Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial se presenta un ejemplo completo de un flujo de trabajo de ciencia de datos de Synapse en Microsoft Fabric. El escenario crea un modelo para recomendaciones de libros en línea.
En este tutorial se describen estos pasos:
- Carga de los datos en un almacén de lago de datos
- Realizar análisis exploratorios sobre los datos
- Entrenamiento de un modelo y registro con MLflow
- Carga del modelo y realización de predicciones
Hay muchos tipos de algoritmos de recomendación disponibles. En este tutorial se usa el algoritmo de factorización de matriz de Mínimos Cuadrados Alternantes (ALS). ALS es un algoritmo de filtrado colaborativo basado en modelos.

ALS intenta calcular la matriz de clasificaciones R como el producto de dos matrices de rango inferior, U y V. Aquí, R = U * Vt. Normalmente, estas aproximaciones se denominan matrices factor.
El algoritmo ALS es iterativo. Cada iteración contiene una de las constantes de matrices de factor, mientras que resuelve la otra mediante el método de mínimos cuadrados. A continuación, mantiene esa constante de matriz de factor recién resuelta mientras resuelve la otra matriz de factor.

Prerrequisitos
Obtenga una suscripción Microsoft Fabric. O bien, regístrese para obtener una prueba gratuita Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Cambie a Fabric mediante el conmutador de experiencia en el lado inferior izquierdo de la página principal.

- Si es necesario, cree un Microsoft Fabric lakehouse como se describe en Crear un lago en Microsoft Fabric.
Seguimiento en un cuaderno
Elija una de estas opciones para seguirlo en un cuaderno.
- Abra y ejecute el cuaderno integrado.
- Cargue el cuaderno desde GitHub.
Abra el cuaderno integrado.
El cuaderno de recomendaciones de libros de muestra acompaña a este tutorial.
Para abrir el cuaderno de ejemplo de este tutorial, siga las instrucciones de Preparar el sistema para tutoriales de ciencia de datos.
Asegúrese de adjuntar un almacén de lago de datos al cuaderno antes de empezar a ejecutar el código.
Importación del cuaderno desde GitHub
El cuaderno AIsample - Book Recommendation.ipynb acompaña a este tutorial.
Para abrir el cuaderno complementario para este tutorial, siga las instrucciones de Preparar el sistema para los tutoriales de ciencia de datos para importar el cuaderno a su área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar una instancia de lakehouse al cuaderno antes de empezar a ejecutar código.
Paso 1: Cargar los datos
El conjunto de datos de recomendación del libro en este escenario consta de tres conjuntos de datos independientes:
Books.csv: un número de libro estándar internacional (ISBN) identifica cada libro, con fechas no válidas ya eliminadas. El conjunto de datos también incluye el título, el autor y el publisher. Para un libro con varios autores, el archivo Books.csv enumera solo el primer autor. Las direcciones URL apuntan a los recursos del sitio web de Amazon para las imágenes de portada, en tres tamaños.
ISBN Título del libro Autor del libro Año de publicación Publisher Image-URL-S Image-URL-M Image-URL-l 0195153448 Mitología clásica Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canadá http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: las clasificaciones de cada libro son explícitas (proporcionadas por los usuarios, en una escala de 1 a 10) o implícitas (observadas sin entrada del usuario y indicadas por 0).
Id. de usuario ISBN Clasificación del libro 276725 034545104X 0 276726 0155061224 5 Users.csv: los identificadores de usuario se anonimizan y se asignan a enteros. Los datos demográficos (por ejemplo, la ubicación y la edad) se proporcionan, si están disponibles. Si estos datos no están disponibles, estos valores son
null.Id. de usuario Ubicación Edad 1 nyc Nueva York EE.UU. 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Defina estos parámetros para poder usar este cuaderno con diferentes conjuntos de datos:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Descarga y almacenamiento de los datos en un almacén de lago de datos
Este código descarga el conjunto de datos y, a continuación, lo almacena en lakehouse.
