Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a: ✅ Punto de conexión de SQL Analytics y Almacén de datos en Microsoft Fabric
Los grupos de SQL personalizados proporcionan a los administradores más control sobre cómo se asignan los recursos para controlar las solicitudes. En este inicio rápido, configurará grupos de SQL personalizados y observará los valores del clasificador mediante la API REST de Fabric.
Los administradores del área de trabajo pueden usar el nombre de la aplicación (o el nombre del programa) de la cadena de conexión para enrutar las solicitudes a diferentes grupos de proceso. Los administradores del área de trabajo también pueden controlar el porcentaje de recursos a los que puede acceder cada grupo de SQL de cómputo, en función del límite de escala elástica de la capacidad del área de trabajo.
La API REST de Fabric define un punto de conexión unificado para las operaciones.
Prerrequisitos
- Acceso a un elemento de almacenamiento en un área de trabajo. Debe ser miembro del rol de Administrador.
Obtención de la configuración actual.
Use la SIGUIENTE API para obtener la configuración actual.
Ejemplo de cuaderno Fabric
Puede ejecutar el código de Python de ejemplo siguiente en un cuaderno de Fabric Spark.
- El código envía una
GETsolicitud a la API de configuración del grupo de SQL personalizado y devuelve la configuración del grupo de SQL personalizado para el área de trabajo. - El campo
workspace_idutilizamssparkutils.runtime.contextpara obtener el GUID del workspace en el que se ejecuta el notebook. Para configurar un grupo de SQL personalizado en un área de trabajo diferente, actualice elworkspace_idal GUID del área de trabajo donde desea configurar los grupos de SQL personalizados.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Configuración de grupos de SQL personalizados
En el ejemplo de Python siguiente se habilitan y configuran grupos de SQL personalizados. Puede ejecutar este código de Python en un cuaderno de Fabric Spark.
- La configuración de grupos de SQL personalizados solo está activa cuando
customSQLPoolsEnabledel atributo se establece en true. Puede definir una carga útil en lacustomSQLPoolsdefinición de objeto, pero si no establece customSQLPoolsEnabled en true, se ignora la carga útil y se usa la administración de cargas de trabajo autónomas. - El código configura dos grupos de SQL personalizados,
ContosoSQLPoolyAdhocPool.-
ContosoSQLPoolestá configurado para recibir el 70% de los recursos disponibles. El clasificador nombre de aplicación tiene el valor deMyContosoApp. - Todas las consultas SQL que proceden de una cadena de conexión que especifica el nombre de la
MyContosoAppaplicación se clasifican en elContosoSQLPoolgrupo de SQL personalizado y tienen acceso a 70% de los nodos totales de capacidad ampliable. - Todas las consultas SQL que no contienen
MyContosoAppen el nombre de la aplicación de la cadena de conexión se envían alAdhocgrupo de SQL personalizado, que se define como el grupo predeterminado. Estas solicitudes obtienen acceso a 30% de los nodos totales de capacidad ampliable.
-
- Todas las configuraciones de grupo de SQL personalizadas deben tener un grupo de SQL predeterminado identificado estableciendo el
isDefaultatributo en true. - La suma de todos los
maxResourcePercentagevalores debe ser menor o igual que 100%. - El campo
workspace_idutilizamssparkutils.runtime.contextpara obtener el GUID del workspace en el que se ejecuta el notebook. Para configurar un grupo de SQL personalizado en un área de trabajo diferente, actualice elworkspace_idal GUID del área de trabajo donde desea configurar los grupos de SQL personalizados.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Sugerencia
Use estos valores útiles de clasificador de nombre de la aplicación (regex) para el tráfico de Fabric.
- Para clasificar consultas de canalizaciones de Fabric, use
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$. - Para clasificar consultas de Power BI, use
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?). - Para clasificar las consultas desde el editor de consultas sql del portal de Fabric, use
DMS_user.
Establecer el nombre de la aplicación en SQL Server Management Studio (SSMS)
El clasificador para grupos de SQL personalizados utiliza el nombre de la aplicación o el nombre del programa como parámetro de las cadenas de conexión comunes.
En SQL Server Management Studio (SSMS), especifique el nombre del servidor para el almacenamiento y proporcione autenticación. Se recomienda Microsoft Entra MFA .
Seleccione el botón Avanzadas .
