Patrón de clúster de Kubernetes de alta disponibilidad
En este artículo se describe cómo diseñar y usar una infraestructura de alta disponibilidad basada en Kubernetes con el motor de Azure Kubernetes Service (AKS) en Azure Stack Hub. Este escenario es común para las organizaciones con cargas de trabajo críticas en entornos regulados y muy restringidos. Organizaciones de dominios como finanzas, defensa y gobierno.
Contexto y problema
Muchas organizaciones desarrollan soluciones nativas de la nube que aprovechan los servicios y tecnologías de vanguardia como Kubernetes. Aunque Azure proporciona centros de datos en la mayoría de las regiones del mundo, a veces hay casos de uso y escenarios excepcionales en los que las aplicaciones críticas para la empresa deben ejecutarse en una ubicación específica. Entre las consideraciones se incluyen las siguientes:
- Distinción de ubicación
- Latencia entre la aplicación y los sistemas locales
- Conservación del ancho de banda
- Conectividad
- Requisitos normativos o legales
Azure, en combinación con Azure Stack Hub, aborda la mayoría de estos problemas. A continuación se describe un amplio conjunto de opciones, decisiones y consideraciones a tener en cuenta para una implementación correcta de Kubernetes que se ejecute en Azure Stack Hub.
Solución
En este patrón se supone que tenemos que tratar con un conjunto estricto de restricciones. La aplicación debe ejecutarse de forma local y ningún dato personal debe llegar a los servicios en la nube pública. Los datos de supervisión y aquellos otros que no constituyan información de identificación personal se pueden enviar a Azure para su procesamiento. Se puede acceder a servicios externos como, por ejemplo, a una instancia de Container Registry pública o a otros, pero tendrían que filtrarse mediante un servidor proxy o firewall.
La aplicación de ejemplo que se muestra aquí está diseñada para usar soluciones nativas de Kubernetes siempre que sea posible. Este diseño evita la dependencia del proveedor, en lugar de usar servicios nativos de la plataforma. Por ejemplo, la aplicación usa un back-end de base de datos de MongoDB autohospedado en lugar de un servicio PaaS o un servicio externo de bases de datos. Para más información, consulte Introducción a Kubernetes en la ruta de aprendizaje de Azure.

En el diagrama anterior se muestra la arquitectura de la aplicación de ejemplo que se ejecuta en Kubernetes en Azure Stack Hub. La aplicación consta de varios componentes, entre los que se incluyen:
- Un clúster de Kubernetes basado en el motor de AKS en Azure Stack Hub.
- cert-manager, que proporciona un conjunto de herramientas para la administración de certificados en Kubernetes y que se usa para solicitar automáticamente los certificados de Let's Encrypt.
- Un espacio de nombres de Kubernetes que contiene los componentes de la aplicación para el front-end (ratings-web), la API (ratings-api) y la base de datos (ratings-mongodb).
- El controlador de entrada que enruta el tráfico HTTP/HTTPS a los puntos de conexión del clúster de Kubernetes.
Se usa la aplicación de ejemplo para mostrar la arquitectura de la aplicación. Todos los componentes son ejemplos. La arquitectura contiene solo la implementación de una única aplicación. Para lograr una alta disponibilidad, se ejecutará la implementación al menos dos veces en dos instancias diferentes de Azure Stack Hub: pueden ejecutarse en la misma ubicación o en dos (o más) sitios diferentes:

Los servicios como Azure Container Registry, Azure Monitor y otros, se hospedan fuera de Azure Stack Hub en Azure o en el entorno local. Este diseño híbrido protege la solución frente a posibles interrupciones de una sola instancia de Azure Stack Hub.
Componentes
Esta arquitectura global consta de los siguientes componentes:
Azure Stack Hub es una extensión de Azure que puede ejecutar cargas de trabajo en un entorno local y proporcionar servicios de Azure en su centro de datos. Vaya a Introducción a Azure Stack Hub para más información.
Motor de Azure Kubernetes Service (motor de AKS) es el motor que está detrás de la oferta de servicio de Kubernetes administrado, Azure Kubernetes Service (AKS), que está disponible en Azure en la actualidad. En el caso de Azure Stack Hub, el motor de AKS nos permite implementar, escalar y actualizar clústeres de Kubernetes autoadministrados y con todas las características mediante las funcionalidades de IaaS de Azure Stack Hub. Vaya a Introducción al motor de AKS para más información.
Vaya a Problemas y limitaciones conocidos para más información sobre las diferencias entre el motor de AKS en Azure y el motor de AKS en Azure Stack Hub.
Azure Virtual Network (VNet) se usa para proporcionar la infraestructura de red en cada instancia de Azure Stack Hub para las máquinas virtuales que hospedan la infraestructura de clústeres de Kubernetes.
Azure Load Balancer se usa para el punto de conexión de API de Kubernetes y el controlador de entrada Nginx. El equilibrador de carga enruta el tráfico externo (por ejemplo, Internet) hacia los nodos y máquinas virtuales que ofrecen un servicio específico.
Azure Container Registry (ACR) se usa para almacenar imágenes privadas de Docker y charts de Helm, los cuales están implementados en el clúster. El motor de AKS se puede autenticar con Container Registry mediante una identidad de Azure AD. Kubernetes no requiere ACR. Puede usar otros registros de contenedor, como Docker Hub.
