Referencia técnica del conector de SQL genérico
En este artículo se describe el conector de SQL genérico. El artículo se aplica a los siguientes productos:
- Microsoft Identity Manager 2016 (MIM2016)
- Id. de Microsoft Entra
Para MIM2016, el conector está disponible como descarga desde el Centro de descarga de Microsoft.
Para ver este conector en acción, consulte el artículo Conector de SQL genérico paso a paso .
Nota
Microsoft Entra ID ahora proporciona una solución basada en agente ligero para aprovisionar usuarios en una base de datos SQL, sin necesidad de una implementación de sincronización de MIM. Se recomienda usarlo para el aprovisionamiento de usuarios salientes. Más información.
Información general sobre el conector de SQL genérico
El conector de SQL genérico permite integrar el servicio de sincronización con un sistema de base de datos que ofrece conectividad ODBC.
Desde una perspectiva de alto nivel, las siguientes características son compatibles con la versión actual del conector:
| Característica | Compatibilidad |
|---|---|
| Origen de datos conectado | El conector es compatible con todos los controladores ODBC de 64 bits*. Se ha probado con los siguientes: |
| Escenarios | |
| Operations | |
| Schema |
Requisitos previos
Antes de usar el conector, asegúrese de que tiene lo siguiente en el servidor de sincronización:
- Microsoft .NET 4.6.2 Framework o posterior
- Controladores cliente ODBC de 64 bits
- Si usa el conector para comunicarse con Oracle 12c, esto requiere Oracle Instant Client 12.2.0.1 o posterior con el paquete ODBC.
- Si usa el conector para comunicarse con Oracle 18c-23c, esto requiere Oracle Instant Client 18-23 o posterior con el paquete ODBC y la variable del sistema de NLS_LANG que se va a establecer para admitir caracteres UTF8, por ejemplo, NLS_LANG=AMERICAN_AMERICA. AL32UTF8.
- Este conector usa instrucciones preparadas de SQL y varias instrucciones por transacción. Algunos sistemas RDBM pueden tener problemas en sus controladores ODBC relacionados con el control de transacciones, las instrucciones SQL preparadas del lado servidor y varias instrucciones dentro de la misma transacción. Configure las opciones de conexión de DSN según corresponda para asegurarse de que esas instrucciones se envían correctamente a la base de datos. Por ejemplo, MySQL ODBC Driver versión 8.0.32 necesita opciones NO_SSPS=1 y MULTI_STATEMENTS=1. Otras opciones como "confirmación automática" o "confirmación solo en operaciones correctas" pueden afectar a cómo se controlan las exportaciones por lotes; consulte al administrador de la base de datos para obtener más información. Para solucionar problemas durante la exportación, establezca el tamaño del lote de exportación en 1 y habilite el registro detallado del conector.
La implementación de este conector puede requerir cambios en la configuración de la base de datos, así como en los cambios de configuración en MIM. En el caso de las implementaciones que implican la integración de MIM con un servidor de bases de datos de terceros en un entorno de producción, se recomienda que los clientes trabajen con su proveedor de bases de datos o con un asociado de implementación para obtener ayuda, instrucciones y soporte técnico para esta integración.
Permisos en origen de datos conectado
Para crear o realizar alguna de las tareas admitidas en el conector de SQL genérico, debe tener:
- db_datareader
- db_datawriter
Puertos y protocolos
En lo relativo a los puertos necesarios para el funcionamiento del controlador ODBC, consulte la documentación del proveedor de la base de datos.
Creación de un nuevo conector
Para crear un conector de SQL genérico, en Servicio de sincronización, seleccione Agente de administración y Crear. Seleccione el conector SQL genérico (Microsoft) .
Conectividad
El conector utiliza un archivo DSN de ODBC para la conectividad. Cree el archivo DSN mediante Orígenes de datos ODBC que se encuentra en el menú Inicio, en Herramientas administrativas. En la herramienta administrativa, cree un DSN de archivo que se pueda proporcionar al conector.
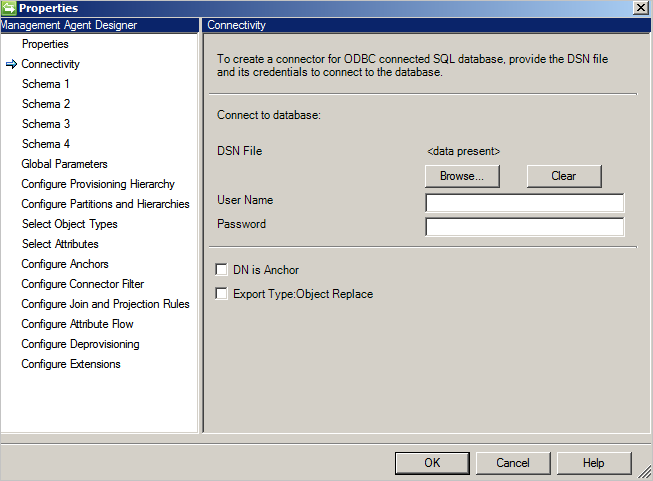
La pantalla Conectividad es la primera que aparece cuando se crea un nuevo conector de SQL genérico. Primero tiene que proporcionar la siguiente información:
- Ruta de acceso de archivo DSN
- Autenticación
- Nombre de usuario
- Contraseña
La base de datos debe admitir uno de estos métodos de autenticación:
- Autenticación de Windows: la base de datos de autenticación utiliza las credenciales de Windows para comprobar el usuario. Se utilizan el nombre de usuario y la contraseña especificados para realizar la autenticación con la base de datos. Esta cuenta necesita permisos para la base de datos.
- Autenticación de SQL: la base de datos de autenticación utiliza el nombre de usuario y la contraseña definidos en la pantalla Conectividad para conectarse a la base de datos. Si almacena el nombre de usuario y la contraseña en el archivo DSN, las credenciales proporcionadas en la pantalla Conectividad tendrán prioridad.
- Azure SQL Autenticación de base de datos: para obtener más información, consulte Conexión a SQL Database a través de la autenticación de Microsoft Entra.
DN is Anchor(DN es el delimitador): si selecciona esta opción, el nombre distintivo también se utilizará como atributo de delimitador. Se puede usar para una implementación simple, aunque tiene la siguiente limitación:
- El conector solo admite un tipo de objeto. Por lo tanto, los atributos de referencia únicamente pueden hacer referencia al mismo tipo de objeto.
