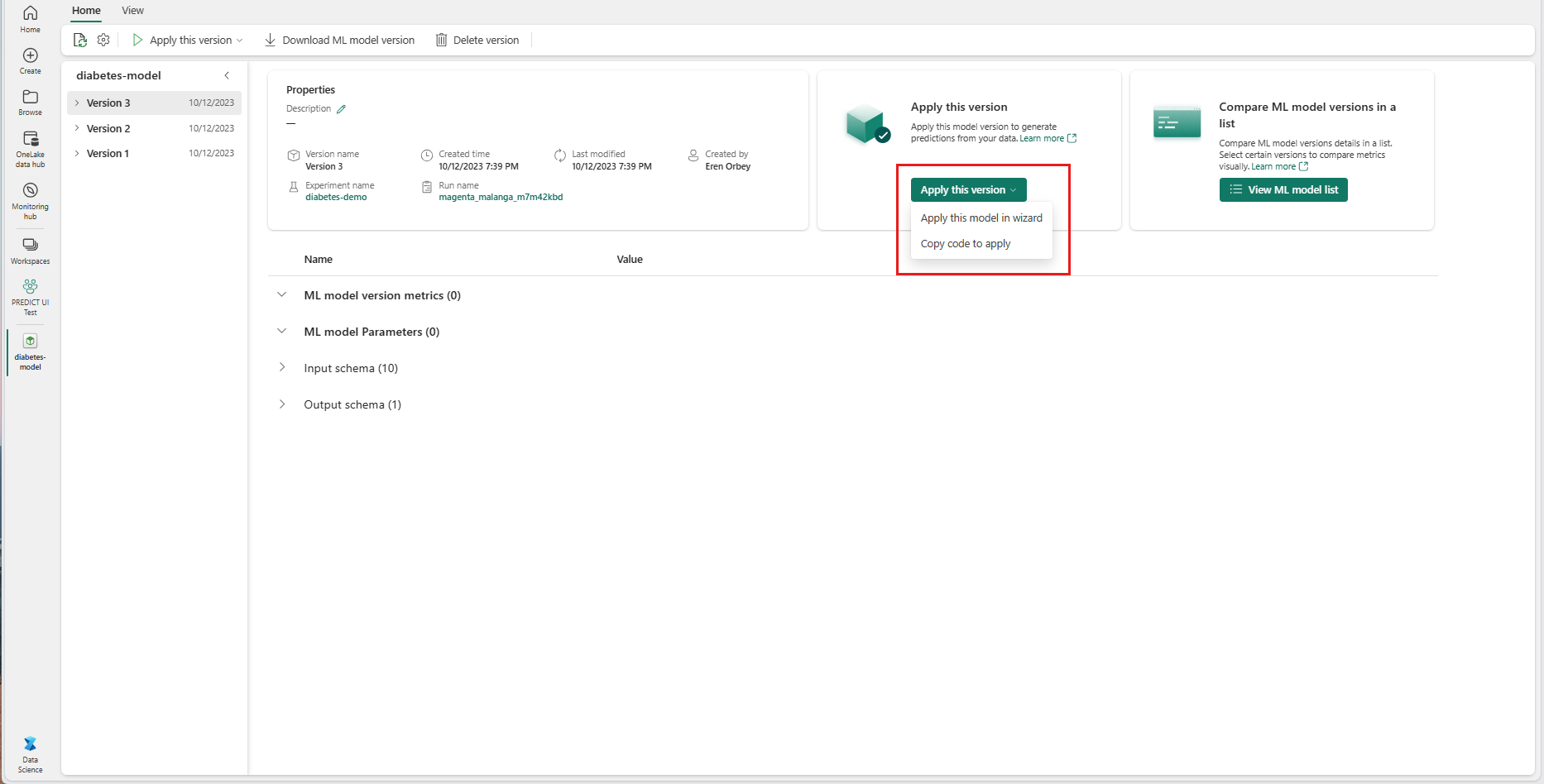
En el paso "Seleccionar tabla de entrada", se abre la ventana "Aplicar predicciones del modelo de ML".
Seleccione una tabla de origen de un lakehouse de datos en su área de trabajo actual.
