Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Debido a ejemplos complejos, este artículo utiliza algunos operadores personalizados específicos como DURATIONCALENDAR o FIRSTIF. No se requieren conocimientos específicos de estos operadores.
Para ver ejemplos sencillos de cómo crear métricas personalizadas, vaya a Ejemplos básicos.
Recapitulación de ejemplos anteriores
La siguiente tabla proporciona descripciones y ejemplos de métricas personalizadas.
| Descripción | Ejemplo |
|---|---|
| Agregación por valor de atributo (Por ejemplo, resultado por actividad = todos los eventos con el mismo valor de actividad) |
AVG(Duration()) AVG(EventsPerAttribute, Duration()) AVG(EdgesPerAttribute, Duration()) |
| Agregación dentro de los casos (resultado por caso individual) |
AVG(CaseEvents, Duration()) |
| Agregación sobre casos (agregación por valor de atributo, el caso se toma en el cálculo una vez) |
SUM(CasesPerAttribute, invoTotal) AVG(CasesPerAttribute, Duration()) |
| Agregación mundial (sobre todos los elementos a la vista/proceso/regla de negocio) |
COUNTIF(ProcessEvents, user == "Peter") AVG(ProcessEvents, Duration()) |
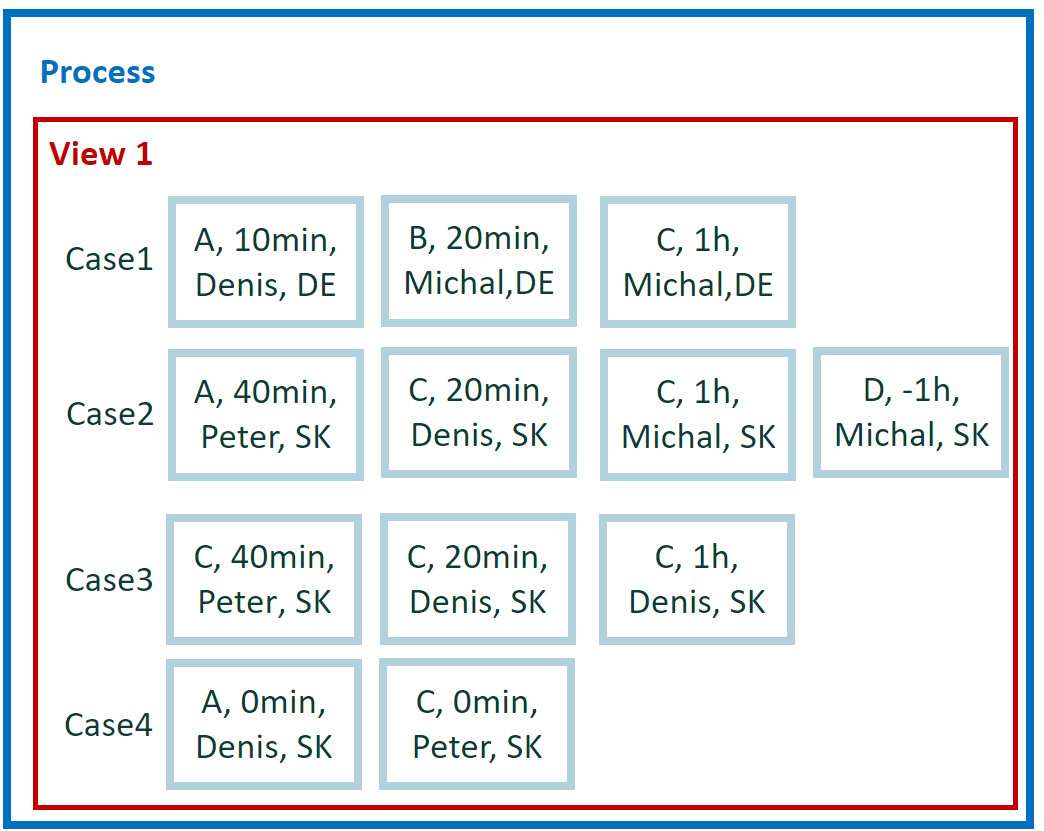
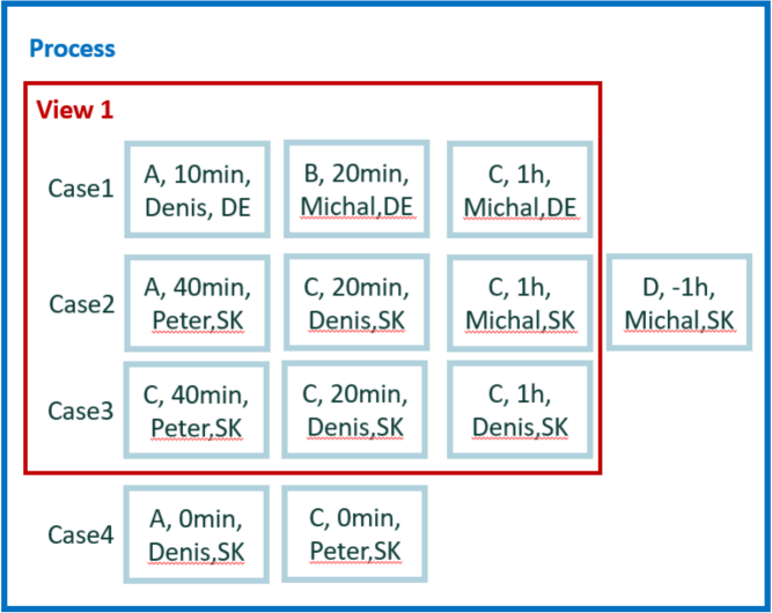
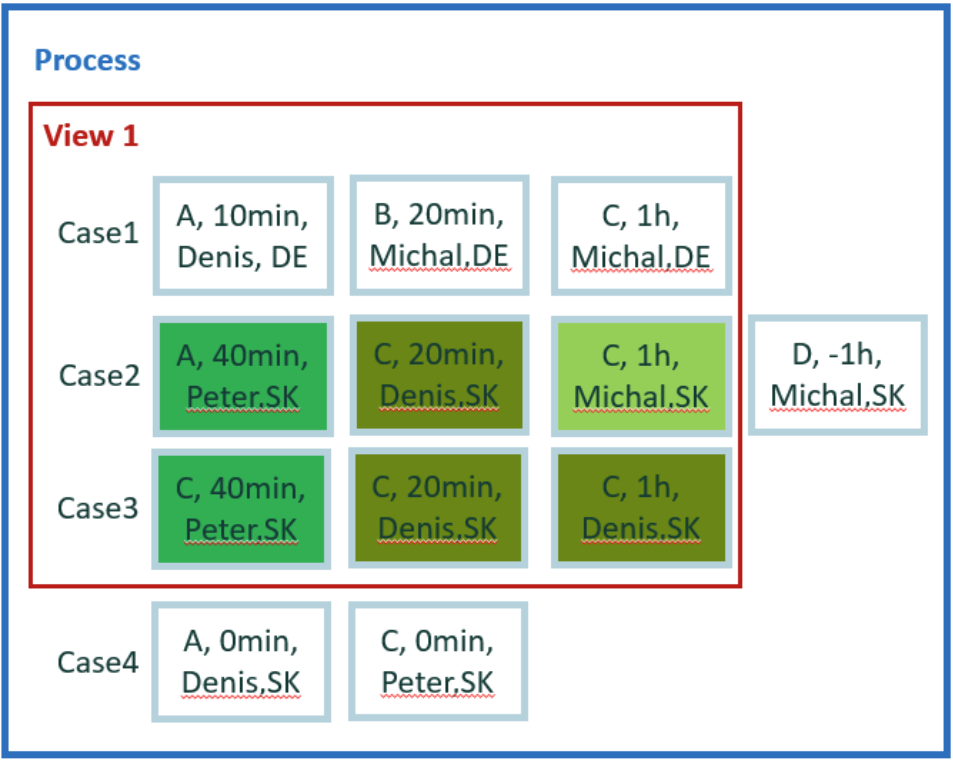
Descripción del conjunto de datos
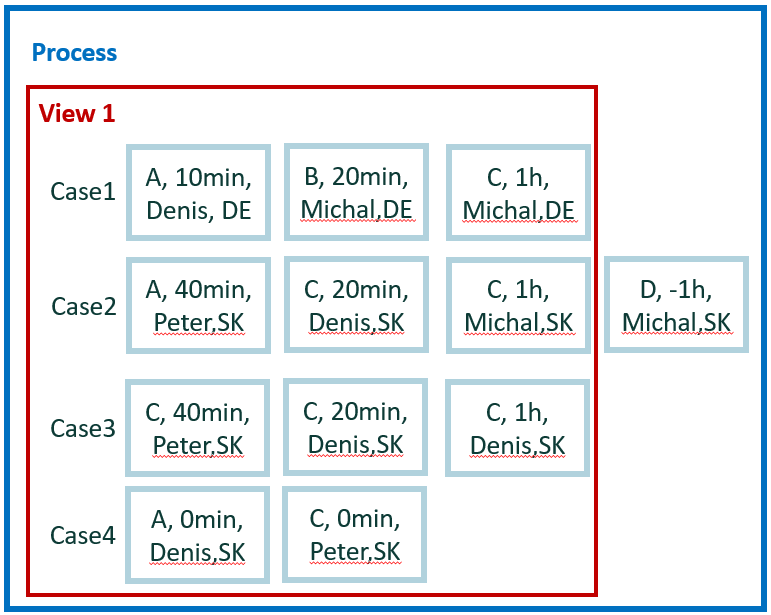
El nuevo pequeño conjunto de datos se usa para facilitar el cálculo de los ejemplos restantes. Contiene cuatro casos y 12 eventos.
Para cálculos manuales sencillos, asumimos cero tiempo de espera entre eventos. Por lo tanto, la duración del caso es la simple suma de la duración de los eventos. Además, no hay paralelismo entre los eventos.
