Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El diseño de un modelo dimensional es una de las tareas más comunes que puede realizar con un flujo de datos. En este artículo se resaltan algunos de los procedimientos recomendados para crear un modelo dimensional mediante un flujo de datos.
Flujos de datos de almacenamiento provisional
Uno de los puntos clave de cualquier sistema de integración de datos es reducir el número de lecturas del sistema operativo de origen. En la arquitectura de integración de datos tradicional, esta reducción se realiza mediante la creación de una nueva base de datos denominada base de datos de almacenamiento provisional. El propósito de la base de datos de almacenamiento provisional es cargar datos as-is desde el origen de datos en la base de datos de almacenamiento provisional según una programación normal.
A continuación, el resto de la integración de datos usa la base de datos de almacenamiento provisional como origen para su posterior transformación y la convierte en la estructura del modelo dimensional.
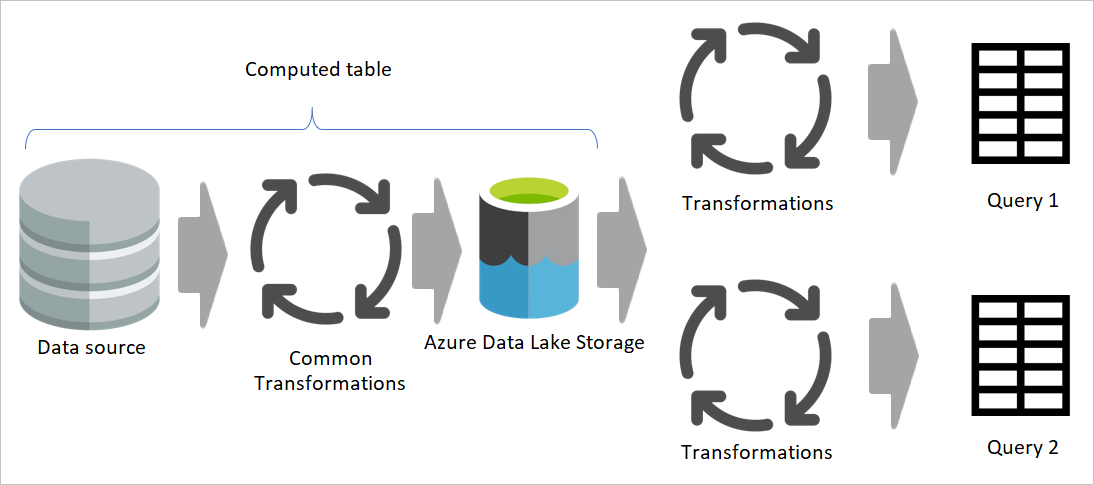
Se recomienda seguir el mismo enfoque mediante flujos de datos. Cree un conjunto de flujos de datos responsables de cargar solo los datos as-is desde el sistema de origen (y solo para las tablas que necesite). A continuación, el resultado se almacena en la estructura de almacenamiento del flujo de datos (Azure Data Lake Storage o Dataverse). Este cambio garantiza que la operación de lectura del sistema de origen sea mínima.
A continuación, puede crear otros flujos de datos que obtengan sus datos de flujos de datos intermedios. Entre las ventajas de este enfoque se incluyen:
- Reducir el número de operaciones de lectura del sistema de origen y reducir la carga en el sistema de origen como resultado.
- Reducir la carga en las puertas de enlace de datos si se utiliza un origen de datos local.
- Tener una copia intermedia de los datos con fines de conciliación, en caso de que los datos del sistema de origen cambien.
- Hacer que los flujos de datos de transformación sean independientes del origen.
