Función dcount() (función de agregación)
Se aplica a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Calcula una estimación del número de valores distintos que toma una expresión escalar en el grupo de resumen.
Los valores NULL se omiten y no tienen en cuenta el cálculo.
Nota:
La función de agregación dcount() es especialmente útil para estimar la cardinalidad de conjuntos de gran tamaño. Negocia la precisión del rendimiento y puede devolver un resultado que varía entre ejecuciones. El orden de las entradas puede afectar la salida.
Nota:
Esta función se usa junto con el operador summarize.
Sintaxis
dcount(expr[, precision])
Obtenga más información sobre las convenciones de sintaxis.
Parámetros
| Nombre | Type | Obligatorio | Descripción |
|---|---|---|---|
| expr | string |
✔️ | Entrada cuyos valores distintos se van a contar. |
| exactitud | int |
Valor que define la precisión de estimación solicitada. El valor predeterminado es 1. Consulte Precisión de estimación para conocer los valores admitidos. |
Devoluciones
Devuelve una estimación del número de valores distintos de expr en el grupo.
Ejemplo
En este ejemplo se muestra cuántos tipos de eventos de storm se produjeron en cada estado.
StormEvents
| summarize DifferentEvents=dcount(EventType) by State
| order by DifferentEvents
La tabla de resultados que se muestra incluye solo las primeras 10 filas.
| Valor | DifferentEvents |
|---|---|
| TEXAS | 27 |
| CALIFORNIA | 26 |
| PENSILVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| MARYLAND | 23 |
| CAROLINA DEL NORTE | 23 |
| MÍCHIGAN | 22 |
| FLORIDA | 22 |
| OREGON | 21 |
| KANSAS | 21 |
| ... | ... |
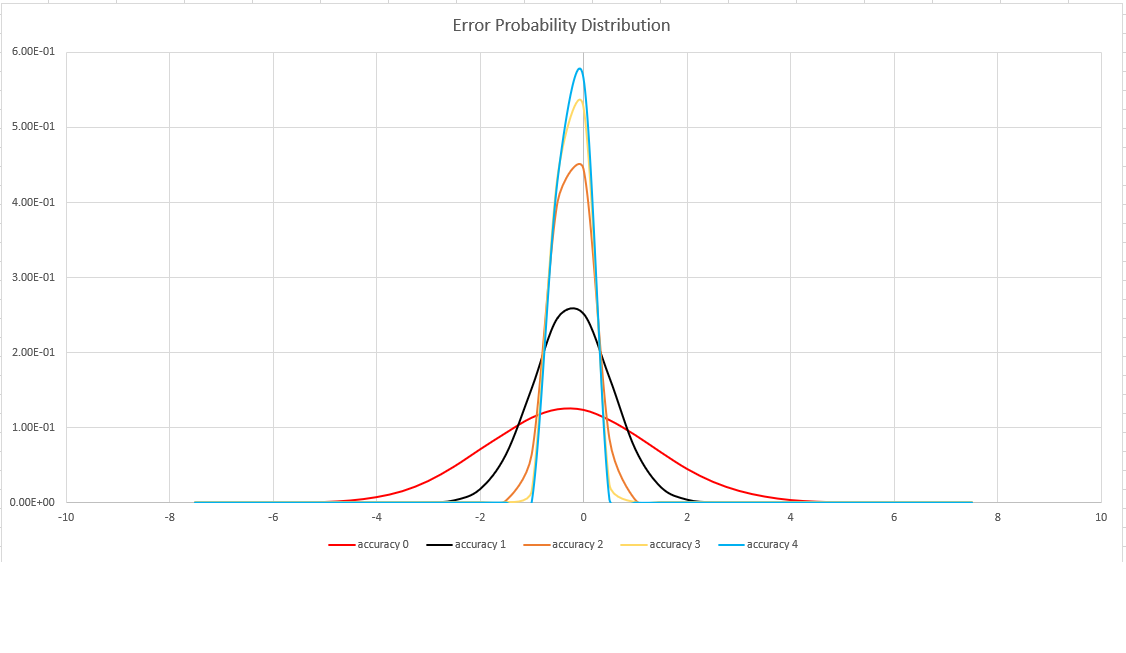
Precisión de la estimación
Esta función usa una variante del algoritmo HyperLogLog (HLL), que realiza una estimación estocástica de la cardinalidad establecida. El algoritmo proporciona una "manija" que se puede usar para equilibrar la precisión y el tiempo de ejecución por tamaño de memoria:
| Precisión | Error (%) | Recuento de entradas |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0,2 | 218 |
Nota:
La columna "recuento de entradas" es el número de contadores de 1 byte en la implementación HLL.
El algoritmo incluye algunas disposiciones para realizar un recuento perfecto (cero errores), si la cardinalidad del conjunto es lo suficientemente pequeña:
- Cuando el nivel de precisión es
1, se devuelven 1000 valores. - Cuando el nivel de precisión es
2, se devuelven 8000 valores.
El límite de errores es probabilístico, no un enlace teórico. El valor es la desviación estándar de la distribución de errores (sigma) y el 99,7 % de las estimaciones tendrá un error relativo de menos de 3 x sigma.
En la imagen siguiente se muestra la función de distribución de probabilidad del error de estimación relativa, en porcentajes, para todas las configuraciones de precisión compatibles: