Varias GPU y máquinas
1. Introducción
CNTK admite actualmente cuatro algoritmos SGD paralelos:
Requisitos previos
Para ejecutar el entrenamiento paralelo, asegúrese de que está instalada una implementación de la interfaz de paso de mensajes (MPI):
En Windows, instale la versión 7 (7.0.12437.6) de Microsoft MPI (MS-MPI), una implementación de Microsoft del estándar de interfaz de paso de mensajes, desde esta página de descarga, marcada simplemente como "Versión 7" en el título de la página. Haga clic en el botón Descargar y, a continuación, seleccione el tiempo de ejecución (
MSMpiSetup.exe).En Linux, instale OpenMPI versión 1.10.x. Siga las instrucciones que se indican aquí para compilarla usted mismo.
2. Configuración del entrenamiento paralelo en CNTK en Python
Para usar SGD paralelo de datos en Python, el usuario debe crear y pasar un aprendiz distribuido al instructor:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
En el caso del bucle de entrenamiento definido por el usuario (en lugar de training_session), los usuarios deben pasar num_data_partitions y partition_index al método para MinibatchSource.next_minibatch() que los distintos nodos de MPI lean datos de distintas particiones de datos (una vez distributed_after leídos los ejemplos).
Tenga en cuenta que solo se debe llamar en caso de que Communicator.finalize() el entrenamiento distribuido finalice correctamente. En caso de que se produzca un error en un trabajo distribuido, no se debe llamar a este método.
Para obtener un ejemplo totalmente funcional, consulte El ejemplo de ConvNet.
3. Configuración del entrenamiento paralelo en CNTK en BrainScript
Para habilitar el entrenamiento paralelo en CNTK BrainScript, primero es necesario activar el siguiente modificador en el archivo de configuración o en la línea de comandos:
parallelTrain = true
En segundo lugar, el SGD bloque del archivo de configuración debe contener un sub block denominado ParallelTrain con los argumentos siguientes:
parallelizationMethod: (obligatorio) los valores legítimos sonDataParallelSGD,BlockMomentumSGDyModelAveragingSGD.Especifica qué algoritmo paralelo se va a usar.
distributedMBReading: (opcional) acepta el valor booleano:trueofalse; el valor predeterminado es .falseSe recomienda activar la lectura de minibatch distribuido para minimizar el costo de E/S en cada trabajo. Si usa lector de formato de texto CNTK, Lector de imágenes o Lector de datos compuestos, distributedMBReading debe establecerse en true.
parallelizationStartEpoch: (opcional) acepta el valor entero; el valor predeterminado es 1.Esto especifica a partir de la época en que se usan los algoritmos de entrenamiento paralelos; antes de que todos los trabajadores realicen el mismo entrenamiento, pero solo un trabajador puede guardar el modelo. Esta opción puede ser útil si el entrenamiento paralelo requiere una fase de "inicio intermedio".
syncPerfStats: (opcional) acepta el valor entero; el valor predeterminado es 0.Esto especifica la frecuencia con la que se imprimirán las estadísticas de rendimiento. Estas estadísticas incluyen el tiempo dedicado a la comunicación o el cálculo en un período de sincronización, lo que puede ser útil para comprender el cuello de botella de los algoritmos de entrenamiento paralelos.
0 significa que no se imprimirán estadísticas. Otros valores especifican con qué frecuencia se imprimirán las estadísticas. Por ejemplo,
syncPerfStats=5significa que las estadísticas se imprimirán después de cada 5 sincronizaciones.Sub-bloque que especifica los detalles de cada algoritmo de entrenamiento paralelo. El nombre del sub bloque debe ser igual a
parallelizationMethod. (obligatorio)
Python proporciona más flexibilidad y usos que se muestran a continuación para diferentes métodos de paralelización.
4. Ejecutar entrenamiento paralelo con CNTK
La paralelización en CNTK se implementa con MPI.