Azure Repos es un conjunto de herramientas de control de versiones que se puede usar para administrar el código. También puede usar GitHub u otros repositorios basados en Git. Vaya a Introducción a Azure Repos para más información.
Azure Pipelines forma parte de Azure DevOps Services y ejecuta compilaciones, pruebas e implementaciones automatizadas. También puede usar soluciones de CI/CD de terceros como Jenkins. Vaya a Introducción a Azure Pipeline para más información.
Azure Monitor recopila y almacena métricas y registros, como las métricas de la plataforma de los servicios de Azure de la solución y los datos de telemetría de la aplicación. Use estos datos para supervisar la aplicación, configurar alertas y paneles y realizar el análisis de causa principal de los errores. Azure Monitor se integra con Kubernetes para recopilar métricas de controladores, nodos y contenedores, así como los registros de contenedor y los registros del nodo maestro. Vaya a Introducción a Azure Monitor para más información.
Azure Traffic Manager es un equilibrador de carga de tráfico basado en DNS que le permite distribuir el tráfico de forma óptima a servicios de diferentes regiones de Azure o implementaciones de Azure Stack Hub. Traffic Manager también proporciona alta disponibilidad y capacidad de respuesta. Los puntos de conexión de la aplicación deben ser accesibles desde el exterior. También hay otras soluciones locales disponibles.
El controlador de entrada Kubernetes expone rutas HTTP(S) a los servicios de un clúster de Kubernetes. Para este fin se puede usar Nginx o cualquier controlador de entrada adecuado.
Helm es un administrador de paquetes para la implementación de Kubernetes que ofrece una manera de agrupar diferentes objetos de Kubernetes, como implementaciones, servicios y secretos, en un solo "chart". Puede publicar, implementar, controlar la administración de versiones y actualizar un objeto de chart. Azure Container Registry puede usarse como repositorio para almacenar charts de Helm empaquetados.
Consideraciones de diseño
Este patrón sigue algunas consideraciones de alto nivel que se explican con más detalle en las secciones siguientes de este artículo:
- La aplicación usa soluciones nativas de Kubernetes para evitar la dependencia del proveedor.
- La aplicación usa una arquitectura de microservicios.
- Azure Stack Hub no necesita conectividad de entrada, pero permite la conectividad saliente de Internet.
Estos procedimientos recomendados serán aplicables también a cargas de trabajo y escenarios reales.
Consideraciones sobre escalabilidad
La escalabilidad es importante para proporcionar a los usuarios acceso coherente, confiable y con un buen rendimiento a la aplicación.
El escenario de ejemplo cubre la escalabilidad en varios niveles de la pila de aplicaciones. A continuación se muestra una descripción detallada de los distintos niveles:
| Nivel de arquitectura | Afecta a | ¿Cómo lo hago? |
|---|---|---|
| Application | Application | Escalado horizontal basado en el número de pods/réplicas/instancias de contenedor* |
| Clúster | Clúster de Kubernetes | Número de nodos (entre 1 y 50), tamaños de SKU de máquinas virtuales y grupos de nodos (el motor de AKS en Azure Stack Hub solo admite un único grupo de nodos); mediante el comando de escalado del motor de AKS (manual) |
| Infraestructura | Azure Stack Hub | Número de nodos, capacidad y unidades de escalado en una implementación de Azure Stack Hub |
* Mediante Horizontal Pod Autoscaler de Kubernetes, el escalado automático basado en métricas o el escalado vertical con ajuste de tamaño de las instancias de contenedor (cpu/memoria).
Azure Stack Hub (nivel de infraestructura)
La infraestructura de Azure Stack Hub es la base de esta implementación, ya que Azure Stack Hub se ejecuta en hardware físico de un centro de datos. Al seleccionar el hardware para la instancia de Azure Stack Hub, debe tomar decisiones sobre la CPU, la densidad de memoria, la configuración de almacenamiento y el número de servidores. Para más información sobre la escalabilidad de Azure Stack Hub, consulte los siguientes recursos:
- Introducción al planeamiento de capacidad de Azure Stack Hub
- Incorporación de nodos de la unidad de escalado adicionales en Azure Stack Hub
Clúster de Kubernetes (nivel de clúster)
El propio clúster de Kubernetes consta de componentes de IaaS de Azure (Stack) y se basa en estos. Entre ellos cabe incluir recursos de proceso, almacenamiento y red. Las soluciones de Kubernetes incluyen nodos maestros y de trabajo que se implementan como máquinas virtuales en Azure (y Azure Stack Hub).
- Los nodos del plano de control (maestro) proporcionan los servicios centrales de Kubernetes y la orquestación de las cargas de trabajo de las aplicaciones.
- Los nodos de trabajo (trabajo) ejecutan las cargas de trabajo de la aplicación.
Al seleccionar los tamaños de máquina virtual para la implementación inicial, hay varias consideraciones que se deben tener en cuenta:
Costo: al planear los nodos de trabajo, tenga en cuenta el costo total por máquina virtual que tendrá. Por ejemplo, si las cargas de trabajo de la aplicación requieren recursos limitados, debe planear la implementación de máquinas virtuales de menor tamaño. Azure Stack Hub, al igual que Azure, se factura normalmente por consumo, por lo que el ajuste adecuado del tamaño de las máquinas virtuales para los roles de Kubernetes es fundamental para optimizar los costos de consumo.
