Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial se presenta un ejemplo completo de un flujo de trabajo de ciencia de datos de Synapse en Microsoft Fabric. El escenario crea un modelo de previsión que usa datos históricos de ventas para predecir las ventas de categorías de productos en un superstore.
La previsión es un activo fundamental en las ventas. Combina datos históricos y métodos predictivos para proporcionar información sobre las tendencias futuras. La previsión puede analizar las ventas anteriores para identificar patrones. También puede aprender del comportamiento del consumidor para optimizar las estrategias de inventario, producción y marketing. Este enfoque proactivo mejora la capacidad de adaptación, la capacidad de respuesta y el rendimiento empresarial general en un marketplace dinámico.
En este tutorial se describen estos pasos:
- Carga de los datos
- Uso del análisis de datos exploratorios para comprender y procesar los datos
- Entrenamiento de un modelo de Machine Learning con un paquete de software de código abierto
- Seguimiento de experimentos con MLflow y la característica de registro automático de Fabric
- Guarde el modelo de aprendizaje automático final y realice predicciones.
- Mostrar el rendimiento del modelo con visualizaciones de Power BI
Prerrequisitos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Cambie a Fabric mediante el conmutador de experiencia en el lado inferior izquierdo de la página principal.

- Si es necesario, cree un lakehouse de Microsoft Fabric, como se describe en el recurso Crear un lakehouse en Microsoft Fabric.
Seguimiento en un cuaderno
Para seguir en un cuaderno, tienes estas opciones:
- Abra y ejecute el cuaderno integrado en la experiencia de ciencia de datos de Synapse
- Carga tu cuaderno desde GitHub a la experiencia de Synapse para ciencia de datos
Abra el cuaderno integrado.
El cuaderno de ejemplo de previsión de ventas acompaña a este tutorial.
Para abrir el cuaderno de ejemplo de este tutorial, siga las instrucciones de Preparar el sistema para tutoriales de ciencia de datos.
Asegúrese de adjuntar un almacén de lago de datos al cuaderno antes de empezar a ejecutar el código.
Importación del cuaderno desde GitHub
El cuaderno AIsample - Superstore Forecast.ipynb acompaña a este tutorial.
Para abrir el cuaderno complementario de este tutorial, siga las instrucciones de Cómo preparar su sistema para los tutoriales de ciencia de datos, para importar el cuaderno a su área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar una instancia de lakehouse al cuaderno antes de empezar a ejecutar código.
Paso 1: Cargar los datos
El conjunto de datos tiene 9995 instancias de ventas de varios productos. También incluye 21 atributos. El cuaderno usa un archivo denominado Superstore.xlsx. Ese archivo tiene esta estructura de tabla:
| Identificador de fila | Id. de pedido | Fecha de pedido | Fecha de envío | Modo de envío | Id. de cliente | Nombre del cliente | Segment | País | Ciudad | Estado | Código postal | Región | Id. de producto | Categoría | Subcategoría | Nombre del producto | Ventas | Cantidad | Descuento | Beneficio |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Clase estándar | SO-20335 | Sean O'Donnell | Consumidor | Estados Unidos | Fort Lauderdale | Florida | 33311 | Sur | FUR-TA-10000577 | Mueble | Tablas | Mesa rectangular delgada Serie CR4500 de Bretford | 957,5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Clase estándar | Clase estándar | Brosina Hoffman | Consumidor | Estados Unidos | Los Ángeles | California | 90032 | Oeste | FUR-TA-10001539 | Mueble | Tablas | Tablas de conferencias rectangulares de Chromcraft | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Clase estándar | TB-21520 | Tracy Blumstein | Consumidor | Estados Unidos | Filadelfia | Pensilvania | 19140 | East | OFF-EN-10001509 | Suministros de Office | Sobres | Sobres con cierre de cuerda de poliéster | 3,264 | 2 | 0.2 | 1,1016 |
El siguiente fragmento de código define parámetros específicos para poder usar este cuaderno con diferentes conjuntos de datos:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Descarga el conjunto de datos y súbelo a la lakehouse
El siguiente fragmento de código descarga una versión disponible públicamente del conjunto de datos y, a continuación, almacena ese conjunto de datos en una instancia de Fabric Lakehouse:
Importante
Debe agregar un lakehouse al cuaderno antes de ejecutarlo. De lo contrario, se producirá un error.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Configuración del seguimiento de experimentos de MLflow
Microsoft Fabric captura automáticamente los valores de parámetro de entrada y las métricas de salida de un modelo de Machine Learning, a medida que se entrena. Esto amplía las funcionalidades de registro automático de MLflow. A continuación, la información se registra en el área de trabajo, donde puede acceder a ella y visualizarla con las API de MLflow o el experimento correspondiente en el área de trabajo. Para obtener más información sobre el registro automático, visite el recurso Registro automático en Microsoft Fabric .