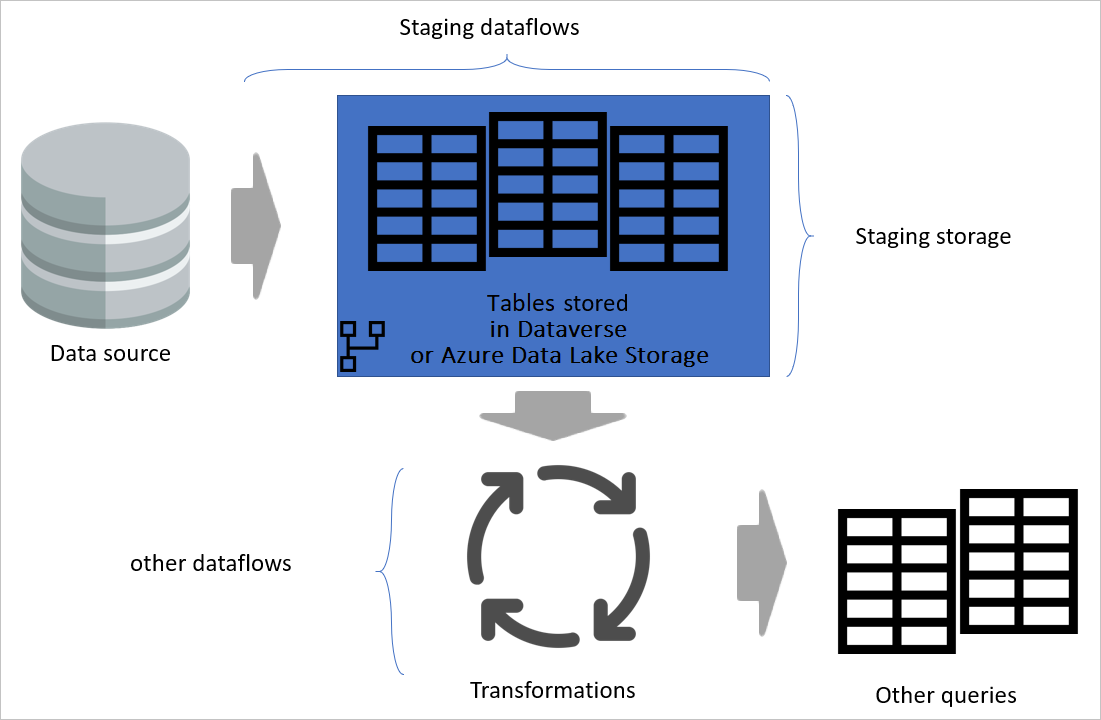
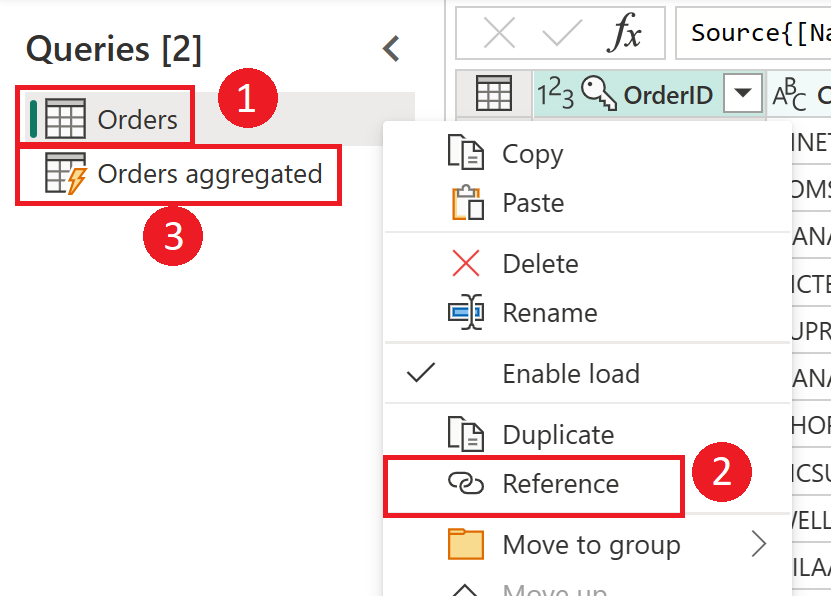
Diagrama que enfatiza los flujos de datos provisionales y el almacenamiento provisional. En el diagrama se muestra el acceso a los datos desde el origen de datos mediante el flujo de datos provisional y las tablas que se almacenan en Cadavers o Azure Data Lake Storage. A continuación, se muestran las tablas que se transforman junto con otros flujos de datos, que luego se envían como consultas.
