Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial, aprenderá a entrenar varios modelos de aprendizaje automático para seleccionar el mejor para predecir qué clientes bancarios probablemente se van.
En este tutorial, hará lo siguiente:
- Entrene modelos Random Forest y LightGBM.
- Use la integración nativa de Microsoft Fabric con el marco de MLflow para registrar los modelos de aprendizaje automático entrenados, los hiperparámetros usados y las métricas de evaluación.
- Registre el entrenamiento del modelo de Machine Learning.
- Evalúe los rendimientos de los modelos de Machine Learning entrenados en el conjunto de datos de validación.
MLflow es una plataforma de código abierto para administrar el ciclo de vida del aprendizaje automático con características como Tracking, Models y Model Registry. MLflow se integra de forma nativa con la experiencia de Ciencia de datos de Fabric.
Requisitos previos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Cambie a Fabric mediante el conmutador de experiencia en el lado inferior izquierdo de la página principal.

Esta es la parte 3 de 5 de la serie de tutoriales. Para realizar este tutorial, primero complete:
- Parte 1: Ingerir datos en un almacén de lago de Microsoft Fabric mediante Apache Spark.
- Parte 2: Explorar y visualizar datos mediante cuadernos de Microsoft Fabric para obtener más información sobre los datos.
Seguir en el cuaderno
3-train-evaluate.ipynb es el cuaderno que acompaña a este tutorial.
Para abrir el cuaderno complementario para este tutorial, siga las instrucciones en para preparar su sistema para los tutoriales de ciencia de datos, y para importar el cuaderno a su área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar una instancia de LakeHouse al cuaderno antes de empezar a ejecutar código.
Importante
Adjunte el mismo lakehouse que usó en la parte 1 y en la parte 2.
Instalación de bibliotecas personalizadas
En este cuaderno, instalará el aprendizaje desequilibrado (importado comoimblearn) usando%pip install. El aprendizaje desequilibrado es una biblioteca para la técnica de sobremuestreo de minorías sintéticas (SMOTE) que se usa al tratar con conjuntos de datos desequilibrados. El kernel de PySpark se reiniciará después de %pip install, por lo que es necesario instalar la biblioteca antes de ejecutar cualquier otra celda.
Accederá a SMOTE mediante la imblearn biblioteca. Instálelo ahora mediante las funcionalidades de instalación en línea (por ejemplo, %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Importante
Ejecute esta instalación cada vez que reinicie el cuaderno.
Al instalar una biblioteca en un cuaderno, solo está disponible durante la sesión del cuaderno, y no en el área de trabajo. Si reinicia el cuaderno, tendrá que volver a instalar la biblioteca.
Si tiene una biblioteca que usa a menudo y quiere que esté disponible para todos los cuadernos del área de trabajo, puede usar un entorno de Fabric para ese propósito. Puede crear un entorno, instalar la biblioteca en él y, después, el administrador del área de trabajo puede asociar el entorno al área de trabajo como entorno predeterminado. Para obtener más información sobre cómo configurar un entorno como el predeterminado del área de trabajo, consulte El administrador establece bibliotecas predeterminadas para el área de trabajo.
Para obtener información sobre cómo migrar las bibliotecas de área de trabajo y las propiedades de Spark existentes a un entorno, consulte Migración de las bibliotecas de áreas de trabajo y propiedades de Spark a un entorno predeterminado.
Carga de los datos
Antes de entrenar cualquier modelo de Machine Learning automático, debe cargar la tabla delta desde lakehouse para leer los datos limpios que creó en el cuaderno anterior.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generación de experimentos para el seguimiento y registro del modelo mediante MLflow
En esta sección se muestra cómo generar un experimento, especificar los parámetros de entrenamiento y modelo de Machine Learning, así como métricas de puntuación, entrenar los modelos de Machine Learning o, registrarlos y guardar los modelos entrenados para su uso posterior.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
Al ampliar las funcionalidades de registro automático de MLflow, el registro automático funciona capturando automáticamente los valores de los parámetros de entrada y las métricas de salida de un modelo de Machine Learning a medida que se entrena. A continuación, esta información se registra en el área de trabajo, donde se puede acceder a ella y visualizarla mediante las API de MLflow o el experimento correspondiente en el área de trabajo.
Todos los experimentos con sus nombres respectivos se registran y podrá realizar un seguimiento de sus parámetros y métricas de rendimiento. Para obtener más información sobre el registro automático, consulte Registro automático en Microsoft Fabric.
