Ampliar Smart Store Analytics
Los usuarios avanzados de Smart Store Analytics pueden acceder a datos y análisis relevantes desde su propio almacenamiento de lago de datos. El acceso puede ser a través de cualquier otro servicio o aplicación compatible con la definición de Microsoft Azure Data Lake Storage y Common Data Model, por ejemplo, Microsoft Azure Synapse Analytics, Microsoft Azure Data Factory o Microsoft Power BI.
Importante
Tiene que usar Microsoft Azure Data Lake Storage Gen2, ya que Microsoft Azure Data Lake Storage Gen1 será incompatible.
El modelo de datos de Smart Store Analytics cumple con las plantillas de base de datos de Azure Synapse para minoristas, está mejorado con las especificaciones de Smart Store Analytics y simplifica la conexión de otras aplicaciones a los datos del lago.
Estructura del lago de datos de Smart Store Analytics
El lago de datos de Smart Store Analytics sigue la definición de Common Data Model (metadatos de Common Data Model).

La carpeta raíz se llama smartstores/. En la carpeta raíz, hay dos instantáneas de datos:
Datos transformados del proveedor de la tienda inteligente (datos brutos de la tienda inteligente)
El manifiesto del Common Data Model raíz para los datos sin procesar es root.manifest.cdm.json. El archivo de manifiesto hace referencia a los archivos de esquema y los archivos de datos reales ubicados en las subcarpetas (nombradas según las tablas), por ejemplo, smartstores/Order/.
La subcarpeta de cada tabla contiene:
archivo de esquema, que define los metadatos, las columnas y los tipos de la tabla, en formato table-name.cdm.json , por ejemplo, Order.cdm.json
archivos de datos, también conocidos como particiones de datos o registros de tablas, en formato parquet, por ejemplo, Order-cec9368060a849b8aab7583b62b506eb-00001.parquet
Datos generados por los módulos Retail Analytical e IA a partir de los datos sin procesar de la tienda inteligente
Todos los datos generados están en una carpeta con nombre GUID, por ejemplo, smartstores/14a7334b-7176-ed11-9985-00224804e0d0/. El manifiesto del Common Data Model raíz para estos datos es kpi.manifest.cdm.json. El archivo de manifiesto hace referencia a los archivos de esquema y los archivos de datos reales ubicados en la carpeta con el nombre GUID.
La carpeta con nombre GUID contiene:
Archivo de esquema, que define los metadatos, las columnas y los tipos de la tabla, en formato table-name.cdm.json, por ejemplo, OrderMetrics.cdm.json
Archivos de datos, también conocidos como particiones de datos o registros de tablas, en formato parquet, por ejemplo, part-00000-1e110bf0-6474-400b-b40a-086fce9f8e2a-c000.snappy.parquet
Importante
De acuerdo con el contrato de metadatos de Common Data Model, los usuarios solo necesitan datos de los archivos manifest.cdm.json. No necesitan interpretar la estructura de carpetas u otros archivos internos presentes en el lago de datos.
Uso del lago de datos de Smart Store Analytics
Estos son algunos ejemplos de datos sincronizados en información analítica/IA generados por Microsoft Cloud for Retail.