Flujos de datos de transformación
Al separar los flujos de datos de transformación de los flujos de datos de almacenamiento provisional, la transformación es independiente del origen. Esta separación ayuda si va a migrar el sistema de origen a un nuevo sistema. Todo lo que debe hacer en ese caso es cambiar los flujos de datos de preparación. Es probable que los flujos de datos de transformación funcionen sin ningún problema porque solo se originan a partir de los flujos de datos de almacenamiento provisional.
Esta separación también ayuda en caso de que la conexión del sistema de origen sea lenta. El flujo de datos de transformación no necesita esperar mucho tiempo para recibir registros que llegan mediante una conexión lenta desde el sistema de origen. El flujo de datos de preparación ya hizo esa parte y los datos están listos para la capa de transformación.
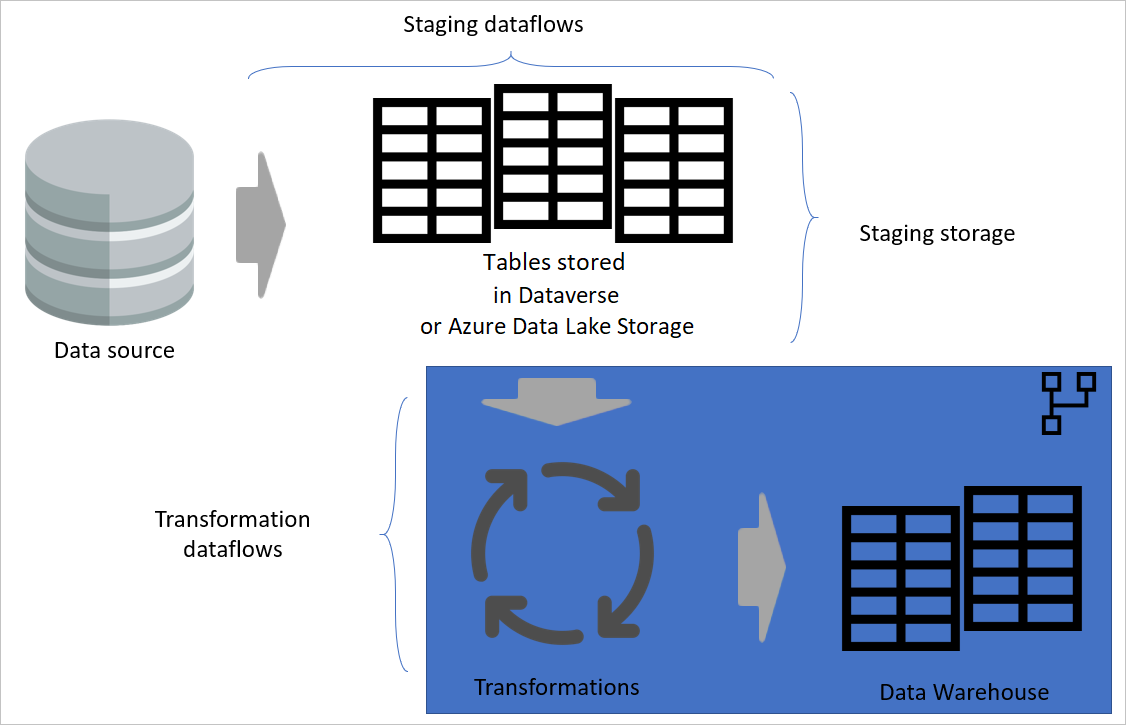
Arquitectura superpuesta
Una arquitectura superpuesta es una arquitectura en la que se realizan acciones en capas independientes. Los flujos de datos de almacenamiento provisional y transformación pueden ser dos capas de una arquitectura de flujo de datos multicapa. Intentar realizar acciones en capas garantiza el mantenimiento mínimo necesario. Cuando quiera cambiar algo, solo tiene que cambiarlo en la capa donde se encuentra. Las demás capas deben seguir funcionando bien.
