SQL Server
Buenos consejos para el mantenimiento eficaz de bases de datos
Paul S. Randal
De un vistazo:
- Administración de datos y archivos de registro de transacciones
- Eliminación de la fragmentación de índices
- Cómo garantizar estadísticas exactas y actualizadas
- Detección de páginas dañadas en la base de datos
- Establecimiento de una estrategia eficaz de copias de seguridad
Contenido
Administración de archivos de datos y archivos de registro
Fragmentación de índices
Estadísticas
Detección de daños
Copias de seguridad
Conclusión
Varias veces por semana me piden consejo sobre cómo mantener de forma efectiva bases de datos de producción. A veces estas preguntas provienen de administradores de bases de datos que están implementando nuevas soluciones y necesitan ayuda
para optimizar las prácticas de mantenimiento y así adaptarse a las características nuevas de sus bases de datos. Con mayor frecuencia, sin embargo, las preguntas me llegan de personas que no son administradores profesionales de bases de datos y a quienes, por alguna razón, les han asignado la propiedad y la responsabilidad de una base de datos. A estas personas me gusta llamarlas "administradores de bases de datos involuntarios". El objetivo de este artículo es proporcionar una guía de buenas prácticas para el mantenimiento de bases de datos dirigida a todos los administradores de bases de datos involuntarios que hay por el mundo.
Al igual que con la mayoría de tareas y procedimientos en el mundo de las tecnologías de la información, no hay una solución universal y fácil para el mantenimiento eficaz de bases de datos, aunque sí hay una serie de áreas clave que casi siempre necesitan abordarse. Mis cinco áreas principales de interés (no por orden de importancia) son:
- Administración de archivos de datos y archivos de registro
- Fragmentación de índices
- Estadísticas
- Detección de daños
- Copias de seguridad
Una base de datos sin mantenimiento (o mal mantenida) puede desarrollar problemas en una o más de estas áreas, lo cual a largo plazo puede provocar un mal rendimiento de la aplicación o incluso tiempos de inactividad y pérdida de datos.
En este artículo explicaré la razón por la que estos problemas son importantes y mostraré unos métodos sencillos para mitigar los problemas. Basaré mis explicaciones en SQL Server® 2005 y resaltaré asimismo las principales diferencias que encontraremos en SQL Server 2000 y la siguiente versión de SQL Server 2008.
Administración de archivos de datos y archivos de registro
La primera área que siempre recomiendo comprobar a la hora de hacerse cargo de una base de datos es la configuración de la administración de archivos de datos y archivos de registro (de transacciones). Concretamente, debe comprobar lo siguiente:
- Que los archivos de datos y archivos de registro están separados entre sí además de aislados de todo lo demás.
- Que el crecimiento automático está configurado correctamente.
- Que la inicialización instantánea de archivos está configurada.
- Que la autorreducción no está habilitada y la reducción no forma parte de ningún plan de mantenimiento.
Cuando los archivos de datos y de registro (que lo ideal sería que estuvieran en volúmenes completamente separados) comparten el mismo volumen/tamaño que cualquier otra aplicación que crea o amplía archivos, existirá la posibilidad de que los archivos se fragmenten. En los archivos de datos, la excesiva fragmentación de archivos puede ser un factor que contribuya en cierta medida a realizar mal las consultas (especialmente aquellas que recorren grandes cantidades de datos). En los archivos de registro, la fragmentación puede tener mucho mayor efecto en el rendimiento, especialmente si la función de crecimiento automático está activada para aumentar el tamaño de los archivos con una cantidad muy pequeña cada vez que es necesario.
Los archivos de registro se dividen internamente en secciones llamadas archivos de registro virtuales (VLF). Cuanto mayor sea la fragmentación del archivo de registro (empleo el singular aquí porque no supone ninguna ventaja tener múltiples archivos de registro, debería haber solamente uno por cada base de datos), mayor número de archivos VLF habrá. Cuando un archivo de registro tiene más de, pongamos, 200 archivos de registro virtuales, el rendimiento se puede ver afectado de forma negativa cuando efectúa operaciones relacionadas con el registro, tales como la lectura de registros (para las réplicas o reversiones transaccionales, por ejemplo), las copias de seguridad de registros e incluso los desencadenadores en SQL Server 2000 (la implementación de desencadenadores se ha cambiado en SQL Server 2005 al marco del control de versiones de filas en lugar del registro de transacciones).