Export Type: Object Replace(Tipo de exportación: reemplazar objeto): durante la exportación, cuando solo se han cambiado algunos atributos, se exportará el objeto completo con todos los atributos y reemplaza el objeto existente.
Esquema 1 (Detectar tipos de objeto)
En esta página, va a configurar cómo encuentra el conector los distintos tipos de objeto en la base de datos.
Cada tipo de objeto se presenta como una partición y se configura más adelante en Configurar particiones y jerarquías.
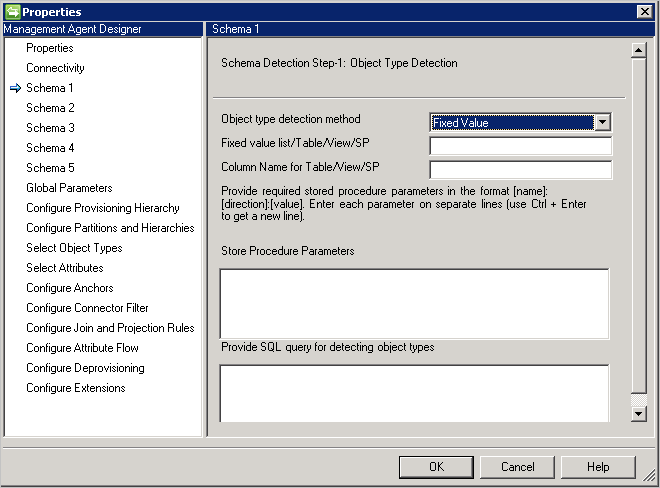
Método de detección de tipos de objeto: el conector admite estos métodos de detección de tipos de objeto.
- Valor fijo: proporcione la lista de tipos de objeto con una lista separada por comas. Por ejemplo:
User,Group,Department.
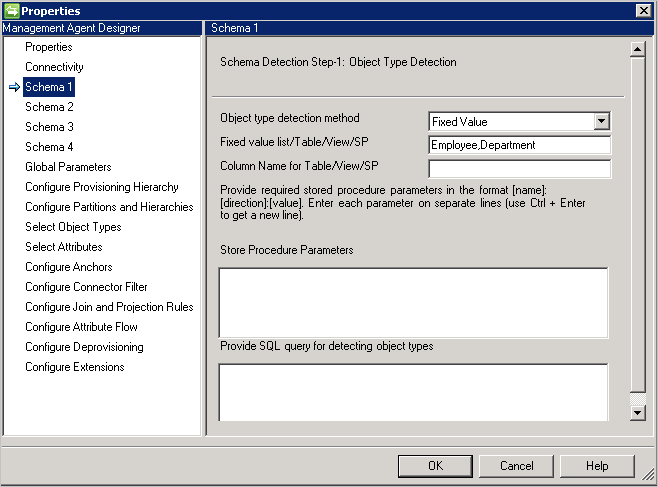
- Tabla/Vista/Procedimiento almacenado: indique el nombre de la tabla, vista o procedimiento almacenado y, después, el nombre de columna que proporciona la lista de tipos de objeto. Si utiliza un procedimiento almacenado, indique también los parámetros para él en el formato [Nombre]:[Dirección]:[Valor]. Proporcione cada parámetro en una línea independiente (use Ctrl + Entrar para obtener una nueva línea).
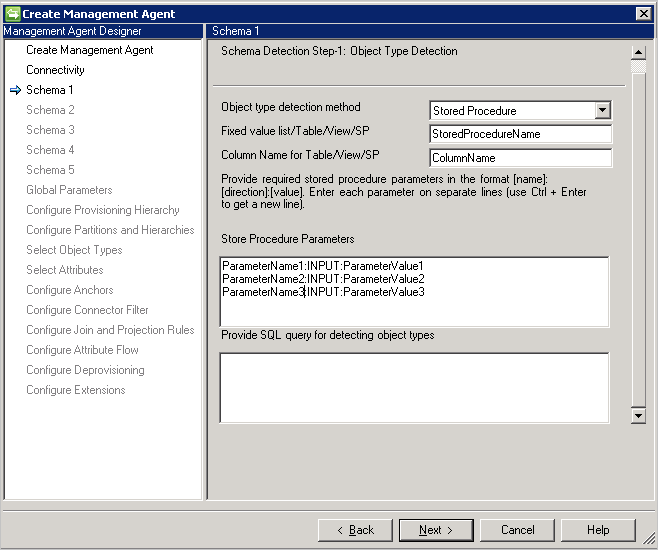
- Consulta SQL: esta opción permite proporcionar una consulta SQL que devuelve una sola columna con tipos de objeto, por ejemplo,
SELECT [Column Name] FROM TABLENAME. La columna devuelta debe ser de tipo cadena (varchar).
Esquema 2 (Detectar tipos de atributo)
En esta página va a configurar cómo se van a detectar los nombres y tipos de atributo. Se muestran las opciones de configuración para cada tipo de objeto detectado en la página anterior.
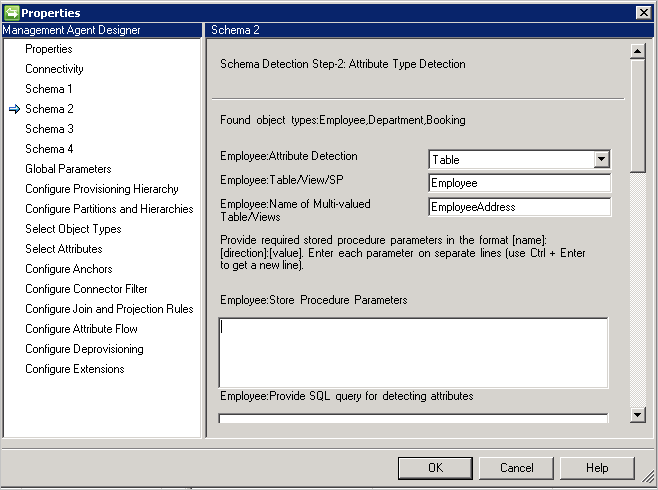
Método de detección de tipos de atributo: el conector admite estos métodos de detección de tipos de atributo con cada tipo de objeto detectado en la pantalla Esquema 1.