En total, tenemos cinco atributos: actividad, inicio, fin, usuario y condado. El país es un atributo a nivel de caso. Los otros atributos son a nivel de evento.
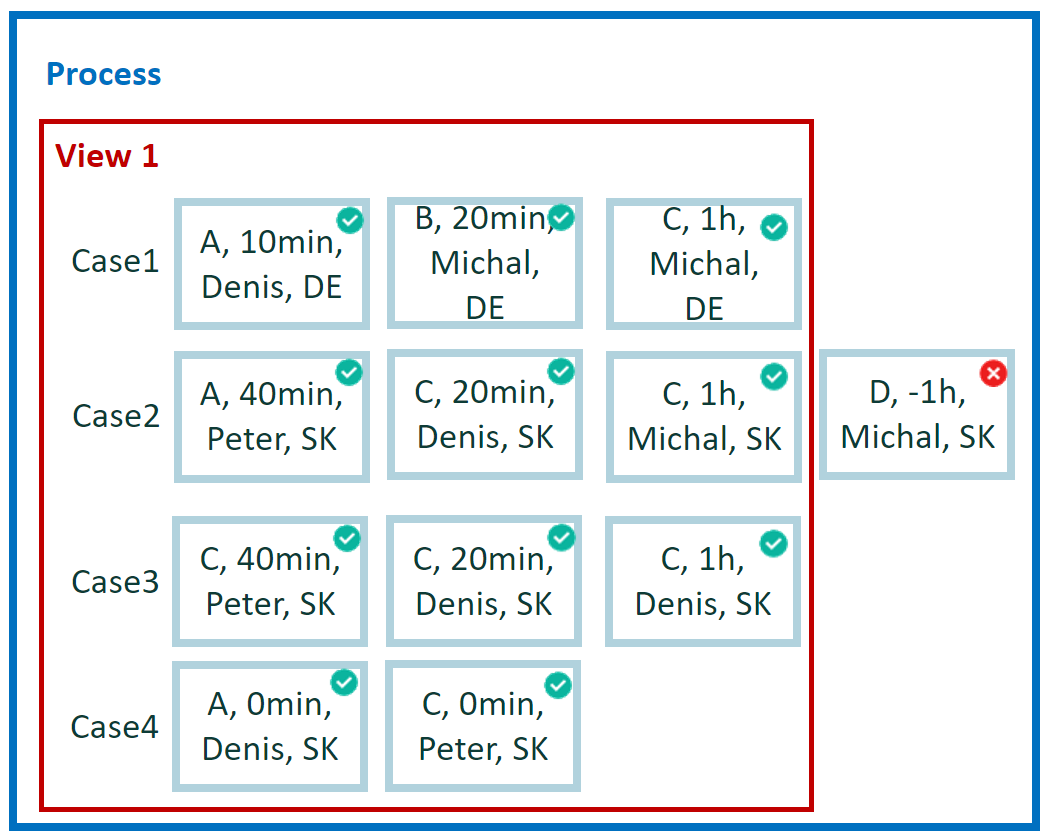
1 No agregación a nivel de evento
¿Cómo filtro a través de eventos CM con duración positiva? Evalúe eventos individuales y elimine los que tengan marcas de tiempo dañadas.
Cálculo para el ejemplo 1
Ejecute y evalúe cada evento uno por uno. Genere un solo resultado por evento. No se requiere ninguna operación de agregación. Compare los valores de los atributos de inicio y fin en cada evento.
Resultado del ejemplo 1
Por cada evento:
- 1x False
- 11x True
Expresión en el editor de métricas de personalización
Uso para el ejemplo 1
Como tenemos un solo resultado por cada evento en la vista actual, los resultados solo están disponibles en las pantallas que muestran y procesan la métrica del evento:
Filtro de métricas de evento
Filtro de métricas de caso
El filtro de métricas de eventos es la opción obvia, ya que le permite filtrar eventos en función de los valores de atributos o métricas. El filtro de métricas de casos utiliza de forma predeterminada métricas a nivel de casos. También le permite seleccionar el filtro de métricas de eventos con especificaciones adicionales si todos o al menos un evento en el caso debe cumplir con la métrica de eventos. Este cambio permite que el filtro de métricas de nivel de caso cambie a métricas de nivel de evento.
Nota
Los valores de atributos de eventos también se muestran en el panel de la tabla Casos de variantes, pero esta vista solo muestra atributos de eventos y no muestra métricas de eventos.