Para desactivar el registro automático de Microsoft Fabric en una sesión de cuaderno, llame mlflow.autolog() a y establezca disable=True, como se muestra en el siguiente fragmento de código:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Lectura de datos sin procesar desde el lago de datos
El siguiente fragmento de código lee datos sin procesar de la sección Archivos de lakehouse. También agrega más columnas para diferentes partes de fecha. La misma información crea una tabla delta con particiones. Dado que los datos sin procesar se almacenan como un archivo de Excel, debe usar pandas para leerlos.
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Paso 2: Realizar análisis de datos exploratorios
Importar bibliotecas
Importe las bibliotecas necesarias antes de iniciar el análisis:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Mostrar los datos sin procesar
Para comprender mejor el propio conjunto de datos, revise manualmente un subconjunto de los datos. Use la display función para imprimir el dataframe. Las Chart vistas pueden visualizar fácilmente subconjuntos del conjunto de datos:
display(df)
En este tutorial se aborda un cuaderno que se centra principalmente en las previsiones de ventas para categorías. Este enfoque acelera el cálculo y ayuda a mostrar el rendimiento del modelo. Sin embargo, este cuaderno usa técnicas adaptables. Puede ampliar esas técnicas para predecir las ventas de otras categorías de productos. El siguiente fragmento de código selecciona Furniture como categoría del producto:
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Preprocesar los datos
Los escenarios empresariales del mundo real suelen necesitar predecir las ventas en tres categorías distintas:
- Categoría de producto específica
- Categoría de cliente específica
- Combinación específica de categoría de producto y categoría de cliente
El siguiente fragmento de código quita las columnas innecesarias para preprocesar los datos. No necesitamos algunas de las columnas (Row ID, Order ID,Customer ID y Customer Name) porque no tienen relevancia. Queremos predecir las ventas generales, en todo el estado y la región, para una categoría de producto específica (Furniture). Por lo tanto, podemos quitar las Statecolumnas , Region, Country, City, y Postal Code . Para predecir las ventas de una ubicación o categoría específicas, es posible que tengamos que ajustar el paso de preprocesamiento en consecuencia.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
El conjunto de datos se estructura diariamente. Debemos reemuestrear en la Order Date columna, ya que queremos desarrollar un modelo para prever las ventas mensualmente.
En primer lugar, agrupe la categoría Furniture por Order Date. A continuación, calcule la suma de la Sales columna para cada grupo para determinar el total de ventas de cada valor único Order Date . Haga un nuevo muestreo de la columna Sales con la frecuencia de MS, para agregar los datos por mes. Por último, calcule el valor medio de ventas de cada mes. En el fragmento de código siguiente se muestran estos pasos:
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
En el siguiente fragmento de código, muestre el impacto de Order Date en Sales para la Furniture categoría:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Antes de cualquier análisis estadístico, debe importar el módulo statsmodels Python. En este módulo se proporcionan clases y funciones para calcular muchos modelos estadísticos. También proporciona clases y funciones para realizar pruebas estadísticas y exploración de datos estadísticos. El siguiente fragmento de código muestra este paso:
import statsmodels.api as sm
Realizar análisis estadísticos
Una serie temporal realiza un seguimiento de estos elementos de datos a intervalos establecidos para determinar la variación de esos elementos en el patrón de serie temporal:
Nivel: componente fundamental que representa el valor medio de un período de tiempo específico.
Trend: describe si la serie temporal disminuye, permanece constante o aumenta con el tiempo.
estacionalidad: describe la señal periódica en la serie temporal y busca apariciones cíclicas que afectan a los patrones de series temporales crecientes o decrecientes.
Ruido/Residual: Hace referencia a las fluctuaciones y variabilidad aleatorias en los datos de serie temporal que el modelo no puede explicar.
El siguiente fragmento de código muestra esos elementos para el conjunto de datos, después del preprocesamiento:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Los gráficos describen la estacionalidad, las tendencias y el ruido en los datos de previsión. Puede capturar los patrones subyacentes y desarrollar modelos que realicen predicciones precisas que tengan resistencia frente a fluctuaciones aleatorias.
Paso 3: Entrenamiento y seguimiento del modelo
Ahora que tiene los datos disponibles, defina el modelo de previsión. En este cuaderno, aplique el modelo de previsión SARIMAX (autorregresivo integrado de promedio móvil estacional con factores exógenos). SARIMAX combina componentes autorregresivos (AR) y de media móvil (MA), diferenciación estacional (S) y predictores externos para hacer pronósticos precisos y flexibles para los datos de series temporales.
También se usa el registro automático de MLflow y Fabric para realizar un seguimiento de los experimentos. Aquí, cargue la tabla delta desde el lago de datos. Puede usar otras tablas delta teniendo en cuenta el almacén de lago como origen. El siguiente fragmento de código importa las bibliotecas necesarias:
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Ajuste de hiperparámetros
SARIMAX tiene en cuenta los parámetros implicados en el modo autoregresivo de media móvil integrada (ARIMA) (p, d, q) y agrega los parámetros de estacionalidad (P, D, Q, s). Estos argumentos del modelo SARIMAX se denominan orden (p, d, q) y orden estacional (P, D, Q, s), respectivamente. Por lo tanto, para entrenar el modelo, primero debemos ajustar siete parámetros.
Parámetros de orden:
p: el orden del componente AR, que representa el número de observaciones pasadas en la serie temporal usada para predecir el valor actual.Normalmente, este parámetro debe tener un valor entero no negativo. Los valores comunes están en el intervalo de
0para3. Sin embargo, son posibles valores más altos, en función de las características de datos específicas. Un valor depsuperior indica una memoria más larga de valores anteriores en el modelo.d: el orden de diferenciación, que representa el número de veces que debe diferenciarse la serie temporal para lograr la estacionaridad.Este parámetro debe tener un valor entero no negativo. Los valores comunes están en el intervalo de
0para2. Un valor dedde0significa que la serie temporal ya es estacionaria. Los valores mayores indican que se requiere un mayor número de operaciones de diferenciación para hacerlo estacionario.q: el orden del componente de MA. Este parámetro representa el número de términos de error de ruido blanco pasados que se usan para predecir el valor actual.Este parámetro debe tener un valor entero no negativo. Los valores comunes están en el intervalo de
0a3, pero ciertas series temporales pueden requerir valores más altos. Un valor deqmayor indica una mayor dependencia de los términos de error pasados para realizar predicciones.
