Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este documento se proporciona orientación específica basada en la experiencia para recuperar sus datos de Fabric en caso de un desastre regional.
Escenario de ejemplo
En muchas secciones de instrucciones de este documento se usa el siguiente escenario de ejemplo con fines de explicación e ilustración. Consulte este escenario según sea necesario.
Imagine que tiene una capacidad C1 en la región A que tiene un área de trabajo W1. Si ha activado la recuperación ante desastres para la capacidad C1, los datos de OneLake se replican en una copia de seguridad en la región B. Si la región A se enfrenta a interrupciones, el servicio Fabric en C1 cambia automáticamente a la región B.
Nota:
Esta guía de recuperación solo se aplica cuando la región primaria tiene una región secundaria emparejada de Azure y Fabric es compatible en la región emparejada.
Este escenario se ilustra en la imagen siguiente. En el cuadro de la izquierda se muestra la región interrumpida. En el cuadro central se representa la disponibilidad continua de los datos después de la conmutación por error y, en el cuadro de la derecha, se muestra la situación completamente cubierta después de que el cliente actúe para restaurar sus servicios a su plena funcionalidad.
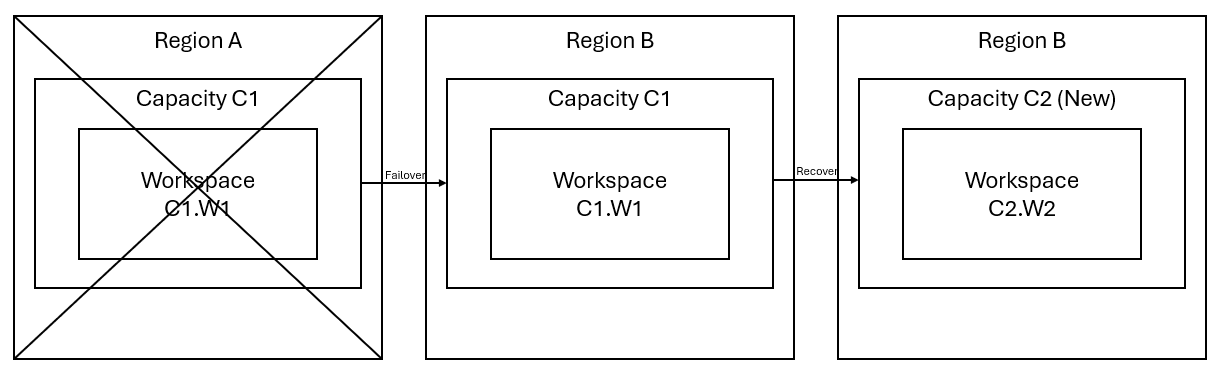
Este es el plan de recuperación general:
Cree una nueva capacidad de Fabric C2 en una nueva región.
Cree un área de trabajo W2 en C2, incluidos sus elementos correspondientes con los mismos nombres que en C1.W1.
Copie los datos del C1.W1 interrumpido a C2.W2.
Siga las instrucciones dedicadas de cada componente para restaurar los elementos a su funcionamiento completo.
Este plan de recuperación supone que la región de origen del cliente permanece operativa. Si la región principal del inquilino experimenta una interrupción, los pasos descritos en este documento dependen de su recuperación, que debe iniciarse y completarse por Microsoft.
Planes de recuperación personalizados por experiencia
En las secciones siguientes se proporcionan guías paso a paso para cada experiencia de Fabric para ayudar a los clientes a través del proceso de recuperación.
Ingeniería de datos
En esta guía se detallan los procedimientos de recuperación de la experiencia de ingeniería de datos. Abarca Lakehouses, notebooks y definiciones de trabajo de Spark.
Lakehouse
Los almacenes de lago de la región original siguen sin estar disponibles para los clientes. Para recuperar un almacén de lago, los clientes pueden volver a crearlo en el área de trabajo C2.W2. Recomendamos dos enfoques para la recuperación de los lakehouses:
Enfoque 1: Uso de un script personalizado para copiar tablas y archivos Delta del Lakehouse
Los clientes pueden volver a crear los almacenes de lago mediante un script de Scala personalizado.
Cree el lakehouse (por ejemplo, LH1) en el área de trabajo recién creada C2.W2.
Cree un cuaderno en el área de trabajo C2.W2.
Para recuperar las tablas y los archivos del lago original, consulte los datos con rutas de acceso de OneLake como abfss (consulte Conectando a Microsoft OneLake). Puede usar el siguiente ejemplo de código (consulte Introducción a las utilidades de Microsoft Spark) en el cuaderno para obtener las rutas de acceso ABFS de archivos y tablas del Lakehouse original. (Reemplace C1.W1 con el nombre real del área de trabajo)
notebookutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Use el ejemplo de código siguiente para copiar tablas y archivos en el almacén de lago recién creado.
En el caso de las tablas Delta, debe copiar cada tabla individualmente para recuperarlas en el nuevo lakehouse. En el caso de los archivos de Lakehouse, puede copiar la estructura completa de archivos con todas las carpetas subyacentes en una sola ejecución.
Póngase en contacto con el equipo de soporte técnico para obtener la marca de tiempo de la conmutación por error necesaria en el script.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support notebookutils.fs.cp(source, destination, true) val filesToDelete = notebookutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelete <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelete.name}" println(s"Deleting file $destFileToDelete") notebookutils.fs.rm(destFileToDelete, false) } notebookutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Una vez ejecutado el script, las tablas aparecen en el nuevo lakehouse.
Enfoque 2: Uso de Azure Storage Explorer para copiar archivos y tablas
Para recuperar solo archivos o tablas específicos desde el Lakehouse original, use Azure Storage Explorer. Consulte Integrate OneLake con Azure Storage Explorer para ver los pasos detallados. Para tamaños de datos grandes, use Enfoque 1.
Nota:
Los dos enfoques descritos anteriormente recuperan los metadatos y los datos de las tablas con formato Delta, ya que los metadatos están colocados y almacenados con los datos de OneLake. En el caso de las tablas con formato no delta (por ejemplo, CSV, Parquet, etc.) que se crean mediante scripts o comandos del lenguaje de definición de datos de Spark (DDL), el usuario es responsable de mantener y volver a ejecutar los scripts o comandos DDL de Spark para recuperarlos.
Recuperación de vistas materializadas de lago de Fabric
Las vistas materializadas de Lake de la región original siguen sin estar disponibles para los clientes después de la conmutación por error. Las programaciones de actualización y el historial de ejecución no se replican en la región secundaria. Para recuperarlos, complete los pasos siguientes después de recuperar los datos de Lakehouse.
- Recupere las tablas de Lakehouse mediante el enfoque 1 o el enfoque 2 descritos anteriormente. Copie solo las tablas de origen.
- Recupere los cuadernos que contienen sus definiciones de MLV. Consulte la sección Cuaderno para conocer los pasos de recuperación.
- Ejecute los cuadernos recuperados para volver a crear los MLV en el nuevo Lakehouse. Para obtener información sobre cómo crear MLV, consulte Creación de una vista materializada de Lago. Si los MLV también se copiaron en el paso anterior, ejecute CREATE OR REPLACE al volver a crearlos.
- Vuelva a crear manualmente las programaciones de actualización de MLV en el nuevo espacio de trabajo. El historial de programación y las métricas de ejecución no se pueden recuperar.
- Si los MLV alimentan los informes o modelos semánticos, compruebe y actualice las referencias del Lakehouse ID y del identificador del conjunto de datos según sea necesario. Vuelva a conectar los informes al modelo semántico actualizado y valide la actualización de los datos.
Sugerencia
Para minimizar los cambios de código al ejecutar cuadernos después de la conmutación por error, use el mismo área de trabajo y los nombres de Lakehouse en la nueva región (especialmente cuando se usa el nombre workspace o Lakehouse en las convenciones de nomenclatura). Las programaciones de actualización, el historial de ejecución y las métricas operativas se inician desde cero en la región restaurada. Planee un período de línea base al establecer nuevos umbrales de supervisión.
Notebook
Los cuadernos de la región primaria siguen sin estar disponibles para los clientes y el código de los cuadernos no se replica en la región secundaria. Hay dos enfoques para recuperar el código del cuaderno en la nueva región.
Enfoque 1: Redundancia administrada por el usuario con integración de Git (en versión preliminar pública)
La mejor manera de facilitar y agilizar este proceso es usar Fabric integración de Git y, a continuación, sincronizar el cuaderno con el repositorio de ADO. Una vez que el servicio conmuta por error a otra región, puede usar el repositorio para recompilar el cuaderno en el área de trabajo que ha creado.
Configure la integración de Git para su área de trabajo y seleccione Conectar y sincronizar con el repositorio de ADO.
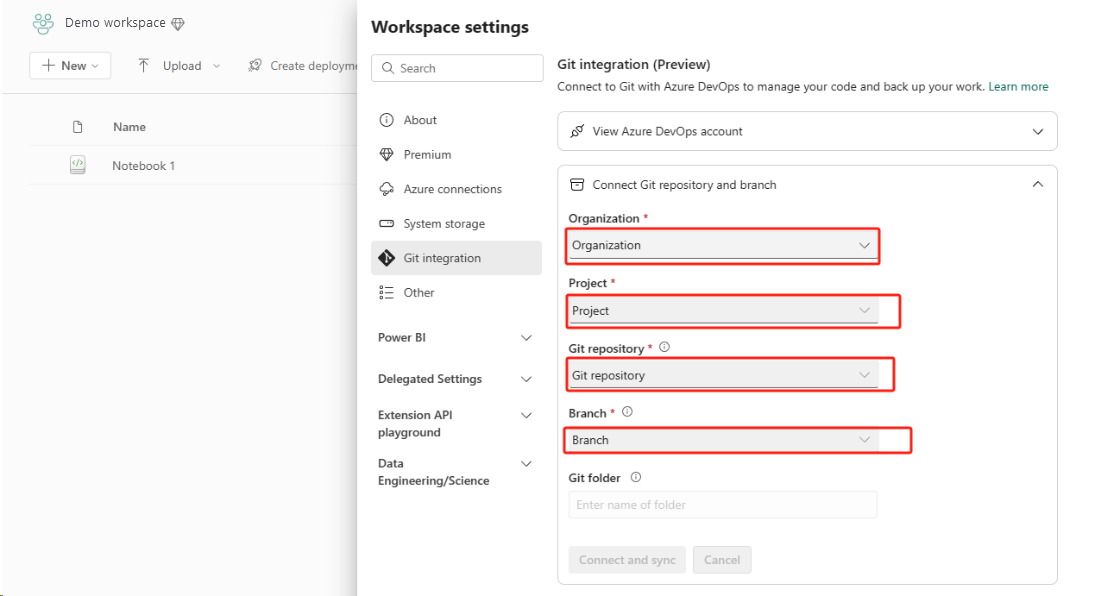
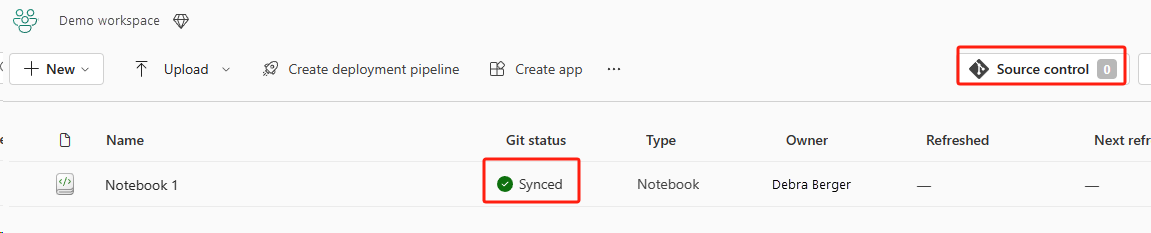
En la imagen siguiente se muestra el cuaderno sincronizado.
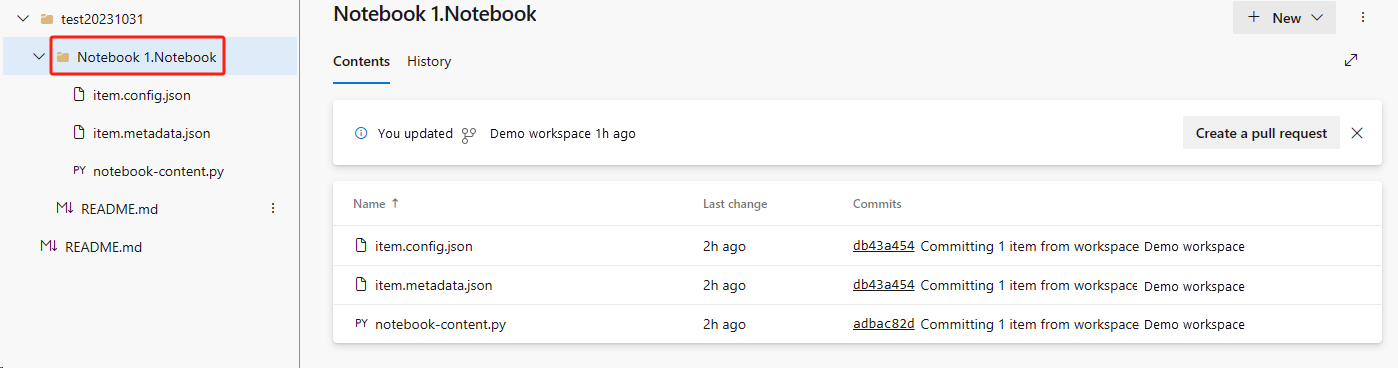
Recupere el cuaderno del repositorio de ADO.
En el área de trabajo recién creada, vuelva a conectarse al repositorio de ADO de Azure.
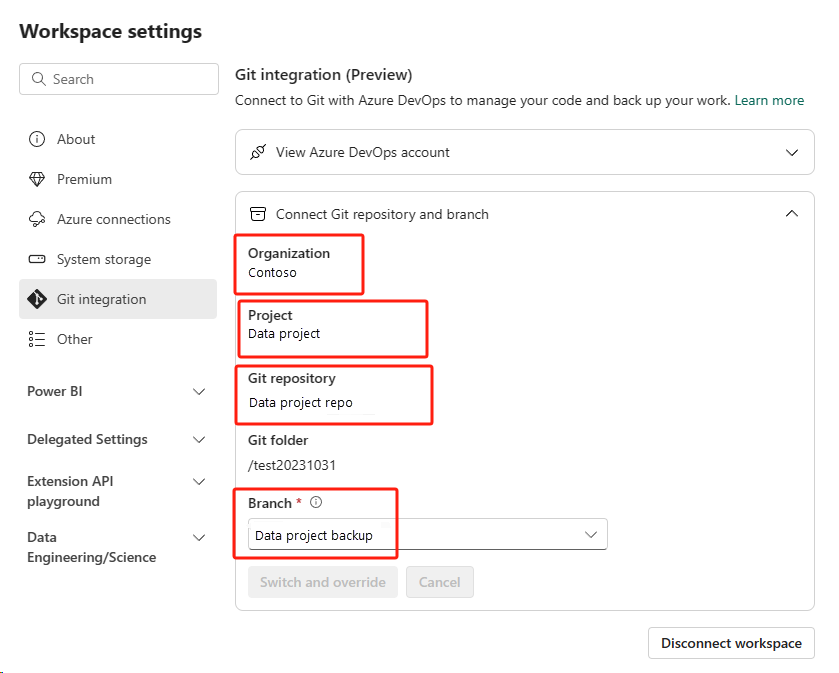
Seleccione el botón de control de código fuente. Después, seleccione la rama correspondiente del repositorio. Luego, seleccione Actualizar todo. Aparece el bloc de notas original.
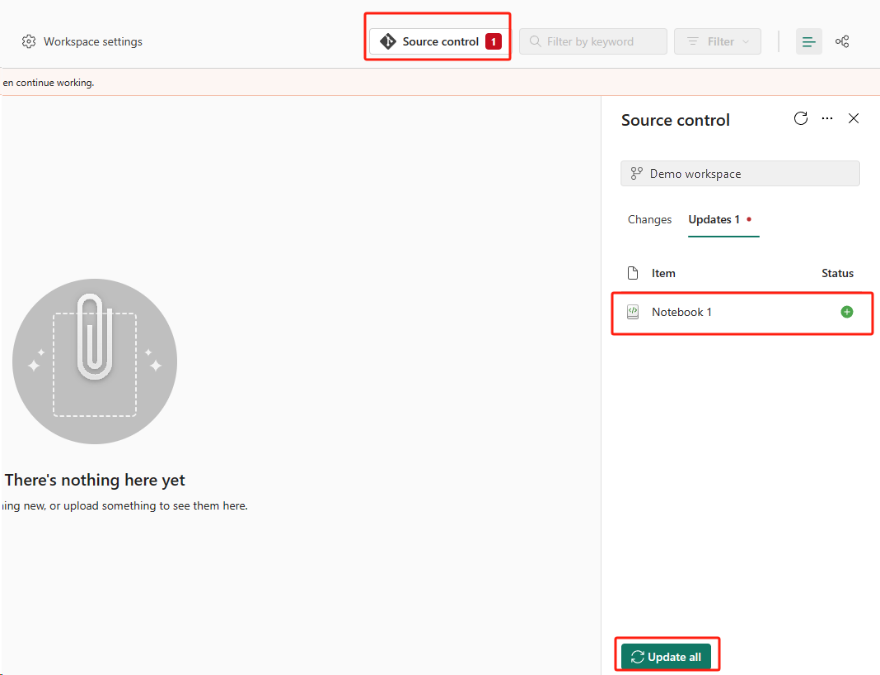
Si el cuaderno original tiene un lakehouse predeterminado, los usuarios pueden hacer referencia a la sección Lakehouse para recuperarlo y luego conectar el lakehouse recién recuperado al cuaderno recién recuperado.