El procedimiento recomendado con respecto al tamaño de los archivos de datos y de registro es crearlos con un tamaño inicial adecuado. En el tamaño inicial de los archivos de datos se debe tener en cuenta que existe la posibilidad de que a corto plazo se agreguen datos adicionales a la base de datos. Por ejemplo, si el tamaño inicial de los datos es 50 GB, pero se sabe que en los seis meses siguientes se agregarán otros 50 GB de datos, tiene más sentido crear directamente un archivo de datos de 100 GB que tener que aumentarlo varias veces para alcanzar ese tamaño.
Por desgracia, esto se complica un poco más para los archivos de registro y tendrá que considerar factores como el tamaño de las transacciones (las transacciones de larga ejecución no pueden eliminarse del registro hasta que se hayan completado) y la frecuencia de copias de seguridad del registro (ya que esto es lo que elimina la parte inactiva del registro). Para más información, consulte el mensaje "8 Steps to Better Transaction Log Throughput" escrito por mi esposa, Kimberly Tipp, en el blog SQLskills.COM.
Una vez definidos, los tamaños de archivo deben controlarse a varias horas del día y aumentarse manualmente de forma proactiva en un momento adecuado del día. La opción de crecimiento automático debe dejarse activada como medida preventiva para así permitir que los archivos puedan crecer si ocurrieran eventos anómalos. La lógica en contra de dejar la administración de archivos enteramente en manos del crecimiento automático es que el crecimiento automático de pequeñas cantidades provoca la fragmentación de archivos y puede convertirse en un proceso largo y lento que atasque la carga de trabajo de la aplicación en tiempos imprevisibles.
El tamaño del crecimiento automático debe establecerse en un valor específico en lugar de en un porcentaje, para de este modo enlazar el tiempo y el espacio necesario para llevar a cabo el crecimiento automático, si fuera necesario. Imaginemos, por ejemplo, que quiere definir un archivo de datos de 100 GB para que tenga un tamaño fijo de crecimiento automático de 5 GB en lugar de, digamos, el 10 por ciento. Esto significa que siempre crecerá 5 GB independientemente de lo grande que acabe siendo el archivo, en vez de incrementar siempre una cantidad determinada (10 GB, 11 GB, 12 GB, etc.) cada vez que el archivo aumente de tamaño.
Cada vez que se aumente un registro de transacciones (ya sea manualmente o a través de crecimiento automático) éste se inicializará a cero. Los archivos de datos tienen el mismo comportamiento predeterminado en SQL Server 2000, pero si empieza con SQL Server 2005 puede habilitar la inicialización instantánea de archivos, con lo que se omite la inicialización a cero de los archivos y se consigue, por tanto, que el crecimiento y el crecimiento automático sean prácticamente instantáneos. Al contrario de lo que muchos creen, esta característica está disponible en todas las ediciones de SQL Server. Para más información, introduzca "inicialización instantánea de archivos" en el índice de los Libros en pantalla de SQL Server 2005 o SQL Server 2008.
Por último, debe tener cuidado de que la función de reducción no esté habilitada en ningún caso. Esta función puede usarse para reducir el tamaño de un archivo de datos o de registro, si bien es un proceso muy intrusivo que consume muchos recursos y que causa grandes cantidades de fragmentación de exploración lógica en archivos de datos (para obtener más detalles, consulte más abajo) y conlleva un bajo rendimiento. He cambiado la entrada en los Libros en pantalla de SQL Server 2005 por reducir para añadir una advertencia al respecto. No obstante, la reducción manual de archivos de datos y de registro individuales puede ser aceptable en circunstancias especiales.
La reducción automática es el peor atacante ya que se inicia cada 30 minutos en segundo plano y trata de reducir las bases de datos que tienen la opción de reducción automática activada. Es un proceso algo impredecible en el que sólo se reducen las bases de datos con más del 25 por ciento de espacio libre. La reducción automática usa muchos recursos y provoca una fragmentación que disminuye el rendimiento, por eso no es una buena estrategia en ningún caso. Debe desactivar siempre la reducción automática con el siguiente código:
ALTER DATABASE MyDatabase SET AUTO_SHRINK OFF;
Tener un plan periódico de mantenimiento que contemple un comando manual de reducción de la base de datos es una idea casi igual de mala. Si cree que su base de datos crece continuamente después de que el plan de mantenimiento la haya reducido, eso se debe a que la base de datos necesita ese espacio para ejecutarse.
