Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El vínculo semántico es una característica que permite establecer una conexión entre semantic models y Synapse Data Science en Microsoft Fabric. El uso del vínculo semántico solo se admite en Microsoft Fabric.
Para Fabric Runtime 1.2 (Spark 3.4) y versiones posteriores, el vínculo semántico está disponible en el entorno de ejecución predeterminado y no es necesario instalarlo.
Para actualizar a la versión más reciente del vínculo semántico, ejecute el siguiente comando:
%pip install -U semantic-link
Los objetivos principales del vínculo semántico son:
- Facilitar la conectividad de datos.
- Habilitar la propagación de información semántica.
- Integre perfectamente con las herramientas establecidas que usan los científicos de datos, como cuadernos.
El vínculo semántico le ayuda a conservar el conocimiento del dominio sobre la semántica de datos de una manera estandarizada que puede acelerar el análisis de datos y reducir los errores.
Flujo de datos semánticos vinculados
El flujo de datos del vínculo semántico comienza con modelos semánticos que contienen datos e información semántica. El vínculo semántico puentea la brecha entre Power BI y la experiencia de ciencia de datos de Synapse.
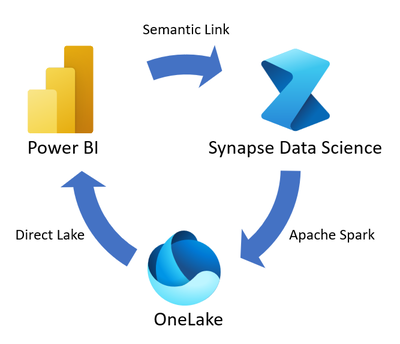
El vínculo semántico permite usar modelos semánticos de Power BI en la experiencia de ciencia de datos de Synapse para realizar tareas como análisis estadísticos detallados y modelado predictivo con técnicas de aprendizaje automático. Puede almacenar la salida del trabajo de ciencia de datos en OneLake mediante Apache Spark e ingerir la salida almacenada en Power BI mediante Direct Lake.
conectividad de Power BI
Un modelo semántico actúa como un único modelo de objetos tabular que proporciona orígenes confiables para definiciones semánticas, como medidas de Power BI. El vínculo semántico se conecta a modelos semánticos en los siguientes ecosistemas, lo que facilita a los científicos de datos trabajar en el sistema con el que están más familiarizados.
- Ecosistema de Python pandas, a través de la biblioteca de Python SemPy.
- Ecosistema de Apache Spark , a través del conector nativo de Spark. Esta implementación admite varios lenguajes, como PySpark, Spark SQL, R y Scala.
Aplicaciones de información semántica
La información semántica de los datos incluye categorías Power BI data como dirección y código postal, relaciones entre tablas e información jerárquica.
Estas categorías de datos incluyen metadatos que el enlace semántico propaga en el entorno de Synapse Data Science permitiendo nuevas experiencias y manteniendo el linaje de datos.
Algunas aplicaciones de ejemplo de vínculo semántico incluyen:
- Sugerencias inteligentes de funciones semánticas integradas.
- Integración innovadora para aumentar los datos con medidas de Power BI, mediante el uso de add-measures.
- Herramientas para la validación de la calidad de los datos en función de las relaciones entre tablas y dependencias funcionales dentro de las tablas.
Vínculo semántico es una herramienta eficaz que permite a los analistas de negocios usar datos de forma eficaz en un entorno completo de ciencia de datos.
El vínculo semántico facilita la colaboración sin problemas entre científicos de datos y analistas de negocios mediante la eliminación de la necesidad de volver a implementar la lógica empresarial insertada en Power BI medidas. Este enfoque garantiza que ambas partes puedan trabajar de forma eficaz y productiva, maximizando el potencial de sus conclusiones controladas por datos.
Estructura de datos FabricDataFrame
FabricDataFrame es la estructura de datos principal que usa el vínculo semántico para propagar la información semántica de modelos semánticos al entorno de ciencia de datos de Synapse.

La clase FabricDataFrame:
- Admite todas las operaciones de pandas.
- Subclasifica DataFrame de pandas y agrega metadatos, como información semántica y procedencia.
- Presenta funciones semánticas y el método add-measure que permite usar medidas de Power BI en el ámbito de la ciencia de datos.
Contenido relacionado
- Explore la documentación de referencia del paquete de vínculos semánticos de Python (SemPy)
- Tutorial: Limpieza de datos con dependencias funcionales
- Conectividad Power BI con vínculo semántico y Microsoft Fabric
- Exploración y validación de datos mediante el vínculo semántico
- Exploración y validación de relaciones en modelos semánticos