Escalabilidad: la escalabilidad del clúster se consigue mediante el escalado y reducción horizontal del número de nodos maestros y de trabajo, o mediante la adición de grupos de nodos adicionales (no disponibles en Azure Stack Hub actualmente). El escalado del clúster se puede realizar según los datos de rendimiento recopilados mediante Container Insights (Azure Monitor + Log Analytics).
Si su aplicación necesita más (o menos) recursos, puede escalar (o reducir) horizontalmente los nodos actuales (entre 1 y 50 nodos). Si necesita más de 50 nodos, puede crear un clúster adicional en una suscripción independiente. No se pueden escalar verticalmente las máquinas virtuales reales a otro tamaño de máquina virtual sin volver a implementar el clúster.
El escalado se realiza manualmente con la máquina virtual auxiliar del motor de AKS que se usó para implementar el clúster de Kubernetes inicialmente. Para más información, consulte Escalado de clústeres de Kubernetes.
Cuotas: tenga en cuenta las cuotas que ha configurado al planear una implementación de AKS en la instancia de Azure Stack Hub. Asegúrese de que cada suscripción tenga los planes adecuados y las cuotas configuradas. La suscripción deberá acomodar la cantidad de proceso, almacenamiento y otros servicios necesarios para los clústeres a medida que estos se escalan horizontalmente.
Cargas de trabajo de aplicaciones: consulte los conceptos de clústeres y cargas de trabajo en el documento sobre conceptos básicos de Kubernetes para Azure Kubernetes Service. Este artículo le ayudará a limitar el tamaño adecuado de la máquina virtual en función de las necesidades de proceso y memoria de la aplicación.
Aplicación (nivel de aplicación)
En el nivel de aplicación, se usa Horizontal Pod Autoscaler (HPA) de Kubernetes. HPA puede aumentar o disminuir el número de réplicas (pods o instancias de contenedor) en nuestra implementación en función de métricas diferentes (como el uso de CPU).
Otra opción consiste en escalar las instancias de contenedor verticalmente. Esto se puede lograr cambiando la cantidad de CPU y memoria solicitada y disponible para una implementación específica. Consulte Administración de recursos de Containers en kubernetes.io para más información.
Aspectos sobre redes y conectividad
Las redes y la conectividad también afectan a los tres niveles mencionados anteriormente para Kubernetes en Azure Stack Hub. En la tabla siguiente se muestran los niveles y los servicios que contienen:
| Nivel | Afecta a | ¿Qué? |
|---|---|---|
| Application | Application | ¿Cómo se puede acceder a la aplicación? ¿Se expondrá a Internet? |
| Clúster | Clúster de Kubernetes | API de Kubernetes, máquina virtual del motor de AKS, extracción de imágenes de contenedor (salida), envío de datos de supervisión y de telemetría (salida) |
| Infraestructura | Azure Stack Hub | Accesibilidad de los puntos de conexión de administración de Azure Stack Hub como los del portal y los de Azure Resource Manager. |
Aplicación
En el nivel de la aplicación, el aspecto más importante es si la aplicación está expuesta y es accesible desde Internet. Desde una perspectiva de Kubernetes, accesibilidad a Internet significa exponer una implementación o pod mediante un servicio de Kubernetes o un controlador de entrada.
La exposición de una aplicación mediante una dirección IP pública a través de una instancia de Load Balancer o un controlador de entrada no significa necesariamente que la aplicación sea ahora accesible a través de Internet. Es posible que Azure Stack Hub tenga una dirección IP pública que solo sea visible en la Intranet local, no todas las IP públicas son realmente accesibles desde Internet.
El bloque anterior tiene en cuenta el tráfico de entrada a la aplicación. Otro tema que debe tenerse en cuenta para una implementación correcta de Kubernetes es el tráfico de salida. Estos son algunos casos de uso que requieren tráfico de salida:
- Extracción de imágenes de contenedor almacenadas en DockerHub o Azure Container Registry
- Recuperación de charts de Helm
- Emisión de datos de Application Insights (u otros datos de supervisión)
Algunos entornos empresariales pueden requerir el uso de servidores proxy transparentes o no transparentes. Estos servidores requieren una configuración específica en varios componentes de nuestro clúster. La documentación del motor de AKS contiene varios detalles sobre cómo acomodar los proxies de red. Para más información, consulte Motor de AKS y servidores proxy
