Inside Microsoft.comManaging SQL Server 2005 Peer-to-Peer Replication
David Lindquist
The Microsoft corporate Web sites rely heavily on databases, which power such high-traffic destinations as Microsoft® Update, Download Center, Communities, TechNet, and MSDN®. Microsoft.com operations has a team of 17 engineers, the SQL Server™ operations team, that manages these database systems. In all, this team is responsible for more than 2250 active user databases that take up about 55.15TB of space on 291 production SQL Servers.
One system managed by this team hosts databases for internal content providers. These content providers are groups within Microsoft that publish content to the Web. They are located around the world and they all require database functionality behind their Internet-facing Web applications.
This environment has gone through different architectures as databases, functionality needs, and hosting strategies have changed. Currently, there are more than 100 databases consolidated in this environment. It is built on Windows Server™ 2003 SP1 Enterprise Edition and SQL Server 2000 SP4 running on six HP Proliant servers. Transactional replication is used to move data to and from a consolidator server, which serves the data to multiple live servers that are accessed by Web applications. A logshipping scenario is also used to provide failover and redundancy. Figure 1 illustrates the architecture.
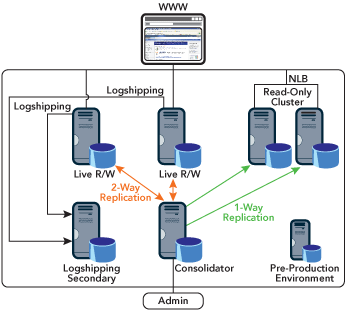
Figure 1** Current Architecture **
As the release of SQL Server 2005 approached, we were interested in a number of its new features and needed to put together a game plan for upgrading the environment. One feature in particular that we were interested in was a new flavor of transactional replication called peer-to-peer replication. With this configuration, all nodes in a topology are peers. Each node publishes and subscribes to the same schema and data. Changes (such as inserts, updates, and deletes) can be made at any node and the replication technology recognizes when a change has been applied to a given node, preventing changes from cycling through the nodes more than one time.
The SQL Server Books Online article "Replication Availability Enhancements" says that "in SQL Server 2000, transactional replication supported hierarchical topologies in which a Publisher owned the data that was replicated to Subscribers. Transactional replication with updating subscriptions supported Subscriber-side updates, but the Subscribers were classified as different types of participants in replication than the Publishers."
The article goes on to explain that SQL Server 2005 introduced a new peer-to-peer model that allows replication to occur between identical participants in the topology. This model is well suited to users who are running server-to-server configurations and also need to move the roles between replicated nodes dynamically to perform maintenance or to manage failure scenarios.
The thought of having the same database hosted on more than one server, where each was in sync with the others and each could be written to and read from sounded great. We could load balance the databases when there was no maintenance to be done, and when we needed to work on a server, we could pull it out of rotation while the other servers handled the load. The uptime, performance, and failover possibilities were quite attractive. (For a comparison of load balancing and failover scenarios, see the "Load Balancing Versus Failover Strategies" sidebar.)
Load Balancing Versus Failover Strategies
Strategy I: Load-Balancing Characteristics
Each production server hosts a read/write copy of the database. The databases are kept in sync using SQL Server 2005 peer-to-peer replication. Applications connect to the SQL cluster through the production interface using a host name that will distribute and load balance traffic between the four nodes.
Redundancy
There is a copy of the database on four different servers. If one node of the cluster becomes unavailable, the other nodes automatically pick up the traffic.
Availability
Each server can be taken out of the cluster individually so maintenance can be performed without causing the database to become unavailable.
Performance
Application calls to a database are load balanced between the four nodes of the cluster. Balancing the load should result in better performance during times of increased activity.
Strategy II: Failover Characteristics
Each production server hosts a read/write copy of the database. The databases are kept in sync using SQL Server 2005 peer-to-peer replication. Applications connect to one node of the SQL cluster using one of the virtual IP addresses on that cluster.
Redundancy
In the event the node taking traffic becomes unavailable or if the server needs to be taken down for maintenance, traffic is redirected (failed over) to the other node of the cluster. There is a current copy of the database on all four nodes for redundancy.
Availability
If the node of the cluster you are connecting to becomes unavailable or needs to be taken down for maintenance, traffic is directed to the other node of the cluster with minimal down time (only seconds).
Performance
The application is always connecting to one database in the topology.
Our Upgrade Strategy
We started our upgrade project by setting up two test servers in our lab. Each was running Windows Server 2003 SP1 and had two instances of prerelease SQL Server 2005. This gave us four nodes to test on. We then set up a test database on each instance and configured peer-to-peer for the first time. We found we could make data and schema changes in any of the four databases and the changes would replicate to the other nodes without a problem. We had initial proof of concept. The propagation of schema changes was a welcome feature. We could now alter tables, views, procedures, functions, and triggers (DML triggers only) and the changes would replicate to the other peers.
