Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Nota:
Los niveles de privacidad no están disponibles actualmente en los flujos de datos de Power Platform, pero el equipo del producto está trabajando para habilitar esta funcionalidad.
Si ha usado Power Query durante algún tiempo, es probable que lo haya experimentado. De repente, mientras realizas consultas, te encuentras con un error que ninguna cantidad de búsqueda en línea, ajustes de las consultas o golpeteos en el teclado puede solucionar. Un error como:
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
O quizás:
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Estos Formula.Firewall errores son el resultado del firewall de privacidad de datos de Power Query (también conocido como firewall), que en ocasiones puede parecer que existe únicamente para frustrar a los analistas de datos en todo el mundo. Sin embargo, creelo o no, el firewall sirve para un propósito importante. En este artículo, profundizamos bajo el capó para comprender mejor cómo funciona. Con mayor comprensión, esperamos que pueda diagnosticar y corregir mejor los errores de Firewall en el futuro.
¿Qué es?
El propósito del Firewall de Privacidad de Datos es sencillo: existe para evitar que Power Query filtre datos involuntariamente entre fuentes.
¿Por qué es necesario? Es decir, ciertamente podría desarrollar un script M que pasaría un valor SQL a una fuente de OData. Pero esto sería una pérdida intencionada de datos. El autor de mashup sabría (o al menos debería) saber que lo hacían. ¿Por qué es necesario proteger contra la pérdida involuntaria de datos?
¿La respuesta? Plegable.
¿Plegable?
Plegado es un término que se refiere a convertir expresiones en M (como filtros, renombres, uniones, etc.) en operaciones sobre un origen de datos bruto (como SQL, OData, etc.). Una gran parte de la eficacia de Power Query se debe a que Power Query puede convertir las operaciones que realiza un usuario a través de su interfaz de usuario en lenguajes complejos de fuentes de datos SQL u otros del back-end, sin que el usuario tenga que conocer esos lenguajes. Los usuarios obtienen la ventaja de rendimiento de las operaciones nativas del origen de datos, con la facilidad de uso de una interfaz de usuario en la que se pueden transformar todos los orígenes de datos mediante un conjunto común de comandos.
Como parte de la optimización, Power Query a veces podría determinar que la manera más eficaz de ejecutar un mashup específico es tomar datos de un origen y transferirlos a otro. Por ejemplo, si va a unir un archivo CSV pequeño a una tabla SQL enorme, probablemente no quiera que Power Query lea el archivo CSV, lea toda la tabla SQL y luego los una en su computadora local. Probablemente quiera que Power Query inserte los datos CSV en una instrucción SQL y pida a la base de datos SQL que realice la combinación.
Así es como se puede producir una pérdida involuntaria de datos.
Imagínese que estuviera uniendo datos SQL que incluían números de seguridad social de empleados con los resultados de una fuente OData externa y de repente descubriera que los números de seguridad social de SQL se estaban enviando al servicio OData. Malas noticias, ¿verdad?
Este es el tipo de escenario que el firewall está pensado para evitar.
¿Cómo funciona?
El firewall existe para evitar que los datos de un origen se envíen involuntariamente a otro origen. Lo suficientemente simple.
¿Cómo logra esta misión?
Para ello, divide las consultas M en algo denominado particiones y, a continuación, aplica la siguiente regla:
- Una partición puede tener acceso a orígenes de datos compatibles o hacer referencia a otras particiones, pero no a ambas.
Sencillo... sin embargo, confuso. ¿Qué es una partición? ¿Qué hace que dos orígenes de datos "sean compatibles"? ¿Y por qué debe importar el firewall si una partición quiere acceder a un origen de datos y hacer referencia a una partición?
Descompongamos esto y examinemos la regla anterior una pieza a la vez.
¿Qué es una partición?
En su nivel más básico, una partición es simplemente una colección de uno o más pasos de consulta. La partición más granular posible (al menos en la implementación actual) es un solo paso. Las particiones más grandes a veces pueden abarcar varias consultas. (Más sobre esto más adelante.)