1.1 No agregación a nivel de evento (alternativa)
Alternativa: ¿Cómo filtro a través de eventos CM con duración negativa? En lugar de utilizar los atributos 'fin' e 'inicio', escriba la expresión utilizando métricas genéricas.
Es un procedimiento recomendado el usar métricas genéricas en lugar de atributos de proceso.
Mayor rendimiento
Portabilidad
Una fórmula se adapta a más aplicaciones (por ejemplo, descripción general de casos y análisis de causa raíz)
La forma agregada funciona con caso/evento/transición
Expresión en el editor de métricas de personalización
2 No agregación a nivel de caso
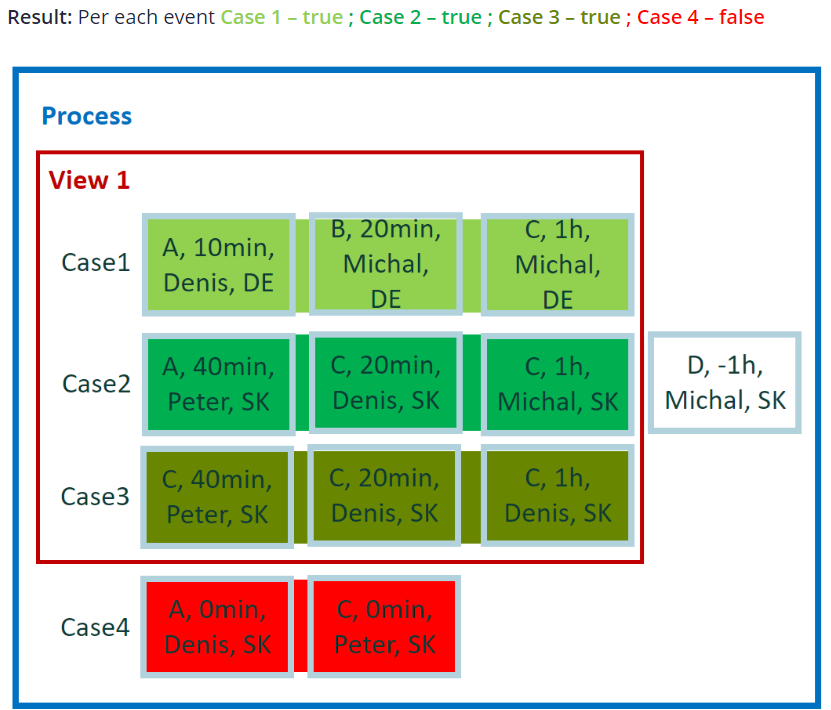
¿Cómo filtro los casos con duración vacía (cero)? Después de eliminar los eventos corruptos, debe deshacerse de los casos no válidos. Quitar casos completos con duración cero.
Cálculo para el ejemplo 2
Ejecute y evalúe cada caso uno por uno. Genere un solo resultado por caso. Dado que existe el operador Duration(), que se aplica a nivel de caso, no se requiere ninguna operación de agregación.
Resultado del ejemplo 2
Por cada evento:
- Caso 1 - verdadero
- Caso 2 - verdadero
- Caso 3 - verdadero
- Caso 4 - falso
Expresión en el editor de métricas de personalización
Uso para el ejemplo 2
Como tiene un solo resultado por caso, los resultados solo están disponibles en las pantallas que muestran los resultados por caso:
Filtro de métricas de caso
Información general de estadísticas de casos
Análisis de la causa raíz
Filtro de métricas de evento
El uso de la métrica a nivel de caso (agregada o no agregada) en la descripción general de casos de estadísticas, el análisis de causa raíz o el filtro de métricas de casos no es una sorpresa.
Para responder por qué hay una indicación de uso para Métricas de eventos, no ofrece ninguna configuración avanzada para cambiar al nivel de caso. La respuesta está en la fórmula de expresión, que utiliza el operador Duration(). La aplicación de escritorio Power Automate Process Mining ofrece el mismo operador Duration() para eventos y casos. Por lo tanto, la misma expresión es aplicable tanto a nivel de caso como de evento.
3 Agregación de transición
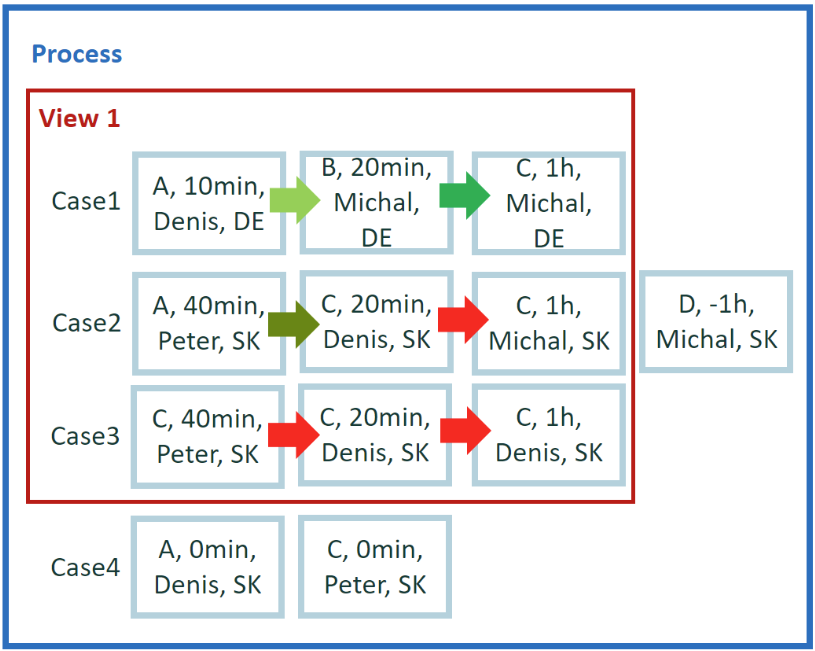
¿Cuál es el número de cambios de usuario por ruta (transición)? En lugar de buscar valores de eventos, preguntará por los cambios ocurridos entre eventos. Así que está buscando resultado por transición.
Edge (path)
: transición entre dos eventos seguidos directamente.

Cálculo para el ejemplo 3
Está evaluando la frecuencia con la que ha cambiado cuando el caso avanzaba a través de los eventos. Quiere identificar en qué transiciones (bordes) ocurre el cambio de usuario. Primero, identifique un conjunto de transiciones en nuestros datos. Para el caso 1, hay dos transiciones A->B y B->C. En el caso 2 tenemos A->C y C->C. Para el caso 3, solo tiene una transición C->C. En total, tiene cuatro (4) transiciones únicas (basadas en valores de actividad) - A->B, B->C, A->C y C->C. Por cada una de estas transiciones, necesita agregar el número de cambios de usuario. Por ejemplo, solo tiene una instancia del borde B->C donde el usuario Michal en el evento de inicio y también en el evento de finalización, por lo que no hay ningún cambio de usuario para este borde.
Resultado del ejemplo 3
- A->B = 1
- B->C = 0
- A->C = 1
- C->C = 2
Expresión en el editor de métricas de personalización

Los operadores TARGET() y SOURCE() devuelven los valores del atributo solicitado para el nodo inicial y final al borde real.
