Opciones de continuidad empresarial y recuperación ante desastres para FSLogix
Nota:
Todos los diagramas son ejemplos basados en Azure Virtual Desktop y son aplicables a otras plataformas de escritorio virtual.
Un plan eficaz de continuidad empresarial y recuperación ante desastres (BCDR) se centra en los procesos y recursos necesarios para que una organización funcione si una catástrofe u otra interrupción significativa. Los perfiles de usuario móviles no se describen normalmente como un componente empresarial o crítico de una estrategia bcDR . En un entorno de escritorio virtual, un usuario no es consciente de que tiene un perfil de itinerancia. El perfil está móvil para proporcionar a los usuarios una experiencia coherente independientemente de la máquina virtual. Los datos empresariales o críticos no deben almacenarse en el perfil de un usuario si es posible. El uso de OneDrive, SharePoint u otras soluciones es un medio eficaz para proteger los datos durante un evento BCDR , sin depender de la itinerancia de datos con el usuario como parte de su perfil. Este proceso se describe mejor en un ejercicio de objetivo de tiempo de recuperación (RTO) y objetivo de punto de recuperación (RPO) en el que se puede ponderar la ventaja de costos y el análisis de riesgos en función de los objetivos empresariales y de la organización.
Opción 1: Sin recuperación de perfiles
Aunque esta opción no parece un diseño de BCDR , se centra en garantizar que los datos empresariales y críticos no estén en el perfil del usuario. Durante un desastre, los usuarios crearían nuevos perfiles en una nueva ubicación o en un nuevo proveedor de almacenamiento (ambos pueden ser true). Esta opción es la más rentable en términos de costo de infraestructura, aunque tiene una penalización debido al efecto que puede tener en la experiencia del usuario.
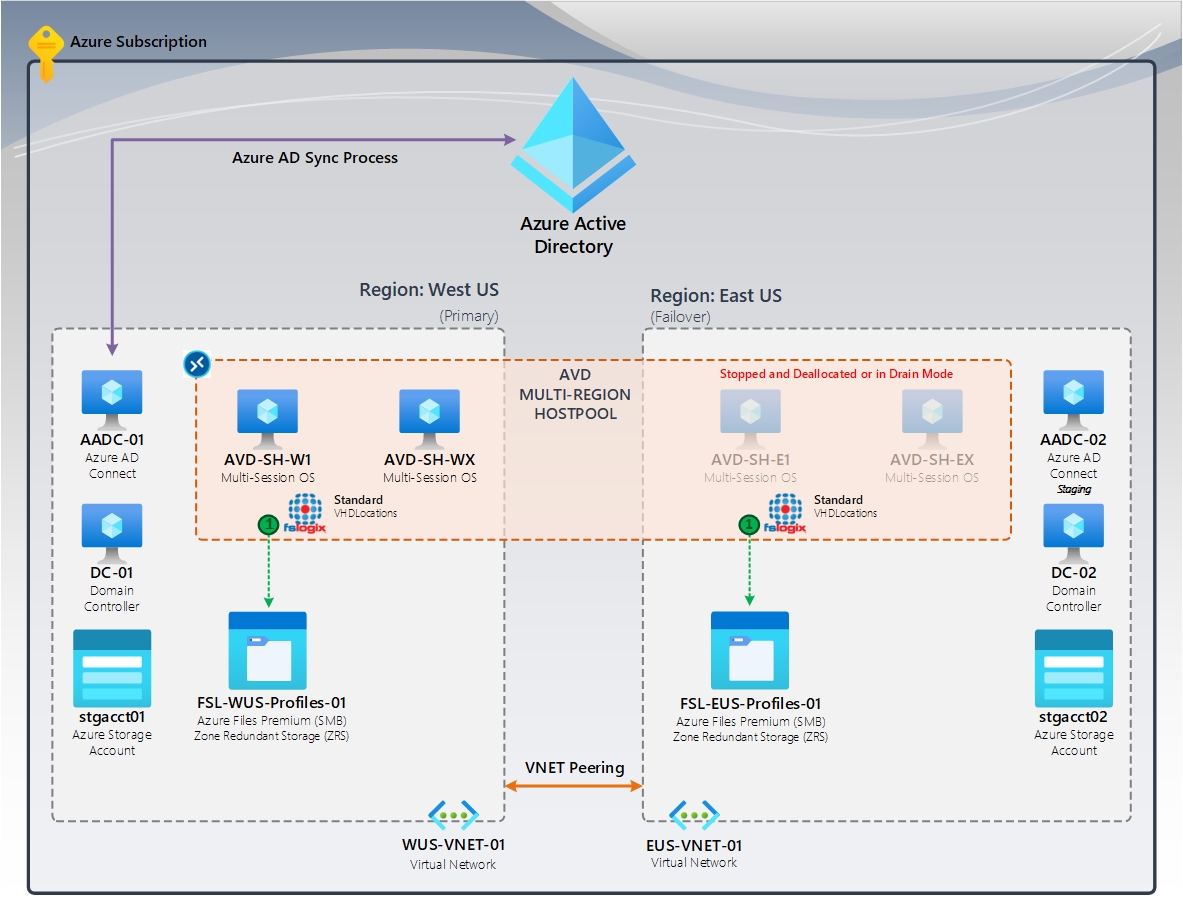
Figura 1: Sin recuperación de perfiles | Contenedores estándar de FSLogix (VHDLocations)