Si no está familiarizado con los pasos, puede verlos a la derecha de la ventana del Editor de Power Query después de seleccionar una consulta, en el panel Pasos aplicados . Los pasos realizan un seguimiento de todo lo que hace para transformar sus datos en su forma final.
Particiones que hacen referencia a otras particiones
Cuando se evalúa una consulta con el firewall activado, el firewall divide la consulta y todas sus dependencias en particiones (es decir, grupos de pasos). Cada vez que una partición hace referencia a algo en otra partición, el firewall reemplaza la referencia por una llamada a una función especial denominada Value.Firewall. En otras palabras, el firewall no permite que las particiones accedan directamente entre sí. Todas las referencias se modifican para pasar por el Firewall. Piense en el Firewall como un guardián. Una partición que haga referencia a otra partición debe obtener el permiso del firewall para hacerlo y el firewall controla si se permiten o no los datos a los que se hace referencia en la partición.
Todo esto podría parecer bastante abstracto, así que veamos un ejemplo.
Supongamos que tiene una consulta denominada Employees, que extrae algunos datos de una base de datos SQL. Supongamos que también tiene otra consulta (EmployeesReference), que simplemente hace referencia a Employees.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
Estas consultas terminan divididas en dos particiones: una para la consulta Employees y otra para la consulta EmployeesReference (que hace referencia a la partición Employees). Cuando se evalúa con el firewall activado, estas consultas se vuelven a escribir de la siguiente manera:
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Observe que la referencia simple a la consulta Employees se reemplaza por una llamada a Value.Firewall, al que se le proporciona el nombre completo de la consulta Employees.
Cuando se evalúa EmployeesReference, firewall intercepta la llamada a Value.Firewall("Section1/Employees"), que ahora tiene la oportunidad de controlar si (y cómo) los datos solicitados fluyen a la partición EmployeesReference. Puede hacer cualquier número de cosas: denegar la solicitud, almacenar en búfer los datos solicitados (lo que impide que se produzca un plegado adicional a su origen de datos original), etc.
Así es como el Firewall mantiene el control sobre los datos que fluyen entre particiones.
Particiones que acceden directamente a orígenes de datos
Supongamos que define una consulta Query1 con un paso (tenga en cuenta que esta consulta de un solo paso corresponde a una partición de firewall) y que este único paso tiene acceso a dos orígenes de datos: una tabla de base de datos SQL y un archivo CSV. ¿Cómo trata el firewall, ya que no hay ninguna referencia de partición y, por tanto, no hay ninguna llamada a Value.Firewall para que intercepte? Vamos a revisar la regla indicada anteriormente:
- Una partición puede tener acceso a orígenes de datos compatibles o hacer referencia a otras particiones, pero no a ambas.
Para que la consulta single-partition-but-two-data-sources se pueda ejecutar, sus dos orígenes de datos deben ser "compatibles". Es decir, debe estar bien para que los datos se compartan bidireccionalmente entre ellos. Esto significa que los niveles de privacidad de ambos orígenes deben ser Públicos, o ambos ser Organizativos, ya que son las únicas dos combinaciones que permiten compartir en ambas direcciones. Si ambos orígenes están marcados como Privados o uno está marcado como Público y otro está marcado como Organizativo, o si se marcan con alguna otra combinación de niveles de privacidad, no se permite el uso compartido bidireccional. No es seguro que sean evaluados simultáneamente en la misma partición. Si lo hace, se podría producir una pérdida de datos no segura (debido al plegado) y el firewall no tendría forma de evitarlo.
¿Qué ocurre si intenta acceder a orígenes de datos incompatibles en la misma partición?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Esperemos que ahora comprenda mejor uno de los mensajes de error enumerados al principio de este artículo.
Este requisito de compatibilidad solo se aplica dentro de una partición determinada. Si una partición hace referencia a otras particiones, los orígenes de datos de las particiones a las que se hace referencia no tienen que ser compatibles entre sí. Esto se debe a que el firewall puede almacenar los datos en un búfer, lo que impide cualquier modificación adicional en el origen de datos original. Los datos se cargan en la memoria y se tratan como si vinieran de ninguna parte.
¿Por qué no lo hacen ambos?
Supongamos que define una consulta con un paso (que nuevamente corresponde a una partición) que accede a otras dos consultas (es decir, otras dos particiones). ¿Qué ocurre si desea acceder directamente a una base de datos SQL en el mismo paso? ¿Por qué no puede una partición hacer referencia a otras particiones y acceder directamente a orígenes de datos compatibles?
Como ha visto anteriormente, cuando una partición hace referencia a otra partición, el firewall actúa como el guardián de todos los datos que fluyen a la partición. Para ello, debe poder controlar qué datos se permiten. Si se tiene acceso a orígenes de datos dentro de la partición y los datos fluyen hacia la partición desde otras particiones, pierde su capacidad de actuar como guardián, ya que los datos que fluyen hacia adentro podrían filtrarse a uno de los orígenes de datos accedidos internamente sin que el guardián lo sepa. Por lo tanto, el firewall impide que una partición que tenga acceso a otras particiones tenga permiso para acceder directamente a cualquier origen de datos.
¿Qué ocurre si una partición intenta hacer referencia a otras particiones y también accede directamente a orígenes de datos?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Ahora esperamos que comprenda mejor el otro mensaje de error que aparece al principio de este artículo.
Análisis en profundidad de particiones
Como probablemente pueda adivinar de la información anterior, forma en que se particionan las consultas termina siendo increíblemente importante. Si tiene algunos pasos que hacen referencia a otras consultas y otros pasos que acceden a orígenes de datos, ahora debería reconocer que dibujar los límites de partición en ciertos lugares provoca errores de firewall, mientras que hacerlo en otros lugares permite que la consulta se ejecute correctamente.
¿Cómo se particionan exactamente las consultas?
Esta sección es probablemente la más importante para comprender por qué ve errores de firewall y cómo resolverlos (siempre que sea posible).
Este es un resumen general de la lógica de creación de particiones.
- Creación de particiones iniciales
- Crea una partición para cada paso de cada consulta.
- Fase estática
- Esta fase no depende de los resultados de la evaluación. En su lugar, se basa en cómo se estructuran las consultas.
- Recorte de parámetros
- Recorta particiones similares a parámetros, es decir, cualquier partición que:
- No hace referencia a ninguna otra partición
- No contiene ninguna invocación de función
- No es cíclico (es decir, no se refiere a sí mismo)
- Tenga en cuenta que "quitar" una partición lo incluye de forma eficaz en cualquier otra partición que haga referencia a ella.
- Recortar particiones de parámetros permite que las referencias de parámetro usadas en las llamadas de función del origen de datos (por ejemplo,
Web.Contents(myUrl)) funcionen, en lugar de producir errores de "partición no puede hacer referencia a orígenes de datos y otros pasos".
- Recorta particiones similares a parámetros, es decir, cualquier partición que:
- Agrupación (estática)
- Las particiones se fusionan en orden de dependencias de abajo hacia arriba. En las particiones combinadas resultantes, las siguientes son independientes:
- Particiones en consultas diferentes
- Particiones que no hacen referencia a otras particiones (y, por tanto, pueden acceder a un origen de datos).
- Particiones que hacen referencia a otras particiones (y, por tanto, están prohibidas para acceder a un origen de datos)
- Las particiones se fusionan en orden de dependencias de abajo hacia arriba. En las particiones combinadas resultantes, las siguientes son independientes:
- Recorte de parámetros
- Esta fase no depende de los resultados de la evaluación. En su lugar, se basa en cómo se estructuran las consultas.
- Fase dinámica
- Esta fase depende de los resultados de evaluación, incluida la información sobre los orígenes de datos a los que acceden varias particiones.
- Recorte
- Recorta las particiones que cumplen todos los requisitos siguientes:
- No tiene acceso a ningún origen de datos
- No hace referencia a ninguna partición que acceda a orígenes de datos
- No es cíclico
- Recorta las particiones que cumplen todos los requisitos siguientes:
- Agrupación (dinámica)
- Ahora que se recortan las particiones innecesarias, intente crear particiones de origen que sean lo más grandes posible. Esta creación se realiza mediante la combinación de las particiones con las mismas reglas descritas en la fase de agrupación estática anterior.
¿Qué significa todo esto?
Veamos un ejemplo para ilustrar cómo funciona la lógica compleja que se ha diseñado anteriormente.
Este es un escenario de ejemplo. Se trata de una combinación bastante sencilla de un archivo de texto (Contactos) con una base de datos SQL (Empleados), donde SQL Server es un parámetro (DbServer).
Las tres consultas
Este es el código M para las tres consultas que se usan en este ejemplo.
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents(
"C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]
),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(
#"Promoted Headers",
{
{"ContactID", Int64.Type},
{"NameStyle", type logical},
{"Title", type text},
{"FirstName", type text},
{"MiddleName", type text},
{"LastName", type text},
{"Suffix", type text},
{"EmailAddress", type text},
{"EmailPromotion", Int64.Type},
{"Phone", type text},
{"PasswordHash", type text},
{"PasswordSalt", type text},
{"AdditionalContactInfo", type text},
{"rowguid", type text},
{"ModifiedDate", type datetime}
}
)
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(
HumanResources_Employee,
{
"HumanResources.Employee(EmployeeID)",
"HumanResources.Employee(ManagerID)",
"HumanResources.EmployeeAddress",
"HumanResources.EmployeeDepartmentHistory",
"HumanResources.EmployeePayHistory",
"HumanResources.JobCandidate",
"Person.Contact",
"Purchasing.PurchaseOrderHeader",
"Sales.SalesPerson"
}
),
#"Merged Queries" = Table.NestedJoin(
#"Removed Columns",
{"ContactID"},
Contacts,
{"ContactID"},
"Contacts",
JoinKind.LeftOuter
),
#"Expanded Contacts" = Table.ExpandTableColumn(
#"Merged Queries",
"Contacts",
{"EmailAddress"},
{"EmailAddress"}
)
in
#"Expanded Contacts";
Esta es una vista de nivel superior que muestra las dependencias.
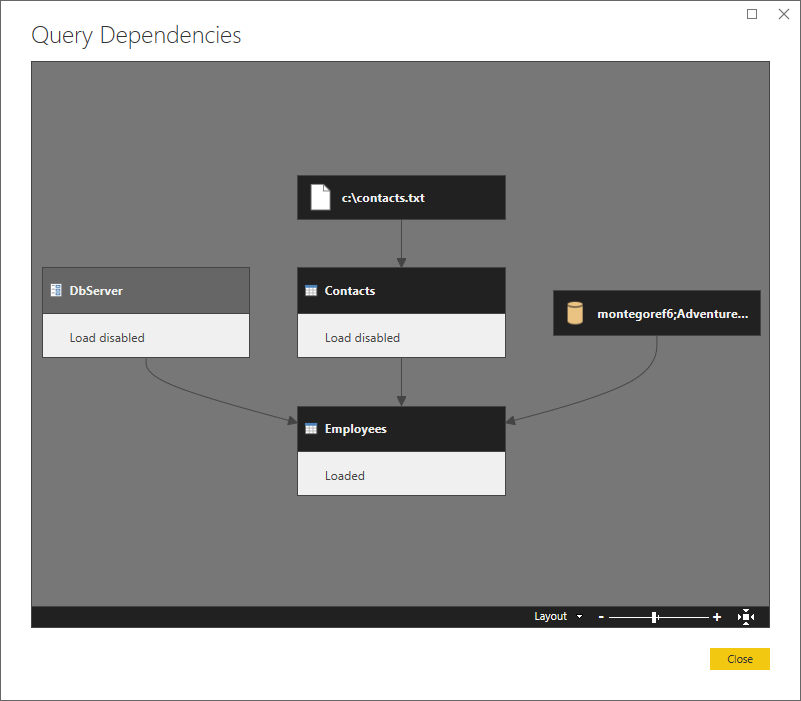
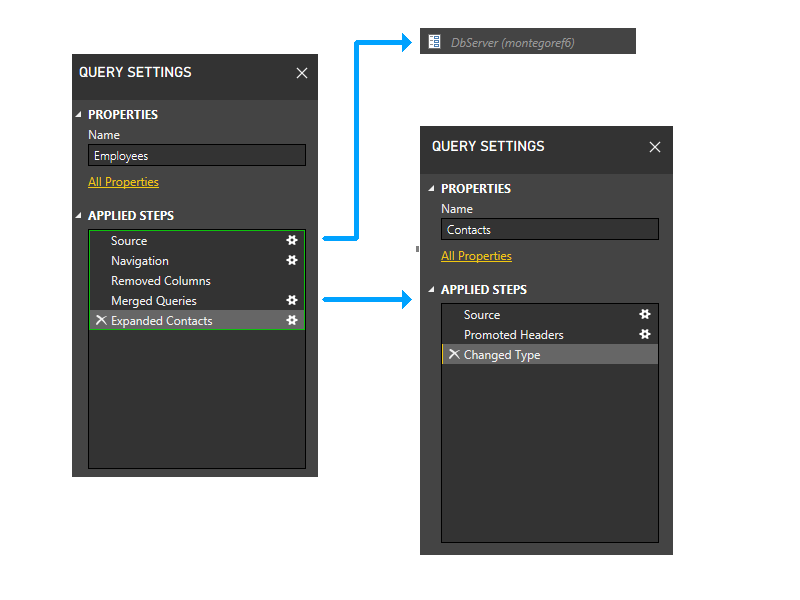
Vamos a particionar
Vamos a examinar más de cerca y detallar los pasos en la imagen, y comenzar a explorar la lógica de particionamiento. Este es un diagrama de las tres consultas, que muestra las particiones iniciales del firewall en verde. Note que cada paso se inicia en su propia partición.
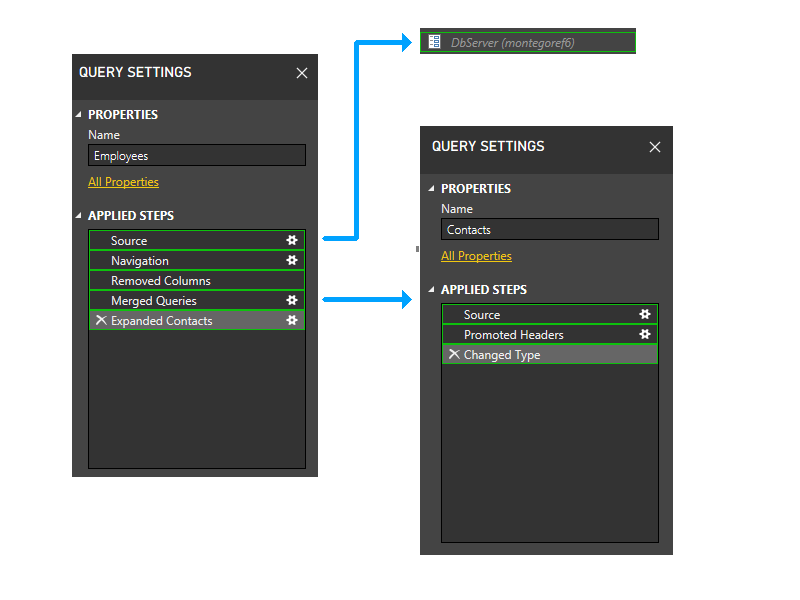
A continuación, recortamos las particiones de parámetros. Por lo tanto, DbServer se incluye implícitamente en la partición de origen.