En la imagen siguiente se muestra una arquitectura multicapa para flujos de datos en los que se usan sus tablas en modelos semánticos de Power BI.
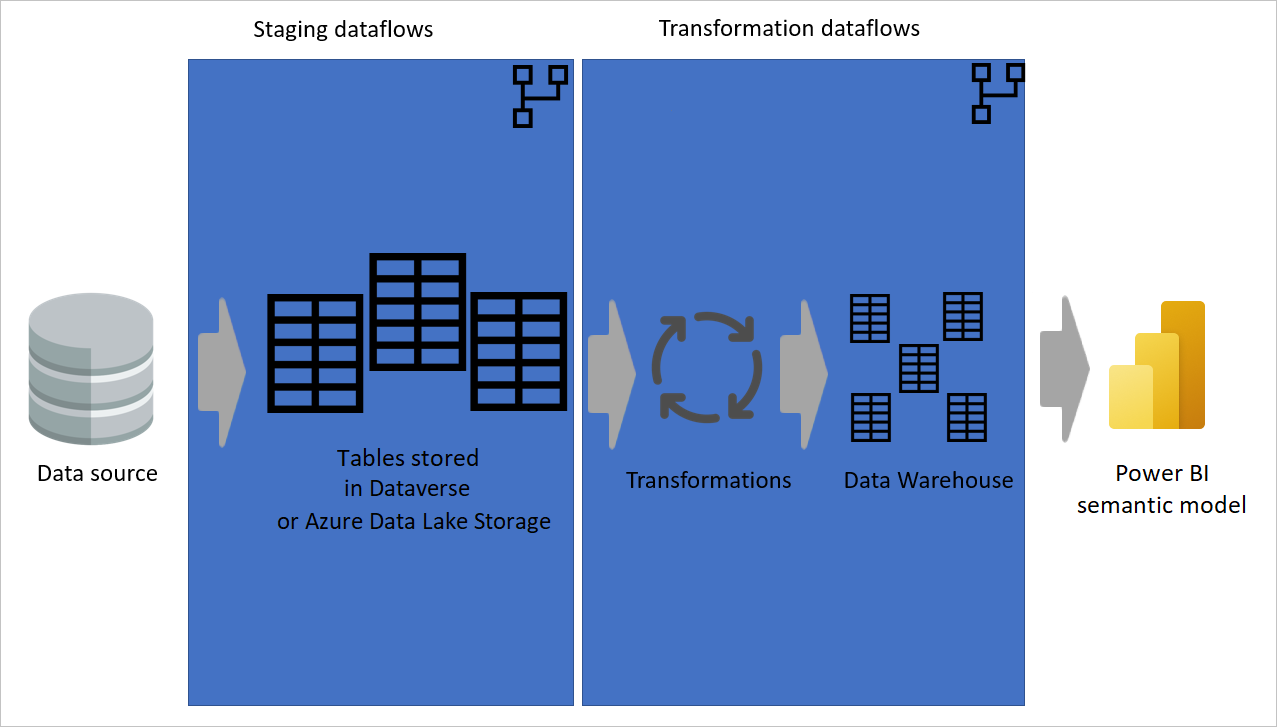
Uso de una tabla calculada tanto como sea posible
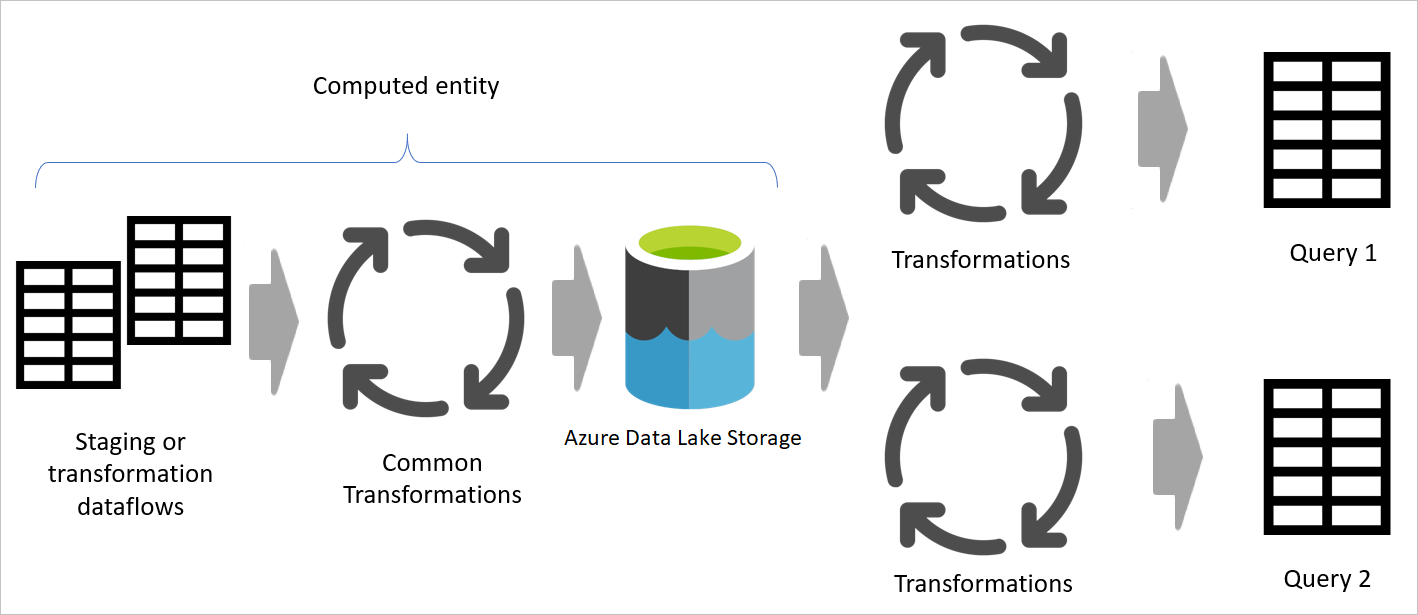
Cuando se usa el resultado de un flujo de datos en otro flujo de datos, se usa el concepto de la tabla calculada, lo que significa obtener datos de una tabla "ya procesada y almacenada". Lo mismo puede ocurrir dentro de un flujo de datos. Al hacer referencia a una tabla desde otra tabla, puede usar la tabla calculada. Este método es útil cuando tiene un conjunto de transformaciones que deben realizarse en varias tablas, que se denominan transformaciones comunes.
En la imagen anterior, la tabla calculada obtiene los datos directamente del origen. Sin embargo, en la arquitectura de los flujos de datos de almacenamiento provisional y transformación, es probable que las tablas calculadas se originen a partir de los flujos de datos de almacenamiento provisional.
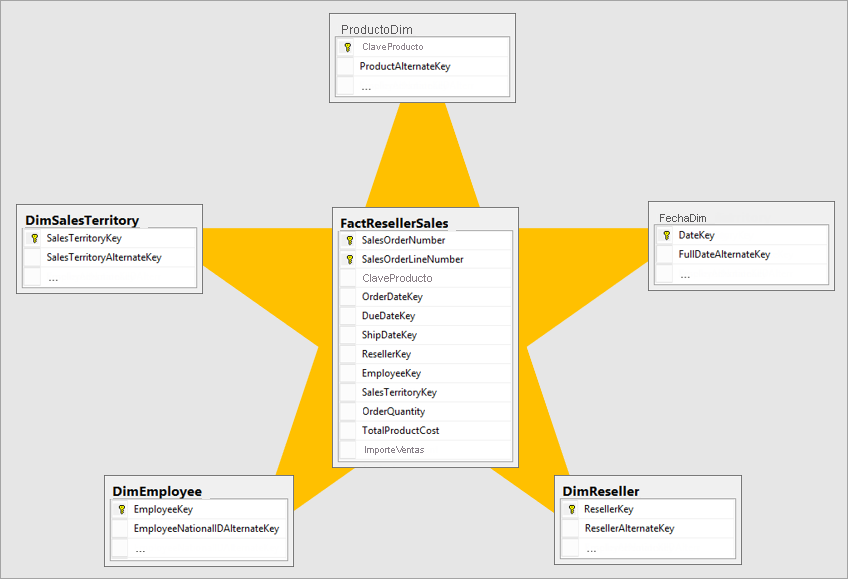
Creación de un esquema de estrella
El mejor modelo dimensional es un modelo de esquema de estrella que tiene dimensiones y tablas de hechos diseñadas de forma que se minimice la cantidad de tiempo para consultar los datos del modelo. Un modelo de esquema de estrella también facilita la comprensión del visualizador de datos.