- Tabla/Vista/Procedimiento almacenado: proporcione el nombre de la tabla/vista/procedimiento almacenado que debe usarse para buscar los nombres de atributo. Si utiliza un procedimiento almacenado, indique también los parámetros para él en el formato [Nombre]:[Dirección]:[Valor]. Proporcione cada parámetro en una línea independiente (use Ctrl + Entrar para obtener una nueva línea). Para detectar los nombres de atributo en un atributo multivalor, proporcione una lista separada por comas de tablas o vistas. No se admiten escenarios multivalor si la tabla primaria y secundaria tienen los mismos nombres de columna.
- Consulta SQL: esta opción permite proporcionar una consulta SQL que devuelve una sola columna con nombres de atributo, por ejemplo,
SELECT [Column Name] FROM TABLENAME. La columna devuelta debe ser de tipo cadena (varchar).
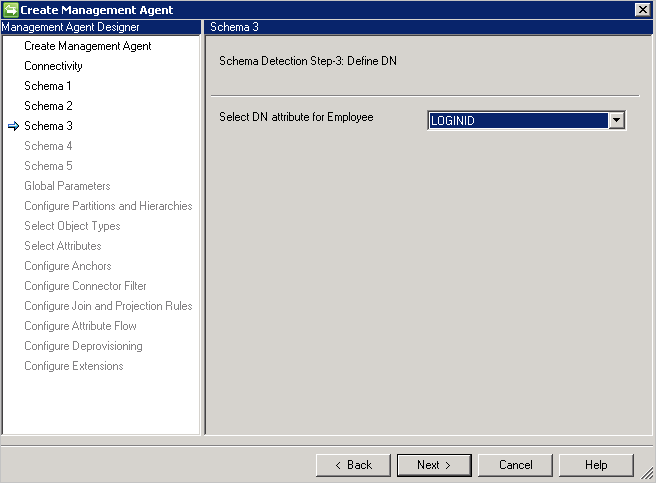
Esquema 3 (Definir delimitador y DN)
Esta página permite configurar el atributo de delimitador y de DN para cada tipo de objeto detectado. Puede seleccionar varios atributos para que el delimitador sea único.
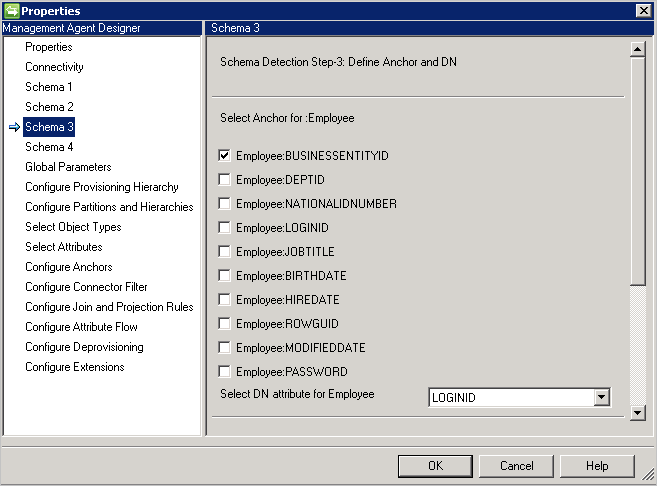
No se enumeran los atributos multivalor y booleanos.
No se puede usar el mismo atributo para el DN y el delimitador, a menos que DN es el delimitador esté seleccionado en la página Conectividad.
Si DN es el delimitador está seleccionado en la página Conectividad, esta página requiere solo el atributo de DN. Este atributo se utilizará también como el atributo de delimitador.
Esquema 4 (Definir tipo de atributo, referencia y dirección)
Esta página permite configurar el tipo de atributo como entero, binario o un valor booleano, así como la dirección para cada atributo. Se muestran todos los atributos de la página Esquema 2 , incluidos los atributos multivalor.
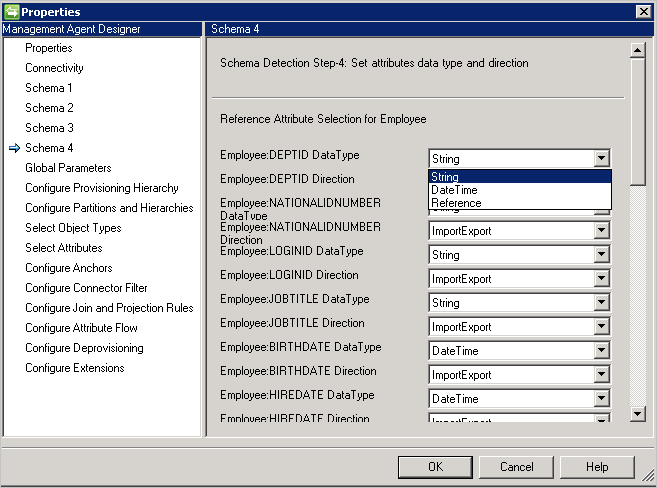
- DataType: se utiliza para asignar el tipo de atributo a aquellos tipos conocidos por el motor de sincronización. El valor predeterminado es usar el mismo tipo que el detectado en el esquema SQL, pero DateTime y Reference no son fácilmente detectables. Para estos, necesita especificar DateTime o Reference.
- Direction: puede establecer la dirección del atributo en Import, Export o ImportExport. ImportExport es el valor predeterminado.
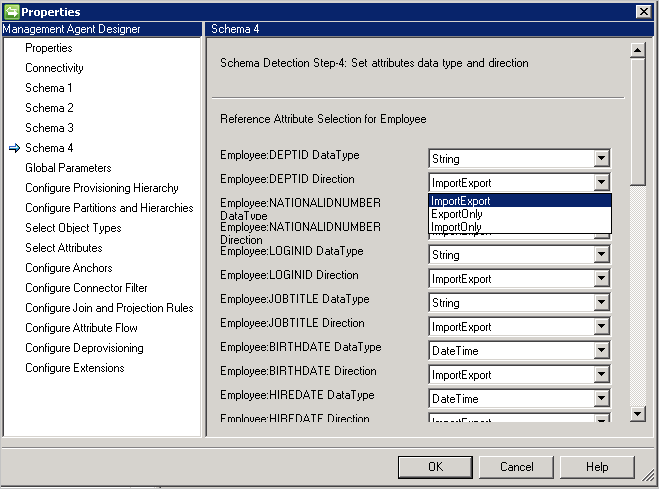
Notas:
- Si un tipo de atributo no es detectable por el conector, utiliza el tipo de datos String.