Establecimiento de especificaciones de experimento y registro automático
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Importación de scikit-learn y LightGBM
Con los datos implementados, ahora puede definir los modelos de Machine Learning. Aplicará modelos de Random Forest y LightGBM en este cuaderno. Use scikit-learn e lightgbm implemente los modelos dentro de unas pocas líneas de código.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Preparación de conjunto de datos de entrenamiento, validación y prueba
Use la train_test_splitfunción descikit-learn para dividir los datos en conjuntos de entrenamiento, validación y pruebas.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Guardar datos de prueba en una tabla delta
Guarde los datos de prueba en la tabla delta para su uso en el cuaderno siguiente.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Aplicar SMOTE a los datos de entrenamiento para sintetizar nuevas muestras para la clase minoría
La exploración de datos en la parte 2 mostró que de los 10,000 puntos de datos correspondientes a 10,000 clientes, solo 2,037 clientes (alrededor del 20 %) han dejado el banco. Esto indica que el conjunto de datos está muy desequilibrado. El problema con la clasificación desequilibrada es que hay demasiados ejemplos de la clase que es minoría para que un modelo aprenda eficazmente el límite de decisión. SMOTE es el enfoque más utilizado para sintetizar nuevas muestras para la clase de minoría. Obtenga más información sobre SMOTE aquí y aquí.
Sugerencia
Tenga en cuenta que SMOTE solo se debe aplicar al conjunto de datos de entrenamiento. Debe dejar el conjunto de datos de prueba en su distribución desequilibrado original para obtener una aproximación válida de cómo se realizará el modelo de Machine Learning en los datos originales, que representa la situación en producción.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Sugerencia
Puede ignorar sin problemas el mensaje de advertencia de MLflow que aparece al ejecutar esta celda.
Si ve un mensaje ModuleNotFoundError, es que no ha ejecutado la primera celda de este cuaderno, que instala la biblioteca imblearn. Deberá instalar esta biblioteca cada vez que reinicie el cuaderno. Vuelva atrás y ejecute de nuevo todas las celdas a partir de la primera celda de este cuaderno.
Entrenamiento del modelo
- Entrene el modelo mediante bosque aleatorio con una profundidad máxima de 4 y 4 características
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Entrene el modelo mediante bosque aleatorio con una profundidad máxima de 8 y 6 características
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Entrene el modelo mediante LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Artefacto de experimentos para el seguimiento del rendimiento del modelo