Uso para el ejemplo 3
Las métricas personalizadas definidas generan un valor de resultado por transición (atributo), por lo que es aplicable en todas partes cuando se utilizan resultados agregados por transición:
Bordes de la representación del proceso
Estadísticas de transiciones
Filtro condicional de borde
4 Agregación de eventos de caso II
En la sección anterior, tuvo un ejemplo simple del uso de la agregación CaseEvents. Aquí tomará otro ejemplo con una fórmula más compleja.
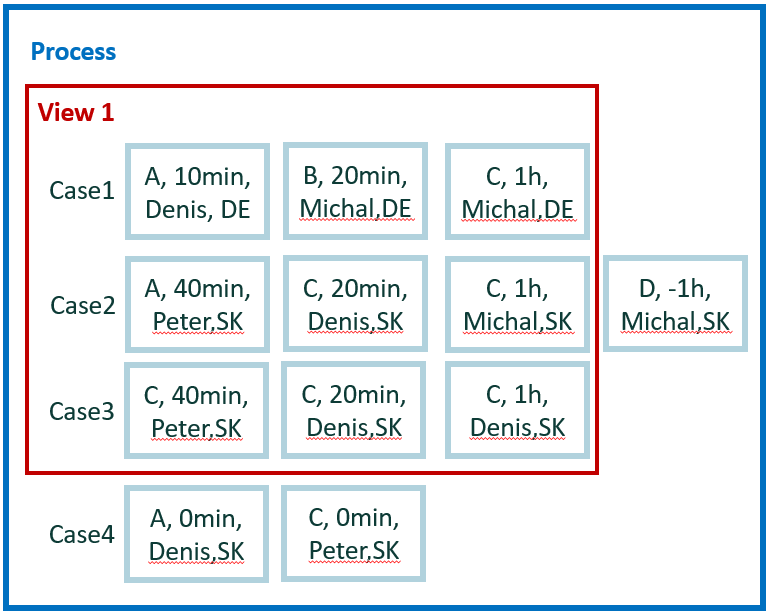
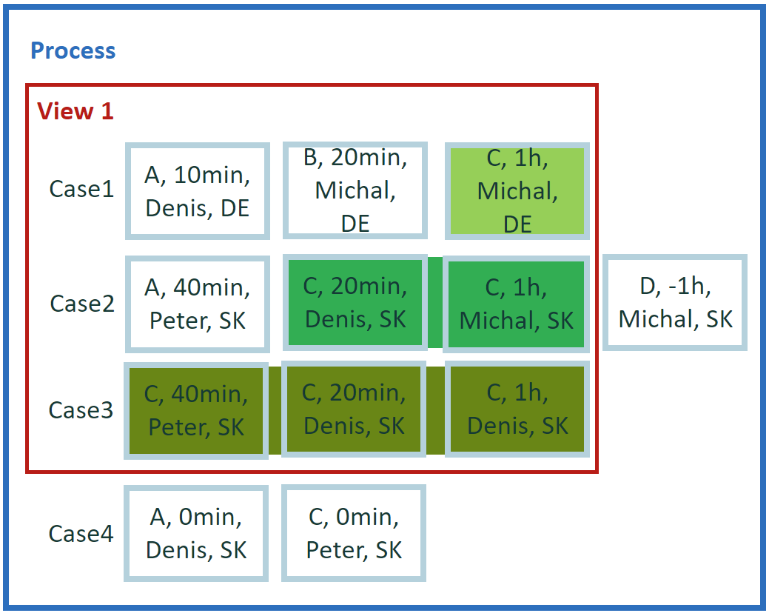
¿Cuál es la duración desde el inicio de la primera C y la actividad final de la última C en los casos? Busca un resultado por caso y hacemos una agregación condicional sobre los eventos del caso.
Cálculo para el ejemplo 4
Ejecute todos los eventos disponibles dentro de su caso. Obtenga la primera y la última actividad 'C' en un caso y mida la duración entre el inicio de la primera y el final de la última.
Resultado del ejemplo 4
- Caso 1 = 1 hora 00 minutos
- Caso 2 = 1 hora 20 minutos
- Caso 3 = 2 horas 00 minutos
Expresión en el editor de métricas de personalización
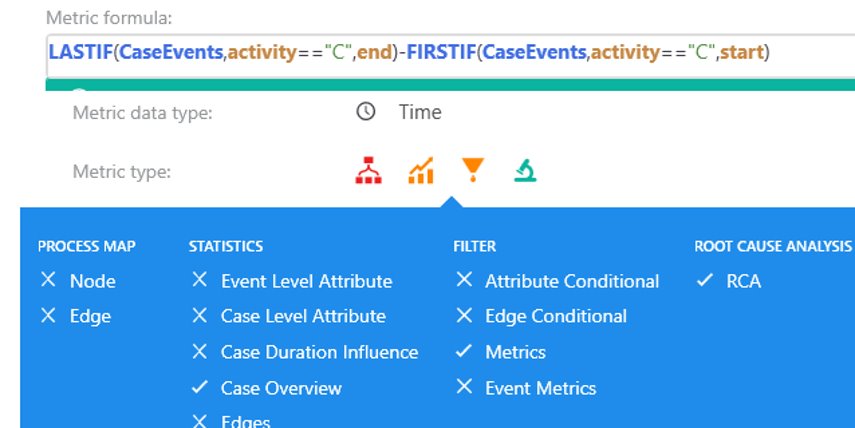
Esta vez, la expresión es un poco más complicada, pero muestra cómo combinar múltiples agregaciones en una sola fórmula. Los operadores FIRSTIF() y LASTIF() son operadores de agregación, que devuelven el primer/último evento en función de los criterios de entrada sobre el alcance de cálculo definido (esta vez CaseEvents).
Uso para el ejemplo 4
La aplicación de la métrica personalizada sigue los requisitos estándar para la agregación de casos únicos (independientemente de la complejidad de la expresión).
4.1 Agregación de eventos de caso II (alternativa)
¿Cuál es la duración desde el inicio de la primera C y la actividad final de la última C, pero calculada solo durante las horas de trabajo? El ejemplo es el mismo que el anterior, pero aquí quiere calcular la diferencia horaria solo sobre las horas de trabajo. Anteriormente, la simple diferencia entre los valores de marca de tiempo era suficiente.
