Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La función dbscan_fl() es una UDF (función definida por el usuario) que agrupa un conjunto de datos mediante el algoritmo DBSCAN.
Requisitos previos
- El complemento de Python debe estar habilitado en el clúster. Esto es necesario para python insertado que se usa en la función .
- El complemento de Python debe estar habilitado en la base de datos. Esto es necesario para python insertado que se usa en la función .
Sintaxis
T | invoke dbscan_fl(características, cluster_col min_samples métrica , de epsilon metric_params, , , )
Obtenga más información sobre las convenciones de sintaxis.
Parámetros
| Nombre | Type | Obligatorio | Descripción |
|---|---|---|---|
| features | dynamic |
✔️ | Matriz que contiene los nombres de las columnas de características que se van a usar para la agrupación en clústeres. |
| cluster_col | string |
✔️ | Nombre de la columna para almacenar el identificador del clúster de salida para cada registro. |
| epsilon | real |
✔️ | Distancia máxima entre dos muestras que se deben considerar como vecinos. |
| min_samples | int |
Número de muestras en un vecindario para que un punto se considere como punto principal. | |
| métrico | string |
Métrica que se va a usar al calcular la distancia entre puntos. | |
| metric_params | dynamic |
Argumentos de palabra clave adicionales para la función de métrica. |
- Para obtener una descripción detallada de los parámetros, consulte la documentación de DBSCAN.
- Para obtener la lista de métricas, consulte cálculos de distancia.
Definición de función
Puede definir la función insertando su código como una función definida por la consulta o creandola como una función almacenada en la base de datos, como se indica a continuación:
Defina la función mediante la siguiente instrucción let. No se requieren permisos.
Importante
Una instrucción let no se puede ejecutar por sí sola. Debe ir seguido de una instrucción de expresión tabular. Para ejecutar un ejemplo de trabajo de kmeans_fl(), vea el ejemplo.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
Ejemplo
En el ejemplo siguiente se usa el operador invoke para ejecutar la función .
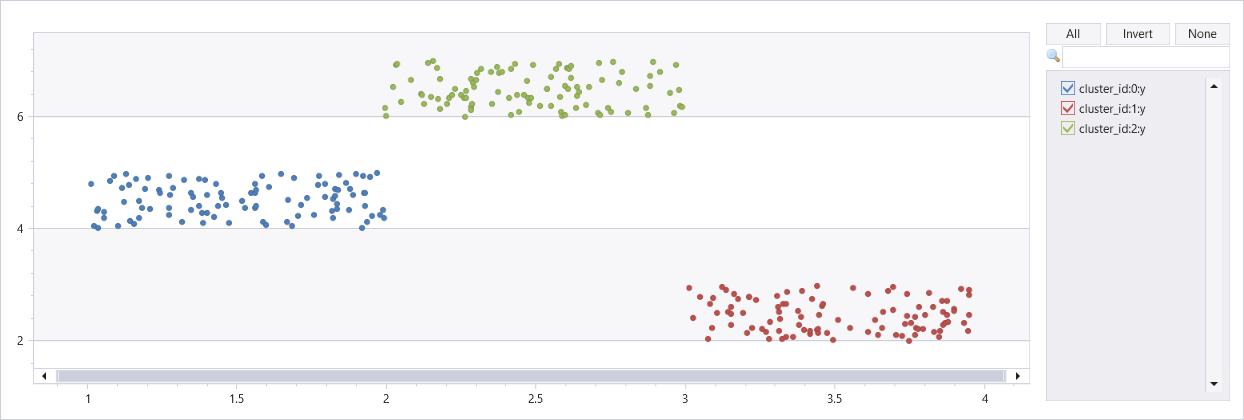
Agrupación en clústeres de conjuntos de datos artificiales con tres clústeres
Para usar una función definida por la consulta, invoquela después de la definición de función incrustada.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)