Por último, el tráfico entre clústeres debe fluir entre las instancias de Azure Stack Hub. La implementación de ejemplo consta de clústeres individuales de Kubernetes que se ejecutan en instancias individuales de Azure Stack Hub. El tráfico entre ellas, al igual que el tráfico de replicación entre dos bases de datos, es "tráfico externo". El tráfico externo se debe enrutar a través de una VPN de sitio a sitio o de direcciones IP públicas de Azure Stack Hub para conectar Kubernetes en dos instancias de Azure Stack Hub:
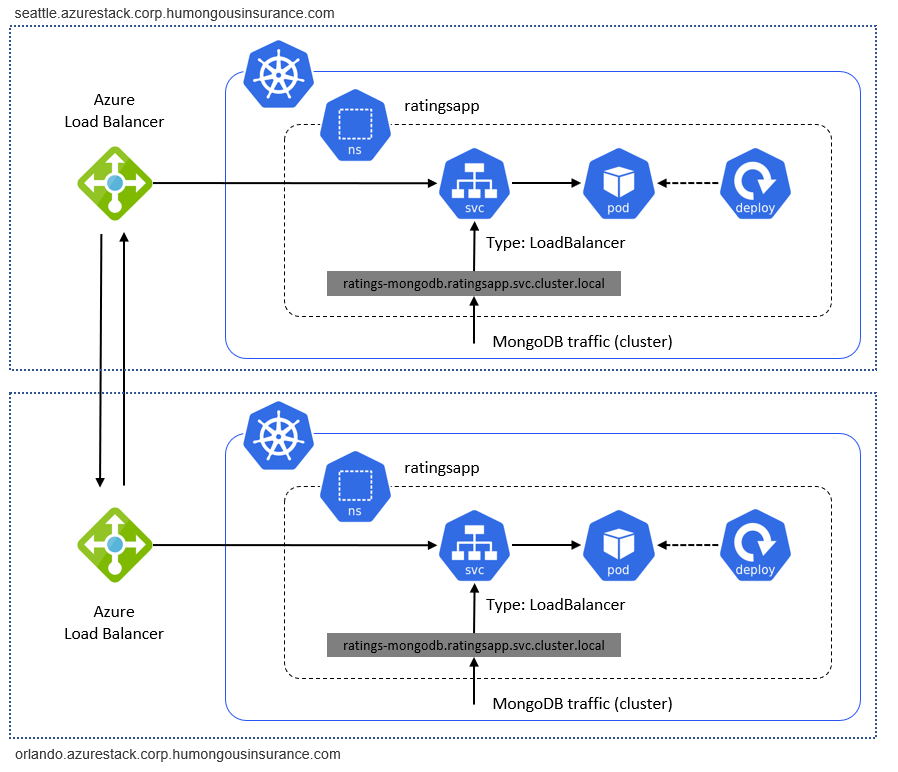
Clúster
No es necesario que el clúster de Kubernetes sea accesible a través de Internet. La parte importante es la API de Kubernetes que se usa para trabajar con un clúster, por ejemplo, mediante kubectl. El punto de conexión de la API de Kubernetes debe ser accesible para todos los usuarios que trabajan con el clúster o que implementan aplicaciones y servicios en él. Este tema se trata con más detalle desde una perspectiva de DevOps en la sección Consideraciones de implementación (CI/CD) que aparece a continuación.
En el nivel de clúster, existen también algunas consideraciones que se deben tener en cuenta sobre el tráfico de salida:
- Actualizaciones de nodos (para Ubuntu)
- Datos de supervisión (que se envían a Azure LogAnalytics)
- Otros agentes que requieren tráfico de salida (específico del entorno de cada implementador)
Antes de implementar el clúster de Kubernetes mediante el motor de AKS, planee el diseño de red final. En lugar de crear una red virtual dedicada, puede que sea más eficaz implementar un clúster en una red ya existente. Por ejemplo, puede aprovechar una conexión VPN de sitio a sitio existente ya configurada en el entorno de Azure Stack Hub.
Infraestructura
La infraestructura hace referencia al acceso a los puntos de conexión de administración de Azure Stack Hub. Los puntos de conexión incluyen los portales de administración y de inquilino, así como los puntos de conexión de administrador y de inquilino de Azure Resource Manager. Estos puntos de conexión son necesarios para trabajar con Azure Stack Hub y sus servicios principales.
Consideraciones a tener en cuenta sobre datos y almacenamiento
Se implementarán dos instancias de la aplicación, en dos clústeres de Kubernetes individuales, en dos instancias de Azure Stack Hub. En este diseño es necesario tener en cuenta cómo replicar y sincronizar los datos entre ellas.
Con Azure, disponemos de la funcionalidad integrada para replicar el almacenamiento en varias regiones y zonas dentro de la nube. Actualmente, con Azure Stack Hub, no hay formas nativas de replicar el almacenamiento en dos instancias diferentes de Azure Stack Hub: forman dos nubes independientes sin ninguna manera de administrarlas como un conjunto. La planeación de la resistencia de las aplicaciones que se ejecutan en Azure Stack Hub obliga a tener en cuenta esta independencia en el diseño y las implementaciones de la aplicación.
En la mayoría de los casos, la replicación del almacenamiento no será necesaria para una aplicación resistente y de alta disponibilidad implementada en AKS. Pero debe tener en cuenta el almacenamiento independiente por instancia de Azure Stack Hub en el diseño de la aplicación. Si este diseño es un problema o un obstáculo para implementar la solución en Azure Stack Hub, existen soluciones de asociados que proporcionan soluciones auxiliares de almacenamiento. Estas ofrecen una solución de replicación de almacenamiento en varias instancias de Azure Stack Hub y Azure. Para más información, consulte Soluciones de asociados.
En nuestra arquitectura, se tuvieron en cuenta estos niveles:
Configuración
La configuración incluye la configuración de Azure Stack Hub, el motor de AKS y el propio clúster de Kubernetes. La configuración se debe automatizar tanto como sea posible y almacenarse como infraestructura como código en un sistema de control de versiones basado en Git como Azure DevOps o GitHub. Esta configuración no se puede sincronizar fácilmente en varias implementaciones. Por lo tanto, se recomienda almacenar y aplicar la configuración desde fuera y mediante la canalización de DevOps.