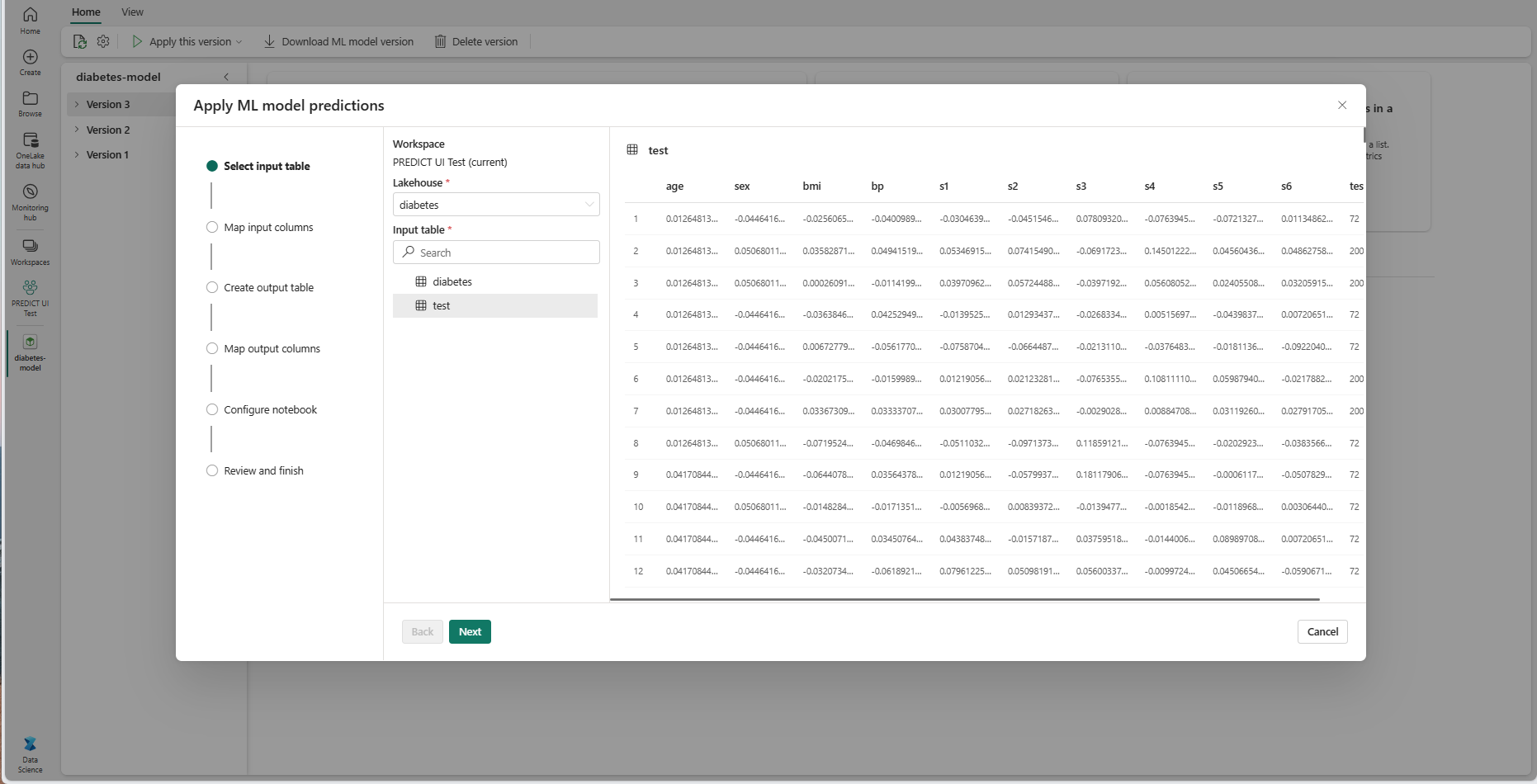
Seleccione Siguiente para ir al paso "Asignar columnas de entrada".
Asigne los nombres de columna de la tabla de origen a los campos de entrada del modelo de aprendizaje automático, que se obtienen de la firma del modelo. Debe proporcionar una columna de entrada para todos los campos obligatorios del modelo. Además, los tipos de datos de columna de origen deben coincidir con los tipos de datos esperados del modelo.
Sugerencia
El asistente rellena previamente esta asignación si los nombres de las columnas de la tabla de entrada coinciden con los nombres de columna registrados en la firma del modelo de aprendizaje automático.