Lo mejor que puede hacer es permitir que la base de datos crezca hasta alcanzar un tamaño estable y evitar ejecutar la reducción. Puede encontrar más información sobre las desventajas de utilizar la reducción además de comentarios acerca de los nuevos algoritmos de SQL Server 2005 en mi antiguo blog de MSDN® en blogs.msdn.com/sqlserverstorageengine/archive/tags/Shrink/default.aspx.
Fragmentación de índices
Aparte de la fragmentación a nivel de sistema de archivos y dentro del archivo de registro, también es posible hacer fragmentaciones dentro de los archivos de datos, en las estructuras que almacenan los datos de tabla e índice. Hay dos tipos básicos de fragmentación que puede ocurrir dentro de un archivo de datos:
- Fragmentación dentro de páginas individuales de datos e índices (a veces denominada fragmentación interna)
- Fragmentación dentro de las estructuras de índice o tabla formadas por páginas (denominada fragmentación de exploración lógica y fragmentación de exploración de extensión)
La fragmentación interna es aquella en la que hay mucho espacio vacío en una página. Como se muestra en la figura 1 , cada página de una base de datos tiene un tamaño de 8 KB y un encabezado de 96 bytes; por tanto, una página puede almacenar unos 8.096 bytes de datos de tabla o índice (hallará información interna específica de tablas e índices para estructuras de datos y de filas en la categoría "Inside the Storage Engine" de mi blog, sqlskills.com/blogs/Paul). Puede llegar a generarse espacio en blanco si cada registro de tabla o de índice ocupa más de la mitad del tamaño de una página, ya que sólo se puede almacenar un registro por página. Esto puede ser muy difícil o imposible de corregir dado que requeriría cambios en el esquema de la tabla o del índice, por ejemplo cambiar una clave de índice para que no cause la inserción aleatoria de puntos como hace un GUID.
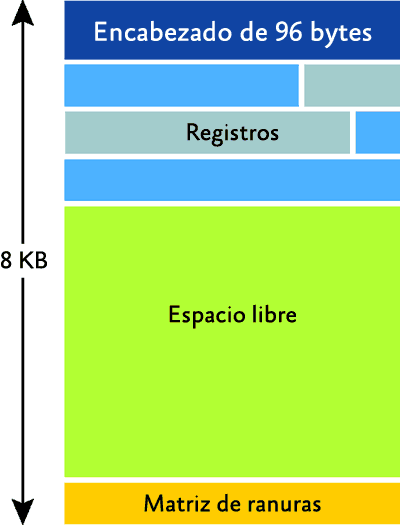
Figura 1 Estructura de la página de una base de datos (haga clic en la imagen para ampliarla)
Con mayor frecuencia, la fragmentación interna es el resultado de la modificación de datos, como inserciones, actualizaciones y eliminaciones, operaciones estas que pueden dejar espacios en blanco en una página. La mala administración del factor de relleno también puede llegar a contribuir a la fragmentación; consulte los Libros en pantalla para obtener más información al respecto. Dependiendo del esquema de tabla/índice y las características de la aplicación, es posible que este espacio en blanco, una vez creado, nunca se pueda volver a usar y además puede provocar el crecimiento incesante de cantidades de espacio no utilizado en la base de datos.
Imagínese, por ejemplo, una tabla de 100 millones de filas con un tamaño medio de registro de 400 bytes. Con el tiempo, el modelo de modificación de datos de la aplicación deja en cada página un promedio de 2.800 bytes de espacio libre. El espacio total necesario para la tabla ronda los 59 GB, calculado teniendo en cuenta que 8.096-2.800/400 = 13 registros por 8 KB por página, y después dividiendo 100 millones entre 13 para de esta forma obtener el número de páginas. Si no se ha malgastado el espacio, deberían caber 20 registros por página, reduciendo así el espacio total necesario a 38 GB. ¡Esto supone un ahorro enorme!
Por tanto, el espacio malgastado en páginas de datos o de índices provoca que se necesiten más páginas para albergar la misma cantidad de datos. Esto no sólo ocupa más espacio en el disco, sino que además significa que las consultas tienen que emitir más E/S para leer la misma cantidad de datos. Y todas estas páginas adicionales ocupan más espacio en la memoria caché de datos, consumiendo así más memoria del servidor.