Aplicación
La aplicación debe almacenarse en un repositorio basado en Git. Siempre que haya una nueva implementación, cambios en la aplicación o recuperación ante desastres, se puede implementar fácilmente mediante Azure Pipelines.
Datos
Los datos son el aspecto más importante en la mayoría de los diseños de aplicaciones. Los datos de la aplicación deben permanecer sincronizados entre las distintas instancias de esta. Los datos también necesitan una estrategia de copia de seguridad y recuperación ante desastres en caso de que se produzca una interrupción.
Lograr este diseño depende en gran medida de las opciones de tecnología. Estos son algunos ejemplos de soluciones para implementar una base de datos con alta disponibilidad en Azure Stack Hub:
- Implementar un grupo de disponibilidad de SQL Server 2016 en Azure y Azure Stack Hub
- Implementar una solución MongoDB de alta disponibilidad en Azure y Azure Stack Hub
Las consideraciones que se deben tener en cuenta al trabajar con datos en varias ubicaciones es un aspecto aún más complejo a la hora de conseguir una solución resistente y de alta disponibilidad. Tenga en cuenta lo siguiente:
- Latencia y conectividad de red entre instancias de Azure Stack Hub.
- Disponibilidad de identidades para los servicios y permisos. Cada instancia de Azure Stack Hub se integra con un directorio externo. Durante la implementación puede elegir entre usar Azure Active Directory (Azure AD) o los Servicios de federación de Active Directory (AD FS). Como tal, existe la posibilidad de usar una única identidad que pueda interactuar con varias instancias independientes de Azure Stack Hub.
Continuidad empresarial y recuperación ante desastres
La continuidad empresarial y la recuperación ante desastres (BCDR) son un tema importante en Azure Stack Hub y en Azure. La diferencia principal es que en Azure Stack Hub, el operador debe administrar todo el proceso de BCDR. En Azure, determinadas partes de BCDR se administran automáticamente mediante Microsoft.
La continuidad empresarial y recuperación ante desastres afecta a las mismas áreas mencionadas en la sección anterior Consideraciones a tener en cuenta sobre datos y almacenamiento:
- Infraestructura y configuración
- Disponibilidad de la aplicación
- Datos de aplicaciones
Y como se mencionó en la sección anterior, estas áreas son responsabilidad del operador de Azure Stack Hub y pueden variar entre organizaciones. Planee el BCDR según las herramientas y procesos disponibles.
Infraestructura y configuración
En esta sección se describe la infraestructura física y lógica y la configuración de Azure Stack Hub. Incluye las acciones en los espacios de administración y de inquilino.
El operador de Azure Stack Hub (o administrador) es responsable del mantenimiento de las instancias de Azure Stack Hub. Incluye componentes como la red, el almacenamiento, la identidad y otros temas que se encuentran fuera del ámbito de este artículo. Para más información sobre los detalles de las operaciones de Azure Stack Hub, consulte los siguientes recursos:
- Recuperación de datos de Azure Stack Hub con el servicio Copia de seguridad de infraestructura
- Habilitación de la copia de seguridad de Azure Stack Hub desde el portal del administrador
- Recuperación después de una pérdida de datos grave
- Procedimientos recomendados del servicio Infrastructure Backup
Azure Stack Hub es la plataforma y el tejido sobre los que se implementarán las aplicaciones de Kubernetes. El propietario de la aplicación de Kubernetes será un usuario de Azure Stack Hub, con acceso otorgado para implementar la infraestructura de la aplicación necesaria para la solución. En este caso, la infraestructura de la aplicación significa el clúster de Kubernetes, que se implementa mediante el motor de AKS, y los servicios circundantes. Estos componentes se implementarán en Azure Stack Hub, restringidos mediante una oferta de Azure Stack Hub. Asegúrese de que la oferta aceptada por el propietario de la aplicación de Kubernetes tenga capacidad suficiente (expresada en cuotas de Azure Stack Hub) para implementar toda la solución. Tal como se recomienda en la sección anterior, la implementación de la aplicación se debe automatizar mediante canalizaciones de infraestructura como código y de implementación como Azure Pipelines para Azure DevOps.
Para más información sobre las ofertas y cuotas de Azure Stack Hub, consulte Introducción a los servicios, planes, ofertas y suscripciones de Azure Stack Hub.
Es importante guardar y almacenar de forma segura la configuración del motor de AKS, incluidas sus salidas. Estos archivos contienen información confidencial que se usa para acceder al clúster de Kubernetes, por lo que debe protegerse para impedir que se exponga a usuarios que no son administradores.
Disponibilidad de la aplicación
La aplicación no debe basarse en las copias de seguridad de una instancia implementada. Como procedimiento estándar, vuelva a implementar la aplicación por completo siguiendo los patrones de infraestructura como código. Por ejemplo, vuelva a implementar con Azure Pipelines para Azure DevOps. El procedimiento de continuidad empresarial y recuperación ante desastres debe incluir la reimplementación de la aplicación en el mismo clúster de Kubernetes o en otro diferente.
Datos de la aplicación
Los datos de la aplicación constituyen el componente fundamental para minimizar la pérdida de datos. En la sección anterior, se describen las técnicas para replicar y sincronizar datos entre dos o más instancias de la aplicación. En función de la infraestructura de la base de datos (MySQL, MongoDB, MSSQL u otras) que se use para almacenar los datos, habrá diferentes técnicas de disponibilidad y copia de seguridad de base de datos disponibles para elegir.