4.1 Ejecución de entrenamiento paralelo con BrainScript
Dado cualquiera de las configuraciones de BrainScript de entrenamiento en paralelo anteriores, se pueden usar los siguientes comandos para iniciar un trabajo MPI paralelo:
Entrenamiento paralelo en la misma máquina con Linux:
mpiexec --npernode $num_workers $cntk configFile=$configEntrenamiento paralelo en la misma máquina con Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Entrenamiento paralelo en varios nodos informáticos con Linux:
Paso 1: Crear un archivo host $hostfile con su editor favorito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Donde name_of_node(n) es simplemente un nombre DNS o una dirección IP del nodo de trabajo.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Entrenamiento paralelo en varios nodos informáticos con Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
donde $cntk debe hacer referencia a la ruta de acceso del ejecutable de CNTK ($x es la forma del shell de Linux de sustituir las variables de entorno, el equivalente de en el shell de %x% Windows).
4.2 Ejecución del entrenamiento paralelo con Python
Puede encontrar ejemplos de entrenamiento distribuido para CNTK v2 con Python aquí:
Dado un script training.py de Python de CNTK v2, se pueden usar los siguientes comandos para iniciar un trabajo MPI paralelo:
Entrenamiento paralelo en la misma máquina con Linux:
mpiexec --npernode $num_workers python training.pyEntrenamiento paralelo en la misma máquina con Windows:
mpiexec -n %num_workers% python training.pyEntrenamiento paralelo en varios nodos informáticos con Linux:
Paso 1: Crear un archivo host $hostfile con su editor favorito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Donde name_of_node(n) es simplemente un nombre DNS o una dirección IP del nodo de trabajo.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Entrenamiento paralelo en varios nodos informáticos con Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel entrenamiento con SGD de 1 bits
CNTK implementa la técnica SGD de 1 bits [1]. Esta técnica permite distribuir cada minibatch sobre K los trabajos. Los degradados parciales resultantes se intercambian y agregan después de cada minibatch. "1 bit" hace referencia a una técnica desarrollada en Microsoft para reducir la cantidad de datos que se intercambian por cada valor de degradado a un solo bit.
5.1 El algoritmo "SGD de 1 bits"
El intercambio directo de degradados parciales después de cada minibatch requiere ancho de banda de comunicación prohibitivo. Para abordar esto, SGD de 1 bits cuantifica de forma agresiva cada valor de degradado... a un solo bit (!) por valor. Prácticamente, esto significa que se recortan valores de degradado grandes, mientras que los valores pequeños se inflan artificialmente. Sorprendentemente, esto no daña la convergencia si, y solo si, se usa un truco .
El truco es que, para cada minibatch, el algoritmo compara los degradados cuantificados (que se intercambian entre los trabajos) con los valores de degradado originales (que se supone que se intercambiaron). La diferencia entre los dos (el error de cuantificación) se calcula y se recuerda como residual. A continuación, este valor residual se agrega al siguiente minibatch.
Como consecuencia, a pesar de la cuantificación agresiva, cada valor de degradado finalmente se intercambia con precisión completa; sólo en un retraso. Los experimentos muestran que, siempre que este modelo se combine con un inicio intermedio (un modelo de inicialización entrenado en un pequeño subconjunto de los datos de entrenamiento sin paralelización), esta técnica ha demostrado provocar una pérdida de precisión o muy pequeña, al tiempo que permite una velocidad no demasiado lejos de lineal (el factor de limitación es que las GPU se vuelven ineficaz al calcular en subprocesos demasiado pequeños).
Para lograr la máxima eficiencia, la técnica debe combinarse con el escalado automático de minibatch, donde cada vez y después, el entrenador intenta aumentar el tamaño del minibatch. Evaluar en un pequeño subconjunto de la próxima época de datos, el instructor seleccionará el tamaño de minibatch más grande que no daña la convergencia. Aquí, resulta útil que CNTK especifique la velocidad de aprendizaje y los hiperparámetros de impulso de una manera independiente del tamaño de minibatch.