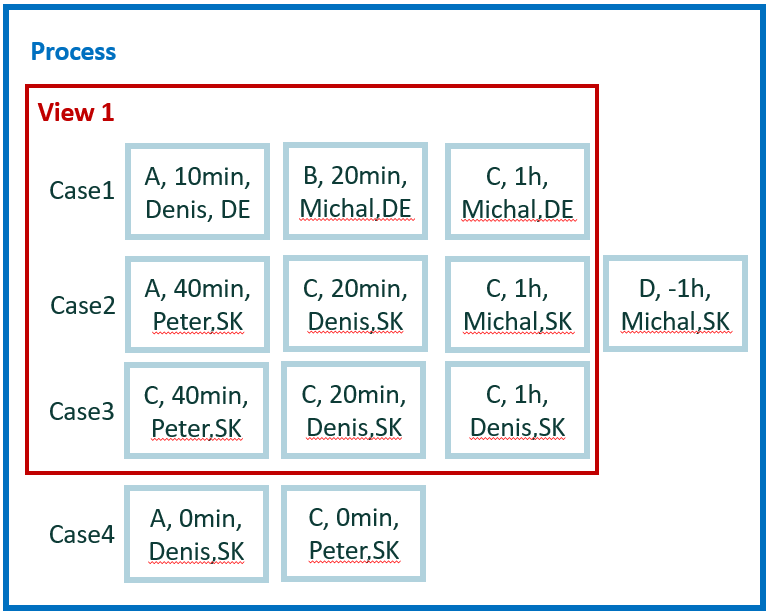
Cálculo para el ejemplo 4.1
Ejecute todos los eventos disponibles dentro de su caso. Obtenga la primera y la última actividad 'C' en un caso y mida la duración entre el inicio de la primera y el final de la última. Para medir la duración, utilice las horas de trabajo definidas en el calendario aplicado.
Resultado del ejemplo 4.1
- Caso 1 = ???
- Caso 2 = ???
- Caso 3 = ???
Expresión en el editor de métricas de personalización
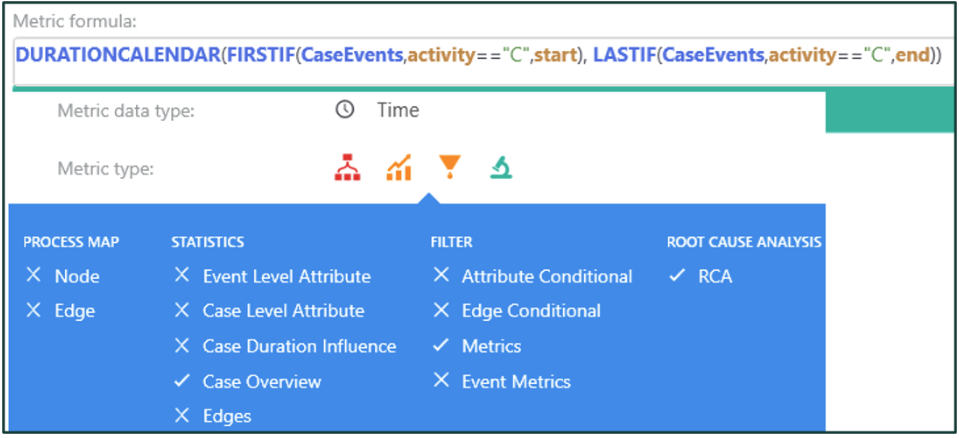
Para calcular la duración sobre la jornada laboral, se han usado los operadores DURATIONCALENDAR(). Los operadores para encontrar el primer y el último evento son argumentos de operador que crean una expresión anidada. Tenga en cuenta que la complejidad de la expresión no afecta ni modifica los ámbitos de cálculo seleccionados.
Uso para el ejemplo 4.1
La aplicación de la métrica personalizada sigue los requisitos estándar para la agregación de casos únicos, independientemente de la complejidad de la expresión.
5 Resultados categóricos vs. cuantitativos
¿El caso contiene la ruta C->C? Esta es una pregunta simple, cuando necesita categorizar casos individuales según la transición de existencia C->C.
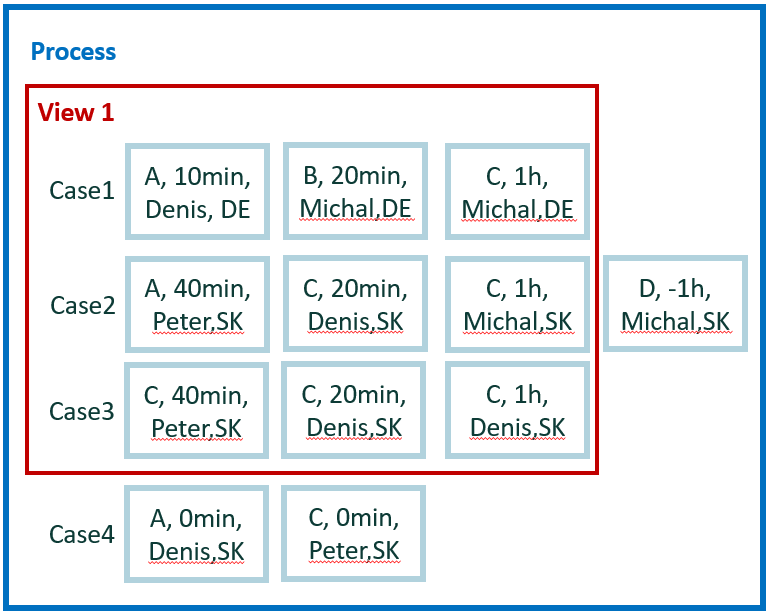
Cálculo para el ejemplo 5
Ejecute todas las transiciones disponibles dentro de su caso. Si el caso contiene la transición C->C, pasa los criterios. Los resultados se generan por caso. La cuenta de tales transiciones no es importante.
Resultado del ejemplo 5
- Caso 1 = Falso
- Caso 2 = Verdadero
- Caso 3 = Verdadero
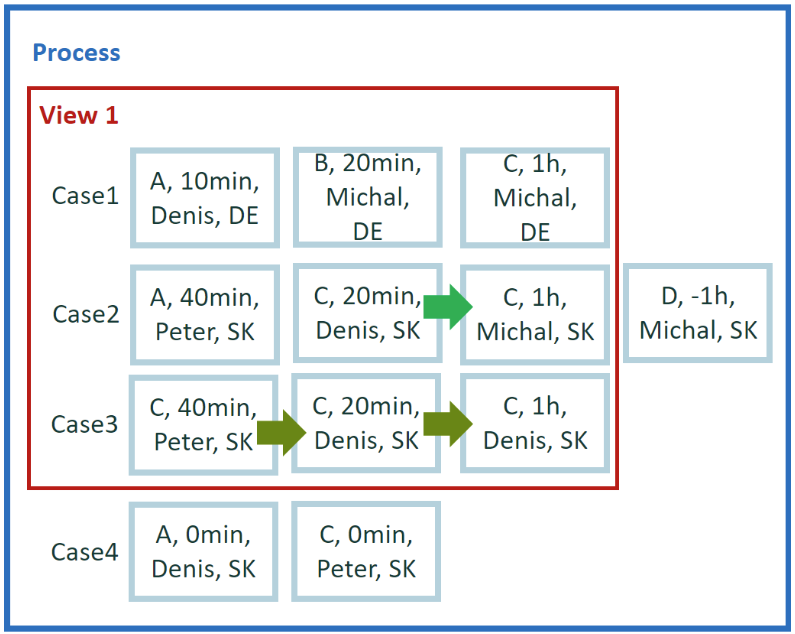
Expresión en el editor de métricas de personalización

El operador ANY() devuelve un valor booleano verdadero/falso cuando al menos un elemento en un contexto determinado cumple los criterios. Vea también el operador ALL()*k devuelve un valor verdadero cuando todos los elementos del contexto dado cumplen los criterios.