Las maneras recomendadas para lograr la integridad incluyen el uso de:
- Una solución de copia de seguridad nativa para la base de datos específica.
- Una solución de copia de seguridad que admite oficialmente la copia de seguridad y la recuperación del tipo de base de datos que emplea la aplicación.
Importante
No almacene los datos de copia de seguridad en la misma instancia de Azure Stack Hub en la que residen los datos de la aplicación. Una interrupción completa de la instancia de Azure Stack Hub también pondría en peligro las copias de seguridad.
Consideraciones sobre disponibilidad
La implementación de Kubernetes en Azure Stack Hub mediante el motor de AKS no es un servicio administrado. Se trata de la implementación y configuración automatizadas de un clúster de Kubernetes mediante la infraestructura como servicio de Azure. Como tal, proporciona la misma disponibilidad que la infraestructura subyacente.
La infraestructura de Azure Stack Hub ya es resistente a los errores y proporciona funcionalidades, como los conjuntos de disponibilidad, para distribuir los componentes entre varios dominios de error y de actualización. No obstante, la tecnología subyacente (clústeres de conmutación por error) puede experimentar un cierto tiempo de inactividad de las máquinas virtuales de un servidor físico si se produce un error de hardware.
Es recomendable implementar el clúster de Kubernetes de producción, así como la carga de trabajo, en dos (o más) clústeres. Estos clústeres se deben hospedar en diferentes ubicaciones o centros de datos y usar tecnologías como Azure Traffic Manager para enrutar a los usuarios en función del tiempo de respuesta del clúster o según la geografía.

Los clientes que tienen un único clúster de Kubernetes suelen conectarse a la dirección IP de servicio o al nombre DNS de una aplicación determinada. En una implementación de varios clústeres, los clientes deben conectarse a un nombre DNS de Traffic Manager que apunte a los servicios o entradas en cada clúster de Kubernetes.

Nota
Este patrón también es un procedimiento recomendado para clústeres de AKS (administrados) en Azure.
El propio clúster de Kubernetes, implementado mediante el motor de AKS, debe constar de al menos tres nodos maestros y dos nodos de trabajo.
Consideraciones que debe tener en cuenta sobre identidad y seguridad
La identidad y la seguridad son temas importantes. Especialmente si la solución abarca instancias de Azure Stack Hub independientes. Kubernetes y Azure (incluido Azure Stack Hub) tienen diferentes mecanismos de control de acceso basado en rol (RBAC):
- El control de acceso basado en rol de Azure controla el acceso a los recursos de Azure (y de Azure Stack Hub), incluida la capacidad de crear nuevos recursos de Azure. Los permisos se pueden asignar a usuarios, grupos o entidades de servicio. (Una entidad de servicio es una identidad de seguridad utilizada por las aplicaciones).
- El control de acceso basado en rol de Kubernetes controla los permisos para la API de Kubernetes. Por ejemplo, la creación de pods y la enumeración de pods son acciones que se pueden autorizar (o denegar) a un usuario mediante RBAC. Para asignar permisos de Kubernetes a los usuarios, puede crear roles y enlaces de rol.
Identidad y control de acceso basado en rol de Azure Stack Hub
Azure Stack Hub proporciona dos opciones de proveedor de identidades. El proveedor que use dependerá del entorno y de si se ejecuta en un entorno con o sin conexión:
- Azure AD: solo se puede usar en un entorno conectado.
- ADFS en un bosque de Active Directory tradicional: puede usarse en un entorno con o sin conexión.
El proveedor de identidades administra usuarios y grupos, incluida la autenticación y autorización para acceder a los recursos. Se puede conceder acceso a los recursos de Azure Stack Hub como suscripciones y grupos de recursos, y a recursos individuales, como las máquinas virtuales o los equilibradores de carga. Para tener un modelo de acceso coherente, considere la posibilidad de usar los mismos grupos (directos o anidados) para todas las instancias de Azure Stack Hub. A continuación se muestra un ejemplo de configuración:

El ejemplo contiene un grupo dedicado (con AAD o ADFS) para un propósito específico. Por ejemplo, para proporcionar permisos de Colaborador para el grupo de recursos que contiene nuestra infraestructura de clústeres de Kubernetes en una instancia de Azure Stack Hub específica (en este ejemplo "Colaborador del clúster Seattle K8s"). A continuación, estos grupos se anidan en un grupo global que contiene los "subgrupos" de cada instancia de Azure Stack Hub.
Nuestro usuario de ejemplo tendrá ahora permisos de "Colaborador" en los grupos de recursos que contengan todo el conjunto de recursos de infraestructura de Kubernetes. El usuario tendrá acceso a los recursos de ambas instancias de Azure Stack Hub, ya que estas comparten el mismo proveedor de identidades.
Importante
Estos permisos solo afectan a Azure Stack Hub y a algunos de los recursos implementados en él. Un usuario que tenga este nivel de acceso puede causar muchos daños, pero no puede acceder a las máquinas virtuales de IaaS de Kubernetes ni a la API de Kubernetes sin acceso adicional a la implementación de Kubernetes.