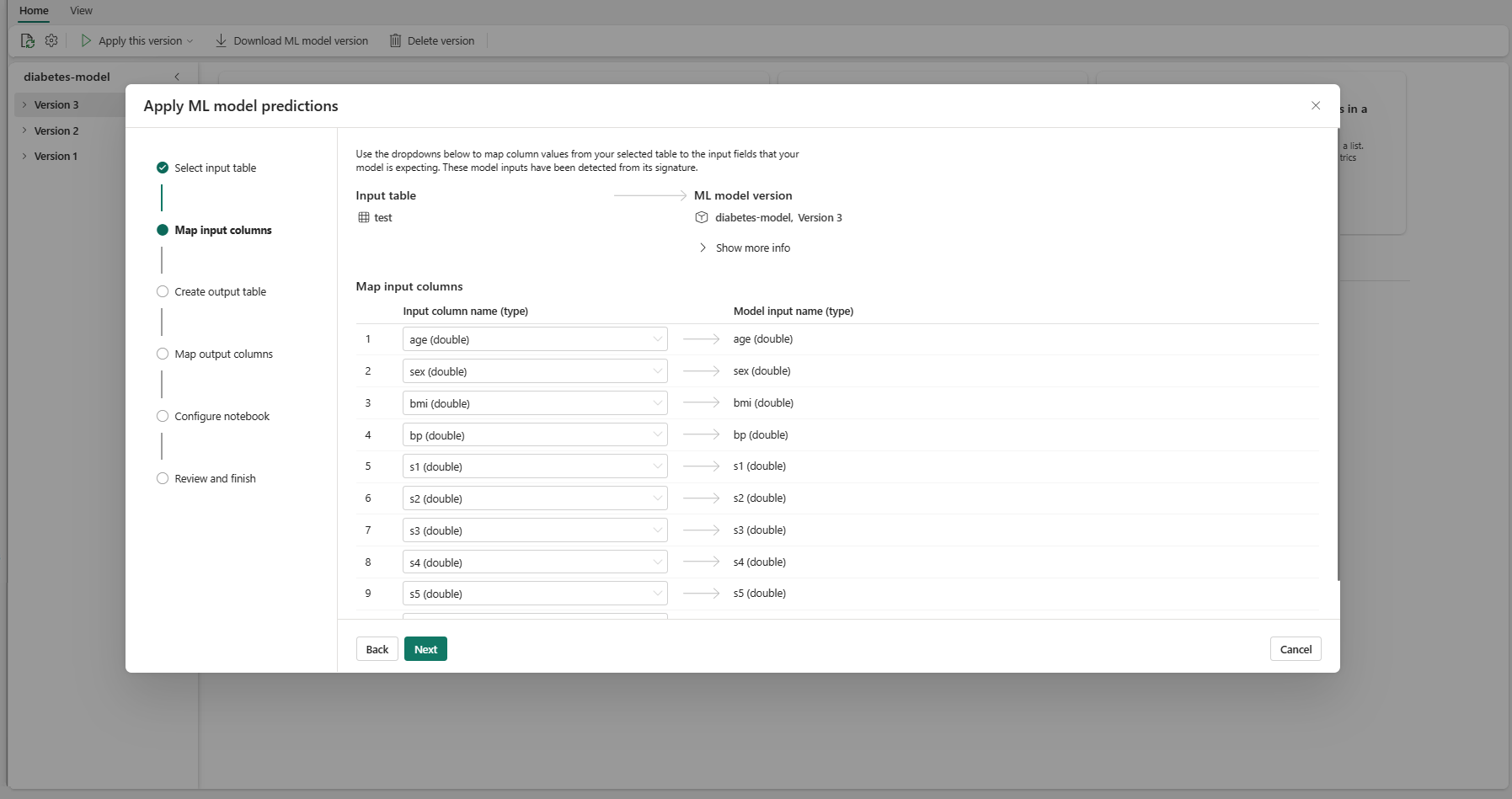
Seleccione Siguiente para ir al paso "Crear tabla de salida".
Proporcione un nombre para una nueva tabla dentro del lakehouse seleccionado de su área de trabajo actual. Esta tabla de salida almacena los valores de entrada del modelo de ML y anexa los valores de predicción a esa tabla. De forma predeterminada, la tabla de salida se crea en el mismo lago que la tabla de entrada. Puede cambiar el lakehouse de datos de destino.