La fragmentación de exploración lógica es causada por una operación denominada división de página. Esto ocurre cuando se quiere insertar un registro en una página específica del índice (con arreglo a la definición de la clave de índice) y no hay suficiente espacio en la página para albergar los datos que se desean insertar. Se divide la página por la mitad y se mueve aproximadamente el 50 por ciento de los registros a una página nueva. Generalmente, esta página nueva no es físicamente contigua a la página previa, por eso se dice que está fragmentada. La fragmentación de exploración de extensión tiene un concepto similar. La fragmentación dentro de estructuras de tabla/índice afecta a la capacidad de SQL Server para hacer exploraciones eficaces, ya sea de una tabla/un índice enteros o limitados por una cláusula WHERE (como SELECT * FROM MyTable WHERE Column1 > 100 AND Column1 < 4000).
La figura 2 muestra las páginas de índice recién creadas con un factor de relleno del 100 por ciento y ninguna fragmentación (las páginas están llenas y el orden físico de las páginas coincide con el orden lógico). La figura 3 muestra la fragmentación que se puede producir tras inserciones/actualizaciones/eliminaciones aleatorias.
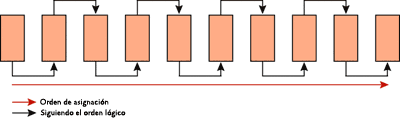
Figura 2 Páginas de índice recién creadas sin fragmentación; páginas llenas al 100% (haga clic en la imagen para ampliarla)
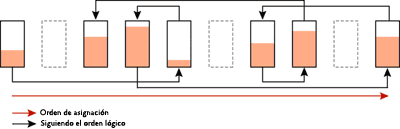
Figura 3 Páginas de índice con fragmentación interna y fragmentación de exploración lógica tras inserciones, actualizaciones y eliminaciones aleatorias (haga clic en la imagen para ampliarla)
A veces se pueden prevenir fragmentaciones cambiando el esquema de tabla/índice pero, como mencioné anteriormente, puede resultar una tarea muy difícil o imposible. Si la prevención no es una opción, existen otras maneras de eliminar la fragmentación una vez que se ha producido; en particular, mediante la regeneración o reorganización de un índice.
Regenerar un índice implica crear una nueva copia del índice, bien compactado y tan contiguo como sea posible, y después eliminar el antiguo índice fragmentado. Puesto que SQL Server crea una copia nueva del índice antes de eliminar la antigua, se necesitará tanto espacio libre en los archivos de datos como el aproximadamente equivalente al tamaño del índice. En SQL Server 2000, la regeneración de un índice siempre era una operación sin conexión. En SQL Server 2005 Enterprise Edition, sin embargo, la regeneración de índices puede realizarse en línea, con unas pocas restricciones. La reorganización, por otro lado, usa un algoritmo local para compactar y desfragmentar el índice; requiere solamente 8 KB de espacio adicional para ejecutarse y siempre se ejecuta en línea. De hecho, en SQL Server 2000 escribí específicamente el código de reorganización del índice como una alternativa en línea y eficiente en espacio para regenerar índices.
En SQL Server 2005, los comandos para investigar son ALTER INDEX … REBUILD, para regenerar índices, y ALTER INDEX … REORGANIZE, para reorganizarlos. Esta sintaxis reemplaza los comandos de SQL Server 2000 DBCC DBREINDEX y DBCC INDEXDEFRAG, respectivamente.
Hay muchas similitudes entre estos métodos, como la cantidad de registros de transacciones generados, la cantidad de espacio libre necesario en la base de datos y si el proceso es interrumpible sin causar pérdidas de trabajo. Encontrará un artículo técnico que aborda estas similitudes, entre otras cosas, en microsoft.com/technet/prodtechnol/sql/2000/maintain/ss2kidbp.mspx. Aunque este documento se basa en SQL Server 2000, los conceptos se aplican igualmente a versiones posteriores.
Algunas personas sencillamente prefieren volver a generar o reorganizar los índices cada noche o cada semana (usando una opción de plan de mantenimiento, por ejemplo) en lugar de averiguar qué índices están fragmentados y si se sacará algún beneficio de eliminar la fragmentación. Aunque esta puede ser una buena solución para un administrador de bases de datos involuntario que desea poner algo en su sitio con el mínimo esfuerzo, tenga en cuenta que puede ser una mala elección para bases de datos o sistemas más grandes, donde escasean los recursos.
Un enfoque más sofisticado implica usar la DMV (vista de administración dinámica) sys.dm_db_index_physical_stats (o DBCC SHOWCONTIG en SQL Server 2000) para determinar periódicamente qué índices se fragmentan y después decidir si y cómo operar en ellos. El artículo técnico también analiza el uso de estas elecciones más sistemáticas. Asimismo puede consultar código de ejemplo para hacer este filtrado en el ejemplo D de la entrada de los Libros en pantalla para la DMV sys.dm_db_index_physical_stats en SQL Server 2005 (msdn.microsoft.com/library/ms188917) o el ejemplo E de la entrada de los Libros en pantalla para el comando DBCC SHOWCONTIG en SQL Server 2000 y versiones posteriores (en msdn.microsoft.com/library/aa258803).
Sea cual sea el método que utilice, es altamente recomendable investigar y corregir la fragmentación con regularidad.
El procesador de consultas es la parte de SQL Server que decide cómo se debe ejecutar una consulta, concretamente qué tablas e índices se usarán y qué operaciones se llevarán a cabo para obtener resultados; lo que se conoce como plan de consulta. Algunas de las entradas más importantes en este proceso de toma de decisiones son las estadísticas, que describen la distribución de valores de datos entre columnas dentro de una tabla o un índice. Obviamente, las estadísticas deben ser exactas y recientes para que le resulten útiles al procesador de consultas, si no se provocará un mal rendimiento del plan de consulta.
Las estadísticas se generan leyendo los datos de las tablas o índices y determinando la distribución de datos entre las columnas pertinentes. Las estadísticas se pueden crear recorriendo todos los valores de datos de una columna en concreto (recorrido completo), aunque también se pueden basar en un porcentaje de datos definido por el usuario (recorrido de muestra). Si la distribución de valores en una columna está bien compensada, entonces bastará con un recorrido de muestra, lo que resultará más rápido que crear y actualizar las estadísticas con un recorrido completo.
Tenga en cuenta que es posible crear y mantener estadísticas automáticamente estableciendo las opciones de base de datos AUTO_CREATE_STATISTICS y AUTO_UPDATE_STATISTICS en ON, como se muestra en la figura 4. Estas opciones están activadas de forma predeterminada, pero si acaba de heredar una base de datos se recomienda comprobarlo para asegurarse. Cuando las estadísticas se quedan desfasadas es posible actualizarlas manualmente con la instrucción UPDATE STATISTICS en conjuntos específicos de estadísticas. También se puede usar el procedimiento almacenado sp_updatestats, que actualiza todas las estadísticas desfasadas (en SQL Server 2000, sp_updatestats actualiza todas las estadísticas, independientemente de su antigüedad).
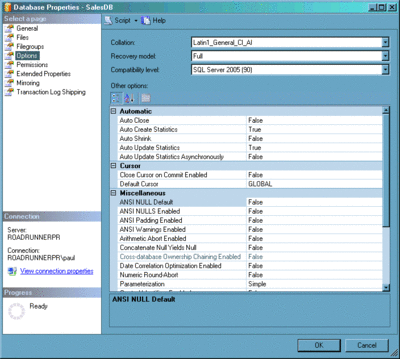
Figura 4 Cambios en la configuración de la base de datos a través de SQL Server Management Studio (haga clic en la imagen para ampliarla)
Si desea actualizar las estadísticas en el marco de su plan periódico de mantenimiento, hay un truco que debería considerar. Tanto UPDATE STATISTICS como sp_updatestats se vuelven de manera predeterminada al nivel de muestreo anteriormente especificado (si existe), que puede ser menos que un recorrido completo. El índice regenera automáticamente estadísticas de actualización con un recorrido completo. Si actualiza estadísticas manualmente tras una regeneración de índice, es posible que acabe con estadísticas menos precisas. Esto puede ocurrir si el recorrido de muestra de la actualización manual sobrescribe el recorrido completo provocado por la regeneración de índice. Por otro lado, al reorganizar índices no se actualizan las estadísticas.
Repito, hay muchas personas que tienen un plan de mantenimiento que actualiza todas las estadísticas en algún momento antes o después de regenerar todos los índices (y sin saberlo acaban teniendo unas estadísticas probablemente menos precisas). Si sencillamente opta por regenerar todos los índices cada cierto tiempo, de esta forma también se ocupará de las estadísticas. Si decide tomar una vía más compleja con eliminación de fragmentación, también debe hacerlo para el mantenimiento de las estadísticas. Sugiero que haga lo siguiente:
- Analice los índices y determine cómo y en cuáles va a aplicar la eliminación de fragmentación.
- Actualice las estadísticas de todos los índices no regenerados.
- Actualice las estadísticas de todas las columnas no indizadas.
Para obtener más información sobre estadísticas, consulte el artículo técnico "Estadísticas usadas por el optimizador de consultas en Microsoft® SQL Server 2005" (microsoft.com/technet/prodtechnol/sql/2005/qrystats.mspx).
Detección de daños
Hasta el momento he hablado del mantenimiento relacionado con el rendimiento. Ahora voy a cambiar de tercio y tratar la detección y mitigación de daños.
Es muy improbable que la base de datos que está administrando contenga información completamente inútil que no le interese a nadie, entonces ¿cómo puede hacer para asegurarse de que no se dañen los datos y que éstos se puedan recuperar en caso de desastre? Los detalles acerca de cómo crear una estrategia de recuperación en caso de desastre y de alta disponibilidad quedan fuera del ámbito de este artículo, si bien hay unas cuantas cosas que puede ir haciendo para empezar.
La gran mayoría de los daños son causados por el "hardware". ¿Por qué lo escribo entre comillas? Bueno, en realidad el hardware se emplea aquí como forma abreviada para "algo en el subsistema de E/S dentro de SQL Server". El subsistema de E/S está formado por elementos tales como el sistema operativo, los controladores del sistema de archivos, los controladores de dispositivos, los controladores RAID, los cables, las redes y las propias unidades de disco reales. Son muchos sitios donde pueden (y suelen) surgir problemas.
Uno de los problemas más comunes se produce cuando falla el suministro eléctrico y una unidad de disco está en pleno proceso de escritura de una página en la base de datos. Si la unidad de disco no consigue completar el proceso de escritura antes de quedarse sin electricidad (o las operaciones de escritura se copian en caché y no hay suficiente batería de reserva para vaciar la memoria caché de la unidad), el resultado podría ser una imagen de página incompleta en el disco. Esto puede suceder porque una página de base de datos de 8 KB está compuesta por 16 sectores contiguos de disco de 512 bytes. Una escritura incompleta podría escribir algunos de los sectores de la página nueva pero dejar algunos de los sectores de la imagen de la página anterior sin escribir. Esta situación se conoce como página rasgada. ¿Cómo se detecta esto cuando sucede?
SQL Server tiene un mecanismo para detectar esta situación. Consiste en almacenar un par de bits de cada sector de la página y escribir un patrón específico en su lugar (esto sucede poco antes de que se escriba la página en el disco). Si el patrón no es el mismo cuando la página se vuelve a leer, SQL Server sabrá que la página se ha "rasgado" y generará un error.
En SQL Server 2005 y versiones posteriores se incluye un mecanismo más completo llamado sumas de comprobación de página que puede detectar cualquier daño en una página. Consiste en escribir una suma de comprobación de una página completa en la página justo antes de de escribirla en el disco y después probarla cuando la página se vuelva a leer, igual que para detectar páginas rasgadas. Tras habilitar las sumas de comprobación de página, habrá que leer una página en el grupo de búferes, cambiarla de alguna manera y luego escribirla al disco otra vez antes de que una suma de comprobación de página la proteja.
Por tanto, se recomienda tener las sumas de comprobación de página activadas para SQL Server 2005 en adelante, con la detección de páginas rasgadas habilitada para SQL Server 2000. Para habilitar sumas de comprobación de página puede usar:
ALTER DATABASE MyDatabase SET PAGE_VERIFY CHECKSUM;
Para habilitar la detección de páginas rasgadas en SQL Server 2000 puede usar:
ALTER DATABASE MyDatabase SET TORN_PAGE_DETECTION ON;
Con estos mecanismos puede detectar que una página contiene errores, pero solamente al leerla. ¿Cómo forzar fácilmente que se lean todas las páginas asignadas? El mejor método para hacer esto (y para encontrar cualquier otra clase de error) es usar el comando DBCC CHECKDB. A pesar de las opciones especificadas, este comando siempre leerá todas las páginas de la base de datos, causando por tanto que se verifiquen todas las sumas de comprobación de página o detecciones de páginas rasgadas. También debe activar alertas para saber en qué momento los usuarios se encuentran con errores durante la ejecución de consultas. Puede recibir notificaciones de todos los problemas descritos arriba usando una alerta para errores de gravedad 24 (figura 5).
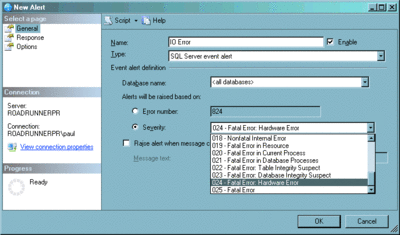
Figura 5 Configuración de una alerta para los errores de gravedad 24 (haga clic en la imagen para ampliarla)
También es una buena costumbre ejecutar regularmente DBCC CHECKDB en las bases de datos con el objetivo de comprobar su integridad. Hay muchas variantes de este comando y tantas otras preguntas acerca de la frecuencia con que debe ejecutarse. Por desgracia, no hay artículos técnicos que traten este tema. Sin embargo, como DBCC CHECKDB es la parte principal de código que escribí para SQL Server 2005, he tratado este asunto extensamente en mi blog. Consulte la categoría "CHECKDB From Every Angle" de mi blog (sqlskills.com/blogs/paul), donde encontrará numerosos artículos sobre comprobaciones de coherencia, prácticas recomendadas y consejos prácticos. Para administradores de bases de datos involuntarios, la regla general es ejecutar un DBCC CHECKDB tan a menudo como se hagan copias de seguridad completas de la base de datos (más adelante hallará más información al respecto). Recomiendo ejecutar el siguiente comando:
DBCC CHECKDB ('MyDatabase') WITH NO_INFOMSGS,
ALL_ERRORMSGS;
Si este comando da resultados, DBCC habrá hallado daños en la base de datos. La pregunta siguiente será qué hacer si DBCC CHECKDB encuentra errores. Aquí es donde entran en juego las copias de seguridad.
Cuando ocurre un daño u otro desastre, la manera más efectiva de recuperar datos es restaurando la base de datos a partir de copias de seguridad. Ahora bien, con esto se da por supuesto que hay copias de seguridad y que éstas no están dañadas. Pasa con demasiada frecuencia que las personas que desean saber cómo conseguir que una base de datos dañada vuelva a funcionar no disponen de copias de seguridad. La respuesta fácil es que, sencillamente, no puede, no sin experimentar algún tipo de pérdida de datos que podría hacer estragos en su lógica empresarial e integridad de sus datos relacionales.
Así que aquí tenemos un ejemplo muy claro de por qué realizar copias de seguridad con regularidad. Si bien es cierto que las implicaciones de usar copias de seguridad y restaurar quedan fuera del ámbito de este artículo, me permiten ofrecerle una ayuda rápida sobre cómo establecer una estrategia de copias de seguridad.
En primer lugar debe efectuar con regularidad copias de seguridad completas de la base de datos. De este modo creará una única versión puntual de lo que podrá restaurar más adelante. Para realizar un copia de seguridad completa de la base de datos use el comando BACKUP DATABASE. Consulte ejemplos en los Libros en pantalla. Para mayor protección, puede usar la opción WITH CHECKSUM, que comprueba las sumas de comprobación de página (si existen) de las páginas que se están leyendo y calcula una suma de comprobación de toda la copia de seguridad. Debe seleccionar una frecuencia que refleje cuántos datos o trabajo podría estar dispuesto a perder su negocio. Por ejemplo, realizar una copia de seguridad completa de la base de datos una vez al día significa que se podría perder hasta el valor de los datos de un día en caso de desastre. Si sólo usa copias de seguridad completas de la base de datos, debería estar en el modelo de recuperación SIMPLE (denominado comúnmente modo de recuperación) para así evitar complicaciones relacionadas con la administración del crecimiento del registro de transacciones.