Identidad de Kubernetes y RBAC
De forma predeterminada, un clúster de Kubernetes no usa el mismo proveedor de identidades que la instancia de Azure Stack Hub subyacente. Las máquinas virtuales que hospedan el clúster de Kubernetes, el maestro y los nodos de trabajo usan la clave SSH que se especifica durante la implementación del clúster. Esta clave SSH es necesaria para conectarse a estos nodos mediante SSH.
La API de Kubernetes (por ejemplo, a la que se tiene acceso mediante kubectl) también está protegida por las cuentas de servicio, incluida una cuenta de servicio "Administrador de clústeres" predeterminada. Las credenciales de esta cuenta de servicio se almacenan inicialmente en el archivo .kube/config de los nodos maestro de Kubernetes.
Administración de secretos y credenciales de aplicaciones
Para almacenar secretos como cadenas de conexión o credenciales de base de datos, hay varias opciones, entre las que se incluyen:
- Azure Key Vault
- Secretos de Kubernetes
- Soluciones de terceros como HashiCorp Vault (que se ejecuta en Kubernetes)
No almacene secretos o credenciales en texto no cifrado en los archivos de configuración, en el código de la aplicación ni en los scripts. Y no los almacene en un sistema de control de versiones. En su lugar, la automatización de la implementación debe recuperar los secretos según sea necesario.
Revisiones y actualizaciones
El proceso de revisión y actualización (PNU) de Azure Kubernetes Service está parcialmente automatizado. Las actualizaciones de versiones de Kubernetes se desencadenan manualmente, mientras que las actualizaciones de seguridad se aplican automáticamente. Estas actualizaciones pueden incluir las revisiones de seguridad del sistema operativo o las actualizaciones del kernel. AKS no reinicia automáticamente estos nodos de Linux para completar el proceso de actualización.
El proceso de revisión y actualización de un clúster de Kubernetes implementado con el motor de AKS en Azure Stack Hub no está administrado y es responsabilidad del operador de clústeres.
El motor de AKS ayuda con las dos tareas más importantes:
- Actualizar a una versión más reciente de la imagen de Kubernetes y del sistema operativo base
- Actualizar solo la imagen del sistema operativo base
Las imágenes más recientes del sistema operativo base contienen las últimas correcciones de seguridad del sistema operativo y las actualizaciones del kernel.
El mecanismo de actualización desatendida instala automáticamente las actualizaciones de seguridad que se publican antes de que haya disponible una nueva versión de la imagen del sistema operativo base en el Marketplace de Azure Stack Hub. La actualización desatendida está habilitada de forma predeterminada e instala las actualizaciones de seguridad automáticamente, pero no reinicia los nodos de clúster de Kubernetes. El reinicio de los nodos puede automatizarse mediante el código abierto KUbernetes REboot Daemon (Kured)). Kured supervisa los nodos de Linux que requieren un reinicio y, después, administra automáticamente la reprogramación de los pods en ejecución y el proceso de reinicio de los nodos.
Consideraciones de implementación (CI/CD)
Azure y Azure Stack Hub exponen las mismas API REST de Azure Resource Manager. Estas API se tratan como cualquier otra nube de Azure (Azure, Azure China 21Vianet, Azure Government). Puede haber diferencias en las versiones de API entre las nubes, y Azure Stack Hub proporciona solo un subconjunto de servicios. El URI del punto de conexión de administración también es diferente para cada nube y cada instancia de Azure Stack Hub.
Aparte de las pequeñas diferencias ya mencionadas, las API REST de Azure Resource Manager proporcionan una manera coherente de interactuar con Azure y Azure Stack Hub. Aquí se puede usar el mismo conjunto de herramientas que se utilizará con cualquier otra nube de Azure. Puede usar Azure DevOps, herramientas como Jenkins, o PowerShell para implementar y coordinar servicios en Azure Stack Hub.
Consideraciones
Una de las principales diferencias en lo que respecta a las implementaciones de Azure Stack Hub es la cuestión de la accesibilidad a Internet. La accesibilidad a Internet determina si se debe seleccionar un agente de compilación hospedado por Microsoft o uno autohospedado para los trabajos de CI/CD.
Un agente autohospedado se puede ejecutar sobre Azure Stack Hub (como una máquina virtual de IaaS) o en una subred con acceso a Azure Stack Hub. Vaya a Agentes de Azure Pipelines para más información sobre las diferencias.
La siguiente imagen le ayuda a decidir si necesita un agente de compilación autohospedado o uno hospedado por Microsoft:
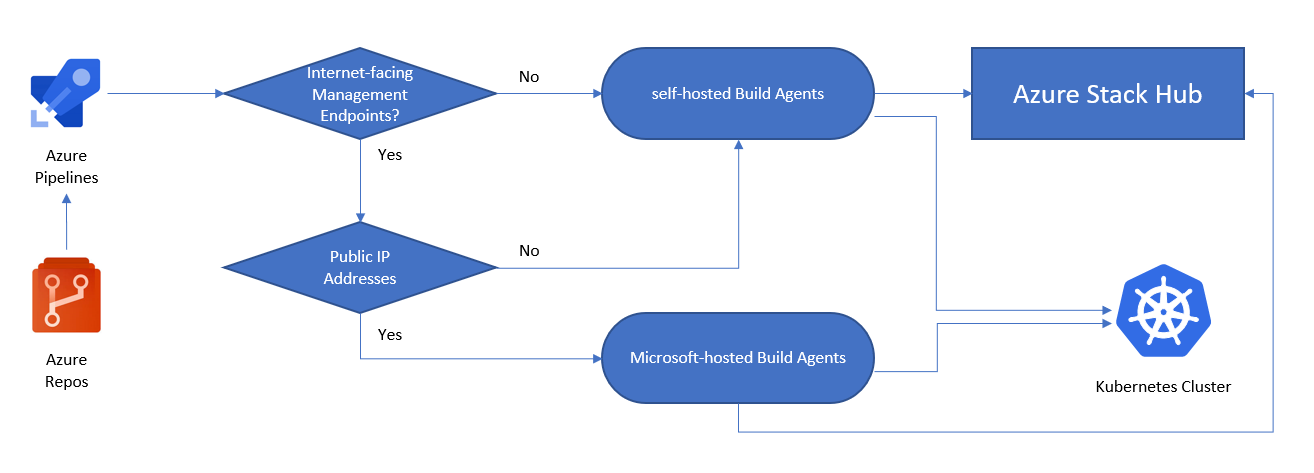
- ¿Son los puntos de conexión de administración de Azure Stack Hub accesibles a través de Internet?