5.2 Uso de SGD de 1 bits en BrainScript
SgD de 1 bits no tiene ningún parámetro que no sea habilitarlo y después de la época en que debe comenzar. Además, se debe habilitar el escalado automático de minibatch. Estos se configuran agregando los parámetros siguientes al bloque SGD:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Tenga en cuenta que Data-Parallel SGD también se puede usar sin cuantificación de 1 bits. Sin embargo, en escenarios típicos, especialmente los escenarios en los que cada parámetro de modelo se aplica solo una vez como para un DNN de avance de fuente, esto no será eficaz debido a las necesidades de ancho de banda de comunicación elevados.
En la sección 2.2.3 siguiente se muestran los resultados de SGD de 1 bits en una tarea de voz, en comparación con el método Block-Momentum SGD, que se describe a continuación. Ambos métodos no tienen o casi ninguna pérdida de precisión a velocidad casi lineal.
5.3 Uso de SGD de 1 bits en Python
Para usar SGD paralelo de datos en Python, opcionalmente con SGD de 1 bits, el usuario debe crear y pasar un aprendiz distribuido al instructor:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Al cambiar num_quantization_bits a 32 durante la creación de distributed_learner, se usa Data-Parallel SGD no cuantificado. En este caso, no es necesario iniciarse en caliente.
6 Block-Momentum SGD
Block-Momentum SGD es la implementación de la "actualización y filtrado del modelo en bloque" o BMUF, algoritmo, impulso de bloque corto [2].
6.1 Algoritmo Block-Momentum SGD
En la ilustración siguiente se resume el procedimiento del algoritmo Block-Momentum.

6.2 Configuración de Block-Momentum SGD en BrainScript
Para usar Block-Momentum SGD, es necesario tener un sub-bloque denominado BlockMomentumSGD en el SGD bloque con las siguientes opciones:
syncPeriod. Esto es similar asyncPeriodenModelAveragingSGD, que especifica la frecuencia con la que se realiza una sincronización de modelos. El valor predeterminado deBlockMomentumSGDes 120 000.resetSGDMomentum. Esto significa que después de cada punto de sincronización, el degradado suavizado utilizado en sgD local se establecerá como 0. El valor predeterminado de esta variable es true.useNesterovMomentum. Esto significa que la actualización de impulso de estilo Nesterov se aplica en el nivel de bloque. Consulte [2] para obtener más detalles. El valor predeterminado de esta variable es true.
El impulso de bloque y la tasa de aprendizaje de bloques suelen establecerse automáticamente según el número de trabajadores usados, es decir,
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Nuestra experiencia indica que estas configuraciones suelen producir una convergencia similar a la del algoritmo SGD estándar hasta 64 GPU, que es el experimento más grande que hemos realizado. También es posible especificar manualmente estos parámetros con las siguientes opciones:
blockMomentumAsTimeConstantespecifica la constante de tiempo del filtro de paso bajo en la actualización del modelo de nivel de bloque. Se calcula como:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateespecifica la velocidad de aprendizaje de bloques.
A continuación se muestra un ejemplo de Block-Momentum sección de configuración de SGD:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Uso de Block-Momentum SGD en BrainScript
1. Volver a ajustar los parámetros de aprendizaje
Para lograr un rendimiento similar por trabajo, es necesario aumentar el número de muestras en un minibatch proporcional al número de trabajos. Esto se puede lograr ajustando
minibatchSizeonbruttsineachrecurrentiter, dependiendo de si se usa la selección aleatoria en modo marco.No es necesario ajustar la velocidad de aprendizaje (a diferencia de Model-Averaging SGD, consulte a continuación).
Se recomienda usar Block-Momentum SGD con un modelo de inicio intermedio. En nuestras tareas de reconocimiento de voz, se logra una convergencia razonable al empezar a partir de modelos de inicialización entrenados en 24 horas (8,6 millones de muestras) a 120 horas (43,2 millones de muestras) con sgD estándar.