- Tablas anidadas se pueden considerar tablas de base de datos con una única columna. Oracle almacena las filas de una tabla anidada sin un orden determinado. Sin embargo, al recuperar la tabla anidada en una variable de PL/SQL, se asigna a las filas subíndices consecutivos a partir de 1. Esto le proporciona un acceso de tipo matriz a las filas individuales.
- VARRYS en el conector.
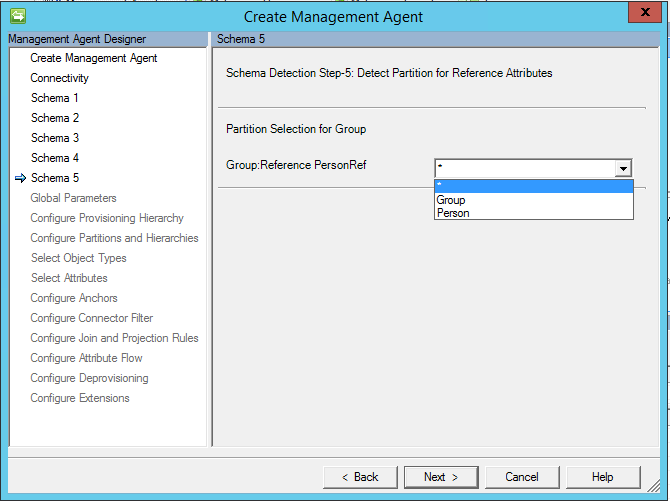
Esquema 5 (Definir partición para atributos de referencia)
En esta página, puede configurar en todos los atributos de referencia a qué partición (tipo de objeto) hace referencia un atributo.

Si utiliza DN is anchor(DN es el delimitador), debe usar el mismo tipo de objeto que el que desde el que hace referencia. No se puede hacer referencia a otro tipo de objeto.
Nota
A partir de la actualización de marzo de 2017, ahora hay una opción para "*". Cuando se elige esta opción, se importan todos los tipos de miembro posibles.
Importante
A partir de mayo de 2017, la opción "*" también conocida como cualquier opción se ha cambiado para admitir el flujo de importación y exportación. Si desea usar esta opción, la tabla o vista multivalor debe tener un atributo que contenga el tipo de objeto.

Si se selecciona "*", también se debe especificar el nombre de la columna con el tipo de objeto.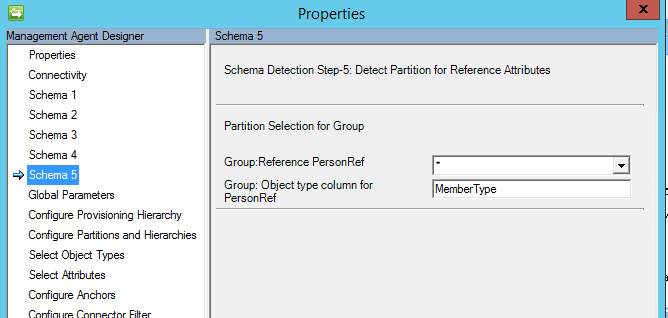
Después de la importación, verá una imagen similar a la que se encuentra a continuación:
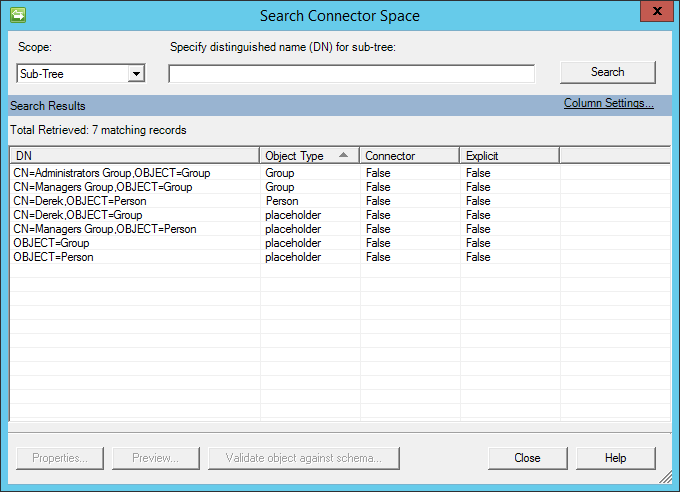
Parámetros globales
La página Parámetros globales se utiliza para configurar la importación diferencial, el formato de fecha y hora, y el método de contraseña.
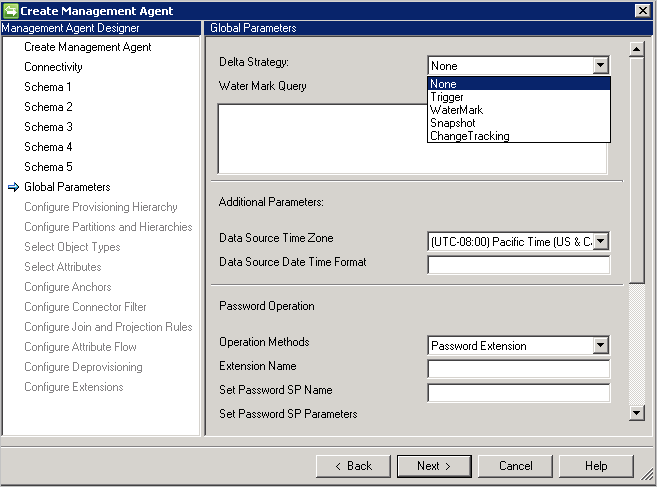
El conector de SQL genérico admite los siguientes métodos para la importación diferencial:
- Trigger: consulte Generating Delta Views Using Triggers.
- Watermark: un enfoque genérico que se puede utilizar con cualquier base de datos. La consulta de marca de agua se rellena previamente basándose en el proveedor de base de datos. En cada tabla/vista que se utiliza, debe estar presente una columna de marca de agua. Esta columna debe realizar el seguimiento de las inserciones y actualizaciones en las tablas, y sus tablas dependientes (multivalor o secundarias). Se deben sincronizar los relojes entre el servicio de sincronización y el servidor de base de datos. Si no es así, se pueden omitir algunas entradas en la importación diferencial.