Canalización de datos con Microsoft Azure Data Factory
Para crear una canalización de datos:
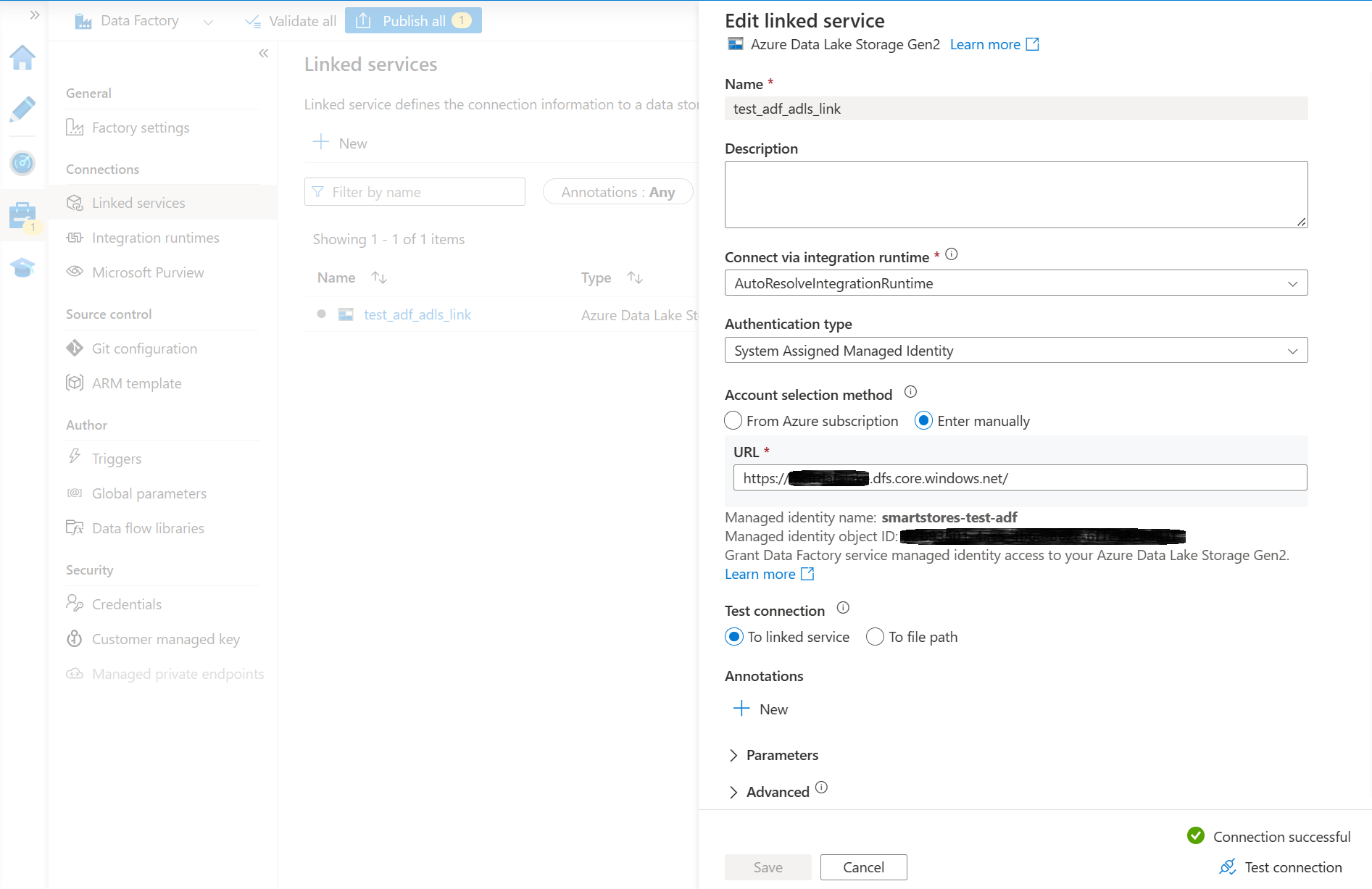
- Cree una instancia de Azure Data Factory y vincúlela al almacenamiento del lago de datos de Smart Store Analytics. Debería tener un servicio vinculado con una prueba de conexión exitosa.
Nota
La forma más fácil de conectar una instancia de Azure Data Factory a Azure Data Lake Storage es asignar un rol de colaborador a una identidad administrada de Azure Data Factory en la cuenta de Azure Data Lake Storage. Vea documentación de Azure Data Factory para obtener detalles.
- Seleccione Publicar todos para publicar el nuevo vinculo.
Crear una canalización de datos con Microsoft Azure Data Factory
Para crear una canalización de copia para la carpeta smartstores/ como origen, realice los siguientes pasos:
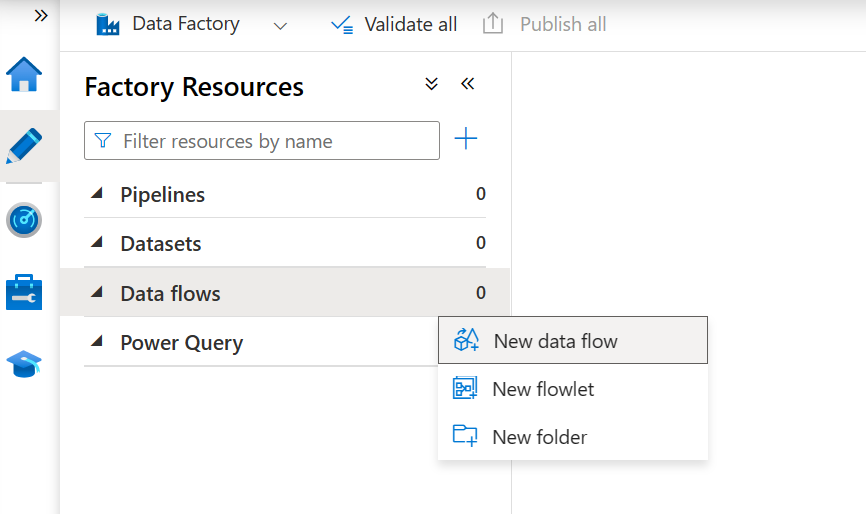
- En la sección Autor, seleccione Nuevo flujo de datos para crear un nuevo flujo de datos.
