Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial se presenta un ejemplo completo de un flujo de trabajo de ciencia de datos de Synapse en Microsoft Fabric. En este escenario, creamos un modelo de detección de fraudes, en R, con algoritmos de aprendizaje automático entrenados en datos históricos. A continuación, usamos el modelo para detectar transacciones fraudulentas futuras.
En este tutorial se describen estos pasos:
- Instalación de bibliotecas personalizadas
- Carga de los datos
- Descripción y procesamiento de los datos con análisis exploratorio de datos, y representación del uso de la característica Limpieza y transformación de datos de Fabric
- Entrenamiento de modelos de aprendizaje automático con LightGBM
- Uso de los modelos de Machine Learning para la puntuación y las predicciones
Prerrequisitos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Use el conmutador de experiencia en la parte inferior izquierda de la página principal para cambiar a Fabric.

- Si es necesario, cree un almacén de lago de datos de Microsoft Fabric como se describe en Creación de un almacén de lago de datos en Microsoft Fabric.
Seguimiento en un cuaderno
Puedes elegir una de estas opciones para tomar notas en un cuaderno:
- Abra y ejecute el cuaderno integrado en la experiencia de ciencia de datos de Synapse
- Carga tu cuaderno desde GitHub a la experiencia de ciencia de datos de Synapse
Abra el cuaderno integrado.
El cuaderno de ejemplo de detección de fraude acompaña a este tutorial.
Para abrir el cuaderno de ejemplo de este tutorial, siga las instrucciones de Preparar el sistema para tutoriales de ciencia de datos.
Asegúrese de adjuntar un almacén de lago de datos al cuaderno antes de ejecutar el código.
Importación del cuaderno desde GitHub
El cuaderno AIsample - R Fraud Detection.ipynb acompaña este tutorial.
A fin de abrir el cuaderno complementario para este tutorial, siga las instrucciones de Preparación del sistema para los tutoriales de ciencia de datos, para importar el cuaderno al área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar un almacén de lago de datos al cuaderno antes de empezar a ejecutar código.
Paso 1: Instalación de bibliotecas personalizadas
Para el desarrollo de modelos de Machine Learning o el análisis de datos ad hoc, es posible que tenga que instalar rápidamente una biblioteca personalizada para la sesión de Apache Spark. Tiene dos opciones para instalar bibliotecas.
- Use recursos de instalación integrados, por ejemplo,
install.packagesydevtools::install_version, para instalar solo en el bloc de notas actual. - Como alternativa, puede crear un entorno de Fabric, instalar bibliotecas desde orígenes públicos o cargar bibliotecas personalizadas en él y, a continuación, el administrador del área de trabajo puede asociar el entorno como valor predeterminado para el área de trabajo. Todas las bibliotecas del entorno estarán disponibles para su uso en los cuadernos y las definiciones de trabajo de Spark en el área de trabajo. Para obtener más información sobre los entornos, consulte crear, configurar y usar un entorno en Microsoft Fabric.
En este tutorial, use install.version() para instalar la biblioteca de aprendizaje desequilibrado:
# Install dependencies
devtools::install_version("bnlearn", version = "4.8")
# Install imbalance for SMOTE
devtools::install_version("imbalance", version = "1.0.2.1")
Paso 2: Cargar los datos
El conjunto de datos de detección de fraudes contiene transacciones de tarjetas de crédito de septiembre de 2013, que los titulares de tarjetas europeos realizaron a lo largo de dos días. El conjunto de datos solo contiene características numéricas debido a una transformación análisis de componentes principal (PCA) aplicada a las características originales. PCA transformó todas las características excepto Time y Amount. Para proteger la confidencialidad, no podemos proporcionar las características originales ni más información general sobre el conjunto de datos.
Estos detalles describen el conjunto de datos:
- Las características de
V1,V2,V3, ...,V28son los componentes principales obtenidos con PCA. - La característica
Timecontiene los segundos transcurridos entre una transacción y la primera transacción del conjunto de datos. - La característica
Amountes la cantidad de transacción. Puede utilizar esta función para el aprendizaje dependiente de ejemplos y sensible a costos. - La columna
Classes la variable de respuesta (destino). Tiene el valor1para fraude y0en otros casos.
Solo 492 transacciones, de 284.807 transacciones totales, son fraudulentas. El conjunto de datos está muy desequilibrado, ya que la clase minoritaria (fraudulenta) representa solo aproximadamente 0,172% de los datos.