En el diagrama, es un grupo de hosts de varias regiones mediante Azure Virtual Desktop. Tanto las regiones de conmutación por error como las principales tienen un recurso compartido de Azure Files dedicado mediante el almacenamiento con redundancia de zona (ZRS), que proporciona alta disponibilidad dentro de la región. La región de conmutación por error tiene hosts de sesión, que se detienen o desasignan. En caso de desastre, la región de conmutación por error se convierte en la región primaria y los usuarios iniciarán sesión en esos hosts de sesión y crearán nuevos perfiles en el recurso compartido de Azure Files en esa región.
Opción 2: Caché en la nube (principal o conmutación por error)
- Revisión:Introducción a la caché en la nube
- Ejemplo:Avanzado + Recuperación ante desastres (principal o conmutación por error)
Un diseño de conmutación por error es una estrategia común para garantizar la disponibilidad y confiabilidad de la infraestructura en caso de desastre o error. Cloud Cache permite usar FSLogix mediante este tipo de diseño de conmutación por error. Con La caché en la nube, puede configurar los dispositivos para que usen dos (2) proveedores de almacenamiento que almacenen los datos de perfil en diferentes ubicaciones. Cloud Cache sincroniza los datos de perfil con cada uno de los dos proveedores de almacenamiento de forma asincrónica, por lo que siempre tiene la versión más reciente de los datos. Algunos de los dispositivos están en la ubicación principal y los otros dispositivos están en la ubicación de conmutación por error. Cloud Cache prioriza el primer proveedor de almacenamiento (más cercano al dispositivo) y usa el otro proveedor de almacenamiento como copia de seguridad. Por ejemplo, si el dispositivo principal está en Oeste de EE. UU. y el dispositivo de conmutación por error está en Este de EE. UU., puede configurar La caché en la nube de la siguiente manera:
- El dispositivo principal usa un proveedor de almacenamiento en Oeste de EE. UU. como la primera opción y un proveedor de almacenamiento en Este de EE. UU. como segunda opción.
- El dispositivo de conmutación por error usa un proveedor de almacenamiento en Este de EE. UU. como la primera opción y un proveedor de almacenamiento en Oeste de EE. UU. como segunda opción.
- Si se produce un error en el dispositivo principal o el proveedor de almacenamiento más cercano, puede cambiar al dispositivo de conmutación por error o al proveedor de almacenamiento de copia de seguridad y continuar el trabajo sin perder los datos del perfil.