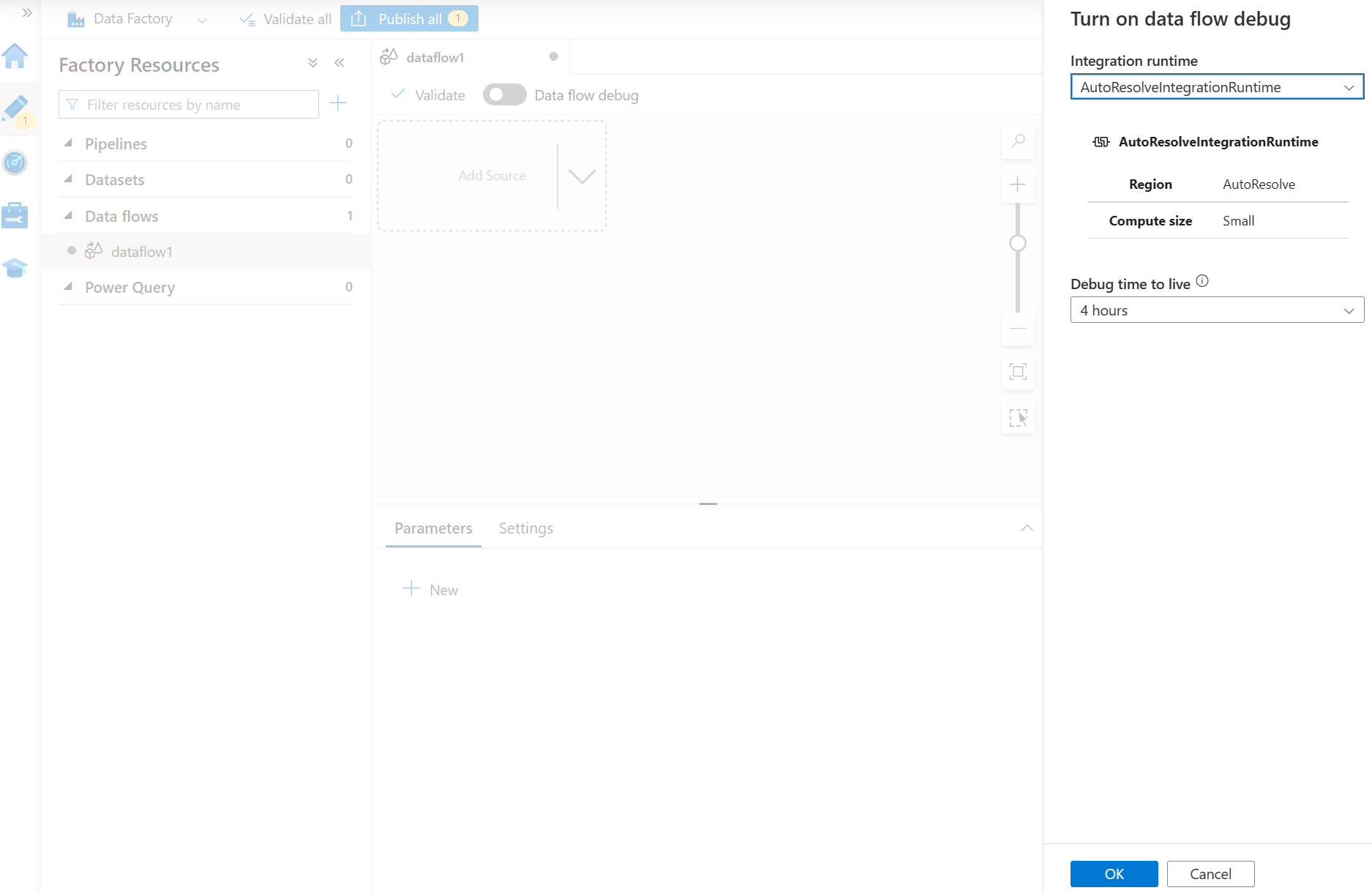
- Inicie la depuración para una verificación más rápida de la configuración de la canalización.