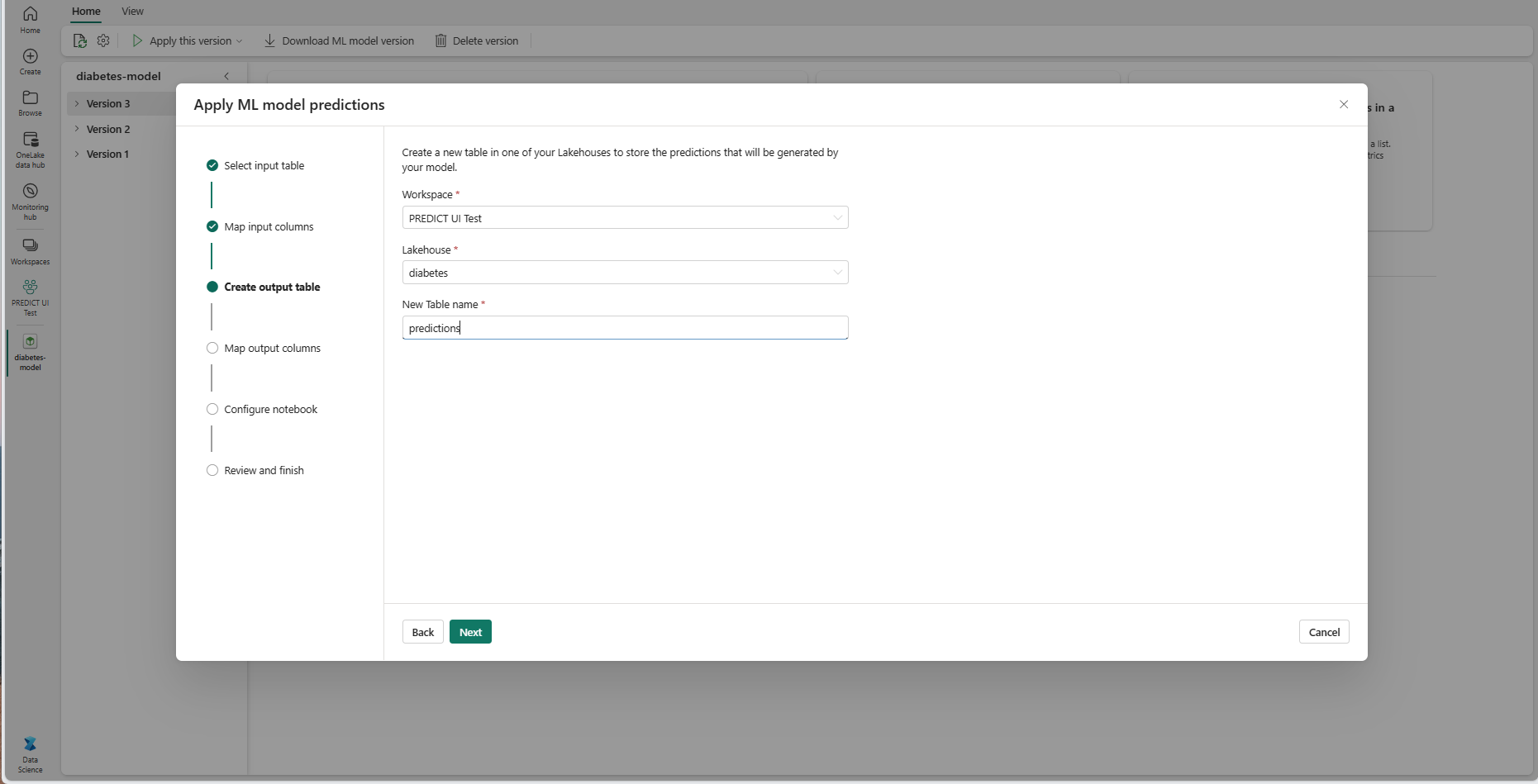
Seleccione Siguiente para ir al paso "Asignar columnas de salida".