2. Experimentos de ASR
Usamos los Block-Momentum SGD y los algoritmos SGD de Data-Parallel (1 bits) para entrenar DNN y LSTM en una tarea de reconocimiento de voz de 2600 horas y comparamos las precisiones de reconocimiento de palabras frente a factores de aceleración. En las tablas y ilustraciones siguientes se muestran los resultados (*).
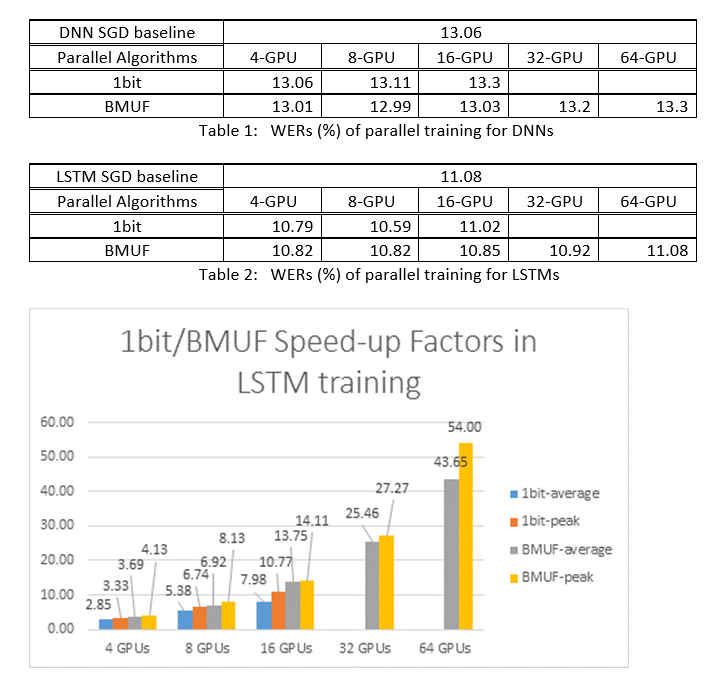
(*): Factor de aceleración máxima: para SGD de 1 bits, medido por el factor de velocidad máxima (en comparación con la línea de base SGD) logrado en un minibatch; para Bloquear impulso, medido por la velocidad máxima lograda en un bloque; Factor de aceleración promedio: el tiempo transcurrido en la línea base de SGD dividido por el tiempo transcurrido observado. Estas dos métricas se introducen debido a la latencia en E/S puede afectar considerablemente a la medición media del factor de aceleración, especialmente cuando la sincronización se realiza en el nivel de minilote. Al mismo tiempo, el factor de velocidad máxima es relativamente sólido.
3. Advertencias
Se recomienda establecer
resetSGDMomentumen true; de lo contrario, a menudo conduce a la divergencia del criterio de entrenamiento. Restablecer el impulso de SGD a 0 después de cada sincronización de modelos básicamente corta la contribución de los últimos minibatches. Por lo tanto, se recomienda no usar un impulso de SGD grande. Por ejemplo, para unsyncPeriodvalor de 120 000, observamos una pérdida de precisión significativa si el impulso utilizado para SGD es 0,99. Reducir el impulso de SGD a 0,9, 0,5 o incluso deshabilitarlo por completo proporciona precisión similar a la que puede lograr el algoritmo sgD estándar.Block-Momentum retrasos de SGD y distribuye las actualizaciones del modelo de un bloque en bloques posteriores. Por lo tanto, es necesario asegurarse de que las sincronizaciones de modelos se realizan con frecuencia suficiente en el entrenamiento. Una comprobación rápida consiste en usar
blockMomentumAsTimeConstant. Se recomienda que el número de ejemplos de entrenamiento únicos,N, cumpla la siguiente ecuación:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
La aproximación se deriva de los siguientes hechos: (1) El impulso de bloque se establece a menudo como (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Uso de Block-Momentum en Python
Para habilitar Block-Momentum en Python, de forma similar al SGD de 1 bits, el usuario debe crear y pasar un aprendiz distribuido de impulso de bloque al instructor:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Para obtener un ejemplo totalmente funcional, consulte el ejemplo de ConvNet.