- Configure los ajustes de origen de la siguiente manera:
- Para Tipo de origen, seleccione Insertado
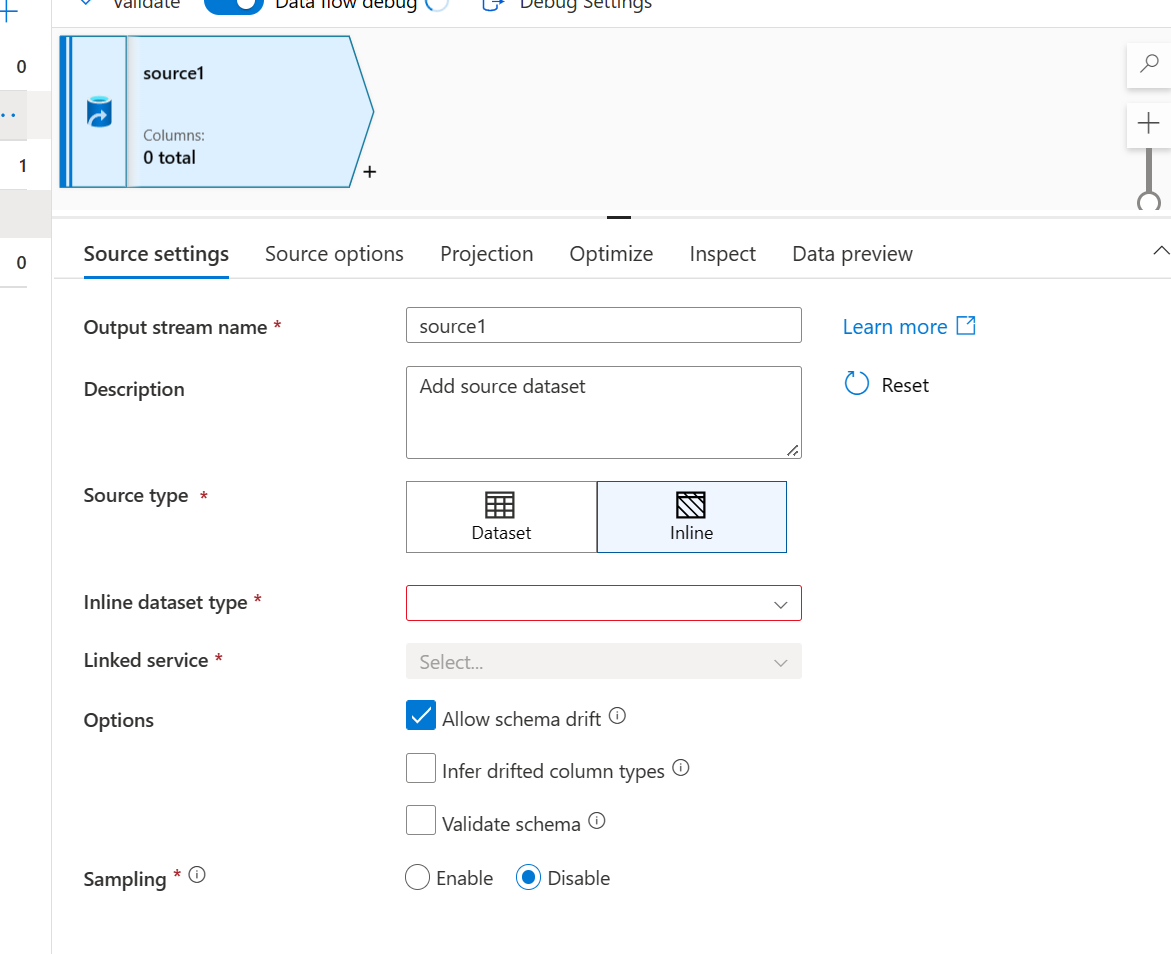
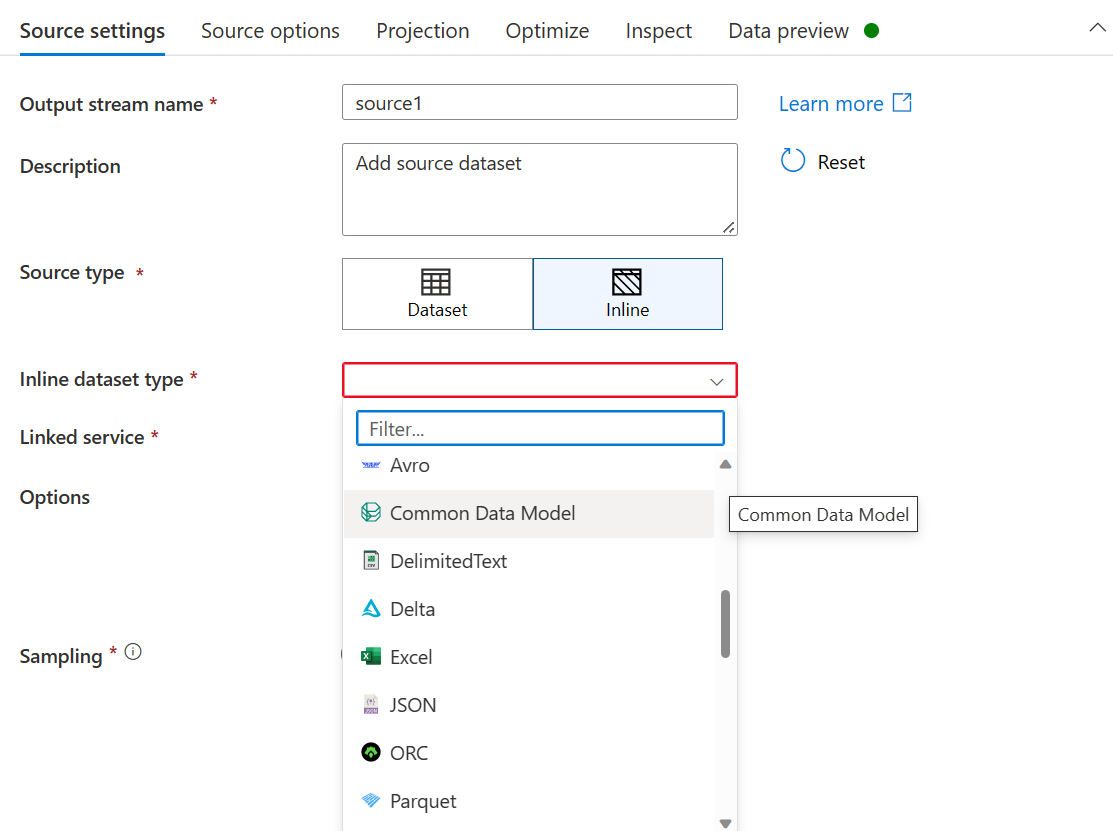
- Para Tipo de conjunto de datos insertado, seleccione Common Data Model
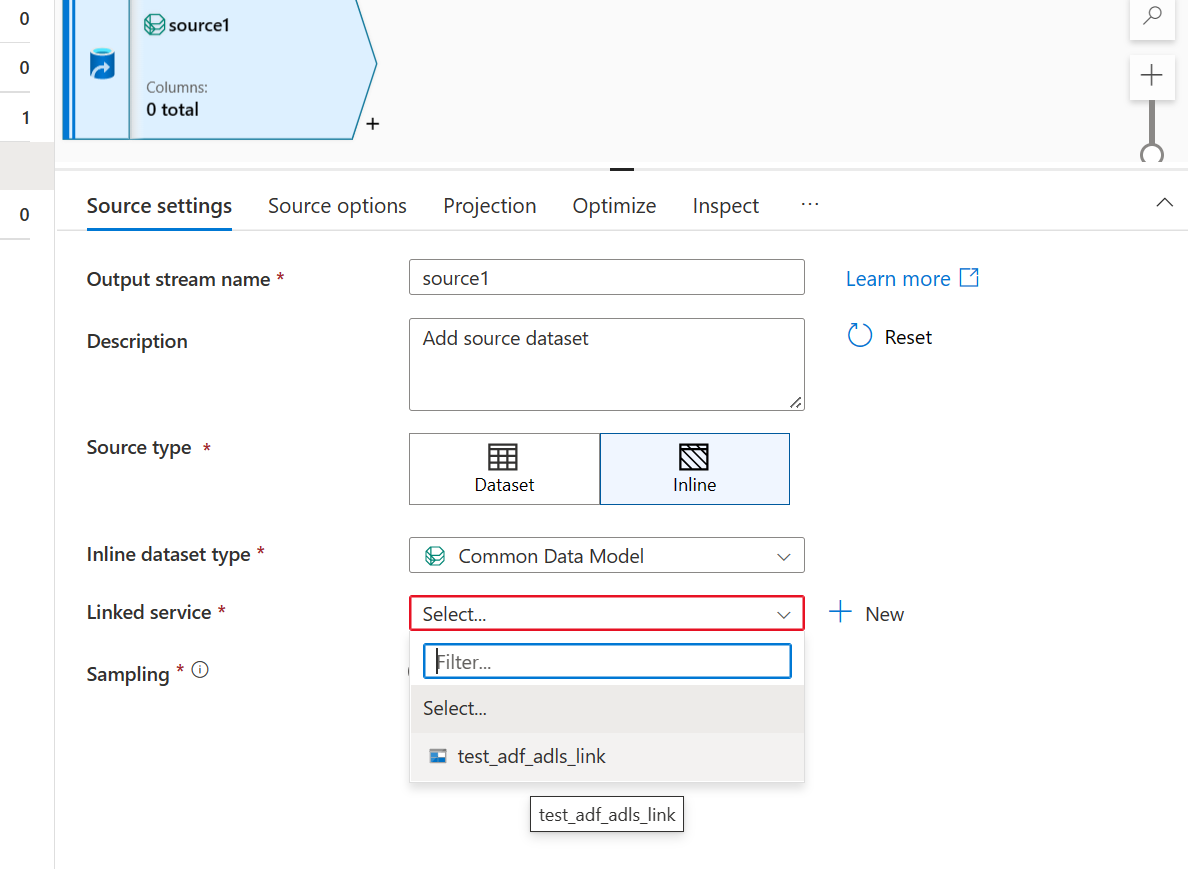