Limitación:- La estrategia de marca de agua no admite objetos eliminados.
- Snapshot: (solo funciona con Microsoft SQL Server) Generating Delta Views Using Snapshots
- ChangeTracking: (solo funciona con Microsoft SQL Server) About ChangeTracking
Limitaciones:- Los atributos de delimitador y de DN deben ser parte de la clave principal para el objeto seleccionado en la tabla.
- No se admite la consulta SQL durante la importación y exportación con seguimiento de cambios.
Parámetros adicionales: especifique la zona horaria del servidor de base de datos que indica dónde se encuentra el servidor de base de datos. Este valor se utiliza para admitir los diversos formatos de los atributos de fecha y hora.
El conector siempre almacena la fecha y la fecha y hora en formato UTC. Para poder convertir correctamente la fecha y hora, se debe especificar la zona horaria del servidor de bases de datos y el formato utilizado. El formato debe expresarse en formato .NET.
Durante la exportación, se debe proporcionar cada atributo de fecha y hora al conector en formato UTC.
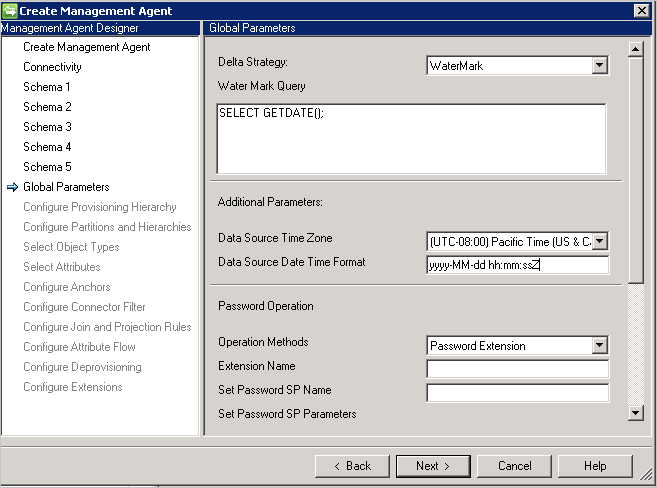
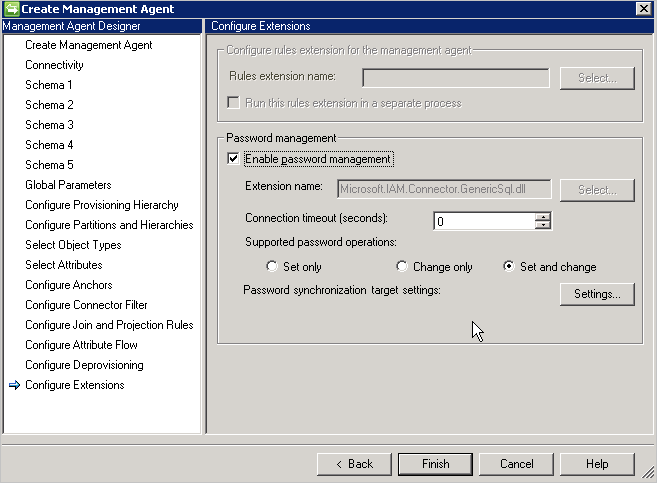
Configuración de contraseña: el conector proporciona funcionalidades de sincronización de contraseña, y admite el establecimiento y el cambio de contraseña.
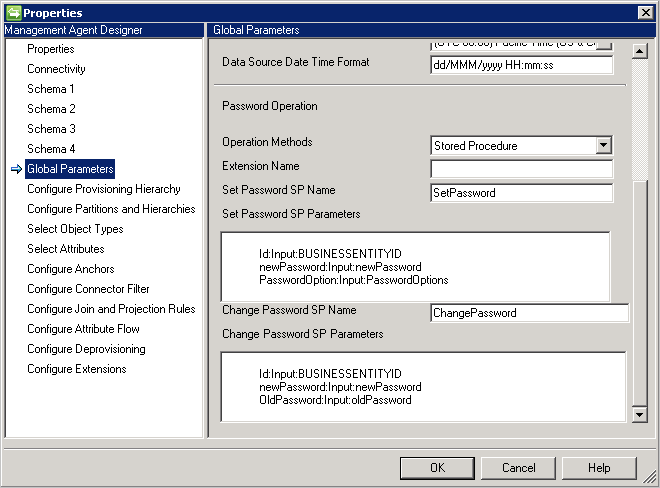
El conector proporciona dos métodos que admiten la sincronización de contraseña:
- Procedimiento almacenado: este método requiere dos procedimientos almacenados para admitir el establecimiento y el cambio de contraseña. Escriba todos los parámetros para la operación de agregación y cambio de contraseña en Set Password SP Parameters (Establecer parámetros de PA de contraseña) y Change Password SP Parameters (Cambiar parámetros de PA de contraseña) respectivamente como en el ejemplo siguiente.
- Extensión de contraseña: este método requiere el archivo DLL de extensión de contraseña (debe proporcionar el nombre del archivo DLL de la extensión que está implementando la interfaz IMAExtensible2Password ). El ensamblado de la extensión de contraseña debe colocarse en la carpeta de extensión para que el conector pueda cargar el archivo DLL en tiempo de ejecución.
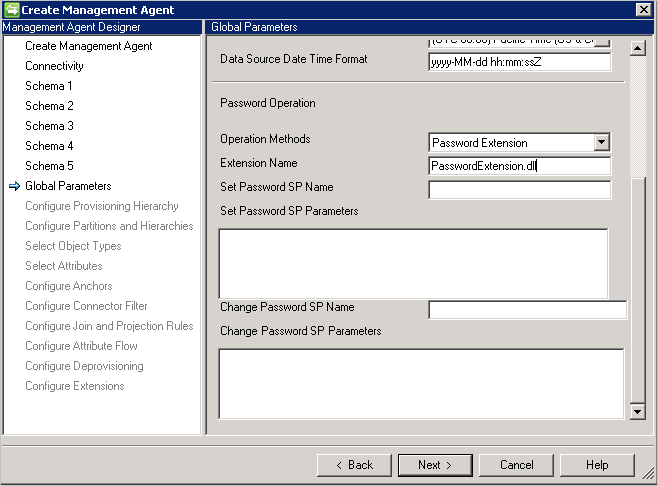
También debe habilitar la administración de contraseñas en la página Configurar extensiones .