La integración de Git no admite la sincronización de archivos, carpetas ni instantáneas de cuadernos en el explorador de recursos del cuaderno.
Si el cuaderno original tiene archivos en el explorador de recursos del cuaderno:
Asegúrese de guardar los archivos o carpetas en un disco local u otro lugar.
Vuelva a cargar el archivo desde el disco local o las unidades en la nube en el cuaderno recuperado.
Si el cuaderno original tiene una instantánea de cuaderno, guárdela también en su propio sistema de control de versiones o en el disco local.
Para más información sobre la integración de Git, vea Introducción a la integración de Git.
Enfoque 2: Enfoque manual para realizar copias de seguridad del contenido de código
Si no adopta el enfoque de integración de Git, puede guardar la versión más reciente del código, los archivos en el explorador de recursos y la instantánea del cuaderno en un sistema de control de versiones, como Git, y recuperar manualmente el contenido del cuaderno después de un desastre:
Use la característica "Importar cuaderno" para importar el código del cuaderno que quiera recuperar.
Después de la importación, vaya al área de trabajo deseada (por ejemplo, "C2.W2") para acceder a ella.
Si el cuaderno original tiene un lakehouse predeterminado, consulte la sección Lakehouse. Después, conecte el lakehouse recién recuperado (que tiene el mismo contenido que el lakehouse predeterminado original) al notebook recién recuperado.
Si el cuaderno original tiene archivos o carpetas en el explorador de recursos, vuelva a cargar los archivos o carpetas guardados en el sistema de control de versiones del usuario.
Definición de trabajos de Spark
Las definiciones de trabajos de Spark (SJD) de la región primaria siguen sin estar disponibles para los clientes, y el archivo de definición principal y el archivo de referencia del cuaderno se replicarán en la región secundaria mediante OneLake. Si quiere recuperar la SJD en la nueva región, puede seguir los pasos manuales que se describen a continuación para hacerlo. Los registros históricos del SJD no se recuperarán.
Para recuperar los elementos SJD, copie el código de la región original mediante Azure Storage Explorer y vuelva a conectar manualmente las referencias de Lakehouse después del desastre.
Cree un elemento de SJD (por ejemplo, SJD1) en el nuevo área de trabajo C2.W2, con los mismos valores y configuraciones que el elemento de SJD original (por ejemplo, idioma, entorno, etc.).
Utiliza Azure Storage Explorer para copiar Libs, Mains e instantáneas del elemento SJD original al nuevo elemento SJD.
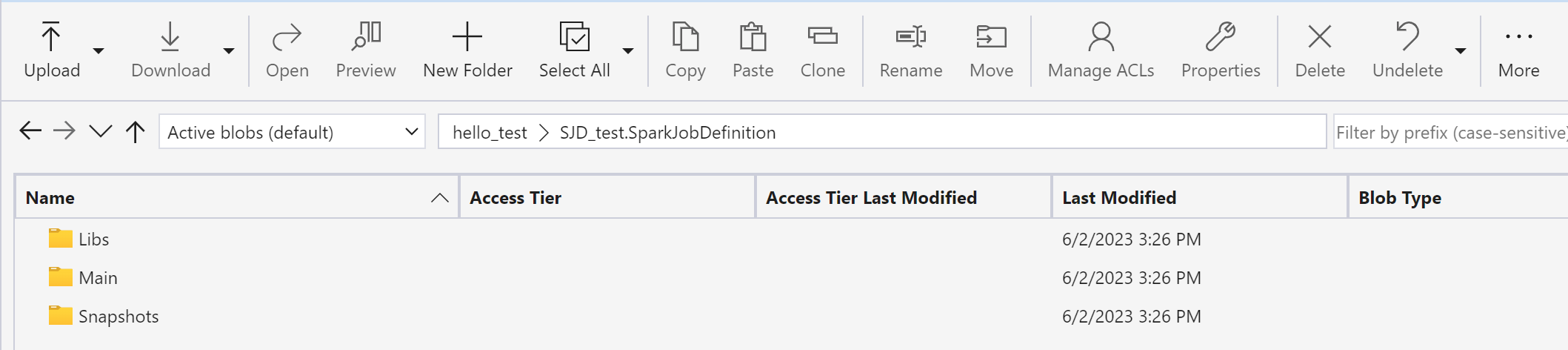
El contenido del código aparecerá en la SJD recién creada. Tendrá que agregar manualmente al trabajo la referencia de Lakehouse recién recuperada (consulte los pasos de recuperación de Lakehouse). Los usuarios tendrán que volver a escribir manualmente los argumentos de la línea de comandos originales.
Ahora puede ejecutar o programar su SJD recién recuperada.
Para obtener más información sobre Azure Storage Explorer, consulte Integrate OneLake con Azure Storage Explorer.
Ciencia de datos
En esta guía se detallan los procedimientos de recuperación de la experiencia de ciencia de datos. Se describen modelos y experimentos de ML.
Modelo y experimento de ML
Los elementos de ciencia de datos de la región primaria siguen sin estar disponibles para los clientes, y el contenido y los metadatos de los modelos y experimentos de ML no se replicarán en la región secundaria. Para recuperarlos completamente en la nueva región, guarde el contenido del código en un sistema de control de versiones (como Git) y vuelva a ejecutar manualmente el contenido del código después del desastre.
Recupere el cuaderno. Consulte los pasos de recuperación de portátiles.
La configuración, las métricas de ejecución histórica y los metadatos no se replicarán en la región emparejada. Tendrá que volver a ejecutar cada versión del código de ciencia de datos para recuperar completamente los modelos y experimentos de ML después del desastre.
Almacén de Datos
Esta guía le guía por los procedimientos de recuperación de la experiencia de Data Warehouse. Cubre almacenes.
Almacén
Los almacenes de la región original siguen sin estar disponibles para los clientes. Para recuperar los almacenes, siga estos dos pasos.
Cree un almacén de lago provisional en el área de trabajo C2.W2 para los datos que copiará del almacén original.