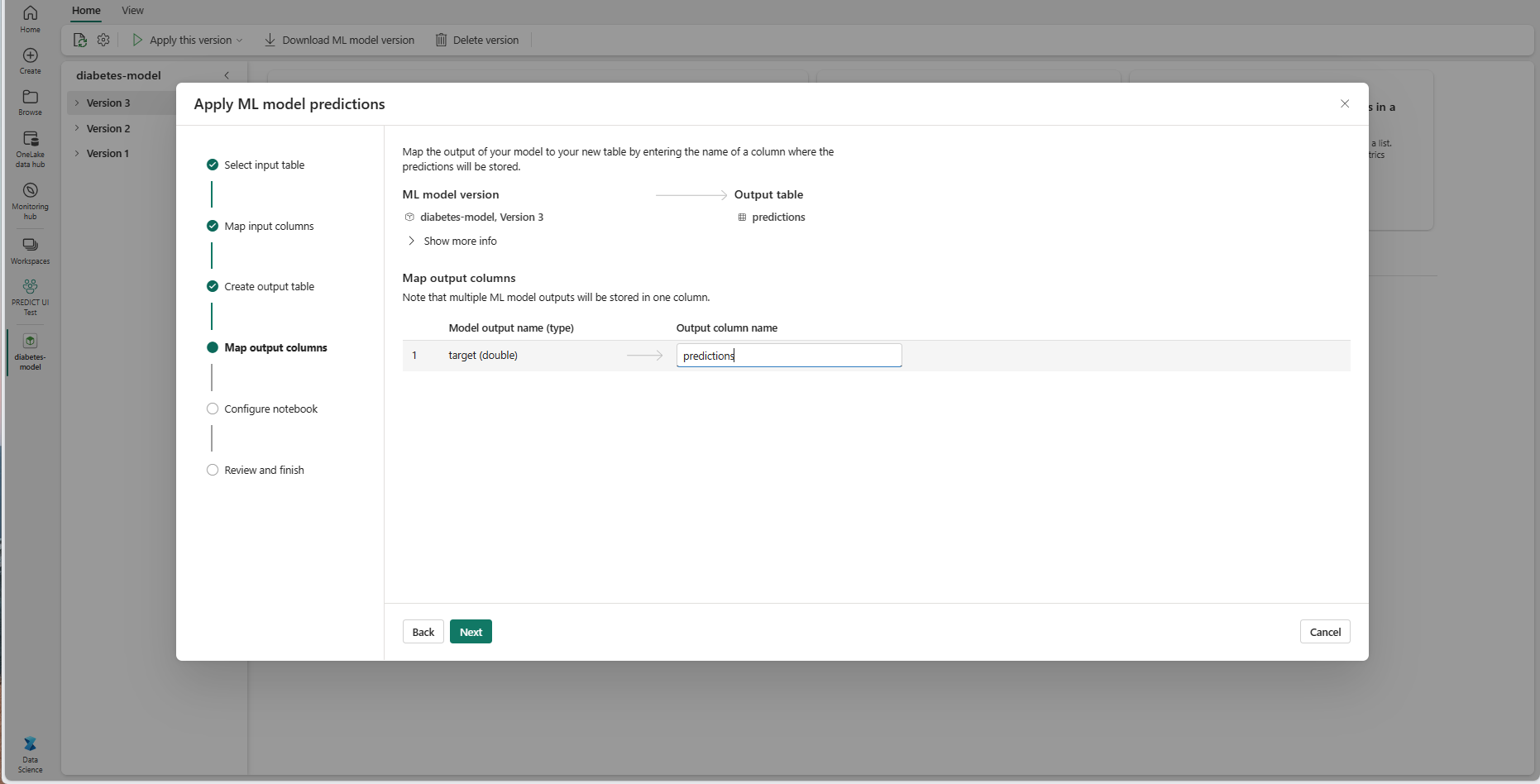
Use los campos de texto proporcionados para asignar un nombre a las columnas de la tabla de salida que almacena las predicciones del modelo de ML.
Seleccione Siguiente para ir al paso "Configurar cuaderno".
