Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se presenta la arquitectura de lago medallón y se describe cómo puedes implementar el patrón de diseño en Microsoft Fabric. Está dirigido a varios públicos:
- Ingenieros de datos: Personal técnico que diseña, compila y mantiene infraestructuras y sistemas que permiten a su organización recopilar, almacenar, procesar y analizar grandes volúmenes de datos.
- Equipos de centro de excelencia, TI y BI: Los equipos responsables de supervisar el análisis en toda la organización.
- Administradores de Fabric: Los administradores responsables de supervisar Fabric en la organización.
La arquitectura medallion lakehouse, comúnmente conocida como arquitectura medallion, es un patrón de diseño que usan las organizaciones para organizar lógicamente los datos en una casa de lago. Es el enfoque de diseño recomendado para Fabric. Dado que OneLake es el lago de datos para Fabric, la arquitectura de medallion se implementa a través de la creación de almacenes de lago en OneLake.
La arquitectura medallion consta de tres capas distintas, también denominadas zonas. Las tres capas de medallón son: bronce (datos sin procesar), plata (datos validados) y oro (datos enriquecidos). Cada capa indica la calidad de los datos almacenados en el lago, con niveles superiores que representan una mayor calidad. Este enfoque multicapa le ayuda a crear una única fuente de verdad para los productos de datos empresariales.
Importantemente, la arquitectura medallion garantiza la atomicidad, la coherencia, el aislamiento y la durabilidad (ACID) a medida que avanzan los datos a través de las capas. Los datos comienzan en su forma sin procesar y, a continuación, una serie de validaciones y transformaciones prepara los datos para optimizarlos para un análisis eficaz, al tiempo que mantiene las copias originales como fuente de verdad.
Para obtener más información, consulte ¿Qué es la arquitectura de medallion de almacén de lago?.
Arquitectura de Medallion en Fabric
El objetivo de la arquitectura medallion es mejorar de forma incremental y progresiva la estructura y la calidad de los datos a medida que avanzan a través de cada fase.
La arquitectura medallion consta de tres capas o zonas distintas.
- Bronce: También se denomina zona sin procesar, esta primera capa almacena los datos de origen en su formato original, incluidos los tipos de datos no estructurados, semiestructurados o estructurados. Los datos de esta capa suelen ser de solo anexión e inmutables. Al conservar los datos sin procesar en la capa de bronce, se mantiene una fuente de verdad y se habilita el reprocesamiento y la auditoría en el futuro.
- Plata: También se denomina zona enriquecida, esta capa almacena los datos procedentes de la capa de bronce. Los datos se limpian y normalizan y ahora se estructuran como tablas (filas y columnas). También puede integrarse con otros datos para proporcionar una vista empresarial de todas las entidades empresariales, como clientes, productos y mucho más.
- Oro: También llamada zona curada, esta capa final almacena los datos procedentes de la capa de plata. Los datos se refinan para satisfacer requisitos específicos de análisis y negocio de bajada. Las tablas normalmente se ajustan al diseño de esquema de estrella, que admite el desarrollo de modelos de datos optimizados para el rendimiento y la facilidad de uso.
Cada zona debe dividirse en su propio lago o almacenamiento de datos en OneLake, con datos que se mueven entre las zonas a medida que se transforman y refinan.
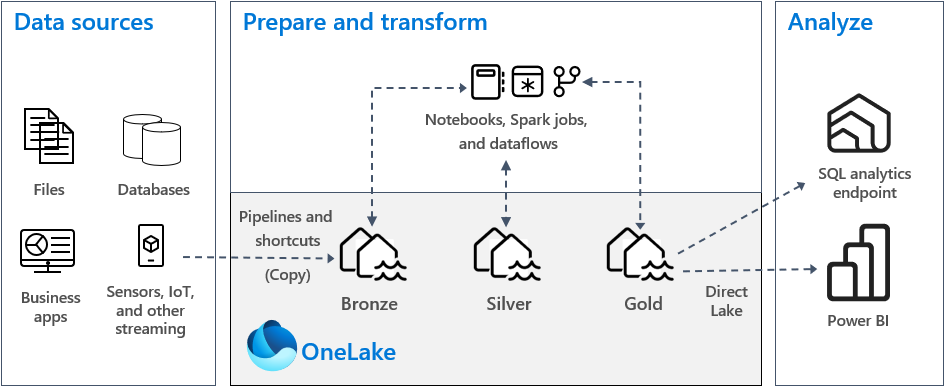
En una implementación típica de la arquitectura medallion en Fabric, la zona bronce almacena los datos en el mismo formato que el origen de datos. Cuando el origen de datos es una base de datos relacional, las tablas Delta son una buena opción. Las zonas Silver y Gold deben contener tablas Delta.