- Utilice el vínculo Azure Data Lake Storage creado para el lago de datos de Smart Stores.
- En la sección Opciones de origen, configure el origen del esquema de Common Data Model de la siguiente manera:
- Seleccione Manifiesto como formato de metadatos.
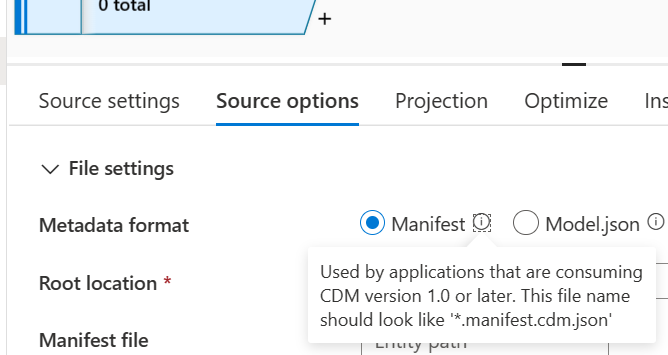
En la ubicación raíz, busque y seleccione la carpeta smartstores.
En la sección Archivo de manifiesto, navegue para seleccionar el manifiesto raíz requerido. Seleccione el archivo raíz para los datos analíticos y de AI Insights kpi.manifest.cdm.json.
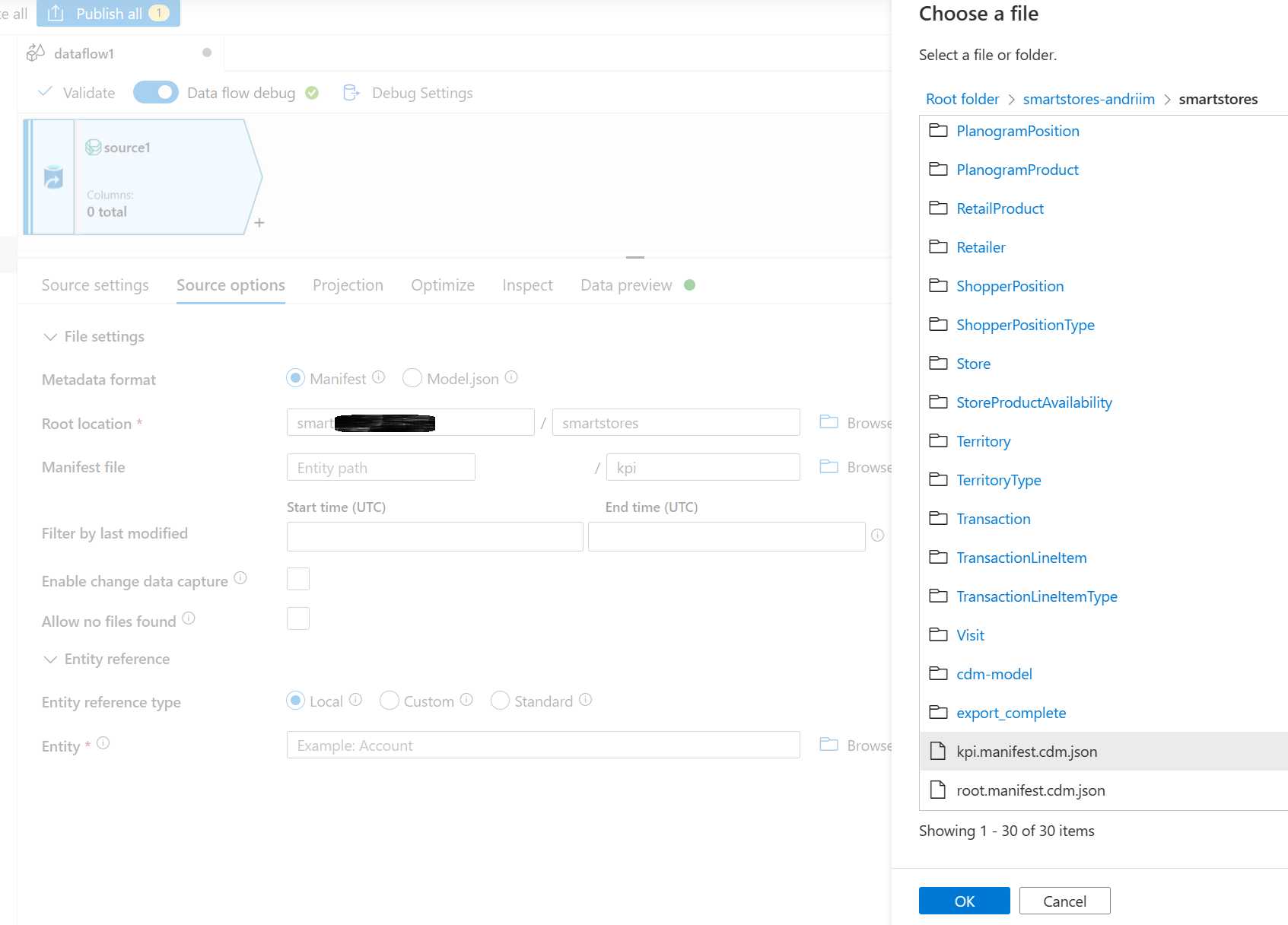
En la sección Entidad, seleccione la entidad (tabla) que necesita copiar/transformar, por