Rellene las tablas Delta del almacenamiento aprovechando el Explorador de almacenamiento y las funcionalidades de T-SQL (consulte Tables en el almacenamiento de datos en Microsoft Fabric).
Nota:
Se recomienda mantener el código de almacenamiento (esquema, tabla, vista, procedimiento almacenado, definiciones de función y códigos de seguridad) con versiones y guardarlo en una ubicación segura (como Git) según los procedimientos de desarrollo.
Ingesta de datos a través del Lakehouse y del código T-SQL
En el área de trabajo C2.W2 recién creada:
Cree un almacén de lago provisional "LH2" en C2.W2.
Siga los pasos de recuperación del Lakehouse para recuperar las tablas Delta en el lakehouse provisional del almacén original.
Cree un almacén "WH2" en C2.W2.
Conecte el almacén de lago provisional en el explorador de almacenamiento.
En función de cómo vaya a implementar las definiciones de tabla antes de la importación de datos, el T-SQL real que se usa para las importaciones puede variar. Puede usar el enfoque INSERT INTO, SELECT INTO o CREATE TABLE AS SELECT para recuperar las tablas de almacenamiento de los almacenes de lago. En un paso posterior del ejemplo, usaremos el formato INSERT INTO. (Si usa el código siguiente, reemplace los ejemplos por nombres reales de tabla y columna)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOPor último, cambie la cadena de conexión en las aplicaciones usando su almacén de Fabric.
Nota:
Para los clientes que necesitan recuperación ante desastres entre regiones y continuidad empresarial totalmente automatizada, se recomienda mantener dos configuraciones de almacenamiento de Fabric en regiones de Fabric independientes y mantener la paridad de código y datos realizando implementaciones periódicas y ingesta de datos en ambos sitios.
Base de datos reflejada
Las bases de datos reflejadas de la región primaria siguen sin estar disponibles para los clientes y la configuración no se replica en la región secundaria. Para recuperarla en caso de error regional, debe volver a crear la base de datos replicada en otro espacio de trabajo de una región diferente.
Fábrica de Datos
Los elementos de Data Factory de la región primaria siguen sin estar disponibles para los clientes, y los ajustes y la configuración en las canalizaciones o elementos de flujo de datos Gen2 no se replicarán en la región secundaria. Para recuperar estos elementos en caso de un error regional, deberá volver a crear los elementos de integración de datos en otra área de trabajo desde otra región. En las secciones siguientes se describen los detalles.
Flujos de datos Gen2
Si quiere recuperar un elemento de Flujo de datos Gen2 en la nueva región, debe exportar un archivo PQT a un sistema de control de versiones como Git y, luego, recuperar manualmente el contenido de Flujo de datos Gen2 después del desastre.
En el elemento Dataflow Gen2, en la pestaña Inicio del editor de Power Query, seleccione Export template.
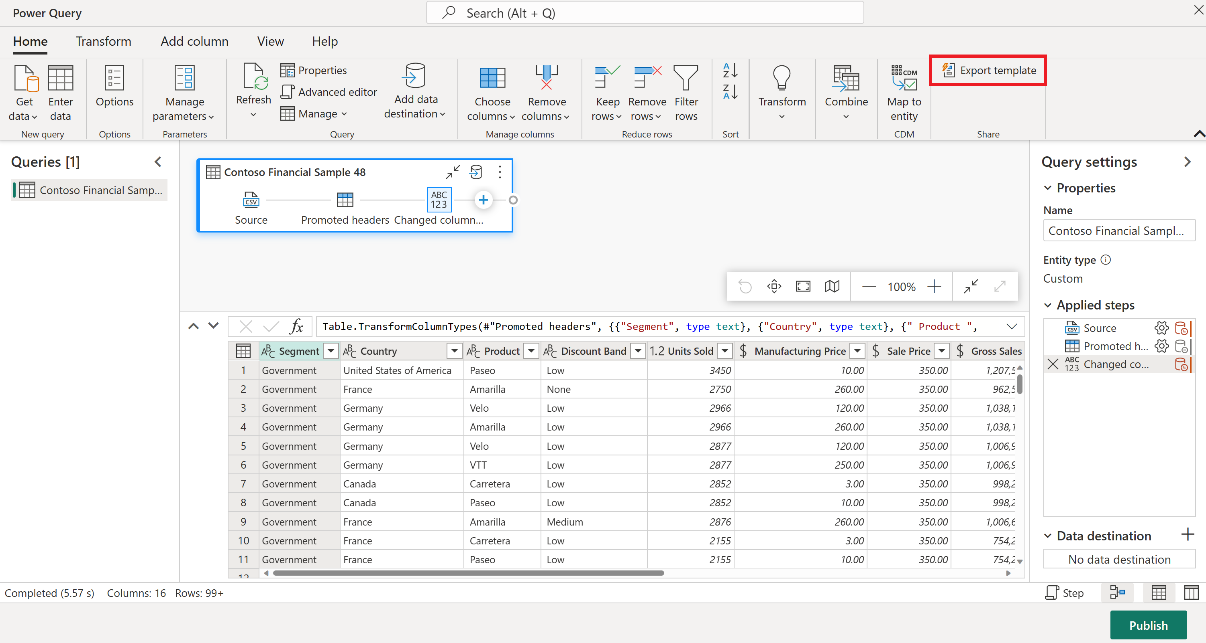
En el cuadro de diálogo Exportar plantilla, escriba un nombre (obligatorio) y una descripción (opcional) para esta plantilla. Cuando termine, seleccione Aceptar.
Después del desastre, cree un elemento de Dataflow Gen2 en el nuevo área de trabajo "C2.W2".
En el panel de vista actual del editor de Power Query, seleccione Importar en una plantilla de Power Query.
En el cuadro de diálogo Abrir, vaya a la carpeta Descargas predeterminada y seleccione el archivo .pqt que ha guardado en los pasos anteriores. A continuación, seleccione Abrir.
Después, la plantilla se importa al nuevo elemento Flujo de datos Gen2.
La función "Guardar como" de los flujos de datos no está disponible en situaciones de recuperación ante desastres.