7 Model-Averaging SGD
Model-Averaging SGD es una implementación del algoritmo de promedio del modelo detallado en [3,4] sin el uso del degradado natural. La idea aquí es permitir que cada trabajo procese un subconjunto de datos, pero promediar los parámetros del modelo de cada trabajo después de un período especificado.
Model-Averaging SGD generalmente converge más lentamente y a un peor óptimo, en comparación con SGD de 1 bits y Block-Momentum SGD, por lo que ya no se recomienda.
Para usar Model-Averaging SGD, es necesario tener un subproceso denominado ModelAveragingSGD en el SGD bloque con las siguientes opciones:
syncPeriodespecifica el número de muestras que cada trabajo necesita procesar antes de que se realice un promedio del modelo. El valor predeterminado es 40 000.
7.1 Uso de Model-Averaging SGD en BrainScript
Para que Model-Averaging SGD sea eficaz y eficaz, los usuarios deben ajustar algunos hiperparámetres:
minibatchSizeonbruttsineachrecurrentiter. Supongamos quenlos trabajadores participan en la configuración de Model-Averaging SGD, la implementación de lectura distribuida actual cargará1/nla minibatch en cada trabajo. Por lo tanto, para asegurarse de que cada trabajo produce el mismo rendimiento que el SGD estándar, es necesario ampliar el tamañonde minibatch -fold. En el caso de los modelos entrenados mediante la selección aleatoria en modo marco, esto se puede lograr al ampliarminibatchSizepornhoras; para los modelos se entrenan mediante la selección aleatoria en modo de secuencia, como RNN, algunos lectores necesitan aumentarnbruttsineachrecurrentiteren su lugar porn.learningRatesPerSample. Nuestra experiencia indica que para obtener una convergencia similar a la SGD estándar, es necesario aumentar loslearningRatesPerSamplentiempos. Puede encontrar una explicación en [2]. Dado que se aumenta la tasa de aprendizaje, se necesita un cuidado adicional para asegurarse de que el entrenamiento no difiere, y esto es, de hecho, la advertencia principal de Model-Averaging SGD. Puede usar laAutoAdjustconfiguración para volver a cargar el mejor modelo anterior si se observa un aumento en el criterio de entrenamiento.inicio cálido. Se encuentra que Model-Averaging SGD suele converger mejor si se inicia desde un modelo de inicialización entrenado por el algoritmo SGD estándar (sin paralelización). En nuestras tareas de reconocimiento de voz, se logra una convergencia razonable al empezar a partir de modelos de inicialización entrenados en 24 horas (8,6 millones de muestras) a 120 horas (43,2 millones de muestras) con sgD estándar.
A continuación se muestra un ejemplo de sección de ModelAveragingSGD configuración:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Uso de Model-Averaging SGD en Python
Se trata de un trabajo en curso.
8 Data-Parallel entrenamiento con el servidor de parámetros
El servidor de parámetros es un marco ampliamente utilizado en el aprendizaje automático distribuido [5][6][7]. La ventaja más importante que aporta es el entrenamiento paralelo asincrónico con muchos trabajadores. Presenta el servidor de parámetros como un almacén de modelos distribuidos. En lugar de aprovechar directamente los primitivos de AllReduce para sincronizar las actualizaciones de parámetros entre los trabajadores, el marco del servidor de parámetros proporciona a los usuarios las interfaces como "Agregar" y "Obtener" para permitir que los trabajadores locales actualicen y recuperen parámetros globales del servidor de parámetros. De este modo, los trabajadores locales no necesitan esperarse entre sí durante el proceso de entrenamiento, lo que ahorra mucho tiempo, especialmente cuando el número de trabajo es grande.