Los parámetros de orden estacional:
-
P: el orden estacional del componente AR, similar alpparámetro , pero que cubre la parte estacional -
D: el orden estacional de diferenciación, similar aldparámetro , pero que cubre la parte estacional -
Q: el orden estacional del componente ma, similar alqparámetro , pero que cubre la parte estacional -
s: el número de pasos de tiempo por ciclo estacional (por ejemplo, 12 para los datos mensuales con una estacionalidad anual)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX tiene otros parámetros:
enforce_stationarity: si el modelo debe aplicar la estacionalidad o no en los datos de serie temporal antes de ajustar el modelo SARIMAX.Un
enforce_stationarityvalor deTrue(el valor predeterminado) indica que el modelo SARIMAX debe aplicar la estacionariedad en los datos de series temporales. Antes de ajustar el modelo, el modelo SARIMAX aplica automáticamente diferencias a los datos para que sean estacionarios, como especifican lasdórdenes yD. Se trata de una práctica común porque muchos modelos de series temporales, incluido SARIMAX, asumen que los datos son estacionarios.Para una serie temporal no estacionaria (por ejemplo, una serie que muestra tendencias o estacionalidad), se recomienda establecer a
enforce_stationarityyTrue, y permitir que el modelo SARIMAX maneje la diferenciación para lograr la estacionariedad. Para una serie temporal fija (por ejemplo, una sin tendencias o estacionalidad), establezcaenforce_stationarityenFalsepara evitar diferencias innecesarias.enforce_invertibility: controla si el modelo debe aplicar o no la invertibilidad en los parámetros estimados durante el proceso de optimización.Un
enforce_invertibilityvalor deTrue(el predeterminado) indica que el modelo SARIMAX debe asegurar la invertibilidad de los parámetros estimados. La invertibilidad garantiza que un modelo bien definido y que los coeficientes estimados de AR y MA se encuentran dentro del intervalo de estacionaridad.La aplicación de la invertibilidad ayuda a garantizar que el modelo SARIMAX cumpla los requisitos teóricos de un modelo de serie temporal estable. También ayuda a evitar problemas con la estimación y la estabilidad del modelo.
Un AR(1) modelo es el valor predeterminado. Esto hace referencia a (1, 0, 0). Sin embargo, es habitual probar diferentes combinaciones de los parámetros de pedido y los parámetros de orden estacional y evaluar el rendimiento del modelo de un conjunto de datos. Los valores adecuados pueden variar de una serie temporal a otra.
La determinación de los valores óptimos suele implicar el análisis de la función de autocorrelación (ACF) y la función de autocorrelación parcial (PACF) de los datos de serie temporal. También suele implicar el uso de criterios de selección de modelos( por ejemplo, el criterio de información Akaike (AIC) o el criterio de información bayesiana (BIC).
Ajuste los hiperparámetros, como se muestra en el siguiente fragmento de código:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Después de la evaluación de los resultados anteriores, puede determinar los valores de los parámetros de pedido y los parámetros de orden estacional. La elección es order=(0, 1, 1) y seasonal_order=(0, 1, 1, 12), que ofrecen el AIC más bajo (por ejemplo, 279.58). Use estos valores para entrenar el modelo. El siguiente fragmento de código muestra este paso:
Entrenamiento del modelo
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Este código visualiza una previsión de series temporales para los datos de ventas de muebles. Los resultados representados gráficamente muestran tanto los datos observados como la predicción de un paso hacia adelante, con una región sombreada para el intervalo de confianza. Los fragmentos de código siguientes muestran la visualización:
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
El siguiente fragmento de código usa predictions para evaluar el rendimiento del modelo, a diferencia de los valores reales. El valor de predictions_future indica la previsión futura.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Paso 4: Puntuar el modelo y guardar predicciones
El siguiente fragmento de código integra los valores reales con los valores previstos para crear un informe de Power BI. Además, almacena estos resultados en una tabla dentro de la casa del lago.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Paso 5: Visualización en Power BI
El informe de Power BI muestra un error medio de porcentaje absoluto (MAPE) de 16,58. La métrica MAPE define la precisión de un método de previsión. Representa la precisión de las cantidades previstas, en comparación con las cantidades reales.
MAPE es una métrica sencilla. Un MAPE de 10% representa que la desviación media entre los valores previstos y los valores reales es 10%, independientemente de si la desviación era positiva o negativa. Los estándares de valores MAPE deseables varían en todos los sectores.
La línea azul claro de este gráfico representa los valores reales de ventas. La línea azul oscuro representa los valores de ventas previstos. La comparación de ventas reales y previstas revela que el modelo predice eficazmente las ventas de la categoría Furniture durante los primeros seis meses de 2023.