With 64-bit technology being adopted in the Microsoft datacenter (and considering the age of the internal content provider servers we had at the time) we decided to purchase new servers and implemented the configurations shown in Figure 2. (For more info on our move to 64-bit technology, see the January/February 2006 Inside Microsoft.com column.
Figure 2 New Datacenter Machines
| Model | OS | Processing | Memory | Application | |
| Production 4X | 64-bit HP ProLiant DL585 G1 | Windows Server 2003 Enterprise x64 Edition SP1 | Four single-core AMD Opteron 2.20GHz processors | 16GB | SQL Server 2005 SP1 |
| Pre-Production 2X | 64-bit HP ProLiant DL385 G1 | Windows Server 2003 Enterprise x64 Edition SP1 | Two dual-core AMD Opteron 2.21GHz processors | 8GB | SQL Server 2005 SP1 |
Load Balancing
Four of the servers are configured in two clusters behind the Microsoft.com Web servers using Network Load Balancing (NLB). The other two servers are set up in the datacenter for pre-production. We utilize a pre-production environment (PPE) so our users, the content providers, can set up their applications on servers that mimic the production servers. This way they can do some development and testing in an environment that has the same OS and application versions that their apps will run on in production. Figure 3 illustrates this setup.

Figure 3** Network Load Balancing Environment **
There are two network interface cards (NICs) in each server. The admin NIC is used by the owners of the database to manipulate the data. We give them db_datareader permissions in the database and insert, update, and delete permissions on certain tables so they can upload and offload data from their production database without having to engage us. The production NIC handles traffic to and from the Web servers along with replication traffic between the nodes.
For the production servers, we configured a pair of two-node clusters. We added a virtual IP address (VIP) for each pair on the admin NICs and another VIP for each pair on the production NICs. This allows us to manage the traffic from both sides of the clusters—the production side and the admin side. We created a DNS host name that round-robins between the two production VIPs so we can utilize all four nodes in load balancing.
We set up NLB in unicast mode and took advantage of a new capability available in Windows Server 2003 SP1 that allows two servers configured for NLB to communicate with each other over the NLB interface. For an explanation of this, see the Knowledge Base article "Unicast NLB nodes cannot communicate over an NLB-enabled network adaptor in Windows Server 2003".
As we did more testing with load balancing, the inherent latency in the system became obvious (meaning the time it takes between a transaction being committed at the Publisher and the corresponding transaction being committed at a Subscriber). There was no getting around the fact that it would take a fixed amount of time for data to replicate from one node to the other three. This meant that some database design considerations had to be addressed.
Design Considerations
With load balancing, there is no guarantee that each time an application makes a call to a database it will connect to the same database. We found that load balancing works for read-only and some write-only databases. However, an application that needs to maintain any kind of session state can encounter problems. With load balancing in place, we weren’t able to guarantee that each time the application made a call to the clusters it would go to the same database. Worse yet, because the Web servers were also clustered, we could not guarantee that subsequent calls from an application would come from the same Web server.
This can cause problems, for example, if an application needs to read data immediately after it has been entered. Say an application stores a change a user makes to the data and then the application immediately reads that data in order to display it back to the user. If the application connects to one database to store the data, but connects to a different database to read it back, the second database may not have the updated data yet (because it hasn’t had time to replicate) and the old data is returned to the user.
We had to devise some way to guarantee that an application would hit the same database every time it made a call while still being able to maintain our availability requirement. After some investigation, we found that it is possible to create multiple VIPs on a pair of NLB-configured interfaces and control those VIPs independently of other VIPs configured on the same interfaces. This meant we could create a second production VIP on one of the clusters. By pushing 100 percent of the traffic from this VIP to one node of the cluster, we were able to guarantee that an application would hit the same database every time it made a call to the VIP. This gave us the flexibility to control the traffic utilizing this VIP between the two cluster nodes, and it allowed us the ability to failover from one node to the other.
Foreign key constraints can also be affected by the peer-to-peer latency. For example, imagine you have a foreign key that requires a value in the primary key column of a particular row in Table 1 before the foreign key value in Table 2 can be inserted. If an entry is made in the PK column of Table 1 DB1, but does not replicate to Table 1 DB2 in time, and the application tries to make an entry in the foreign key column of Table 2 DB2, it will fail because the necessary primary key value is not yet in place. Of course, if the entire procedure is handled in the same database connection, there is no problem. But if this is handled in separate calls from the Web server within seconds of each other, there is a potential for failure.