En la página Propiedades avanzadas , en Contexto, cambie el valor de Nombre de aplicación a
MyContosoApp.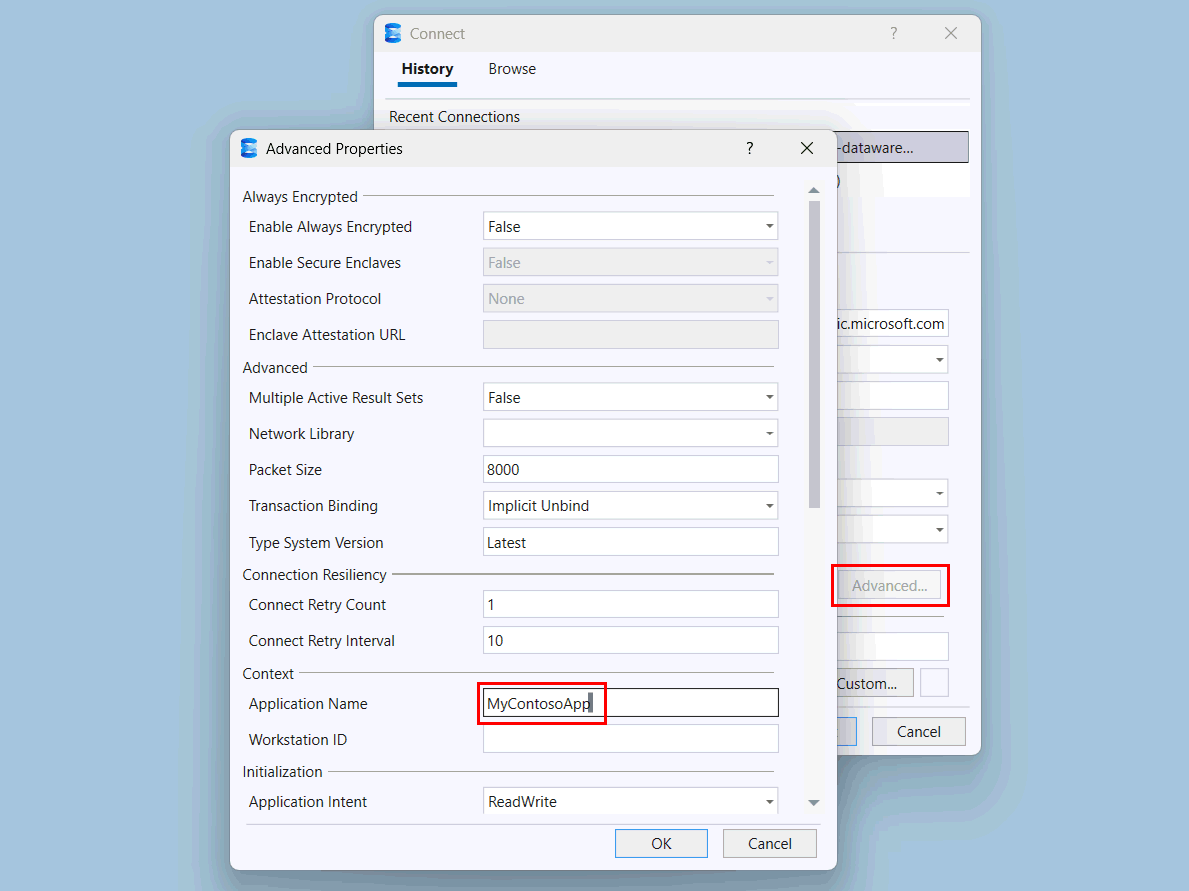
Selecciona Aceptar.
Seleccione Conectar.
Para generar alguna actividad de ejemplo, use esta conexión en SSMS para ejecutar una consulta sencilla en el almacenamiento, por ejemplo:
SELECT * FROM dbo.DimDate;

Observación de la información de consulta para el grupo de SQL personalizado
Revise la
sys.dm_exec_sessionsvista de administración dinámica para ver queMyContosoAppse reconoce como el nombre de la aplicación que se pasa de SSMS al motor de SQL.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Por ejemplo:
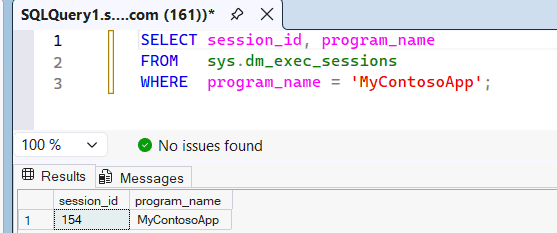
Dado que
program_namecoincide con el nombre de la aplicación en elMyContosoAppgrupo de SQL personalizado, esta consulta usa los recursos de ese grupo. Para demostrar qué grupo de SQL personalizado usó la consulta, puede consultar la vista del sistema de queryinsights.exec_requests_history . Espere entre 10 y 15 minutos para que la información de consulta se rellene y, a continuación, ejecute la consulta siguiente.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';También puede identificar el grupo de una consulta por su identificador de instrucción. En el editor de consultas SQL del portal de Fabric, ejecute una consulta en el almacén o en el punto de conexión de SQL Analytics.
SELECT * FROM dbo.DimDate;Seleccione la pestaña Mensajes y registre el Statement ID de la ejecución de la consulta. En el editor de consultas SQL,
program_nameesDMS_user, que configuró anteriormente para usar el pool de SQL personalizadoMyContosoApp.Espere entre 10 y 15 minutos para que la información de consulta se rellene.
Recupere
sql_pool_namey otra información para comprobar que se utilizó el grupo de SQL personalizado adecuado.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
Revertir la configuración de grupos de SQL personalizados
Para devolver el área de trabajo al estado original, cambie la customSQLPoolsEnabled propiedad a False. Si desea conservar la configuración de grupos de SQL personalizados, debe pasar cada nombre de grupo como en esta customSQLPools lista.
Este código de ejemplo en Python deshabilita los grupos de SQL personalizados y restablece la configuración autónoma de administración de cargas de trabajo a SELECT y a los grupos que no son SELECT. Se llama a una PATCH solicitud con la customSQLPoolsEnabled propiedad establecida en False.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)