En esta tabla se muestra una vista previa de los datos de creditcard.csv:
| Tiempo | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Importe | Clase |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.3598071336738 | -0.0727811733098497 | 2.53634673796914 | 1,37815522427443 | -0,338320769942518 | 0.462387777762292 | 0.239598554061257 | 0.0986979012610507 | 0.363786969611213 | 0.0907941719789316 | -0.551599533260813 | -0.617800855762348 | -0.991389847235408 | -0.311169353699879 | 1.46817697209427 | -0.470400525259478 | 0,207971241929242 | 0.0257905801985591 | 0.403992960255733 | 0.251412098239705 | -0.018306777944153 | 0.277837575558899 | -0.110473910188767 | 0.0669280749146731 | 0.128539358273528 | -0.189114843888824 | 0.133558376740387 | -0.0210530534538215 | 149.62 | "0" |
| 0 | 1,19185711131486 | 0.26615071205963 | 0.16648011335321 | 0.448154078460911 | 0.0600176492822243 | -0.0823608088155687 | -0.0788029833323113 | 0.0851016549148104 | -0.255425128109186 | -0.166974414004614 | 1,61272666105479 | 1.06523531137287 | 0.48909501589608 | -0.143772296441519 | 0,635558093258208 | 0,463917041022171 | -0.114804663102346 | -0.183361270123994 | -0.145783041325259 | -0.0690831352230203 | -0.225775248033138 | -0.638671952771851 | 0.101288021253234 | -0.339846475529127 | 0.167170404418143 | 0.125894532368176 | -0.00898309914322813 | 0.0147241691924927 | 2,69 | "0" |
Descarga el conjunto de datos y cárgalo en el lakehouse
Defina estos parámetros para poder usar este cuaderno con diferentes conjuntos de datos:
IS_CUSTOM_DATA <- FALSE # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE <- FALSE # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS <- 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT <- "/lakehouse/default"
DATA_FOLDER <- "Files/fraud-detection" # Folder with data files
DATA_FILE <- "creditcard.csv" # Data file name
Este código descarga una versión disponible públicamente del conjunto de datos y, a continuación, la almacena en una instancia de Fabric Lakehouse.
Importante
Asegúrese de agregar un almacén de lago de datos al cuaderno antes de ejecutarlo. De lo contrario, se producirá un error.
if (!IS_CUSTOM_DATA) {
# Download data files into a lakehouse if they don't exist
library(httr)
remote_url <- "https://synapseaisolutionsa.blob.core.windows.net/public/Credit_Card_Fraud_Detection"
fname <- "creditcard.csv"
download_path <- file.path(DATA_ROOT, DATA_FOLDER, "raw")
dir.create(download_path, showWarnings = FALSE, recursive = TRUE)
if (!file.exists(file.path(download_path, fname))) {
r <- GET(file.path(remote_url, fname), timeout(30))
writeBin(content(r, "raw"), file.path(download_path, fname))
}
message("Downloaded demo data files into lakehouse.")
}
Lectura de datos sin procesar desde el almacén de lago de datos
Este código lee datos sin procesar de la sección Archivos del lago de datos:
data_df <- read.csv(file.path(DATA_ROOT, DATA_FOLDER, "raw", DATA_FILE))
Paso 3: Realizar análisis de datos exploratorios
Use el comando display para ver las estadísticas de alto nivel del conjunto de datos:
display(as.DataFrame(data_df, numPartitions = 3L))
# Print dataset basic information
message(sprintf("records read: %d", nrow(data_df)))
message("Schema:")
str(data_df)
# If IS_SAMPLE is True, use only SAMPLE_ROWS of rows for training
if (IS_SAMPLE) {
data_df = sample_n(data_df, SAMPLE_ROWS)
}
Imprima la distribución de clases en el conjunto de datos:
# The distribution of classes in the dataset
message(sprintf("No Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 0)/nrow(data_df) * 100, 2)))
message(sprintf("Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 1)/nrow(data_df) * 100, 2)))
Esta distribución de clases muestra que la mayoría de las transacciones no sonfraudulentes. Por lo tanto, el preprocesamiento de datos es necesario antes del entrenamiento del modelo para evitar el sobreajuste.