Tuberías
Los clientes no pueden acceder a canalizaciones en caso de desastre regional y las configuraciones no se replican en la región emparejada. Recomendamos construir sus canalizaciones críticas en varios espacios de trabajo en distintas regiones.
Copiar trabajo
Los usuarios de CopyJob deben adoptar medidas proactivas para protegerse frente a un desastre regional. El siguiente enfoque garantiza que, después de un desastre regional, los CopyJobs de un usuario permanecen disponibles.
Redundancia administrada por el usuario con la integración de Git (en versión preliminar pública)
La mejor manera de facilitar y agilizar este proceso es usar Fabric integración de Git y, a continuación, sincronizar copyJob con el repositorio de ADO. Una vez que el servicio se traslade a otra región, puede usar el repositorio para recompilar el CopyJob en el nuevo área de trabajo que creó.
Configure la integración de Git del área de trabajo y seleccione conectar y sincronizar con el repositorio de ADO.
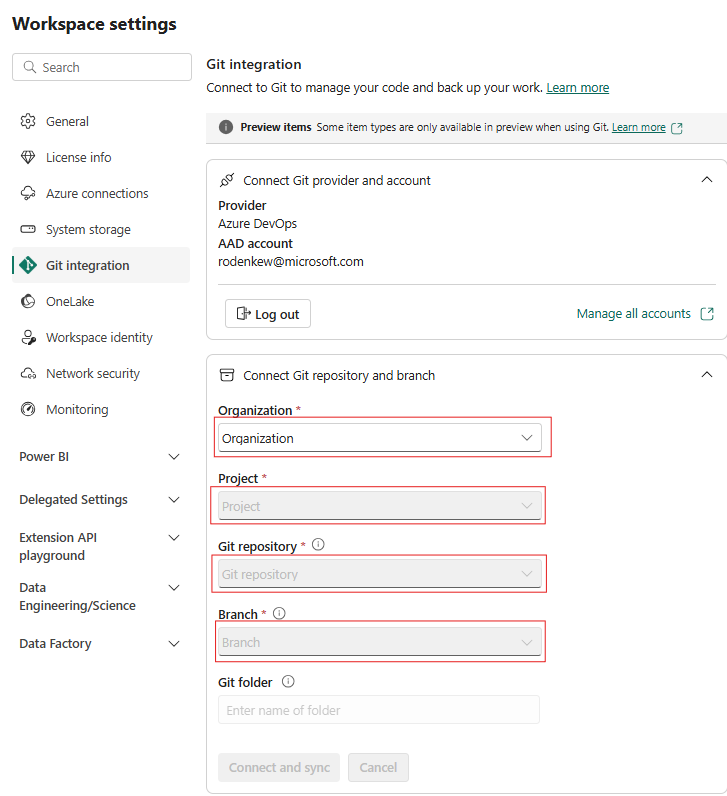
En la siguiente imagen se muestra el CopyJob sincronizado.
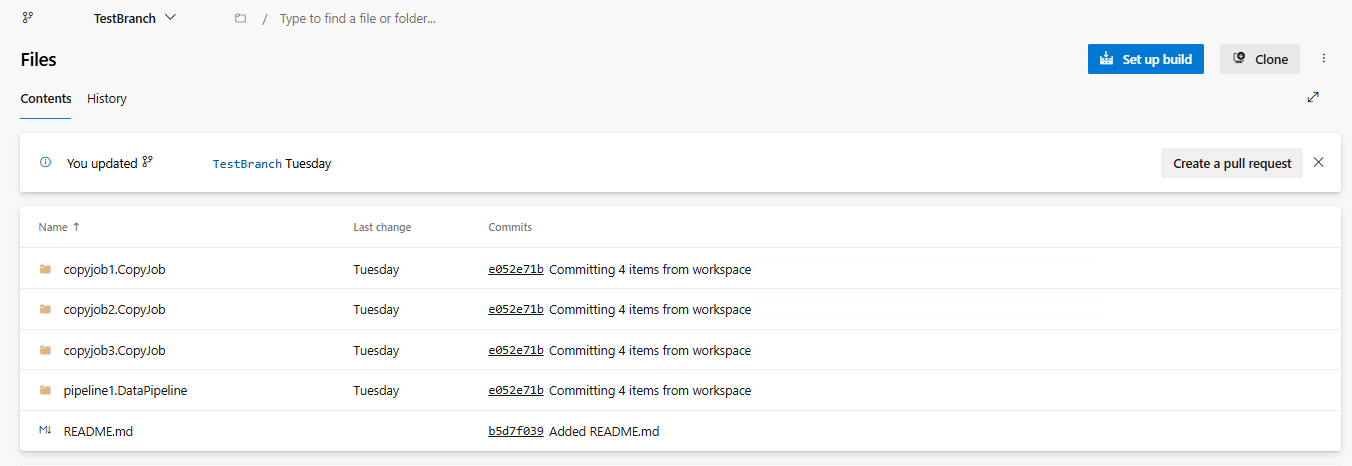
Recupere copyJob del repositorio de ADO.
En el área de trabajo recién creada, conéctese y sincronice con el repositorio de ADO de Azure de nuevo. Todos los elementos Fabric de este repositorio se descargan automáticamente en el nuevo área de trabajo.
Si el copyJob original usa una instancia de Lakehouse, los usuarios pueden hacer referencia a la sección Lakehouse para recuperar Lakehouse y, a continuación, conectar el copyJob recién recuperado a la instancia de Lakehouse recién recuperada.
Para más información sobre la integración de Git, vea Introducción a la integración de Git.
Trabajo de Apache Airflow
Los usuarios de trabajos de Apache Airflow en Fabric deben adoptar medidas proactivas para protegerse contra un desastre regional.
Se recomienda gestionar la redundancia con la integración de Git de Fabric. En primer lugar, sincronice su Airflow Job con su repositorio de ADO. Si el servicio conmuta por error a otra región, puede usar el repositorio para reconstruir la tarea de Airflow en el nuevo espacio de trabajo que creó.