Sugerencia
Para aprender a crear un almacén de lago, consulte el tutorial Escenario de un extremo a otro de almacén de lago.
OneLake y almacén de lago en Fabric
La base de un almacenamiento de datos moderno es un lago de datos. Microsoft OneLake es un lago de datos lógico y unificado para toda la organización. Se aprovisiona automáticamente con todos los usuarios de Fabric y es la única ubicación de todos los datos de analítica.
Puede usar OneLake para:
- Quitar los silos y reducir el trabajo de administración. Todos los datos de la organización se almacenan, administran y protegen dentro de un recurso de lago de datos.
- Reducir el movimiento y la duplicación de datos. El objetivo de OneLake es almacenar solo una copia de datos. Menos copias de datos producen menos procesos de movimiento de datos y esto conduce a mejoras de eficiencia y reducción de la complejidad. Use accesos directos para hacer referencia a los datos almacenados en otras ubicaciones, en lugar de copiarlos en OneLake.
- Usar con varios motores analíticos. Los datos de OneLake se almacenan en formato abierto. De este modo, varios motores analíticos pueden consultar los datos, incluidos Analysis Services (que usa Power BI), T-SQL y Apache Spark. Otras aplicaciones que no son de Fabric pueden usar API y SDK para acceder también a OneLake .
Para almacenar datos en OneLake, cree un lakehouse en Fabric. Una instancia de Lakehouse es una plataforma de arquitectura de datos para almacenar, administrar y analizar datos estructurados y no estructurados en una sola ubicación. Se puede escalar a grandes volúmenes de datos de todos los tipos y tamaños de archivo, y dado que los datos se almacenan en una sola ubicación, se pueden compartir y reutilizar en toda la organización.
Cada almacén de lago tiene un punto de conexión de análisis SQL integrado que desbloquea las funcionalidades del Almacenamiento de datos sin necesidad de mover datos. Esto significa que puede consultar los datos en el almacén de lago mediante consultas SQL y sin ninguna configuración especial.
Para obtener más información, consulte ¿Qué es un almacén de lago en Microsoft Fabric?.
Tablas y archivos
Al crear un lakehouse en OneLake, se aprovisionan automáticamente dos ubicaciones de almacenamiento físico.
- Las tablas son un área administrada para almacenar tablas de todos los formatos en Apache Spark (CSV, Parquet o Delta). Todas las tablas, tanto si se crean automáticamente como explícitamente, se reconocen como tablas en el almacén de lago. Las tablas Delta, las cuales son archivos de datos Parquet con un registro de transacciones basado en archivos, también se reconocen como tablas.
- Los archivos son un área no administrada para almacenar datos en cualquier formato de archivo. Los archivos Delta almacenados en esta área no se reconocen automáticamente como tablas. Si desea crear una tabla sobre una carpeta de Delta Lake en el área no administrada, cree un acceso directo o una tabla externa con una ubicación que apunte a la carpeta no administrada que contiene los archivos de Delta Lake en Apache Spark.
La distinción principal entre el área administrada (tablas) y el área no administrada (archivos) es el proceso automático de detección y registro de tablas. Este proceso se ejecuta en cualquier carpeta creada solo en el área administrada, pero no en el área no administrada.
En la zona bronce, se almacenan datos en su formato original, que puede ser tablas o archivos. Si los datos de origen proceden de OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 o Google, cree un acceso directo en la zona bronce en lugar de copiar los datos.
En las zonas silver y gold, normalmente se almacenan datos en tablas Delta. Sin embargo, también puede almacenar datos en archivos Parquet o CSV. Si lo hace, debe crear explícitamente un acceso directo o una tabla externa con una ubicación que apunte a la carpeta no administrada que contiene los archivos de Delta Lake en Apache Spark.