En segundo lugar, conserve siempre las copias de seguridad durante unos cuantos días para el caso de que alguna de ellas estuviera dañada (una copia de seguridad de hace unos días siempre es mejor que ninguna copia de seguridad). También debe comprobar la integridad de sus copias de seguridad, para ello use el comando RESTORE WITH VERIFYONLY (una vez más, consulte los Libros en pantalla). Si utilizó la opción WITH CHECKSUM cuando se creó la copia de seguridad, ejecutar el comando de verificación comprobará que la suma de comprobación de la copia de seguridad todavía es válida y revisará todas las sumas de comprobación de las páginas contenidas en la copia de seguridad.
En tercer lugar, si realizar cada día una copia de seguridad completa de la base de datos no es suficiente para cumplir con la pérdida máxima de datos/trabajo que admite su negocio, se recomienda investigar las copias de seguridad diferenciales de la base de datos. Una copia de seguridad diferencial de la base de datos se basa en una copia de seguridad completa de la base de datos y contiene un registro de todos los cambios producidos desde la última copia de seguridad completa de la base de datos (un error que se comete a menudo es creer que las copias de seguridad diferenciales son incrementales, y no lo son). Un ejemplo de estrategia podría ser efectuar una copia de seguridad diaria completa de la base de datos con una copia de seguridad diferencial de la base de datos cada cuatro horas. Las copias de seguridad diferenciales ofrecen una única opción extra de recuperación a un momento dado. Si sólo usa copias de seguridad completas y diferenciales de la base de datos, debe seguir usando el modelo de recuperación simple.
Para finalizar, lo último en recuperación son las copias de seguridad de registros. Éstas sólo están disponibles en los modelos de recuperación FULL (o BULK_LOGGED) y proporcionan una copia de seguridad de todos los registros generados desde la última copia de seguridad de registros. Mantener un conjunto de copias de seguridad de registros con copias de seguridad completas de la base de datos (y quizás copias diferenciales de la base de datos) proporciona un número ilimitado de versiones a un momento dado para recuperar, incluida una recuperación actualizada. Debe tenerse en cuenta que el registro de transacciones continuará creciendo a no ser que se "libere" efectuando una copia de seguridad de registros. Un ejemplo para este caso sería realizar una copia de seguridad completa de la base de datos cada día, una copia de seguridad diferencial de la base de datos cada cuatro horas y una copia de seguridad de registros cada media hora.
Optar por una estrategia de copias de seguridad y configurarla puede ser una tarea complicada. Como mínimo, debe realizar una copia de seguridad periódica completa de la base de datos para asegurarse de que tiene por lo menos una copia a un momento dado desde la que recuperar información.
Como puede ver, para garantizar que su base de datos permanezca en buen estado y disponible hay unas cuantas tareas que tiene que realizar. He aquí mi lista de comprobación final para un administrador de base de datos involuntario que se hace cargo de una base de datos:
- Elimine la fragmentación excesiva del archivo de registro de transacciones.
- Establezca el crecimiento automático correctamente.
- Desactive las operaciones de reducción programadas.
- Active la inicialización instantánea de archivos.
- Implemente un proceso periódico para detectar y eliminar la fragmentación de índices.
- Establezca AUTO_CREATE_STATISTICS y AUTO_UPDATE_STATISTICS en ON e implemente un proceso periódico para actualizar estadísticas.
- Active la opción de sumas de comprobación de página (o, como mínimo, la detección de páginas rasgadas en SQL Server 2000).
- Disponga de un proceso periódico para ejecutar DBCC CHECKDB.
- Implemente un proceso periódico para efectuar copias de seguridad completas de la base de datos, además de copias de seguridad diferenciales y copias de seguridad de registros para la recuperación a un momento dado.
En este artículo he usado comandos de T-SQL, pero también se pueden hacer muchas cosas desde Management Studio. Espero haberle dado algunos consejos útiles para el mantenimiento efectivo de bases de datos. Si tiene comentarios o preguntas, escríbame a paul@sqlskills.com.
Paul S. Randal es el director general de SQLskills.com y uno de los profesionales más valorados (MVP) de SQL Server. Ha trabajado en el equipo de Motor de almacenamiento de SQL Server en Microsoft de 1999 a 2007. Paul es un experto en recuperación ante desastres, en alta disponibilidad y en el mantenimiento de bases de datos. Además, es autor de un blog: SQLskills.com/blogs/paul.
© 2008 Microsoft Corporation y CMP Media, LLC. Reservados todos los derechos. Queda prohibida la reproducción parcial o total sin previa autorización.