Sin embargo, hay algunas desventajas de usar un diseño de conmutación por error con Caché en la nube. En primer lugar, tiene que pagar más por almacenar los datos del perfil en dos (2) ubicaciones. En segundo lugar, debe iniciar manualmente el proceso de conmutación por error, lo que puede requerir la aprobación de las partes interesadas de la empresa. En tercer lugar, puede experimentar cierta latencia o incoherencia en los datos del perfil debido a la sincronización asincrónica con los dos proveedores de almacenamiento.
Sugerencia
- Antes de permitir que los usuarios conmuten por recuperación a perfiles en la ubicación principal, asegúrese de que todos los usuarios han cerrado sesión correctamente desde la ubicación de conmutación por error para asegurarse de que la ubicación principal tiene una réplica actualizada de los datos del perfil del usuario.
- La caché en la nube es un sistema intensivo de E/S y puede provocar fácilmente cuellos de botella de red o almacenamiento en la ubicación restaurada.
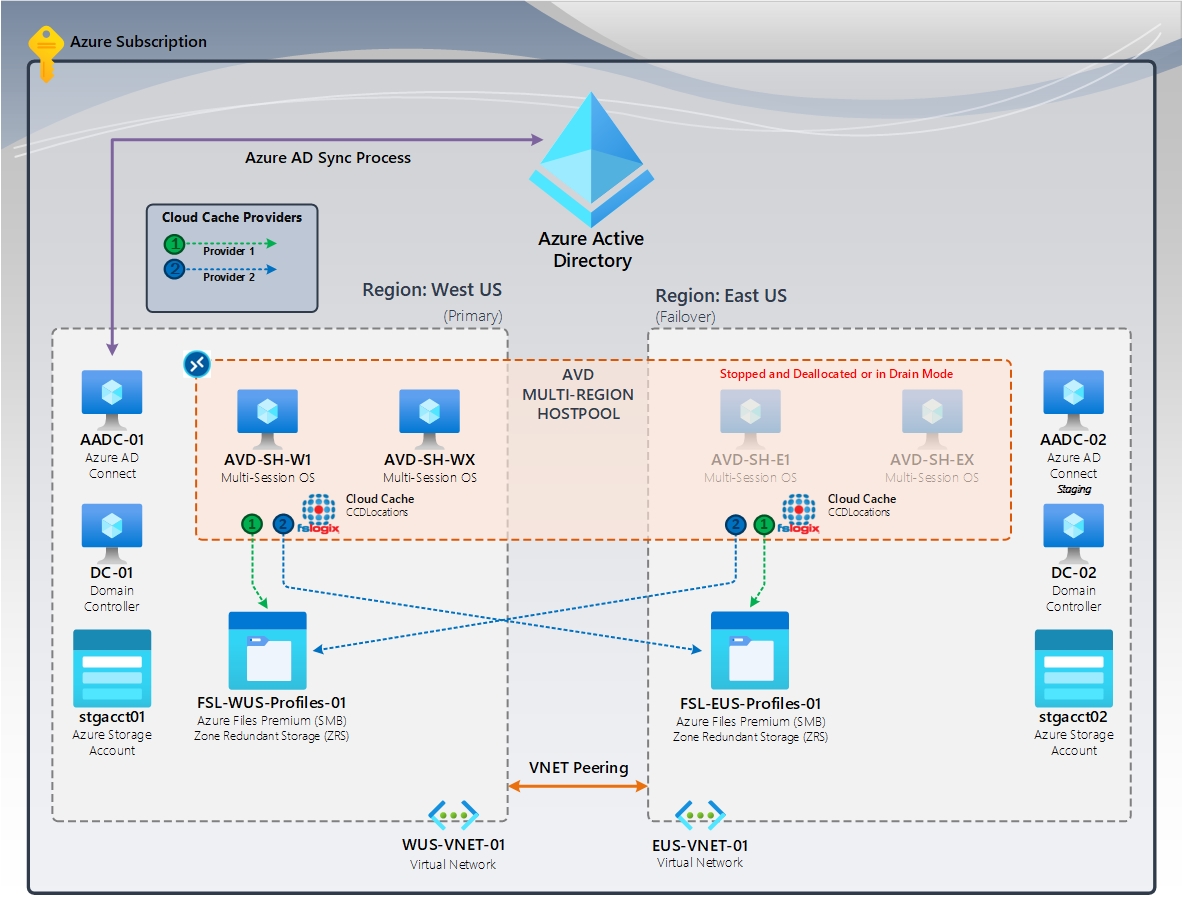
Figura 2: Caché en la nube (principal o conmutación por error) | FSLogix Cloud Cache (CCDLocations)
En el diagrama, tenemos un grupo de hosts de varias regiones mediante Azure Virtual Desktop. Las regiones principal y de conmutación por error forman parte de esta configuración. Cada uno tiene un recurso compartido de Azure Files dedicado mediante el almacenamiento con redundancia de zona (ZRS), lo que garantiza una alta disponibilidad dentro de la región. La región de conmutación por error contiene hosts de sesión, que se detienen o desasignan. En caso de desastre, la región de conmutación por error se convierte en la región primaria. Los usuarios iniciarán sesión en estos hosts de sesión y cargarán su perfil replicado desde la región de conmutación por error.
Sin embargo, es esencial tener en cuenta lo siguiente:
- Los eventos bcDR (continuidad empresarial y recuperación ante desastres) rara vez son correctos. En función de las circunstancias, es posible que los datos del perfil de usuario no estén intactos.
- Los usuarios que inician sesión en hosts de sesión en la región de conmutación por error podrían experimentar pérdida de datos o, en casos peores, daños en el contenedor.
Dada esta situación, es fundamental usar plataformas de almacenamiento como OneDrive o SharePoint para datos críticos. Estas plataformas proporcionan redundancia adicional y protección contra la pérdida de datos. Recuerde que el planeamiento de la recuperación ante desastres es esencial y tener la estrategia de almacenamiento adecuada puede mitigar los riesgos y garantizar la continuidad empresarial.
Opción 3: Caché en la nube (activa/activa)
- Revisión:Introducción a la caché en la nube
- Ejemplo:Avanzado + Recuperación ante desastres (principal o conmutación por error)
Al analizar la infraestructura, es habitual usar diseños activos o activos, que también se pueden aplicar a una solución de perfil de FSLogix. Con esta opción, Cloud Cache se configura con dos proveedores de almacenamiento que se actualizan de forma asincrónica para reflejar todos los cambios realizados en la memoria caché local. El proveedor de almacenamiento más cercano a la ubicación activa aparece primero, mientras que el proveedor más lejano aparece en segundo lugar. En la otra ubicación, se invierte el orden. Esta opción conlleva costos adicionales para almacenar datos del proveedor en dos ubicaciones y requiere una decisión manual por parte de las partes interesadas empresariales antes de iniciar una conmutación por error.
Sugerencia
- Cuando la región con error está operativa, los datos del perfil pueden tardar mucho tiempo en replicarse por completo.
- La caché en la nube es un sistema intensivo de E/S y puede provocar fácilmente cuellos de botella de red o almacenamiento en la ubicación restaurada.