Las ejecuciones del experimento se guardan automáticamente en el artefacto del experimento que se puede encontrar en el área de trabajo. Se denominan en función del nombre usado para establecer el experimento. Todos los modelos de aprendizaje automático entrenados, sus ejecuciones, métricas de rendimiento y parámetros de modelo se registran.
Para ver los experimentos:
En el panel izquierdo, seleccione el área de trabajo.
En la parte superior derecha, filtre para mostrar solo experimentos, para facilitar la búsqueda del experimento.
Busque y seleccione el nombre del experimento, en este caso bank-churn-experiment. Si no ve el experimento en el área de trabajo, actualice el explorador.
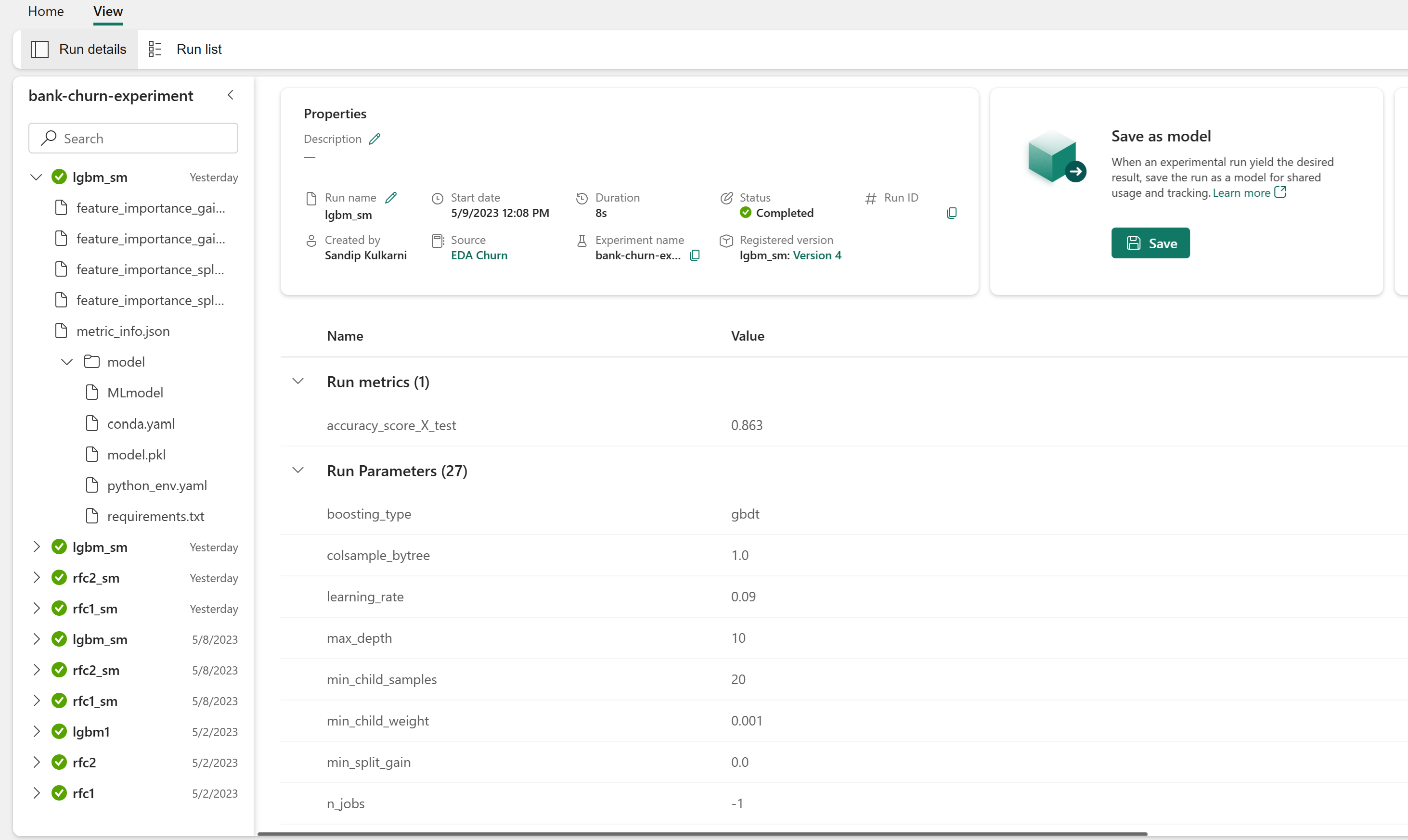


Evalúe los rendimientos de los modelos entrenados en el conjunto de datos de validación
Una vez haya terminado con el entrenamiento de modelos de Machine Learning, puede evaluar el rendimiento de los modelos entrenados de dos maneras.
Abra el experimento guardado desde el área de trabajo, cargue los modelo de Machine Learning y, a continuación, evalúe el rendimiento de los modelos cargados en el conjunto de datos de validación.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMEvalúe directamente los rendimientos de los modelos de Machine Learning entrenados en el conjunto de datos de validación.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Dependiendo de su preferencia, cualquiera de los enfoques es correcto y debe ofrecer rendimientos idénticos. En este cuaderno, elegirá el primer enfoque para demostrar mejor las funcionalidades del registro automático de MLflow en Microsoft Fabric.
Mostrar verdaderos/falsos positivos/negativos mediante la matriz de confusión
A continuación, desarrollará un script para trazar la matriz de confusión con el fin de evaluar la precisión de la clasificación usando el conjunto de datos de validación. La matriz de confusión también se puede trazar mediante herramientas de SynapseML, que se muestra en el ejemplo de Detección de Fraudes que está disponible aquí.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Una Matriz de Confusión para el clasificador de bosque aleatorio con una profundidad máxima de 4 y 4 características
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
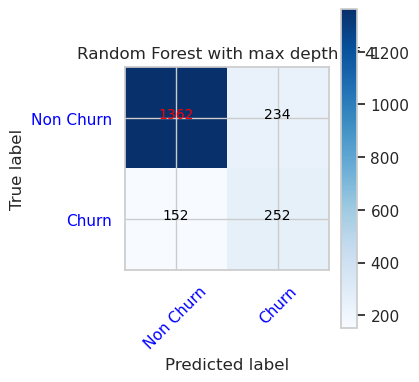
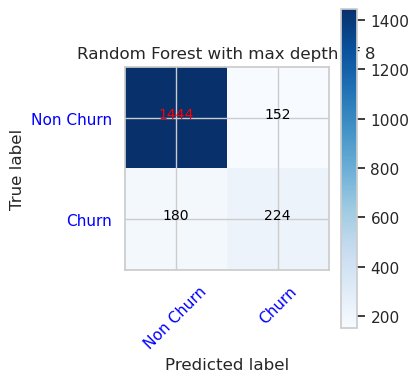
- Una Matriz de Confusión para el clasificador de bosque aleatorio con una profundidad máxima de 8 y 6 características
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
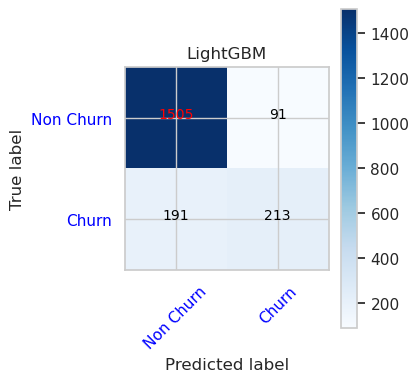
- Matriz de confusión para LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()