En Microsoft Fabric, el explorador de Lakehouse proporciona una representación gráfica unificada de todo Lakehouse para que los usuarios naveguen, accedan y actualicen sus datos.
Para obtener más información sobre la detección automática de tablas, consulte Detección y registro de tablas automáticas.
Almacenamiento de Delta Lake
Delta Lake es una capa de almacenamiento optimizada que proporciona la base para almacenar datos y tablas. Admite transacciones ACID para cargas de trabajo de macrodatos y, por este motivo, es el formato de almacenamiento predeterminado en un almacén de lago de Fabric.
Delta Lake ofrece seguridad, rendimiento y fiabilidad tanto para operaciones de streaming y por lotes. Internamente, almacena datos en formato de archivo Parquet, pero también mantiene registros de transacciones y estadísticas que proporcionan características y mejora del rendimiento sobre el formato Parquet estándar.
El formato Delta Lake ofrece las siguientes ventajas en comparación con los formatos de archivo genéricos:
- Compatibilidad con las propiedades ACID, especialmente la durabilidad para evitar daños en los datos.
- Consultas de lectura más rápidas.
- Aumento de la actualización de los datos.
- Compatibilidad con cargas de trabajo por lotes y streaming.
- Compatibilidad con la reversión de datos mediante el Viaje en el tiempo de Delta Lake.
- Cumplimiento normativo mejorado y auditoría mediante elHistorial de tablas de Delta Lake.
Fabric estandariza el formato de archivo de almacenamiento con Delta Lake. De forma predeterminada, cada motor de carga de trabajo de Fabric crea tablas Delta al escribir datos en una nueva tabla. Para más información, consulte Tablas de Lakehouse y Delta Lake.
Modelo de implementación
Para implementar la arquitectura medallion en Fabric, puede usar almacenes de lago (uno para cada zona), un almacenamiento de datos o una combinación de ambos. Su decisión debe basarse en sus preferencias y la experiencia de su equipo. Con Fabric, puede usar diferentes motores analíticos que trabajan sobre la única copia de sus datos en OneLake.
Estos son dos patrones que se deben tener en cuenta:
- Patrón 1: Cree cada zona como un almacén de lago. En este caso, los usuarios empresariales acceden a los datos mediante el punto de conexión de análisis SQL.
- Patrón 2: Crear las zonas de bronce y plata como almacenes de lago y la zona dorada como un almacenamiento de datos. En este caso, los usuarios empresariales acceden a los datos mediante el punto de conexión de almacenamiento de datos.
Si bien puede crear todos los almacenes de lago en una única Área de trabajo de Fabric, le recomendamos que cree cada almacén de lago en su propia área de trabajo independiente. Este enfoque proporciona más control y mejor gobernanza en el nivel de zona.
Para la zona bronce, se recomienda almacenar los datos en su formato original o usar Parquet o Delta Lake. Siempre que sea posible, mantenga los datos en su formato original. Si los datos de origen proceden de OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 o Google, cree un acceso directo en la zona bronce en lugar de copiar los datos.
Para las zonas plata y oro, se recomienda usar tablas Delta debido a las funcionalidades adicionales y mejoras de rendimiento que proporcionan. Fabric normaliza el formato Delta Lake y, de forma predeterminada, cada motor de Fabric escribe datos en este formato. Además, estos motores usan la optimización en tiempo de escritura de orden V al formato de archivo Parquet. Esta optimización permite las lecturas rápidas de los motores de proceso de Fabric, como Power BI, SQL, Apache Spark y otros. Para obtener más información, consulte Optimización de tablas de Delta Lake y Orden V.
Por último, en la actualidad, muchas organizaciones se enfrentan al crecimiento masivo de los volúmenes de datos, junto con una creciente necesidad de organizar y administrar esos datos de forma lógica, al tiempo que facilitan un uso y gobernanza más dirigidos y eficientes. Esto puede llevar a establecer y administrar una organización de datos descentralizada o federada con gobernanza. Para cumplir este objetivo, considere la posibilidad de implementar una arquitectura de malla de datos. La malla de datos es un patrón arquitectónico que se centra en la creación de dominios de datos que ofrecen datos como producto.