Uso para el ejemplo 5
La aplicación de la métrica personalizada sigue los requisitos estándar para la agregación de casos únicos:
Filtro de métricas de caso
Análisis de la causa raíz
Panel de estadísticas de información general de casosTransición
5.1 Resultados categóricos vs. cuantitativos (alternativa)
¿Cuántas rutas C->C están dentro del caso? Cambie la pregunta anterior de si el caso contiene la transición C->C a cuántas de esas transiciones hay.
Cálculo en el ejemplo 5.1
Ejecute todas las transiciones dentro de su caso. Cuente cualquier transición C->C encontrada. Si no se encuentra tal transición, el recuento es cero para el caso dado.
Resultado en el ejemplo 5.1
- Caso 1 = 0
- Caso 2 = 1
- Caso 3 = 2
Expresión en el editor de métricas de personalización

En comparación con la fórmula anterior, acaba de reemplazar el operador ANY() con COUNTIF().
Uso para el ejemplo 5.1
La aplicación de la métrica personalizada sigue los requisitos estándar para la agregación de casos únicos.
6 Agregación de casos de eventos o transiciones utilizando el contexto de la totalidad del caso
¿Cuántos casos en DE contienen la transición C->C? Esta solicitud contiene dos valores. El primero es el valor del atributo de país o región 'DE' y el segundo es el valor de la transición 'C->C'.
La limitación para el borde 'C->C' describe el requisito de dominio y por qué el país o región 'DE' es uno de los valores de atributo.
Cálculo para el ejemplo 6
¿Por qué no calcular el resultado para todos los países o regiones? Al principio, reconsidere la pregunta original. Es posible generar resultados por valor de atributo (por ejemplo, para el país o región del atributo), pero no hay forma (excepto para las reglas comerciales) de crear un cálculo para un valor de atributo único. En su uso de reglas comerciales, puede omitir esta sección. Sabiendo esto, puede actualizar la pregunta original a la forma genérica:
¿Cuántos casos contiene la transición C->C por país o región?
Ahora el cálculo consta de dos pasos. Al principio, analice cada caso y compruebe la existencia de transiciones 'C->C'. El número exacto de transiciones 'C->C' en el caso no es importante. Luego, en el segundo paso, agregue los resultados por caso individual según un valor del país o región del atributo de nivel de caso. Hay dos valores 'DE' y 'SK', por lo que habrá dos resultados.
Ambos casos para el atributo de país o región 'SK' contienen la transición 'C->C', por lo que el resultado para 'SK' es 2. El número total de transiciones es 3, pero no contamos el número de transiciones.
Resultado del ejemplo 6
- DE = 0
- SK = 2
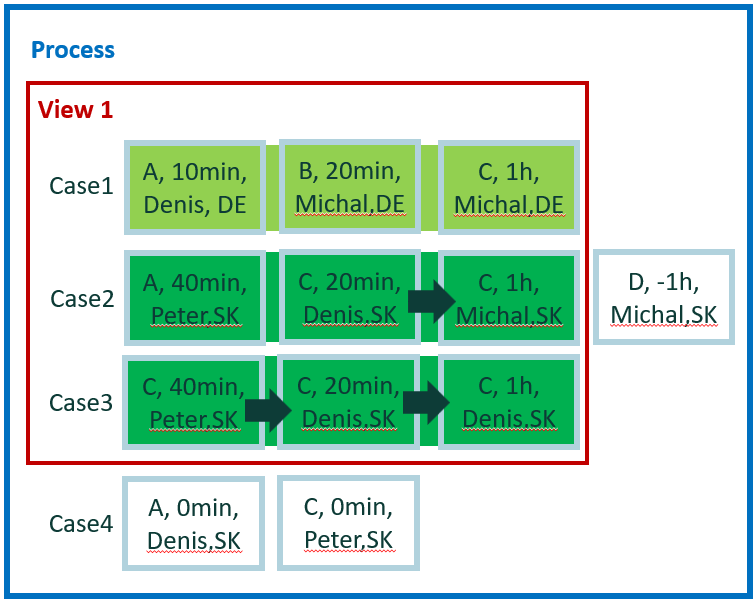
Expresión en el editor de métricas de personalización
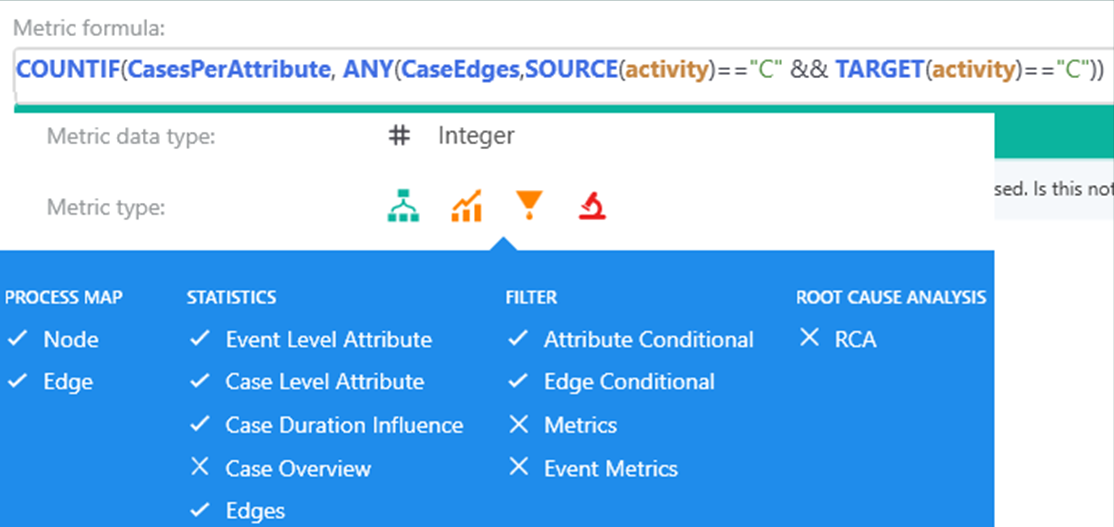
La fórmula anidada contiene una agregación de dos pasos. El interior ejecuta todas las transiciones del caso. El exterior agrega casos por valor de atributo. La agregación externa usa context CasesPerAttribute porque el resultado por caso es exactamente uno. El contexto EventsPerAttribute también agrupa el resultado por valor de atributo, pero puede involucrar el mismo caso varias veces, por cada evento involucrado, en el resultado.
Uso para el ejemplo 6
La métrica personalizada es aplicable en todas las pantallas donde los valores se muestran por valor de atributo. El valor del atributo se puede agrupar utilizando el contexto de nivel de evento (EventsPerAttribute) o de nivel de caso (CasesPerAttribute). Estos dos contextos de cálculo proporcionan un cálculo diferente, pero comparten la misma aplicabilidad del cálculo (métrica personalizada):
Mapa de procesos (ambos nodos y agregaciones)
Todas las estadísticas excepto Resumen de casos, que requiere resultados por caso.
Filtro condicional de atributos y agregaciones.
Para una expresión con agregaciones anidadas, el contexto de agregación más externo determina la aplicación en la aplicación de escritorio Process Mining.