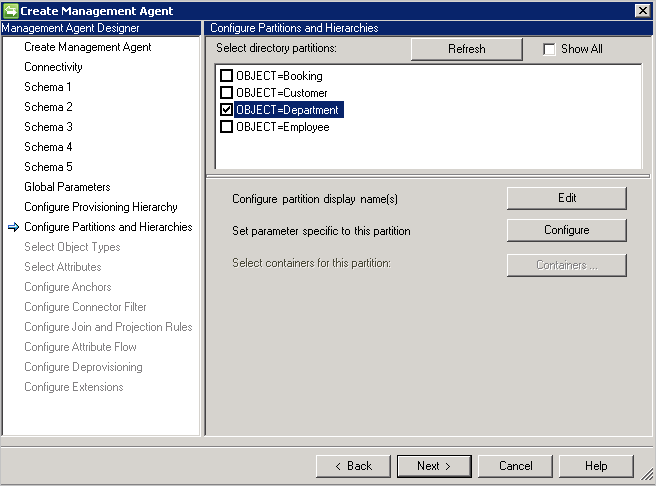
Configurar particiones y jerarquías
En la página de particiones y jerarquías, seleccione todos los tipos de objeto. Cada tipo de objeto está en su propia partición.
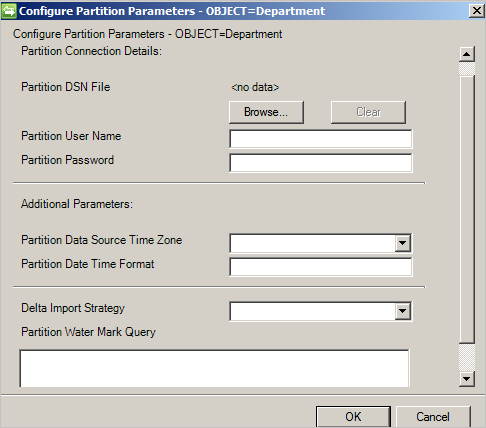
También puede invalidar los valores definidos en la página Conectividad o Parámetros globales.
Configuración de delimitadores
Esta página es de solo lectura puesto que ya se ha definido el delimitador. El atributo del delimitador seleccionado se anexa siempre con el tipo de objeto para asegurarse de que sigue siendo único en todos los tipos de objeto.
Configuración del parámetro de paso de ejecución
Estos pasos se configuran en los perfiles de ejecución del conector. Estas configuraciones realizan el trabajo real de importación y exportación de datos.
Importación completa y diferencial
El conector de SQL genérico admite la importación completa y diferencial mediante estos métodos:
- Tabla
- Ver
- Procedimiento almacenado
- Consulta SQL

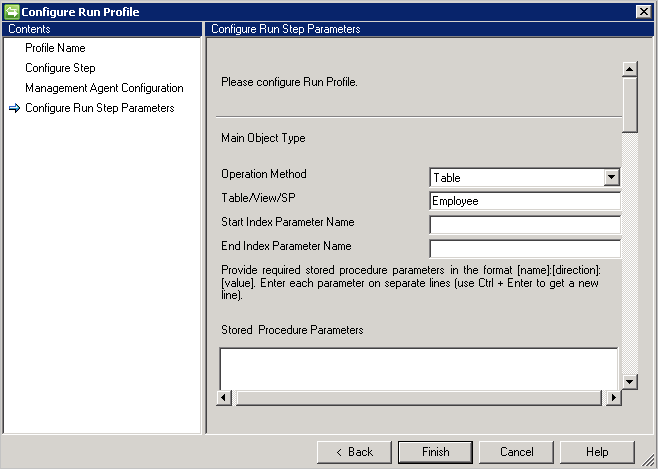
Tabla o vista
Para importar los atributos multivalor de un objeto, debe proporcionar el nombre de tabla/vista en Name of Multi-Valued table/views (Nombre de tabla/vistas multivalor) y las condiciones de combinación correspondientes en Condición de combinación con la tabla principal. Si hay más de una tabla con varios valores en el origen de datos, puede usar union en una sola vista.
Importante
El agente de administración de SQL genérico solo puede funcionar con una tabla multivalor. No coloque en Name of Multi-Valued table/views (Nombre de tabla/vistas multivalor) más de un nombre de tabla. Es la limitación de SQL genérico.
Ejemplo: Desea importar el objeto Employee y todos sus atributos multivalor. Hay dos tablas con el nombre Employee (tabla principal) y Department (multivalor). Haga lo siguiente:
- Escriba Employee en Tabla/Vista/PA.
- Indique Department en Nombre de tabla/vistas multivalor.
- Escriba la condición de combinación entre Employee y Department en Condición de combinación, por ejemplo,
Employee.DEPTID=Department.DepartmentID.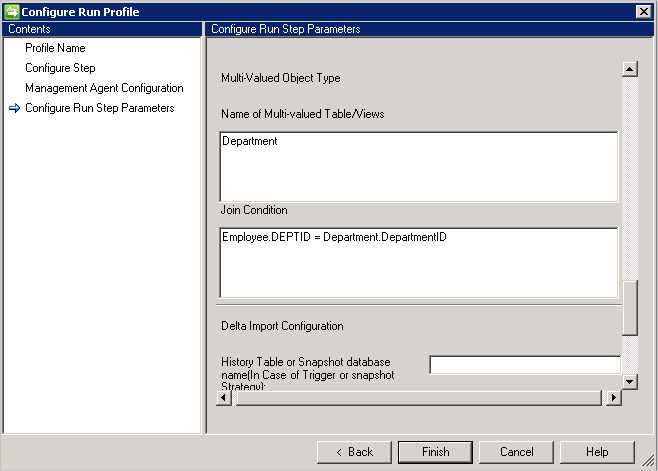
procedimientos almacenados
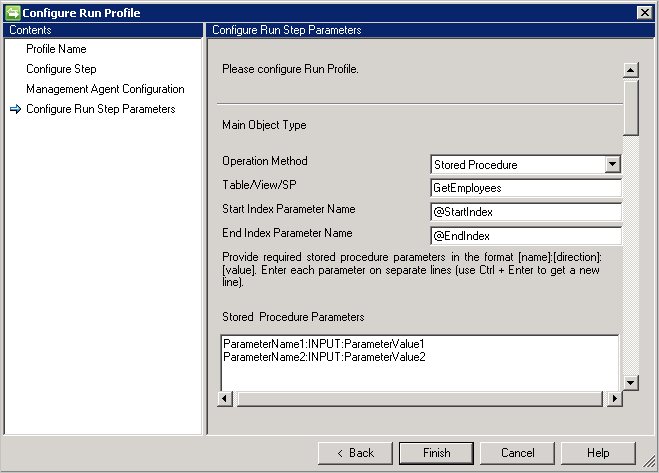
- Si tiene una gran cantidad de datos, se recomienda implementar la paginación con los procedimientos almacenados.