Puede crear una arquitectura de malla de datos para el patrimonio de datos en Fabric mediante la creación de dominios de datos. Puede crear dominios que se asignen a los dominios empresariales, por ejemplo, marketing, ventas, inventario, recursos humanos y otros. A continuación, puede implementar la arquitectura medallion mediante la configuración de zonas de datos dentro de cada uno de los dominios. Para obtener más información sobre los dominios, consulte Dominios.
Descripción del almacenamiento de datos de tabla delta
En esta sección se describen otras instrucciones relacionadas con la implementación de una arquitectura de la casa de lago medallion en Fabric.
Tamaño de archivo
Por lo general, una plataforma de macrodatos funciona mejor cuando tiene algunos archivos grandes en lugar de muchos archivos pequeños. La degradación del rendimiento se produce cuando el motor de proceso tiene muchas operaciones de metadatos y archivos que se van a administrar. Para mejorar el rendimiento de las consultas, se recomienda que apunte a los archivos de datos que tienen un tamaño aproximado de 1 GB.
Delta Lake tiene una característica denominada optimización predictiva. La optimización predictiva automatiza las operaciones de mantenimiento de las tablas Delta. Cuando esta característica está habilitada, Delta Lake identifica las tablas que se beneficiarían de las operaciones de mantenimiento y, a continuación, optimiza su almacenamiento. Aunque esta característica debe formar parte de la excelencia operativa y el trabajo de preparación de datos, Fabric también puede optimizar los archivos de datos durante la escritura de datos. Para más información, consulte Optimización predictiva para Delta Lake.
Retención histórica
De forma predeterminada, Delta Lake mantiene un historial de todos los cambios realizados, por lo que el tamaño de los metadatos históricos crece con el tiempo. En función de los requisitos empresariales, mantenga los datos históricos solo durante un período de tiempo determinado para reducir los costos de almacenamiento. Considere la posibilidad de conservar los datos históricos solo durante el último mes u otro período de tiempo adecuado.
Puede quitar datos históricos más antiguos de una tabla Delta mediante el comando VACUUM. Sin embargo, de forma predeterminada no se pueden eliminar datos históricos en los últimos siete días. Esa restricción mantiene la coherencia en los datos. Configura el número predeterminado de días con la propiedad de la tabla delta.deletedFileRetentionDuration = "interval <interval>". Esa propiedad determina el período de tiempo que se debe eliminar un archivo antes de que se pueda considerar candidato para una operación de vacío.
Particiones de tabla
Al almacenar datos en cada zona, se recomienda usar una estructura de carpetas con particiones siempre que corresponda. Esta técnica mejora la capacidad de administración de datos y el rendimiento de las consultas. Por lo general, los datos particionados en una estructura de carpetas tienen como resultado una búsqueda más rápida de entradas de datos específicas debido a la eliminación o eliminación de particiones.
Normalmente, se anexan datos a la tabla de destino a medida que llegan nuevos datos. Sin embargo, en algunos casos podría combinar datos porque necesita actualizar los datos existentes al mismo tiempo. En ese caso, puede realizar una operación upsert mediante el comando MERGE. Cuando se particione la tabla de destino, asegúrese de usar un filtro de partición para acelerar la operación. De este modo, el motor puede eliminar las particiones que no requieren actualización.
Acceso a datos
Debe planear y controlar quién necesita acceso a datos específicos en almacén de lago de datos. También debe comprender los distintos patrones de transacción que se van a usar al acceder a estos datos. A continuación, puede definir el esquema de partición de tabla correcta y la intercalación de datos con índices de orden Z de Delta Lake.
Contenido relacionado
Para obtener más información sobre cómo implementar un almacén de lago de Fabric, consulte los siguientes recursos.
- Tutorial: Escenario de un extremo a otro de Lakehouse
- Tablas de Lakehouse y Delta Lake
- Guía de decisión de Microsoft Fabric: elección de un almacén de datos
- La necesidad de optimizar la escritura en Apache Spark
- ¿Tiene alguna pregunta? Intente preguntar a la comunidad de Fabric.
- ¿Sugerencias? Contribuir ideas para mejorar Fabric.