- Sí: se puede usar Azure Pipelines con agentes hospedados por Microsoft para conectarse a Azure Stack Hub.
- No: se necesitan agentes autohospedados que puedan conectarse a los puntos de conexión de administración de Azure Stack Hub.
- ¿Es el clúster de Kubernetes accesible a través de Internet?
- Sí: se puede usar Azure Pipelines con agentes hospedados por Microsoft para interactuar directamente con el punto de conexión de la API de Kubernetes.
- No: se necesitan agentes autohospedados que puedan conectarse al punto de conexión de la API del clúster de Kubernetes.
En los escenarios en los que los puntos de conexión de administración de Azure Stack Hub y la API de Kubernetes son accesibles a través de Internet, la implementación puede usar un agente hospedado por Microsoft. Esta implementación producirá una arquitectura de aplicación similar a la que se indica a continuación:

Si no se puede acceder a los puntos de conexión de Azure Resource Manager, a la API de Kubernetes, o a ambos, directamente a través de Internet, podemos aprovechar un agente de compilación autohospedado para ejecutar los pasos de la canalización. Este diseño necesita menos conectividad y se puede implementar solo con conectividad de red local en los puntos de conexión de Azure Resource Manager y la API de Kubernetes:

Nota
¿Qué ocurre con los escenarios sin conexión? En escenarios en los que Azure Stack Hub o Kubernetes, o en ambos, no tienen puntos de conexión de administración con conexión a Internet, todavía es posible usar Azure DevOps para sus implementaciones. Puede usar un grupo de agentes autohospedado (que es un agente de DevOps que se ejecuta en el entorno local o en la propia instancia de Azure Stack Hub) o en un servidor completamente autohospedado de Azure DevOps Server local. El agente autohospedado solo necesita conectividad saliente a Internet HTTPS (TCP/443).
El patrón puede usar un clúster de Kubernetes (implementado y organizado con el motor de AKS) en cada instancia de Azure Stack Hub. Incluye una aplicación que consta de un front-end, un nivel medio, servicios de back-end (por ejemplo, MongoDB) y un controlador de entrada basado en Nginx. En lugar de usar una base de datos hospedada en el clúster K8s, puede usar los "almacenes de datos externos". Entre las opciones de base de datos se incluyen MySQL, SQL Server o cualquier tipo de base de datos hospedada fuera de Azure Stack Hub o en IaaS. Las configuraciones como esta no pertenecen a este ámbito.
Soluciones de socios
Hay soluciones de asociados de Microsoft que pueden ampliar las funcionalidades de Azure Stack Hub. Estas soluciones han resultado útiles en implementaciones de aplicaciones que se ejecutan en clústeres de Kubernetes.
Soluciones de almacenamiento y datos
Como se indica en la sección Consideraciones a tener en cuenta sobre datos y almacenamiento, Azure Stack Hub no dispone actualmente de una solución nativa para replicar el almacenamiento en varias instancias. A diferencia de Azure, la funcionalidad de replicación de almacenamiento en varias regiones no existe. En Azure Stack Hub, cada instancia es su propia nube independiente. Sin embargo, hay soluciones disponibles de asociados de Microsoft que permiten la replicación del almacenamiento en instancias de Azure Stack Hub y en Azure.
SCALITY
Scality ofrece un almacenamiento a escala web que ha supuesto un gran impulso para las empresas digitales desde 2009. Scality RING, nuestra solución de almacenamiento definido por software, convierte los servidores x86 en un bloque de almacenamiento ilimitado para cualquier tipo de datos (archivos y objetos) a escala de petabytes.
CLOUDIAN
Cloudian simplifica el almacenamiento empresarial con almacenamiento escalable ilimitado que consolida los conjuntos de datos masivos en un entorno único y de fácil administración.
Pasos siguientes
Para más información sobre los conceptos presentados en este artículo, consulte:
- Escalado de toda la nube y Patrones de aplicaciones distribuidas geográficamente en Azure Stack Hub.
- Arquitectura de microservicios en Azure Kubernetes Service (AKS).
Cuando esté listo para probar la solución de ejemplo, continúe con la guía de implementación de clústeres de Kubernetes de alta disponibilidad. La guía de implementación proporciona instrucciones paso a paso para implementar y probar sus componentes.