Ver la distribución de transacciones fraudulentas frente a nofraudulentes
Vea la distribución de transacciones fraudulentas frente a nofraudulentes con un trazado para mostrar el desequilibrio de clases en el conjunto de datos:
library(ggplot2)
ggplot(data_df, aes(x = factor(Class), fill = factor(Class))) +
geom_bar(stat = "count") +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Class Distributions \n (0: No Fraud || 1: Fraud)") +
theme(plot.title = element_text(size = 10))
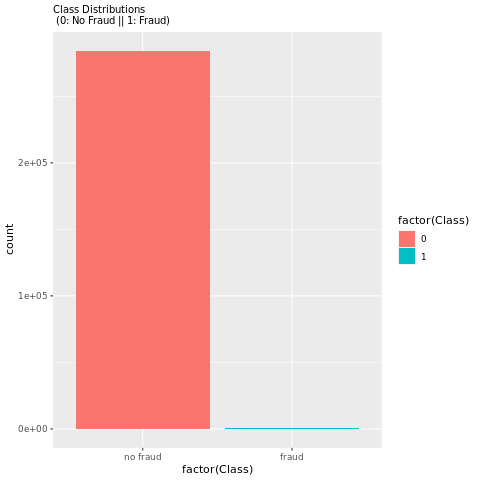
El gráfico muestra claramente el desequilibrio del conjunto de datos:
Mostrar el resumen de cinco números
Muestra el resumen de cinco números (puntuación mínima, primer cuartil, mediana, tercer cuartil y puntuación máxima) para el importe de la transacción, con trazados de cuadros:
library(ggplot2)
library(dplyr)
ggplot(data_df, aes(x = as.factor(Class), y = Amount, fill = as.factor(Class))) +
geom_boxplot(outlier.shape = NA) +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Boxplot without Outliers") +
coord_cartesian(ylim = quantile(data_df$Amount, c(0.05, 0.95)))
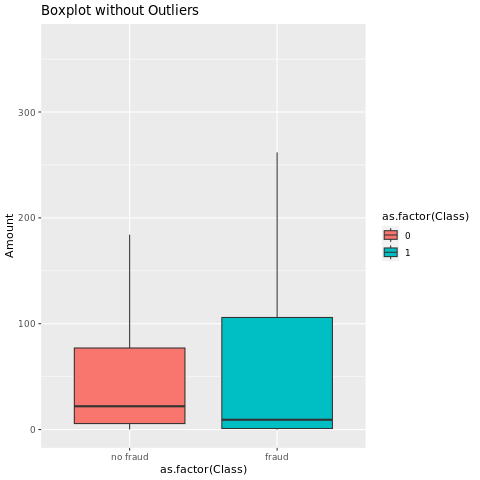
En el caso de datos muy desequilibrados, es posible que los diagramas de caja no muestren información precisa. Sin embargo, puede abordar primero el problema de desequilibrio Class y, a continuación, crear los mismos gráficos para obtener información más precisa.
Paso 4: Entrenamiento y evaluación de los modelos
Aquí, entrenas un modelo LightGBM para clasificar las transacciones de fraude. Se entrena un modelo LightGBM tanto en conjuntos de datos desequilibrados como equilibrados. A continuación, comparará el rendimiento de ambos modelos.
Preparación de conjuntos de datos de entrenamiento y prueba
Antes del entrenamiento, divida los datos en los conjuntos de datos de entrenamiento y prueba:
# Split the dataset into training and test datasets
set.seed(42)
train_sample_ids <- base::sample(seq_len(nrow(data_df)), size = floor(0.85 * nrow(data_df)))
train_df <- data_df[train_sample_ids, ]
test_df <- data_df[-train_sample_ids, ]
Aplicación de SMOTE al conjunto de datos de entrenamiento
La clasificación desbalanceada tiene un problema. Tiene demasiados pocos ejemplos de clase minoritaria para que un modelo aprenda eficazmente a identificar el límite de decisión. La técnica de sobremuestreo de minorías sintéticas (SMOTE) puede controlar este problema. SMOTE es el enfoque más utilizado para sintetizar nuevas muestras para la clase minoría. Puede acceder a SMOTE mediante la biblioteca de imbalance que instaló en el paso 1.
Aplique SMOTE solo al conjunto de datos de entrenamiento, en lugar del conjunto de datos de prueba. Al puntuar el modelo con los datos de prueba, necesita una aproximación del rendimiento del modelo en datos no vistos en producción. Para una aproximación válida, tus datos de prueba se basan en la distribución desequilibrada original para representar los datos de producción tan cerca como sea posible.