6.1 Agregación de eventos de caso o transición (alternativa)
Convierta el ejemplo anterior de evaluación categórica a cuantitativa.
¿Cuántas transiciones C->C hay en casos en DE? Convierta la pregunta en una forma genérica: ¿Cuántas transiciones C->C hay en casos por país o región?
Cálculo en el ejemplo 6.1
Una vez más, el cálculo consta de dos pasos. Al principio, analice cada caso y cuente las transiciones 'C->C'. Luego, en el segundo paso, agregue los resultados por caso individual según el valor del país o región del atributo de nivel de caso. Hay dos valores: 'DE' y 'SK', por lo que habrá dos resultados.
Ambos casos para el atributo de país o región 'SK' contienen transiciones 'C->C'. El resultado de 'SK' y el recuento total de estas transiciones es 3 (1 + 2).
Resultado en el ejemplo 6.1
- DE = 0
- SK = 3
Expresión en el editor de métricas de personalización

La expresión contiene de nuevo una agregación de dos pasos (anidada). El interno recorre todas las transiciones dentro del caso y el externo agrega casos por valor de atributo.
Uso para el ejemplo 6.1
La métrica personalizada es aplicable en todas las pantallas donde los valores se muestran por valor de atributo.
7 Cambiar de evento a contexto de caso
¿Cuál es la duración promedio de la actividad en comparación con la duración del caso? El tiempo promedio dedicado a las actividades es una de las métricas de rendimiento estándar.
Pero, ¿qué sucede si necesitamos calcular la proporción promedio de cuánto tiempo dedicamos a las actividades en comparación con la duración del caso? ¿Dónde pasamos relativamente la mayor parte del tiempo? ¿Está sobre el umbral?
Cálculo para el ejemplo 7
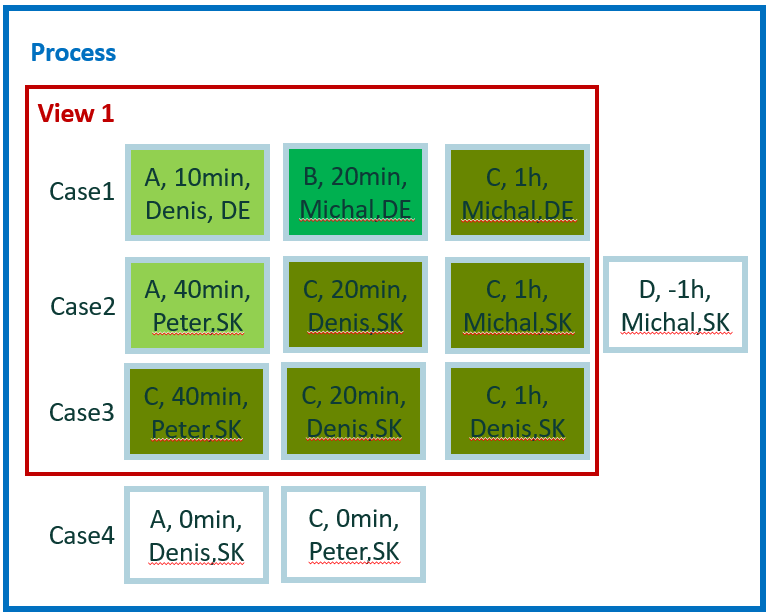
¿Qué vamos a calcular exactamente? Queremos resultados por actividad, por lo que obtenemos resultados para 'A', 'B' y 'C'. La actividad 'B' es solo en el caso 1. La duración del caso 1 es de 90 minutos y la duración de la actividad 'B' es de 20 minutos. El resultado para el caso 1 y la actividad 'B' es 20/90 = ~ 0,22. Debido a que 'B' no se incluye en otros casos, este también es el resultado final para 'B'.
Haga el cálculo para la actividad 'A', para el caso 1 la relación es 10/90, para el caso 2 la relación es 40/120, con valor promedio 0,22 (0,11 + 0,33 dividido por 2). De la misma manera, calculamos 6 resultados individuales por cada uno de los eventos 'C' y hacemos el promedio.
En términos de agregación, no es nada nuevo. Generamos resultados por valor de atributo, pero para el cálculo usamos la métrica (valor) del caso.
Resultado del ejemplo 7
- A = 0,22
- B = 0,22
- C = 0,375
Expresión en el editor de métricas de personalización
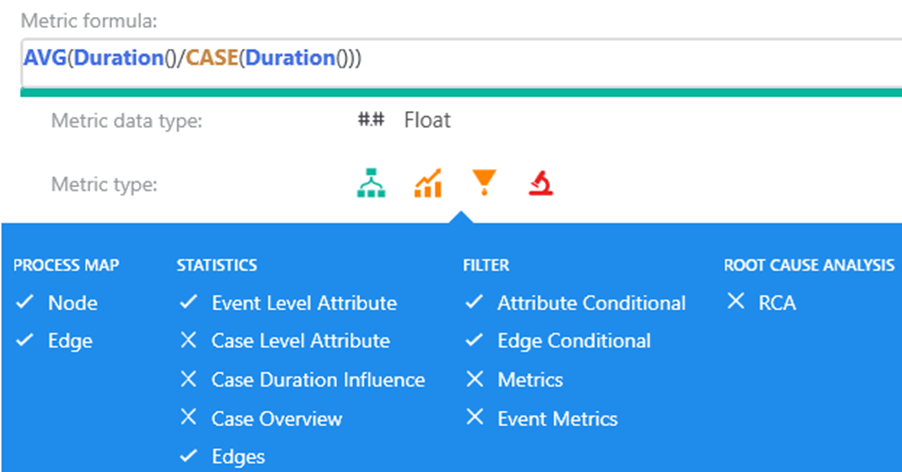
La expresión es simple, pero usa el importante operador CASE(), que le permite cambiar el contexto para el nivel de caso. Esta es la única forma de calcular las métricas de nivel de evento y solicitar métricas (valores) de su caso.
Uso para el ejemplo 7
La aplicación de la métrica personalizada sigue los requisitos estándar para la agregación por valor de atributo. Porque la expresión usa Duration() y no el valor de atributo, también es aplicable en las transiciones (tanto en la representación del proceso como en las estadísticas).
8 Agregación de eventos-caso-evento
Relación genérica entre eventos dentro del caso.