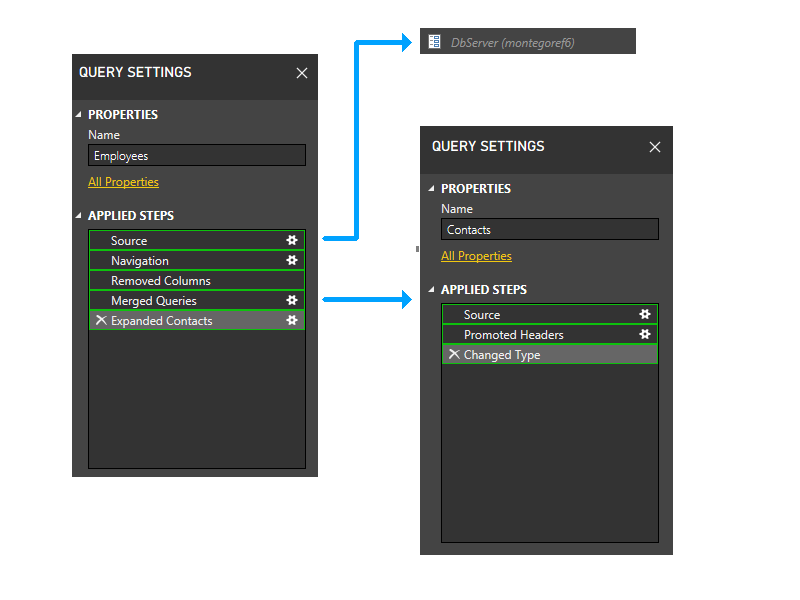
Ahora realizamos la agrupación estática. Esta agrupación mantiene la separación entre particiones en consultas independientes (tenga en cuenta, por ejemplo, que los dos últimos pasos de Empleados no se agrupan con los pasos de Contactos) y entre particiones que hacen referencia a otras particiones (como los dos últimos pasos de Empleados) y las que no (como los tres primeros pasos de Empleados).
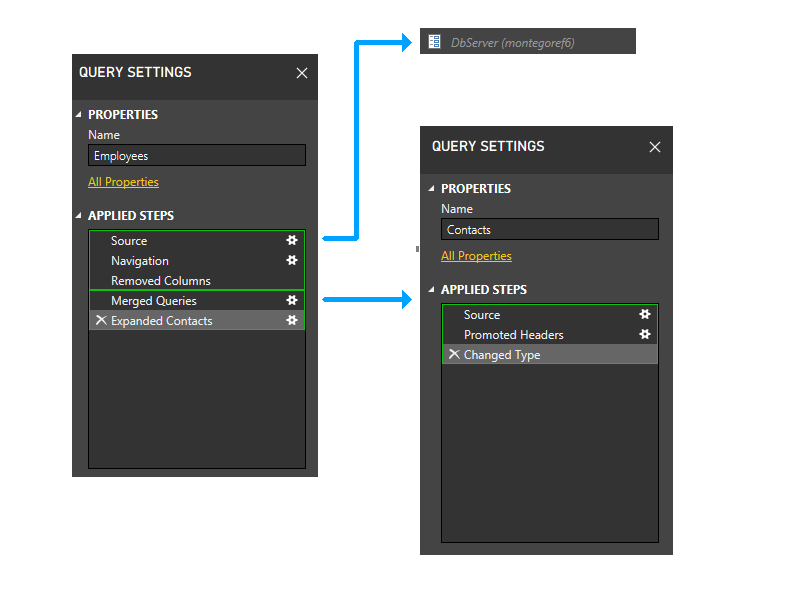
Ahora entramos en la fase dinámica. En esta fase, se evalúan las particiones estáticas anteriores. Se recortan las particiones que no tienen acceso a ningún origen de datos. A continuación, las particiones se agrupan para crear particiones de origen que sean lo más grandes posible. Sin embargo, en este escenario de ejemplo, todas las particiones restantes acceden a los orígenes de datos y no hay ninguna agrupación adicional que se pueda realizar. Por lo tanto, las particiones de nuestro ejemplo no cambian durante esta fase.