Estos son los pasos para lograrlo:
Configure la integración de Git del área de trabajo y seleccione "conectar y sincronizar" con el repositorio de ADO.
Después, verá que el trabajo de Airflow se ha sincronizado con el repositorio de ADO.
Si necesita recuperar el trabajo de Flujo de aire desde el repositorio de ADO, cree una nueva área de trabajo, conéctese y sincronice con el repositorio de ADO de Azure. Todos los elementos de Fabric, incluido Airflow, en este repositorio se descargarán automáticamente a tu nueva área de trabajo.
Inteligencia en tiempo real
En esta guía se detallan los procedimientos de recuperación de la experiencia de inteligencia en tiempo real. Se describen bases de datos o conjuntos de consultas KQL y secuencias de eventos.
Modelo de Grafo/Conjunto de consultas
Los elementos de Graph Model y Graph Queryset de la región primaria siguen sin estar disponibles para los clientes y estos elementos no se replican en la región secundaria. Para recuperar, crear o utilizar una capacidad en otra región, y allí volver a crear los elementos de Graph Model y Graph Queryset.
Cree o use una capacidad de Fabric existente en otra región que no se vea afectada por el desastre.
Cree una nueva área de trabajo o use un área de trabajo existente en esa capacidad.
Vuelva a crear el elemento Modelo de grafo en el área de trabajo secundaria (a la que se hace referencia en el paso 2). Vuelva a configurar la definición del modelo, incluidos los nodos, los bordes, etc., para que coincidan con el modelo de Graph original.
Si el lakehouse original se encuentra en la región con errores, recupérelo primero siguiendo la sección Lakehouse.
Conecte una instancia de Lakehouse como origen de datos de OneLake para el modelo de gráfico recién creado. Use el lakehouse recuperado si se encontraba en la región fallida, o reconéctese al lakehouse existente si permanece disponible.
Vuelva a configurar las programaciones o conexiones de carga de datos para el modelo de Graph en el nuevo área de trabajo.
Vuelva a crear el elemento Conjunto de consultas de Graph en el área de trabajo secundaria. Vuelva a escribir manualmente las consultas y las configuraciones de consulta guardadas del conjunto de consultas de Graph original.
Base de datos KQL / Queryset
Los usuarios de bases de datos o conjuntos de consultas KQL deben adoptar medidas proactivas para protegerse frente a un desastre regional. El siguiente enfoque garantiza que, en caso de desastre regional, los datos de los conjuntos de consultas y bases de datos KQL permanecen seguros y accesibles.
Siga estos pasos para garantizar una solución de recuperación ante desastres eficaz para bases de datos y conjuntos de consultas de KQL.
Establecer bases de datos KQL independientes: configure dos o más bases de datos o conjuntos de consultas KQL independientes en capacidades de Fabric dedicadas. Deben configurarse en dos regiones de Azure diferentes (preferentemente regiones de Azure emparejadas) para maximizar la resistencia.
Replicar actividades de administración: cualquier acción de administración realizada en una base de datos de KQL se debe reflejar en la otra. Esto garantiza que ambas bases de datos permanezcan sincronizadas. Entre las actividades clave que se van a replicar se incluyen las siguientes:
Tablas: asegúrese de que las estructuras de tabla y las definiciones de esquema sean coherentes entre las bases de datos.
Mapeo: Duplique cualquier mapeo requerido. Asegúrese de que los orígenes de datos y los destinos se alinean correctamente.
Directivas: asegúrese de que ambas bases de datos tengan directivas similares de retención de datos, de acceso y demás directivas pertinentes.
Administrar la autenticación y la autorización: para cada réplica, configure los permisos necesarios. Asegúrese de que se establecen los niveles de autorización adecuados y de conceder acceso al personal necesario al tiempo que mantiene los estándares de seguridad.
Ingesta de datos paralelos: para mantener los datos coherentes y listos en varias regiones, cargue el mismo conjunto de datos en cada base de datos KQL al mismo tiempo que la ingiere.
Flujo de eventos
Un flujo de eventos es un lugar centralizado en la plataforma de Fabric para capturar, transformar y enrutar eventos en tiempo real a varios destinos (por ejemplo, lakehouses, bases de datos KQL o conjuntos de consultas) con una experiencia sin necesidad de programación. Siempre que los destinos sean compatibles con la recuperación ante desastres, las secuencias de eventos no perderán datos. Por tanto, los clientes deben usar las funcionalidades de recuperación ante desastres de esos sistemas de destino para garantizar la disponibilidad de los datos.
Los clientes también pueden lograr redundancia geográfica implementando cargas de trabajo de Eventstream idénticas en varias regiones de Azure como parte de una estrategia activa o activa de varios sitios. Con un enfoque activo/activo de varios sitios, los clientes pueden acceder a su carga de trabajo en cualquiera de las regiones implementadas. Este enfoque es el más complejo y costoso para la recuperación ante desastres, pero puede reducir el tiempo de recuperación a casi cero en la mayoría de las situaciones. Para obtener una redundancia geográfica completa, los clientes pueden
Crear réplicas de sus orígenes de datos en regiones diferentes.
Cree elementos Eventstream en las regiones correspondientes.
Conectar estos nuevos elementos a los orígenes de datos idénticos.
Agregar destinos idénticos para cada secuencia de eventos en regiones diferentes.
Mapa
Los elementos de mapa de la región primaria siguen sin estar disponibles para los clientes y los elementos de mapa no se replican en la región secundaria.
Si quiere recuperar un elemento de mapa cuando se produzca un desastre, configure la integración de Fabric Git y sincronice el elemento de mapa con el repositorio de Git.
Durante la recuperación, después de configurar la nueva región o capacidad en Fabric, puede usar el repositorio para reconstruir el elemento de mapa en la nueva área de trabajo que ha creado. Dado que la nueva área de trabajo está vacía, Git sync obtiene el contenido del repositorio en el área de trabajo vacía. Este paso reactiva el elemento de mapa.