- Para que el procedimiento almacenado admita la paginación, debe proporcionar el índice inicial y el índice final. Consulte: Tutorial 25: Efficiently Paging Through Large Amounts of Data.
- @StartIndex y @EndIndex se reemplazan en tiempo de ejecución por el valor del tamaño de página correspondiente establecido en la página Configurar paso. Por ejemplo, cuando el conector recupera la primera página y el tamaño de página se establece en 500, en esta situación @StartIndex sería 1 y @EndIndex 500. Estos valores aumentan cuando el conector recupera las páginas siguientes y cambia el valor de @StartIndex y de @EndIndex.
- Para ejecutar el procedimiento almacenado con parámetros, proporcione estos en el formato
[Name]:[Direction]:[Value]. Escriba cada parámetro en una línea independiente (use Ctrl + Entrar para obtener una nueva línea). - El conector SQL genérico también admite la operación de importación desde los servidores vinculados de Microsoft SQL Server. Si la información debe recuperarse de una tabla en un servidor vinculado, es necesario proporcionar la tabla en el formato:
[ServerName].[Database].[Schema].[TableName] - El conector de SQL genérico admite únicamente los objetos que tienen una estructura similar (tanto nombre de alias como tipo de datos) entre la información de pasos de ejecución y la detección del esquema. Si el objeto seleccionado en el esquema y la información proporcionada en el paso de ejecución es diferente, el conector de SQL no puede admitir este tipo de escenarios.
Consulta SQL
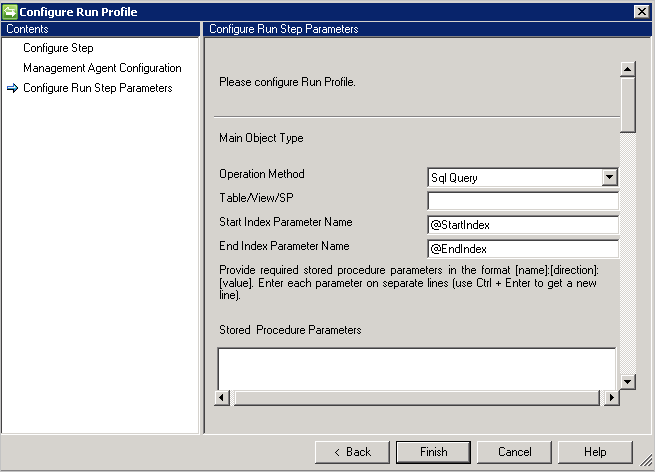
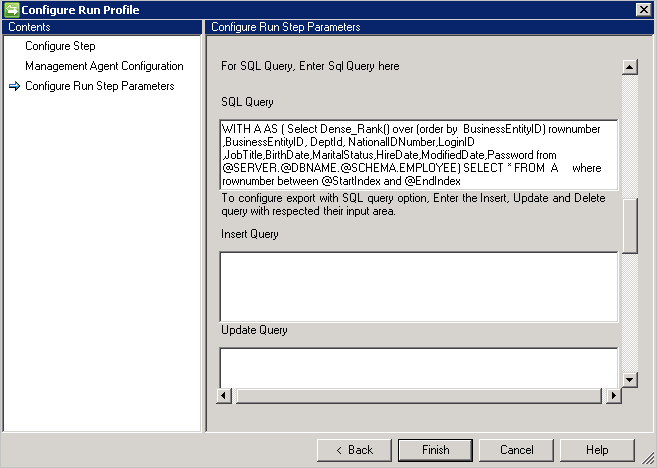
Importante
CRLF o nuevo carácter de línea actúa como separador entre varias instrucciones.
Consulta SQL de ejemplo con paginación: consulta incorrecta, no funcionará cuando se use el nuevo carácter de línea:
WITH A AS
(select dense_rank() over (order by BusinessEntityID)
rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password
from Employees
) select * from A where rownumber between @StartIndex and @EndIndex
Consulta SQL de ejemplo con paginación: consulta correcta:
WITH A AS (select dense_rank() over (order by BusinessEntityID) rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password from Employees) select * from A where rownumber between @StartIndex and @EndIndex
- No se admiten consultas de conjuntos de resultados múltiples.
- La consulta SQL admite la paginación y proporciona el índice inicial y el índice final como una variable para admitir la paginación.
Importación delta
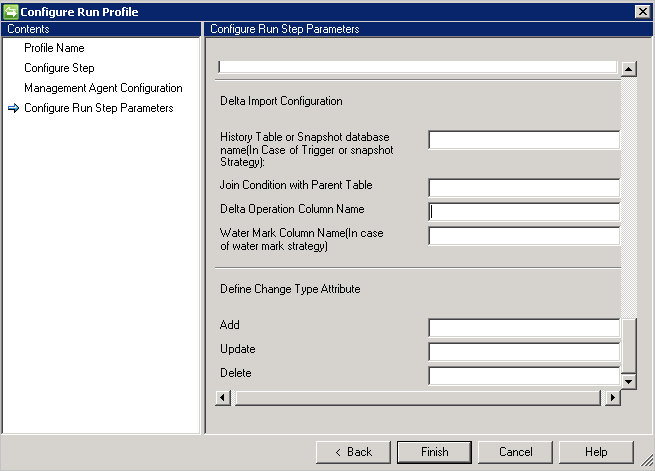
La configuración de importación condicional requiere algo más de configuración si se compara con la importación completa.