ejemplo, FBTProductAssociationsUI del paquete Comprados juntos frecuentemente.

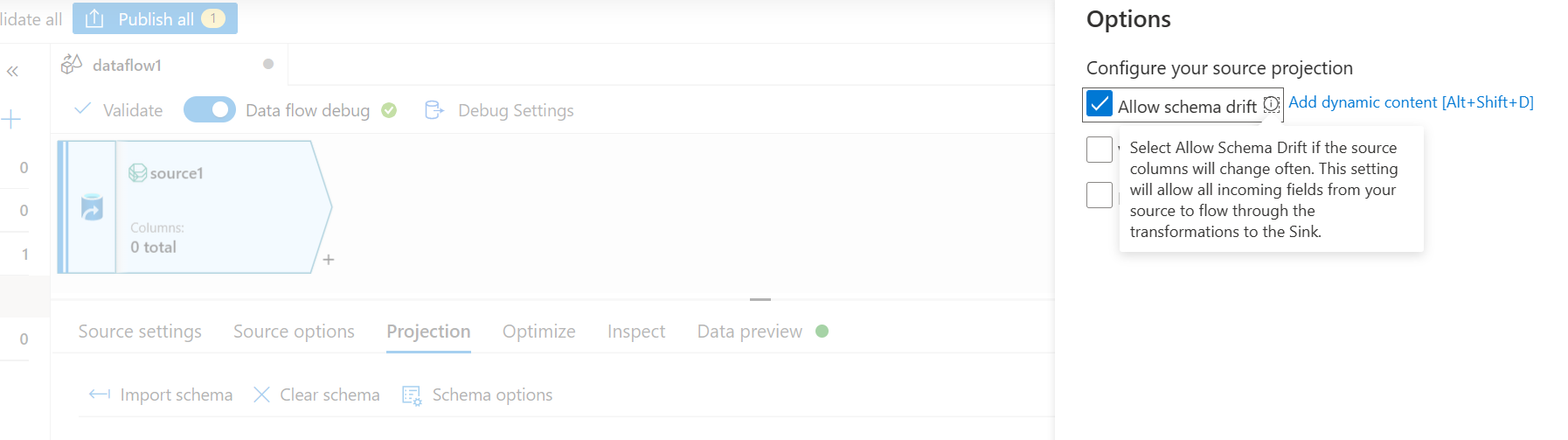
- En la pestaña Proyección, seleccione Permitir desviación de esquema. Esta selección garantizará que el esquema no se valide en el origen, sino que se desvíe a otros pasos de transformación/recepción.
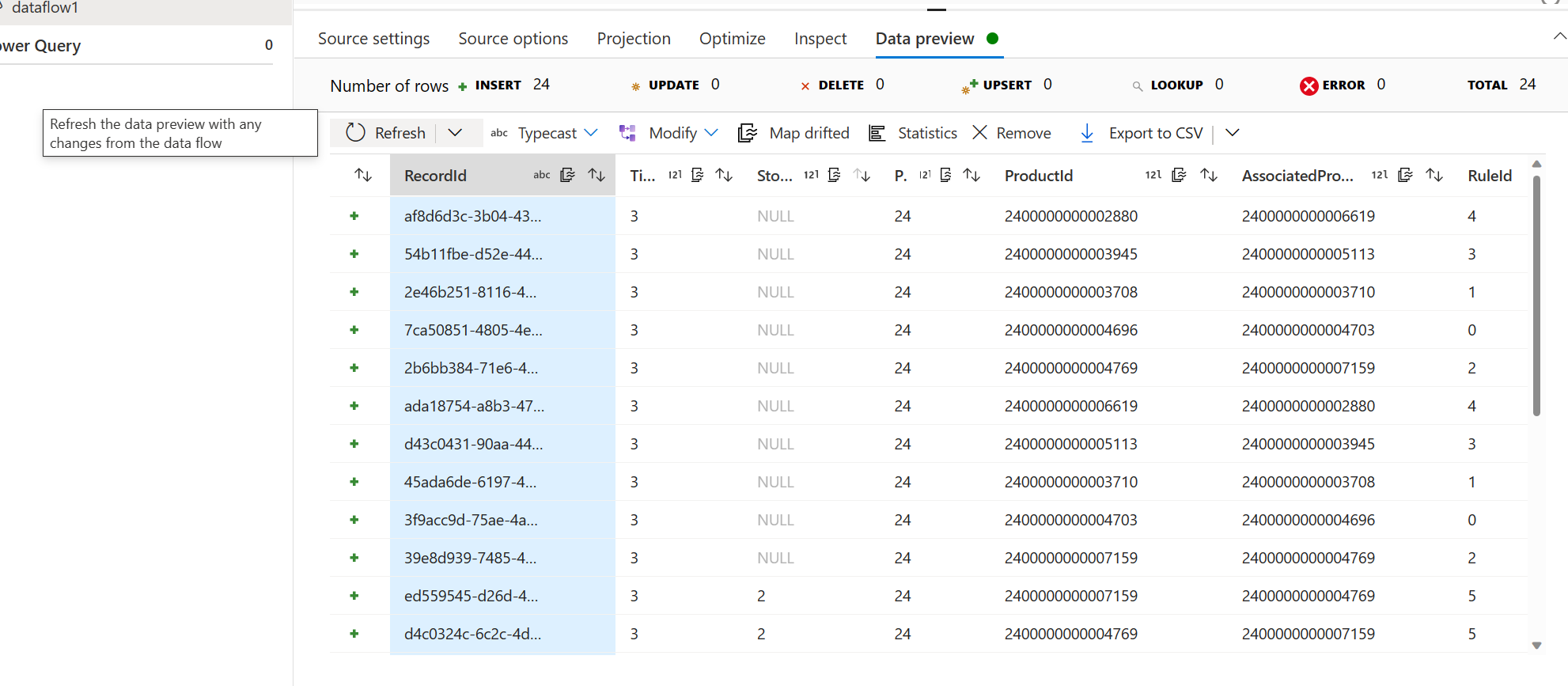
- En la pestaña Vista previa de datos, seleccione Recargar para validar la configuración de origen de datos.
Agregue un paso de recepción: configure los parámetros y la asignación de datos según sea necesario para su escenario.
Seleccione Publicar para publicar los cambios.