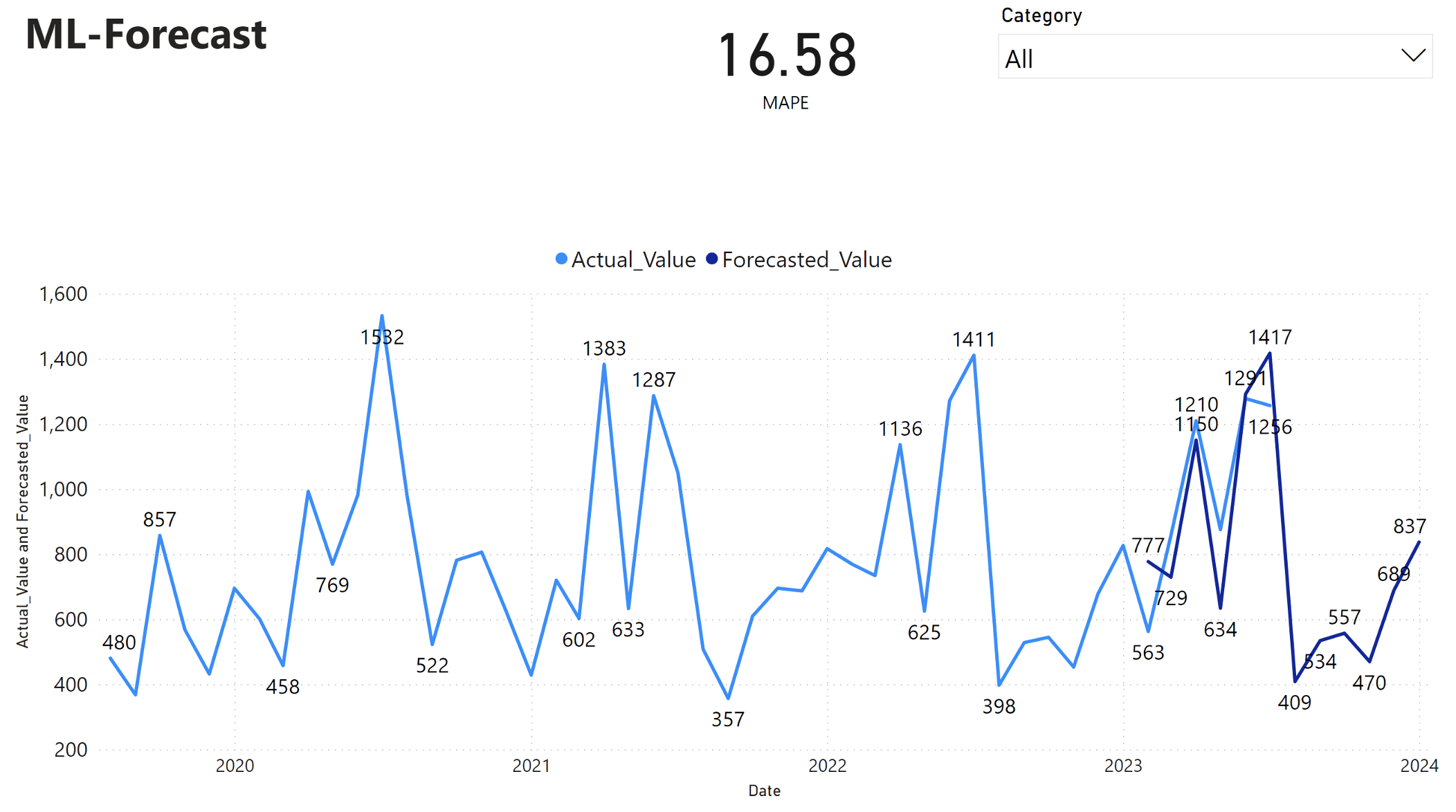
En función de esta observación, podemos tener confianza en las capacidades de previsión del modelo para las ventas generales en los últimos seis meses de 2023 y extenderse a 2024. Esta confianza puede informar a las decisiones estratégicas sobre la gestión del inventario, la adquisición de materias primas y otras consideraciones relacionadas con la empresa.