- Si elige el enfoque Trigger o Snapshot para realizar el seguimiento de los cambios diferenciales, puede indicar la base de datos de tablas o de instantáneas de historial en el cuadro Nombre de base de datos de tablas o instantáneas de historial .
- También debe proporcionar la condición de combinación entre la tabla de historial y la tabla primaria, por ejemplo
Employee.ID=History.EmployeeID - Para realizar el seguimiento de la transacción en la tabla primaria desde la tabla de historial, debe proporcionar el nombre de la columna que contiene la información de la operación (Agregar/Actualizar/Eliminar).
- Si elige Watermark para realizar el seguimiento de los cambios diferenciales, debe proporcionar el nombre de la columna que contiene la información de la operación en Water Mark Column Name(Nombre de columna de marca de agua).
- La columna Atributo de tipo de modificación es necesaria para el tipo de cambio. Esta columna asigna un cambio que se produce en la tabla principal o una tabla multivalor a un tipo de cambio en la vista diferencial. Puede contener el tipo de cambio Modify_Attribute para un cambio de nivel de atributo o un tipo de cambio Agregar, Modificar o Eliminar para un tipo de cambio de nivel de objeto. Si se trata de algo distinto al valor predeterminado de Agregar, Modificar o Eliminar, puede definir estos valores mediante esta opción.
Exportación
El conector de SQL genérico admite la exportación mediante cuatro métodos compatibles como:
- Tabla
- Ver
- Procedimiento almacenado
- Consulta SQL
Tabla o vista
Si elige la opción de tabla o vista, el conector genera las consultas correspondientes para realizar la exportación.
procedimientos almacenados
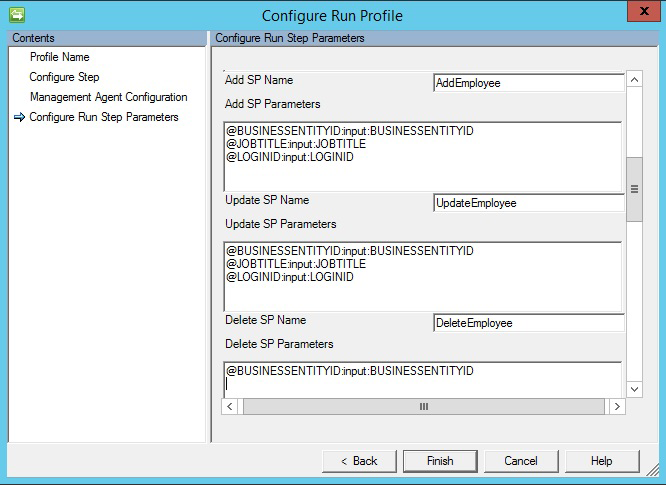
Si elige la opción Procedimiento almacenado, la exportación requiere tres procedimientos almacenados diferentes para realizar las distintas operaciones de inserción, actualización o eliminación.
- Add SP Name(Agregar nombre de PA): este procedimiento almacenado se ejecuta si se trata de cualquier objeto que llega al conector para su inserción en la tabla correspondiente.
- Update SP Name(Actualizar nombre de PA): este procedimiento almacenado se ejecuta si se trata de cualquier objeto que llega al conector para su actualización en la tabla correspondiente.
- Delete SP Name(Eliminar nombre de PA): este procedimiento almacenado se ejecuta si se trata de cualquier objeto que llega al conector para su eliminación en la tabla correspondiente.
- Atributo seleccionado en el esquema usado como valor de parámetro para el procedimiento almacenado. Por ejemplo,
@EmployeeName: INPUT: EmployeeName(EmployeeName está seleccionado en el esquema del conector y el conector reemplaza el valor correspondiente al realizar la exportación) - Para ejecutar el procedimiento almacenado con parámetros, proporcione estos en el formato
[Name]:[Direction]:[Value]. Escriba cada parámetro en una línea independiente (use Ctrl + Entrar para obtener una nueva línea).
SQL query
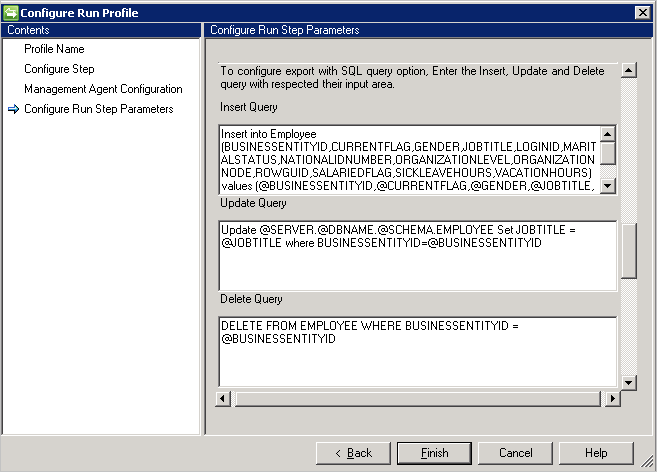
Si elige la opción Consulta SQL, la exportación requiere tres consultas diferentes para realizar las distintas operaciones de inserción, actualización o eliminación.
- Consulta de inserción: esta consulta se ejecuta si se trata de cualquier objeto que llega al conector para su inserción en la tabla correspondiente.
- Consulta de actualización: esta consulta se ejecuta si se trata de cualquier objeto que llega al conector para su actualización en la tabla correspondiente.
- Consulta de eliminación: esta consulta se ejecuta si se trata de cualquier objeto que llega al conector para su eliminación en la tabla correspondiente.
- Atributo seleccionado en el esquema usado como valor de parámetro para la consulta, por ejemplo
Insert into Employee (ID, Name) Values (@ID, @EmployeeName)
Importante
CRLF o nuevo carácter de línea actúa como separador entre varias instrucciones.
Consulta SQL de actualización de varios pasos de ejemplo: el nuevo carácter de línea se usa para separar instrucciones SQL:
update Employee set jobTitle=@JOBTITLE where BusinessEntityID=@BUSINESSENTITYID
insert into ChangeLog VALUES (@BUSINESSENTITYID)
Solución de problemas
- Para más información acerca de cómo habilitar el registro para solucionar problemas del conector, consulte How to Enable ETW Tracing for FIM 2010 R2 Connectors.