When tables contain identity columns that are configured as primary keys, there are considerations that must be addressed for both load balancing and failover scenarios. For example, when a row from a Publisher table with an identity value is replicated to a Subscriber table, and the Not For Replication property is set on that column at the Publisher, the row values are inserted in the Subscriber table but the insert does not increment the identity value. The result is that when an application tries to add a row directly to the Subscriber table (which would now be the Publisher) it fails because there is already an entry in the identity column with the next identity value because it was replicated from the original Publisher.
Identity columns can be addressed in two ways. First, a new column can be created in a table that has an identity column. This column is an integer data type (adding 4 bytes to the row) and defaults to the specific server ID where that instance of the database resides. For example, if the server ID of the first node is 1, the second is 2, and so on, the new column on the first node would default to 1, the new column on the second node would default to 2, and so forth. This new column, or SRVID column, and the identity column are configured as a composite primary key. This effectively ensures a unique key value on each node of the cluster and mitigates the duplicate key violation issue.
The second option is to seed each identity value on each node with its own range of values. This assures that each identity value remains unique across the four instances of the database. To reduce the maintenance of this approach, the identity columns are created as a bigint data type. We use bigint so we have enough overhead to create large ranges (a billion) that require less reseeding. For example, the range for node one starts at 1, the node two range starts at 1,000,000,001, the node three range starts at 2,000,000,001, and the range for node four starts at 3,000,000,001. This approach also adds 4 bytes to the row because bigint takes up 8 bytes instead of the 4 bytes taken up by the integer data type.
In Production
The beauty of this system is the flexibility that allows us to host a variety of databases in different configurations. We can take advantage of the fact that we have four servers and spread the load across all four, or two or three, or even send traffic to just one.
The majority of the databases in this environment connect through a data source name (DSN) that is configured in the registry on the Web servers. The DSN is how we control the traffic. We have a script that rolls DSN changes through the Web servers. If a DSN is pointing to the host name that balances the load between all four servers, we can run the script to change the DSN, one server at a time, to point to one node of the cluster. We can then make any changes to the database and verify that the changes replicate successfully to the other three nodes before resetting the DSN to point to the host name that provides load balancing between the cluster nodes. Also, if for some reason we have a replication problem while the DSN is pointing to the one node, we can tear down replication and set it back up again before pointing the DSN at the other three nodes. We can do all of this while the site continues to make successful calls to the database.
With the failover strategy, the application is already making calls to one database. So we can make changes on that one node without worrying about the availability of the other nodes since they are not being accessed directly by the application.
One thing to keep in mind is that the environment can become very complex very quickly. For each database, there is a publication and three subscriptions, one to each of the other three nodes. This means there are four copies of a database (one on each node), four publications (one on each node), and twelve subscriptions for each database (three on each node). Thus, the number of jobs and processes running on the servers can increase substantially. For instance, when we get 100 distinct databases in this environment, it adds up to 400 databases, 400 publications, and 1200 subscriptions.
Multiple VIPs on the interfaces can also create complexity. If the interface connections are not well documented and well understood, the failover VIP can be managed incorrectly, resulting in a group of databases in the environment becoming unavailable.
The identity value is one of the biggest hurdles to get over. This is because a lot of developers use the identity value to identify a logical entity, such as a business name, contact name, or product name. This can cause some unexpected development time needed to adapt an existing application to a composite primary key that includes the new server ID column and the identity column. We think the payoff is worth the work, but if the server ID column cannot be added, the identity ranges will need to be seeded and this seeding will need to be managed. One way to manage it is to create a SQL Server Agent job that monitors the incremented value of the identity columns in the database tables. If the value reaches a certain threshold, a stored procedure is run to reseed the identity value.
Being able to rebuild replication after a failure has been critical. If the data becomes inconsistent in the databases, we must point the traffic to one node and then investigate and resolve the differences between tables on the other nodes. There is a new utility that ships with SQL Server 2005 called tablediff.exe. This has proven very useful in identifying the differences between tables and building a script that corrects the differences. Once all the data has been recovered to the one live database, replication can be rebuilt and the DSN pointed back to the cluster.
We are now using peer-to-peer replication successfully for a variety of data sources throughout Microsoft. Moving forward, we have plans to implement a geo-clustering solution to add even further resiliency and redundancy to this infrastructure.
David Lindquist is a System Engineer / MCDBA on the Microsoft.com operations team. He has worked in operations at Microsoft since October 1999 and has been in his current position for the past year and a half. David lives near the Microsoft campus with his wife and two cats. You can reach him at davl@microsoft.com.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.