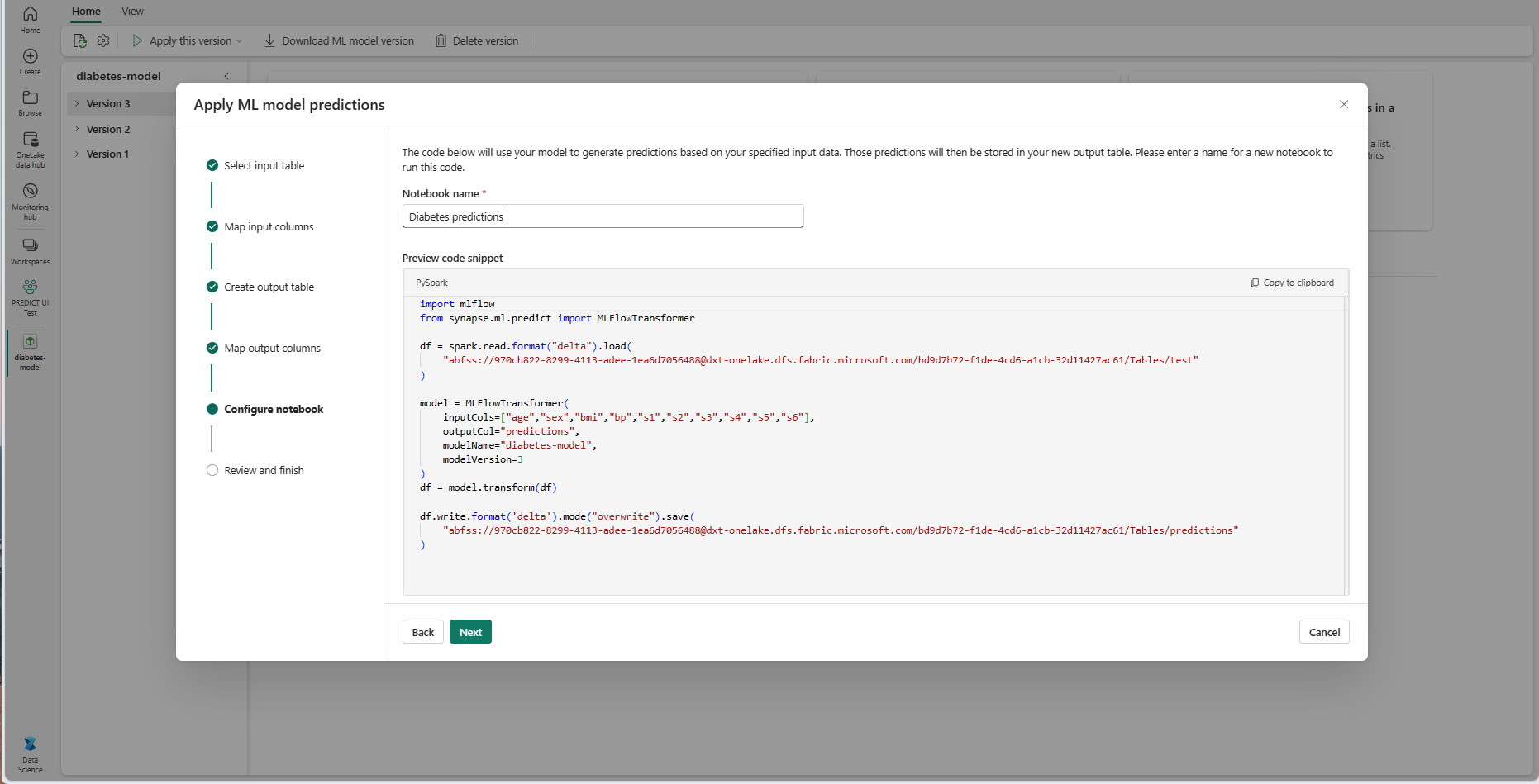
Proporcione un nombre para un nuevo cuaderno que ejecute el código PREDICT generado. El asistente muestra una vista previa del código generado en este paso. Si lo desea, puede copiar el código en el Portapapeles y pegarlo en un cuaderno existente.
Seleccione Siguiente para ir al paso "Revisar y finalizar".