Importante
Asegúrese de agregar un almacén de lago de datos al cuaderno antes de ejecutarlo. De lo contrario, se producirá un error.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Configuración del seguimiento de experimentos de MLflow
Use este código para configurar el seguimiento del experimento de MLflow. En este ejemplo se deshabilita el registro automático. Para obtener más información, consulte el artículo Autologging in Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Lectura de datos desde el almacén de lago de datos
Después de colocar los datos correctos en lakehouse, lea los tres conjuntos de datos en tramas de datos de Spark independientes en el cuaderno. Las rutas de acceso de archivo de este código usan los parámetros definidos anteriormente.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Paso 2: Realizar análisis de datos exploratorios
Mostrar datos sin procesar
Explore los DataFrames mediante el display comando . Con este comando, puede ver las estadísticas de dataframe de alto nivel y comprender cómo se relacionan las distintas columnas de conjunto de datos entre sí. Antes de explorar los conjuntos de datos, use este código para importar las bibliotecas necesarias:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Use este código para examinar el DataFrame que contiene los datos del libro:
display(df_items, summary=True)
Agregue una columna _item_id para su uso posterior. El valor _item_id debe ser un entero para los modelos de recomendación. Este código usa StringIndexer para transformar ITEM_ID_COL en índices:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Muestre el DataFrame y compruebe si el valor de _item_id aumenta de forma monotónica y sucesivamente, según lo previsto:
display(df_items.sort(F.col("_item_id").desc()))
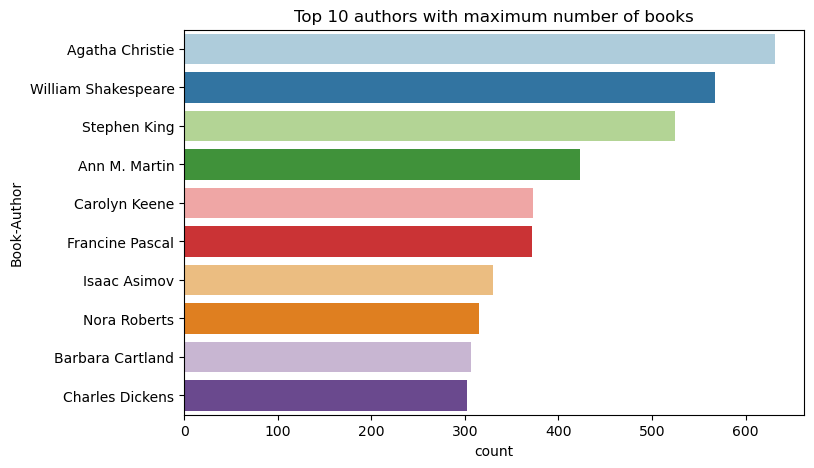
Use este código para trazar los 10 autores principales, por número de libros escritos, en orden descendente. Agatha Christie es el autor principal con más de 600 libros, seguidos por William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
A continuación, muestre el DataFrame que contiene los datos de usuario:
display(df_users, summary=True)
Si una fila tiene un valor de User-ID que falta, quite esa fila. Los valores que faltan en un conjunto de datos personalizado no provocan problemas.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Agregue una columna _user_id para su uso posterior. Para los modelos de recomendación, el valor _user_id debe ser un entero. En el ejemplo de código siguiente se usa StringIndexer para transformar USER_ID_COL en índices.
El conjunto de datos de libros ya tiene una columna entera User-ID. Sin embargo, agregar una columna de _user_id para la compatibilidad con diferentes conjuntos de datos hace que este ejemplo sea más sólido. Use este código para agregar la columna _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Use este código para ver los datos de clasificación:
display(df_ratings, summary=True)
Obtenga las clasificaciones distintas y guárdelas para usarlas posteriormente en una lista denominada ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
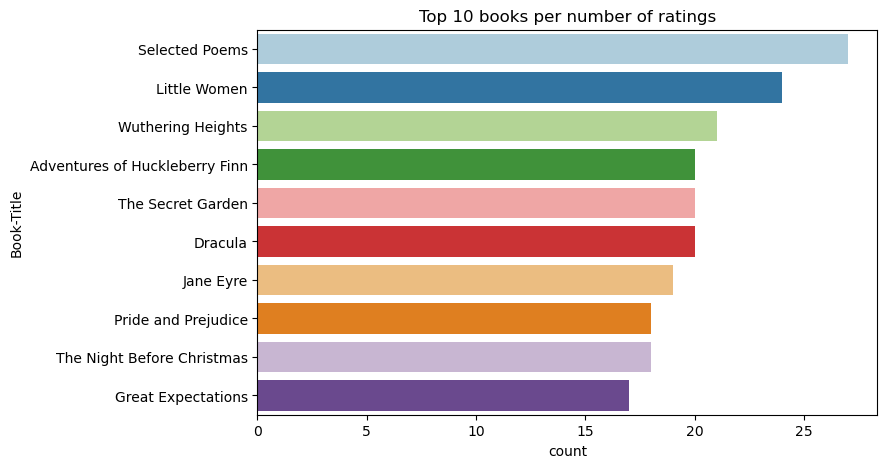
Use este código para mostrar los 10 libros principales con las clasificaciones más altas:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Según las clasificaciones, Selected Poems es el libro más popular. Aventuras de Huckleberry Finn, The Secret Gardeny Dracula tienen la misma clasificación.