# Apply SMOTE to the training dataset
library(imbalance)
# Print the shape of the original (imbalanced) training dataset
train_y_categ <- train_df %>% select(Class) %>% table
message(
paste0(
"Original dataset shape ",
paste(names(train_y_categ), train_y_categ, sep = ": ", collapse = ", ")
)
)
# Resample the training dataset by using SMOTE
smote_train_df <- train_df %>%
mutate(Class = factor(Class)) %>%
oversample(ratio = 0.99, method = "SMOTE", classAttr = "Class") %>%
mutate(Class = as.integer(as.character(Class)))
# Print the shape of the resampled (balanced) training dataset
smote_train_y_categ <- smote_train_df %>% select(Class) %>% table
message(
paste0(
"Resampled dataset shape ",
paste(names(smote_train_y_categ), smote_train_y_categ, sep = ": ", collapse = ", ")
)
)
Para más información sobre SMOTE, vea los recursos Paquete "imbalance" y Trabajo con conjuntos de datos desequilibrados en el sitio web de CRAN.
Entrenamiento del modelo con LightGBM
Entrene el modelo LightGBM con el conjunto de datos desequilibrado y el conjunto de datos equilibrado (a través de SMOTE). A continuación, compare su rendimiento:
# Train LightGBM for both imbalanced and balanced datasets and define the evaluation metrics
library(lightgbm)
# Get the ID of the label column
label_col <- which(names(train_df) == "Class")
# Convert the test dataset for the model
test_mtx <- as.matrix(test_df)
test_x <- test_mtx[, -label_col]
test_y <- test_mtx[, label_col]
# Set up the parameters for training
params <- list(
objective = "binary",
learning_rate = 0.05,
first_metric_only = TRUE
)
# Train for the imbalanced dataset
message("Start training with imbalanced data:")
train_mtx <- as.matrix(train_df)
train_x <- train_mtx[, -label_col]
train_y <- train_mtx[, label_col]
train_data <- lgb.Dataset(train_x, label = train_y)
valid_data <- lgb.Dataset.create.valid(train_data, test_x, label = test_y)
model <- lgb.train(
data = train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = valid_data),
nrounds = 300L
)
# Train for the balanced (via SMOTE) dataset
message("\n\nStart training with balanced data:")
smote_train_mtx <- as.matrix(smote_train_df)
smote_train_x <- smote_train_mtx[, -label_col]
smote_train_y <- smote_train_mtx[, label_col]
smote_train_data <- lgb.Dataset(smote_train_x, label = smote_train_y)
smote_valid_data <- lgb.Dataset.create.valid(smote_train_data, test_x, label = test_y)
smote_model <- lgb.train(
data = smote_train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = smote_valid_data),
nrounds = 300L
)
Determinar la importancia de las características
Determine la importancia de las características para el modelo que ha entrenado en el conjunto de datos desequilibrado:
imp <- lgb.importance(model, percentage = TRUE)
ggplot(imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_bar(stat = "identity") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(imp$Frequency) * 1.1)
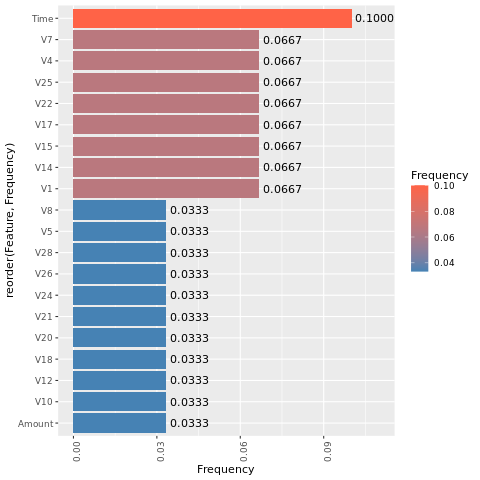
Para el modelo que ha entrenado con el conjunto de datos equilibrados (con SMOTE), calcule la importancia de las características:
smote_imp <- lgb.importance(smote_model, percentage = TRUE)
ggplot(smote_imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
geom_bar(stat = "identity") +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(smote_imp$Frequency) * 1.1)
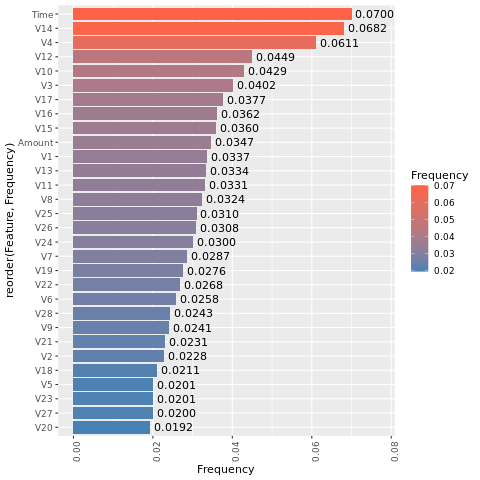
Una comparación de estas gráficas muestra claramente que los conjuntos de datos de entrenamiento equilibrados y desequilibrados tienen grandes diferencias en la importancia de las características.