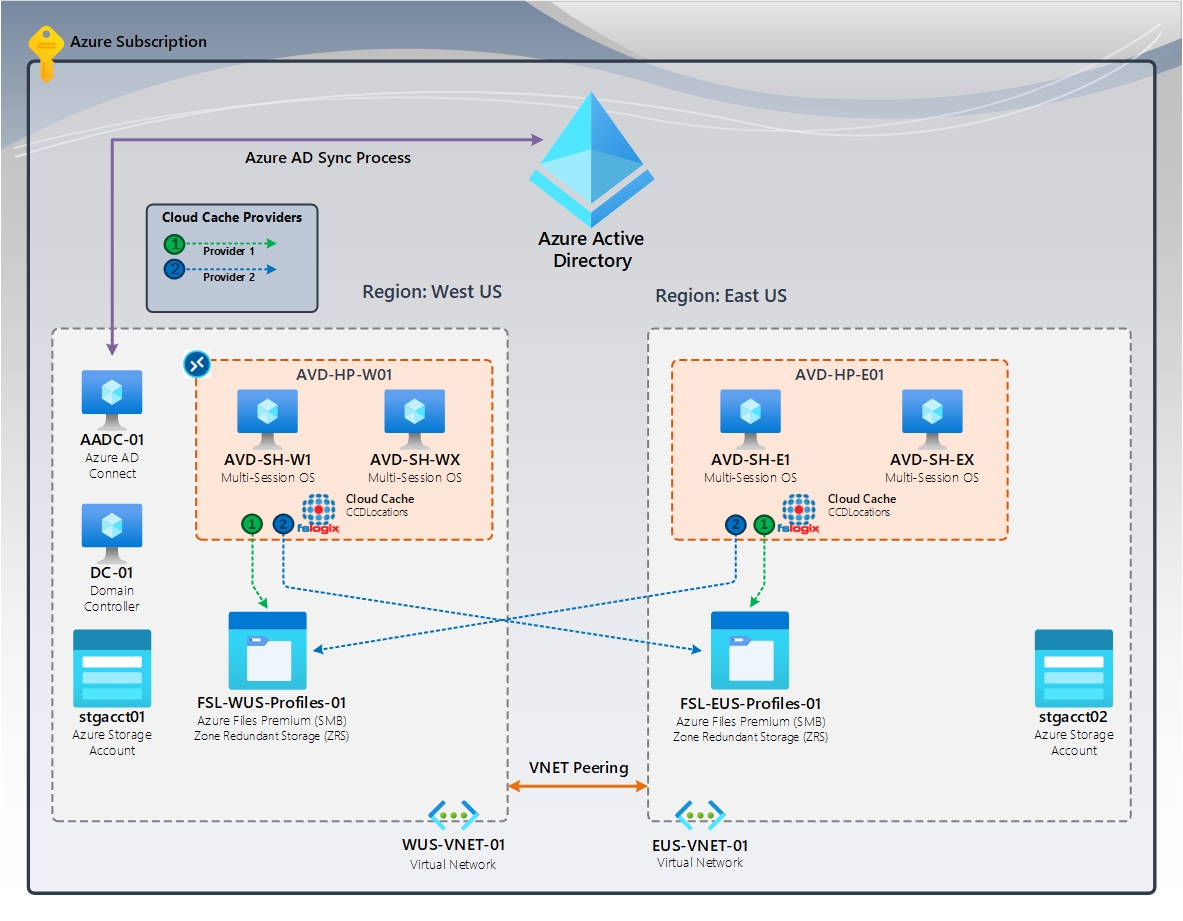
Figura 3: Caché en la nube (activa/activa) | FSLogix Cloud Cache (CCDLocations)
En el diagrama, son dos (2) grupos de hosts de AVD y hosts de sesión que residen en regiones de Azure específicas. Los usuarios asignados a la región Oeste de EE. UU., acceden a esas máquinas virtuales. Los usuarios de la región Este de EE. UU. solo tienen acceso y se asignan a esas máquinas virtuales. Durante un desastre, la región de supervivencia debe tener suficiente capacidad para admitir a todos los usuarios. Además, los usuarios de la región con errores necesitan tener acceso concedido a las máquinas virtuales de la región de supervivencia.
Los eventos bcDR nunca son correctos y, en función de las circunstancias del evento, no se garantiza que los datos del perfil de usuario estén intactos. Los usuarios que inician sesión en hosts de sesión en la región de supervivencia podrían experimentar pérdida de datos o daños en contenedores peores. Esta situación amplía la necesidad de usar plataformas de almacenamiento como OneDrive o SharePoint para datos críticos del usuario.