No es ideal incluir datos en un diseño igual al del sistema operacional en un sistema de BI. Las tablas de datos deben remodelarse. Algunas de las tablas deben tener la forma de una tabla de dimensiones, que mantiene la información descriptiva. Algunas de las tablas deben adoptar la forma de una tabla de hechos para mantener los datos aggregables. El mejor diseño para formar tablas de hechos y tablas de dimensiones es un esquema en estrella. Para más información, vaya a Descripción del esquema de estrella y la importancia de Power BI.
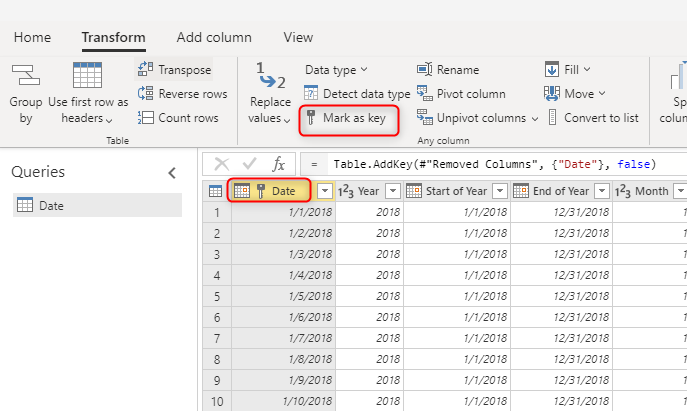
Usar un valor de clave único para dimensiones
Al compilar tablas de dimensiones, asegúrese de que tiene una clave para cada una. Esta clave garantiza que no haya relaciones de varios a varios (o, en otras palabras, "débiles") entre dimensiones. Puede crear la clave aplicando alguna transformación para asegurarse de que una columna o una combinación de columnas devuelven filas únicas en la dimensión. A continuación, esa combinación de columnas se puede marcar como una clave en la tabla del flujo de datos.
Realizar una actualización incremental para tablas de hechos grandes
Las tablas de hechos son siempre las tablas más grandes del modelo dimensional. Se recomienda reducir el número de filas transferidas para estas tablas. Si tiene una tabla de hechos muy grande, asegúrese de usar la actualización incremental para esa tabla. Se puede realizar una actualización incremental en el modelo semántico de Power BI y también en las tablas de flujo de datos.
Puede usar la actualización incremental para actualizar solo parte de los datos, la parte que cambió. Hay varias opciones para elegir qué parte de los datos se van a actualizar y qué parte se va a conservar. Para obtener más información, consulte Uso de la actualización incremental con flujos de datos de Power BI.

Referenciar para crear dimensiones y tablas de hechos
En el sistema de origen, a menudo tiene una tabla que se usa para generar tablas de hechos y dimensiones en el almacenamiento de datos. Estas tablas son buenas candidatas para tablas calculadas y también flujos de datos intermedios. La parte común del proceso, como la limpieza de datos y la eliminación de filas y columnas adicionales, se pueden realizar una vez. Mediante una referencia de la salida de esas acciones, puede generar las tablas de dimensiones y hechos. Este enfoque usa la tabla calculada para las transformaciones comunes.