Nota:
Si el elemento de mapa original tiene configurado un lakehouse o un conjunto de consultas KQL, consulte la sección de Lakehouse y la sección de consultas KQL para recuperarlos primero. Una vez que esas dependencias se hayan gestionado, conecte el lakehouse recién recuperado y al conjunto de consultas al elemento Map recién recuperado.
Ontología
Los usuarios de ontología deben realizar pasos proactivos para prepararse para la recuperación ante desastres regional. El enfoque descrito a continuación garantiza que, después de un desastre regional, la ontología permanece recuperable y se puede restaurar rápidamente.
La manera más sencilla y rápida de habilitar la recuperación es usar Fabric integración de Git y sincronizar la ontología con un repositorio de Azure DevOps (ADO). Si el servicio conmuta por error a otra región, puede usar este repositorio para volver a generar la ontología en un área de trabajo recién creada.
Los elementos de ontología de la región primaria no están disponibles para los clientes después de un desastre regional y los elementos de ontología no se replican en la región secundaria.
Para recuperar un elemento de ontología durante un desastre, configure la integración de Fabric Git y sincronice el elemento de ontología con su repositorio de ADO con antelación.
Durante la recuperación, una vez configurada la nueva región y la capacidad en Fabric, puede usar el repositorio para volver a generar el elemento de ontología en un nuevo espacio de trabajo. Dado que la nueva área de trabajo está vacía, Git sync extrae el contenido del repositorio en el área de trabajo, restaurando eficazmente el elemento Ontology.
Nota:
Si el elemento de ontología original tiene configurado un lakehouse, consulte la sección Lakehouse para primero recuperar el lakehouse. Después de ocuparse de esas dependencias, conecte el lakehouse recién recuperado al elemento ontología recién recuperado.
Base de datos transaccional
En esta guía se describen los procedimientos de recuperación para la experiencia de base de datos transaccional.
SQL database
Para protegerse frente a un error regional, los usuarios de bases de datos SQL pueden tomar medidas proactivas para exportar periódicamente sus datos y usar los datos exportados para volver a crear la base de datos en una nueva área de trabajo cuando sea necesario.
Esto se puede lograr mediante la herramienta de la CLI de SqlPackage que proporciona portabilidad de base de datos y facilita las implementaciones de bases de datos.
- Use la herramienta SqlPackage para exportar la base de datos a un
.bacpacarchivo. Consulte Exportación de una base de datos con SqlPackage para obtener más información. - Almacene el
.bacpacarchivo en una ubicación segura que se encuentra en una región diferente de la base de datos. Algunos ejemplos incluyen almacenar el archivo.bacpacen una instancia de Lakehouse que se encuentra en otra región, usar una cuenta de Azure Storage con redundancia geográfica o utilizar otro medio de almacenamiento seguro que se encuentre en una región diferente. - Si la base de datos SQL y la región no están disponibles, puede usar el
.bacpacarchivo con SqlPackage para volver a crear la base de datos en un área de trabajo en una nueva región: área de trabajo C2. W2 en la región B, tal como se describe en el escenario anterior. Siga los pasos que se detallan en Importación de una base de datos con SqlPackage para volver a crear la base de datos con el.bacpacarchivo.
La base de datos recreada es una base de datos independiente de la base de datos original y refleja el estado de los datos en el momento de la operación de exportación.
Consideraciones de retorno después de una conmutación
La base de datos recreada es una base de datos independiente. Los datos agregados a la base de datos recreada no se reflejarán en la base de datos original. Si planea conmutar a la base de datos original cuando la región principal esté disponible, deberá considerar reconciliar manualmente los datos de la base de datos recreada con la base de datos original.
Platform
La plataforma hace referencia a los servicios compartidos y la arquitectura subyacentes que se aplican a todas las cargas de trabajo. Esta sección le guía por los procedimientos de recuperación para experiencias compartidas. Cubre las bibliotecas de variables.
Biblioteca de variables
Microsoft Fabric bibliotecas de variables permiten a los desarrolladores personalizar y compartir configuraciones de elementos dentro de un área de trabajo, lo que simplifica la administración del ciclo de vida del contenido. Desde el punto de vista de la recuperación ante desastres, los usuarios de la biblioteca de variables deben protegerse proactivamente frente a un desastre regional. Esto se puede hacer a través de la integración de Git de Fabric, lo que garantiza que, después de un desastre regional, la biblioteca de variables de un usuario permanezca disponible. Para recuperar una biblioteca de variables, se recomienda lo siguiente:
Utiliza la integración de Git de Fabric para sincronizar la biblioteca de variables con el repositorio de ADO. En caso de desastre, puede usar el repositorio para volver a generar la biblioteca de variables en el nuevo área de trabajo que ha creado. Siga estos pasos:
- Conecte el área de trabajo al repositorio de Git como se describe aquí.
- Asegúrese de mantener el WS y el repositorio sincronizados con confirmación y actualización.
- Recuperación: en caso de desastre, use el repositorio para volver a generar la biblioteca de variables en una nueva área de trabajo:
En el área de trabajo recién creada, conéctese y sincronice con el repositorio de ADO de Azure de nuevo.
Todos los elementos Fabric de este repositorio se descargan automáticamente en el nuevo área de trabajo.
Después de sincronizar los elementos desde Git, abra las bibliotecas de variables en el nuevo área de trabajo y seleccione manualmente el conjunto de valores activos deseado.
Claves administradas por el cliente para áreas de trabajo de Fabric
Puede usar claves administradas por el cliente (CMK) almacenadas en Azure Key Vault para agregar una capa adicional de cifrado sobre las claves administradas por Microsoft para los datos en reposo. En caso de que Fabric sea inaccesible o inoperable en una región, sus componentes pasarán automáticamente a una instancia de copia de seguridad. Durante la conmutación por error, la característica CMK admite operaciones de solo lectura. Siempre que el servicio de Azure Key Vault esté en buen estado y los permisos de la bóveda estén intactos, Fabric seguirá conectándose a su clave y le permitirá leer datos con normalidad. Esto significa que no se admiten las siguientes operaciones durante la conmutación por error: habilitar y deshabilitar la configuración de CMK del área de trabajo y actualizar la clave.