Combinar datos
Combine los tres dataframes en un dataframe para obtener un análisis más completo:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Use este código para mostrar un recuento de los distintos usuarios, libros e interacciones:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Calcula y representa gráficamente los elementos más populares
Use este código para calcular y mostrar los 10 libros más populares:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Sugerencia
Utilice el valor de <topn> para las secciones Popular o de Más vendidos.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Preparación de conjuntos de datos de entrenamiento y prueba
La matriz ALS requiere cierta preparación de datos antes del entrenamiento. Use este ejemplo de código para preparar los datos. El código realiza estas acciones:
- Cambie la columna de valoración al tipo correcto.
- Muestree los datos de entrenamiento con valoraciones de usuario.
- Divida los datos en conjuntos de datos de entrenamiento y prueba.
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity hace referencia a los datos de comentarios dispersos, que no pueden identificar similitudes en los intereses de los usuarios. Para comprender mejor los datos y el problema actual, use este código para calcular la sparsidad del conjunto de datos:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Paso 3: Desarrollar y entrenar el modelo
Entrene un modelo de ALS para proporcionar recomendaciones personalizadas a usuarios.
Definición del modelo
Spark ML proporciona una API cómoda para compilar el modelo ALS. Sin embargo, el modelo no controla problemas de forma confiable, como la sparsidad de datos y el arranque en frío (haciendo recomendaciones cuando los usuarios o elementos son nuevos). Para mejorar el rendimiento del modelo, combine la validación cruzada y el ajuste automático de hiperparámetros.
Use este código para importar las bibliotecas necesarias para el entrenamiento y la evaluación del modelo:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Ajuste de hiperparámetros de modelo
El siguiente ejemplo de código construye una cuadrícula de parámetros para ayudar a buscar en los hiperparámetros. El código también crea un evaluador de regresión que usa el error raíz medio cuadrado (RMSE) como métrica de evaluación:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
El siguiente ejemplo de código inicia diferentes métodos de optimización de modelos en función de los parámetros preconfigurados. Para obtener más información sobre el ajuste de modelos, consulte optimización de ML: selección de modelos e ajuste de hiperparámetros en el sitio web de Apache Spark.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Evaluación del modelo
Evalúe los modelos con los datos de prueba. Un modelo bien entrenado tiene métricas elevadas en el conjunto de datos.
Un modelo sobreajustado podría necesitar más datos de entrenamiento o una reducción de algunas características redundantes. Es posible que tenga que cambiar la arquitectura del modelo o ajustar sus parámetros.
Nota
Un valor de métrica de R cuadrado negativo indica que el modelo entrenado funciona peor que una línea recta horizontal. Este hallazgo sugiere que el modelo entrenado no explica los datos.
Use este código para definir una función de evaluación:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Seguimiento del experimento mediante MLflow
Use MLflow para realizar un seguimiento de todos los experimentos y registrar parámetros, métricas y modelos. Para iniciar el entrenamiento y la evaluación del modelo, use este código:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Seleccione el experimento denominado aisample-recommendation del área de trabajo para ver la información registrada de la ejecución de entrenamiento. Si cambia el nombre del experimento, seleccione el experimento que tiene el nuevo nombre. La información registrada es similar a esta imagen:

Paso 4: Carga del modelo final para la puntuación y realización de predicciones
Después de terminar de entrenar el modelo y seleccionar el mejor modelo, cargue el modelo para la evaluación (también llamada inferencia). Este código carga el modelo y usa predicciones para recomendar los 10 libros principales para cada usuario:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
La salida es similar a esta tabla:
| _item_id | _user_id | rating | Título del libro |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Laher: Vidas de ... |
| 786 | 7 | 6.2255826 | El D… del Hombre del Piano |
| 45330 | 7 | 4.980466 | Estado mental |
| 38960 | 7 | 4.980466 | Todo lo que él siempre quería |
| 125415 | 7 | 4.505084 | Harry Potter y ... |
| 44939 | 7 | 4.3579073 | Taltos: Vidas de ... |
| 175247 | 7 | 4.3579073 | El Bonesetter es ... |
| 170183 | 7 | 4.228735 | Vivir el simple... |
| 88503 | 7 | 4.221206 | Isla del Blu... |
| 32894 | 7 | 3.9031885 | Solsticio de invierno |
Guardar las predicciones en el almacén de lago de datos
Use este código para volver a escribir las recomendaciones en el almacén de lago de datos:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)