Evaluación de los modelos
Aquí, evalúas los dos modelos entrenados:
modelentrenado con datos sin procesar y desequilibradossmote_modelentrenado con datos equilibrados
preds <- predict(model, test_mtx[, -label_col])
smote_preds <- predict(smote_model, test_mtx[, -label_col])
Evaluación del rendimiento del modelo con una matriz de confusión
La matriz de confusión muestra el número de
- verdaderos positivos (TP)
- verdaderos negativos (TN)
- falsos positivos (FP)
- falsos negativos (FN)
que un modelo produce cuando es puntuado con datos de prueba. Para la clasificación binaria, el modelo devuelve una matriz de confusión 2x2. Para la clasificación multiclase, el modelo devuelve una matriz de confusión nxn, donde n es el número de clases.
Use una matriz de confusión para resumir el rendimiento de los modelos de aprendizaje automático entrenados en los datos de prueba:
plot_cm <- function(preds, refs, title) { library(caret) cm <- confusionMatrix(factor(refs), factor(preds)) cm_table <- as.data.frame(cm$table) cm_table$Prediction <- factor(cm_table$Prediction, levels=rev(levels(cm_table$Prediction))) ggplot(cm_table, aes(Reference, Prediction, fill = Freq)) + geom_tile() + geom_text(aes(label = Freq)) + scale_fill_gradient(low = "white", high = "steelblue", trans = "log") + labs(x = "Prediction", y = "Reference", title = title) + scale_x_discrete(labels=c("0", "1")) + scale_y_discrete(labels=c("1", "0")) + coord_equal() + theme(legend.position = "none") }Trazar la matriz de confusión del modelo entrenado en el conjunto de datos desequilibrado:
# The value of the prediction indicates the probability that a transaction is fraud # Use 0.5 as the threshold for fraud/no-fraud transactions plot_cm(ifelse(preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Imbalanced dataset)")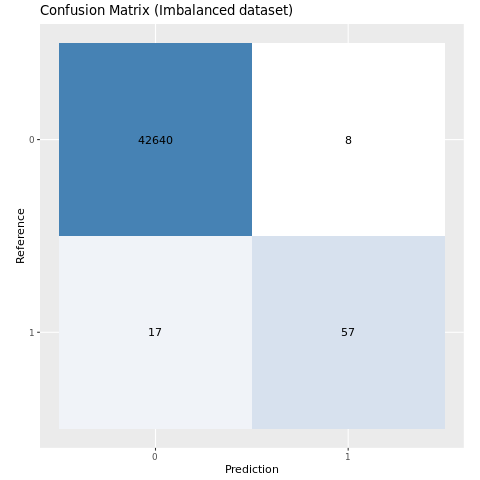
Trazar la matriz de confusión del modelo entrenado en el conjunto de datos equilibrado:
plot_cm(ifelse(smote_preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Balanced dataset)")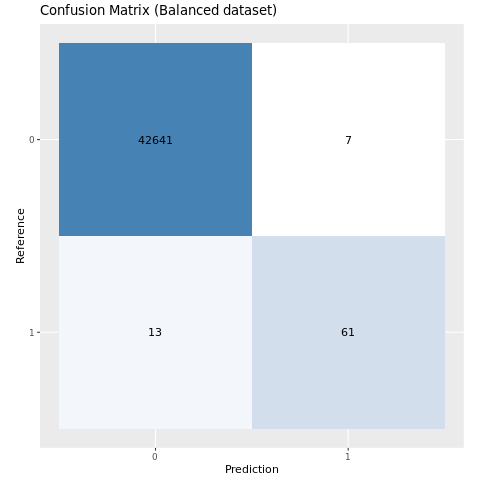
Evaluación del rendimiento del modelo con medidas de AUC-ROC y AUPRC
La medida de Área Bajo la Curva de Característica Operativa del Receptor (AUC-ROC) evalúa el rendimiento de los clasificadores binarios. El gráfico de AUC-ROC visualiza el equilibrio entre la tasa positiva verdadera (TPR) y la tasa de falsos positivos (FPR).