Además, como servidores de parámetros es un marco distribuido que almacena parámetros de modelo, los trabajadores solo pueden recuperar esos parámetros que necesitan durante el proceso de entrenamiento por lotes mini, esto aporta una gran flexibilidad en el diseño del método de entrenamiento distribuido y también mejora la eficacia al realizar el entrenamiento con actualizaciones dispersas del modelo. En esta versión, nos centraremos primero en el entrenamiento paralelo asincrónico, más adelante se proporcionará más introducción sobre cómo aprovechar el marco de servidor de parámetros para un entrenamiento eficaz del modelo con actualizaciones dispersas.
8.1 Uso de Data-Parallel ASGD
- Para usar servidores de parámetros para el SGD asincrónico (abbr. como ASGD), debe compilar CNTK con multiverso compatible, Multiverso es un marco de servidor de parámetros general para la tarea de aprendizaje automático distribuido desarrollada por el equipo de Microsoft Research Asia.
Clone Code: clone el código en la carpeta raíz de CNTK mediante:
git submodule update --init Source/Multiverso
Linux: compile con--asgd=yesen el proceso de configuración.Windows: agregueCNTK_ENABLE_ASGDal entorno del sistema y establezca el valor en .true
- inicio cálido. En algunos casos, es mejor que el entrenamiento del modelo asincrónico se inicie a partir de un modelo de inicialización (entrenado por el algoritmo SGD estándar). En cierto sentido, SGD asincrónico aporta más ruido para el entrenamiento debido a las actualizaciones retrasadas del asincronismo entre los trabajadores. Algunos modelos son muy sensibles a este ruido al principio, lo que podría dar lugar a una divergencia del entrenamiento del modelo. En tal circunstancia, se necesita un inicio cálido .
8.2 Configuración de Data-Parallel ASGD en BrainScript
Para usar Data-Parallel ASGD en CNTK, es necesario tener un dataParallelASGD de sub block en el bloque SGD con las siguientes opciones.
-
syncPeriodPerWorkers. Especifica el número de muestras que cada trabajo necesita procesar antes de comunicarse con los servidores de parámetros. El valor predeterminado es 256. Se recomienda como tamaño de minibatch. Es obvio que la sincronización frecuente dará lugar a un costo de comunicación elevado significativo. En nuestra prueba, no es necesario establecer el valor en 1 en la mayoría de los casos.
-
usePipeline. Especifica si activa la canalización de recuperación del modelo y el cálculo local. Activar la canalización aumentará significativamente el rendimiento general del entrenamiento, ya que ocultará algunos o todos los costos de comunicación. Sin embargo, a veces podría ralentizar la tasa convergente, ya que se introducirá más retraso agregando canalización. En general, la hora del reloj se guardará en la mayoría de los casos con la canalización.
-
AdjustLearningRateAtBeginning. Según el artículo publicado recientemente [5], el entrenamiento de ASGD es menos estable, y requiere el uso de una velocidad de aprendizaje mucho menor para evitar explosiones ocasionales de la pérdida de entrenamiento, por lo que el proceso de aprendizaje se vuelve menos eficaz. Sin embargo, hemos detectado que el uso de una velocidad de aprendizaje inferior no es necesario para todas las tareas. Y para esas tareas sensibles al principio, empezamos el entrenamiento con una velocidad de aprendizaje pequeña y aumentamos gradualmente en la fase inicial del proceso de entrenamiento hasta que alcanza la velocidad de aprendizaje inicial utilizada en la SGD normal. De este modo, la precisión final coincidirá con SGD mientras que con la velocidad de ASGD. Por lo tanto, proporcionamos esta opción para que los usuarios de ASGD aprovechen este truco. Es un subproceso en DataParallelASGD con dos parámetros: adjustCoefficient y adjustNBMiniBatch. La lógica es que la velocidad de aprendizaje comienza desde adjustCoefficient of SGD initial learning rate (Velocidad de aprendizaje inicial de SGD) y aumenta ajustandoCoefficient de la velocidad de aprendizaje inicial de SGD cada ajusteNBMiniBatch mini lotes.