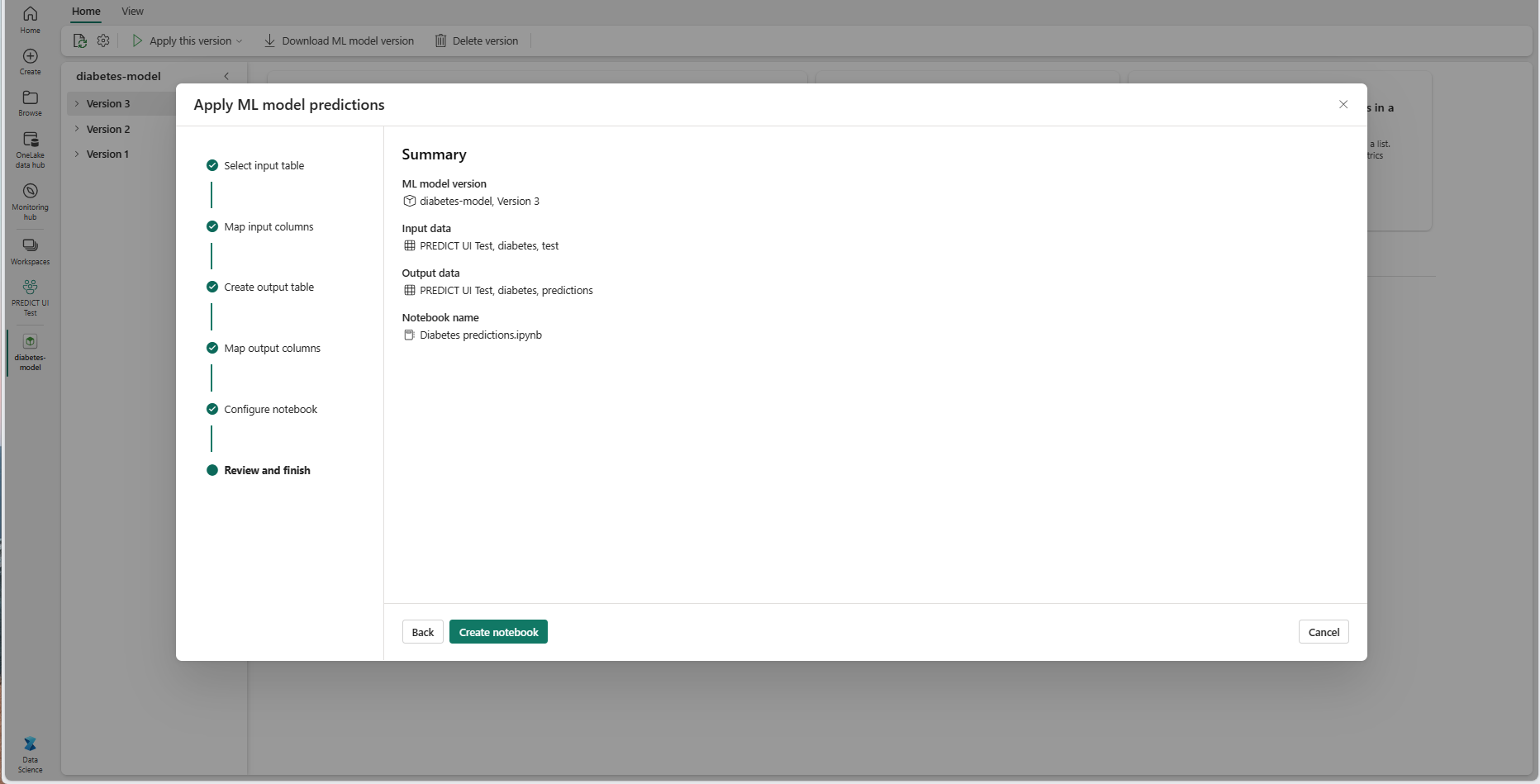
Revise los detalles de la página de resumen y seleccione Crear cuaderno para agregar el nuevo cuaderno con su código generado al área de trabajo. Se le llevará directamente a ese cuaderno, donde puede ejecutar el código para generar y almacenar predicciones.







Uso de una plantilla de código personalizable
Para usar una plantilla de código para generar predicciones por lotes:
- Vaya a la página de elementos de la versión de un modelo de Machine Learning determinado.
- Seleccione Copiar código para aplicar en la lista desplegable Aplicar esta versión. La selección copia una plantilla de código personalizable.
Puede pegar esta plantilla de código en un cuaderno para generar predicciones por lotes con el modelo de Machine Learning. Para ejecutar correctamente la plantilla de código, reemplace manualmente los valores siguientes:
-
<INPUT_TABLE>: La ruta de acceso al archivo de la tabla que proporciona entradas al modelo de ML. -
<INPUT_COLS>: Un array de nombres de columnas de la tabla de entrada para alimentar al modelo de ML. -
<OUTPUT_COLS>: un nombre para una nueva columna de la tabla de salida que almacena predicciones. -
<MODEL_NAME>: el nombre del modelo de ML que se va a usar para generar predicciones. -
<MODEL_VERSION>: la versión del modelo de ML que se va a usar para generar predicciones. -
<OUTPUT_TABLE>: ruta de acceso del archivo para la tabla que almacena las predicciones.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)