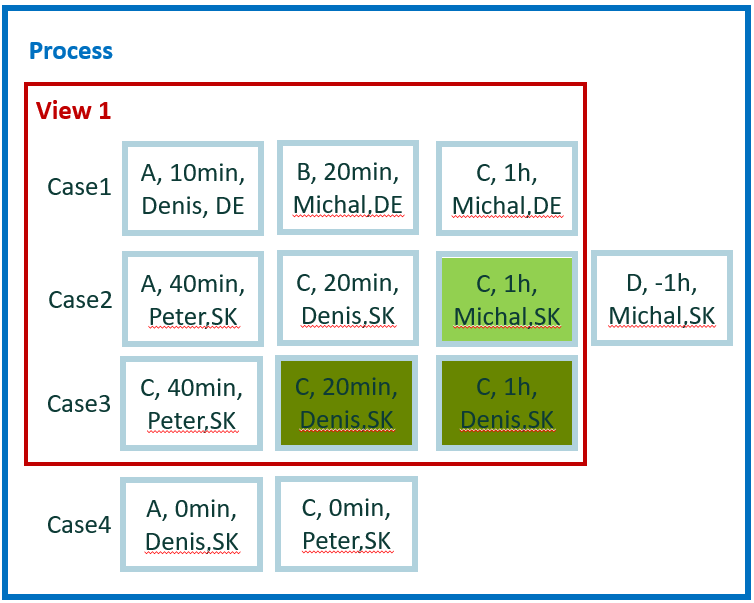
¿Cuántos eventos realizados por Mical fueron en casos tocados por Peter? Imagine que 'Peter' es un miembro senior del equipo que generalmente solo se involucra en algunos problemas. Queremos saber cuántas veces 'Peter' tuvo que realizar una acción cuando otro usuario 'Michal' estuvo involucrado en el mismo caso.
Cambie la pregunta a una forma genérica: ¿Cuántos eventos por usuario se realizaron en casos con Peter?
Cálculo en el ejemplo 8
El evento es válido para esta pregunta, si está entre mayúsculas y minúsculas, donde hay al menos un evento realizado por el usuario 'Peter'. Evalúe cada evento y agrupe los resultados por valor de usuario de atributo: 'Michal', 'Peter' y 'Denis'.
Resultado en el ejemplo 8
- Michal = 1
- Peter = 2
- Denis = 3
Expresión en el editor de métricas de personalización
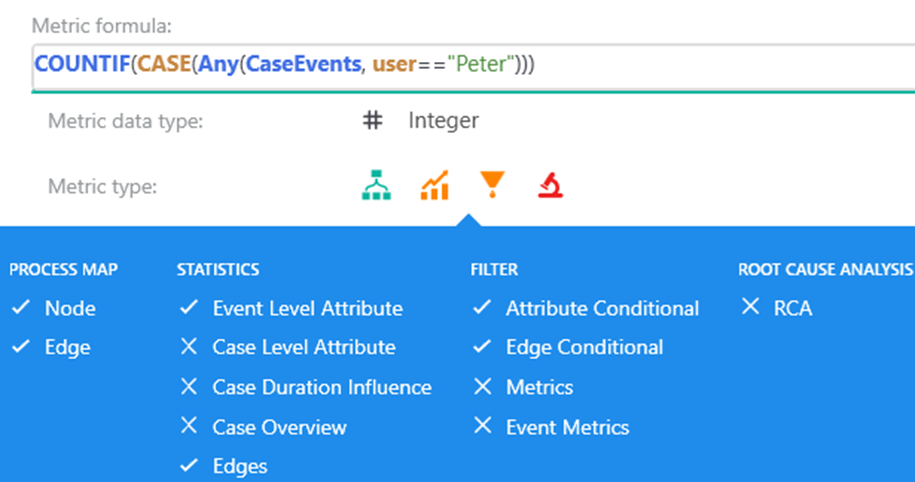
La expresión es corta pero requiere cierto conocimiento para entenderla. La parte más interior Any(CaseEvents, user=="Peter") es un resultado simple por cada caso. Evalúa si el caso contiene al usuario 'Peter' o no. La parte más exterior COUNTIF() hace una agregación simple por valor de atributo. El requisito es realizar la agregación en el usuario de atributo de nivel de evento, pero el valor calculado es la métrica de nivel de caso. El cambio entre estos dos contextos se realiza mediante CASE() operador en el medio.
Nota
En este ejemplo, el contexto EventsPerAttribute no está especificado. La métrica personalizada luego aplicó el contexto de cálculo implícito.
Uso para el ejemplo 8
La aplicación de la métrica personalizada sigue los requisitos estándar para la agregación por valor de atributo.
8.1 Agregación condicional evento-caso-evento
Relación entre dos atributos de nivel de evento dentro del caso con condición.
¿Cuántas veces Michal trabajó en C repetida con Peter en el caso? Es una pregunta similar a la anterior, pero se añade condicional.
Convierta la pregunta a genérica: ¿Cuántas veces Michal (por usuario) trabajó en casos C repetidos con Peter?
Cálculo para el ejemplo 8.1
Evalúe cada evento y agrupe los resultados por valor de usuario de atributo: 'Michal', 'Peter' y 'Denis', como en el ejemplo anterior. La evaluación de eventos es más complicada, ya que existe una limitación solo para las actividades repetidas 'C'.
En el caso 1, no hay actividades 'C' repetidas, en el caso 2 hay una actividad 'C' repetida realizada por 'Michal' y en el caso 3 hay dos actividades 'C' repetidas realizadas por 'Denis'.
Resultado del ejemplo 8.1
- Michal = 1
- Peter = 0
- Denis = 2
Expresión en el editor de métricas de personalización

Agregación de dos pasos (anidada): la interna evalúa el caso individual, la externa agrupa los resultados por valor de atributo. Las condiciones también se separan entre estos para la agregación. El interior se ocupa del requisito del caso si contiene al usuario 'Peter'. El externo agrupa eventos, por lo que contiene la condición relacionada con el evento si la actividad es 'C' y si se repite.
Operador OCCURRENCE() devuelve el índice de ocurrencia de un valor de atributo de evento dado dentro del caso.
Uso para el ejemplo 8.1
La aplicación de la métrica personalizada sigue los requisitos estándar para la agregación por valor de atributo.
9 Extra: métricas personalizadas específicas de valor
¿Es posible evitar el operador?
CASE()? ¿Hay alguna forma de simplificar las expresiones? Sí, existe, pero hay compensaciones. Consulte el siguiente ejemplo.¿Cuántos eventos realizados por Michal (por usuario) fueron en casos con Peter? La misma pregunta como en 8 Agregación evento-caso-evento.
¿Es posible responder a la pregunta sin usar el operador
CASE()?
Solución genérica usando el operador CASE()

¿Es posible saltar el operador CASE() al costo de crear una métrica personalizada específica de valor? En tal métrica personalizada, tenemos que especificar el valor personalizado solicitado 'Michal' y tener cálculos de anulación para otros valores de atributo (por usuario) y agrupar por otros atributos.
Métrica personalizada limitada a un valor personalizado específico

Razonamiento detrás de este último:
Seleccionar casos con 'Peter' (operador
ANY())Convierta el resultado booleano en cero o uno numérico (operador
IF())Cuente el número de actividades con requisito (operador
COUNTIF())Aplicar el resultado por caso por cada caso exactamente una vez (contexto de cálculo CasesPerAttribute)
Por último Sumar recuento de eventos por caso (operador
SUM())
La métrica personalizada sin el operador CASE() es quizás más fácil de leer para los humanos, pero tiene algunas desventajas.
Por cada valor de atributo resultante ("Michal"), necesitamos una métrica personalizada separada. Para otros valores de atributo, la métrica devuelve cero.
El operador
COUNTIF()está bloqueado para el atributo de usuario. Resultados agrupados por otro atributo, por ejemplo, el país o región requiere un cambio de condición a un código de país específico, por ejemplo,COUNTIF(CaseEvents, country == "DE").