A continuación se muestra un ejemplo de sección de DataParallelASGD configuración:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Configuración de Data-Parallel ASGD en Python
Se trata de un trabajo en curso.
8.4 Experimentos
En la ilustración siguiente se muestran los experimentos para probar ASGD con el conjunto de datos CIFAR-10. El modelo que se usa en este experimento es resnet de 20 capas. El algoritmo asincrónico reduce el costo de esperar a todos los nodos de trabajo. ASGD, en este caso, es claramente más rápido que los algoritmos sincrónicos, como MA y SSGD. *En los experimentos, todos los modos paralelos sincronizan los parámetros cada iteración (actualización por lotes mini). Y para SSGD, usamos actualizaciones de parámetros de 32 bits. El algoritmo asincrónico obtiene una ventaja significativa en cuanto al rendimiento de entrenamiento medido por la velocidad de procesamiento de muestras, especialmente cuando el número de nodo de trabajo sube a 16.
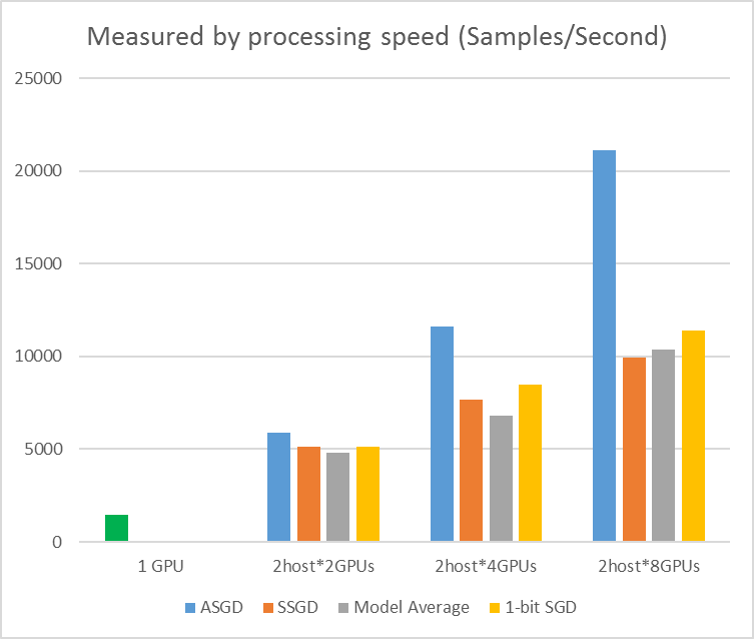 Figura 2.4 aceleración para diferentes métodos de entrenamiento
Figura 2.4 aceleración para diferentes métodos de entrenamiento
Referencias
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li y Dong Yu, "descenso de degradado estocástico de 1 bit y su aplicación a la formación distribuida en paralelo de datos de DNN de voz", en Actas de Interspeech, 2014.
[2] K. Chen y Q. Gateway, "Entrenamiento escalable de máquinas de aprendizaje profundo mediante el entrenamiento incremental de bloques con optimización en paralelo dentro del bloque y filtrado de actualización de modelos en bloques bloqueados", en Actas de ICASSP, 2016.
[3] M. Zinkovich, M. Weimer, L. Li y A. J. Smola, "Descenso de degradado estocástico paralelo", en Procedimientos de avances en NIPS, 2010, pp. 2595–2603.
[4] D. Povey, X. Zhang, y S. Khudanpur, "Entrenamiento paralelo de DNN con degradado natural y promedio de parámetros", en Actas de la Conferencia Internacional sobre Representaciones de Aprendizaje, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Redes profundas distribuidas a gran escala. En Avances en los sistemas de procesamiento de información neuronal, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Anderson y Alexander Smola. "Servidor de parámetros para el aprendizaje automático distribuido". En Big Learning NIPS Workshop, vol. 6, p. 2. 2013.