En algunos casos, es más adecuado evaluar el clasificador en función de la medida Área bajo la curva de precisión-coincidencias (AUPRC). La curva AUPRC combina estas tasas:
- Precisión o valor predictivo positivo (PPV)
- Coincidencia, o TPR
# Use the PRROC package to help calculate and plot AUC-ROC and AUPRC
install.packages("PRROC", quiet = TRUE)
library(PRROC)
Calcular las métricas AUC-ROC y AUPRC
Calcular y graficar las métricas de AUC-ROC y AUPRC para los dos modelos.
Conjunto de datos desequilibrado
Calcule las predicciones:
fg <- preds[test_df$Class == 1]
bg <- preds[test_df$Class == 0]
Imprima el área bajo la curva AUC-ROC:
# Compute AUC-ROC
roc <- roc.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(roc)
Trazar la curva AUC-ROC:
# Plot AUC-ROC
plot(roc)
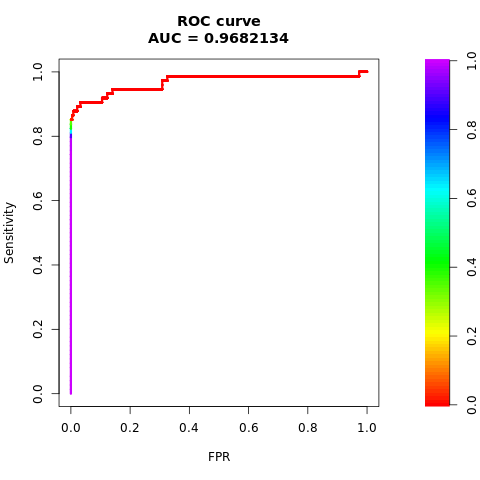
Imprima la curva AUPRC:
# Compute AUPRC
pr <- pr.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(pr)
Trazar la curva AUPRC:
# Plot AUPRC
plot(pr)
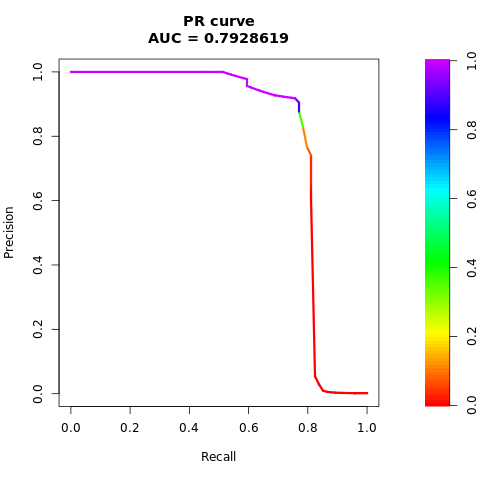
Conjunto de datos equilibrado (mediante SMOTE)
Calcule las predicciones:
smote_fg <- smote_preds[test_df$Class == 1]
smote_bg <- smote_preds[test_df$Class == 0]
Imprima la curva AUC-ROC:
# Compute AUC-ROC
smote_roc <- roc.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_roc)
Trazar la curva AUC-ROC:
# Plot AUC-ROC
plot(smote_roc)
Imprima la curva AUPRC:
# Compute AUPRC
smote_pr <- pr.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_pr)
Trazar la curva AUPRC:
# Plot AUPRC
plot(smote_pr)
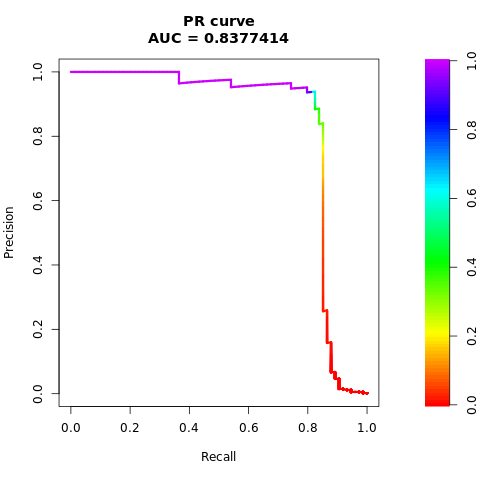
Las cifras anteriores muestran claramente que el modelo entrenado en el conjunto de datos equilibrado supera el rendimiento del modelo entrenado en el conjunto de datos desequilibrado, tanto para las puntuaciones de AUC-ROC como de AUPRC. Este resultado sugiere que SMOTE mejora eficazmente el rendimiento del modelo al trabajar con datos altamente desequilibrados.