Vamos a fingir
Por motivos de ilustración, sin embargo, echemos un vistazo a lo que sucedería si la consulta Contactos, en lugar de provengar de un archivo de texto, estuviera codificada de forma rígida en M (quizás a través del cuadro de diálogo Escribir datos ).
En este caso, la consulta contactos no accedería a ningún origen de datos. Por consiguiente, se recortará durante la primera etapa de la fase dinámica.
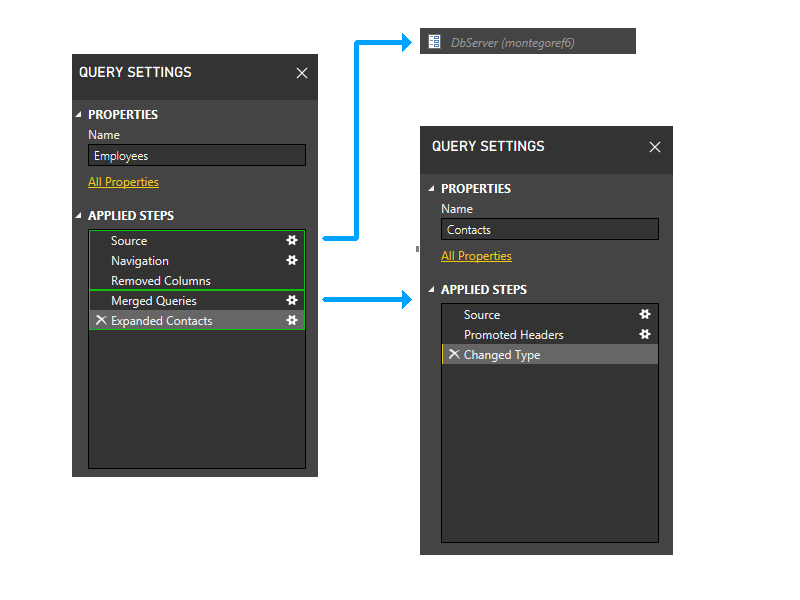
Con la partición Contactos eliminada, los dos últimos pasos de Employees ya no harían referencia a ninguna partición, excepto la que contiene los tres primeros pasos de Employees. Por lo tanto, las dos particiones se agruparían.
La partición resultante tendría este aspecto.
Ejemplo: Pasar datos de un origen de datos a otro
Bien, suficiente explicación abstracta. Echemos un vistazo a un escenario común en el que es probable que encuentre un error de firewall y los pasos para resolverlo.
Imagine que quiere buscar un nombre de empresa desde el servicio OData de Northwind y, a continuación, use el nombre de la empresa para realizar una búsqueda de Bing.
En primer lugar, cree una consulta de empresa para recuperar el nombre de la compañía.
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
A continuación, creará una consulta de búsqueda que haga referencia a Company y la pase a Bing.
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
En este momento, te encuentras con problemas. Evaluar Search genera un error de Firewall.
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Este error se produce porque el paso Origen de la búsqueda hace referencia a un origen de datos (bing.com) y también hace referencia a otra consulta o partición (Empresa). Infringe la regla mencionada anteriormente ("una partición puede tener acceso a orígenes de datos compatibles o hacer referencia a otras particiones, pero no a ambas").
¿Qué debe hacer? Una opción consiste en deshabilitar el firewall por completo (a través de la opción Privacidad etiquetada Omitir los niveles de privacidad y mejorar potencialmente el rendimiento). Pero, ¿qué ocurre si desea dejar habilitado el firewall?
Para resolver el error sin deshabilitar el firewall, puede combinar Company and Search en una sola consulta, de la siguiente manera:
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
Ahora todo está sucediendo dentro de una sola partición. Suponiendo que los niveles de privacidad de los dos orígenes de datos sean compatibles, el firewall debería ser feliz y ya no recibirá un error.
Eso es todo
Aunque hay mucho más que podría decirse sobre este tema, este artículo introductorio ya es lo suficientemente largo. Esperemos que le dé una mejor comprensión del firewall y le ayuda a comprender y corregir errores de firewall cuando los encuentre en el futuro.