Administración de Windows
Introducción a Windows Server 2008 Failover Clustering
Chuck Timon
De un vistazo:
- Complemento Administración del clúster de conmutación por error
- Nuevas características y mejoras
- Funciones de copia de seguridad y restauración
- Migración desde Windows Server 2003
Contenido
Nueva interfaz de administración
Procesos de configuración mejorados
Procedimiento de validación incrustado
Nuevo modelo de quórum
Características de seguridad mejoradas
Ampliación de la funcionalidad de red
Aumento de la confiabilidad al interactuar con el almacenamiento
Procesos de recuperación integrados
Nuevas funciones de copia de seguridad y restauración
Migración desde los clústeres de Windows Server 2003
Desde que se incluyó por primera vez la tecnología de clústeres en Windows NT 4.0 Enterprise Edition, los usuarios se han quejado de lo difícil que es configurarlos, y más aún mantenerlos. Para administrar un clúster,
es necesario que el administrador tenga algo más que un conocimiento general de la propia pieza de clúster. Además, debe conocer en profundidad las tecnologías de almacenamiento y el modo en que el servicio de clúster interactúa con una serie de soluciones de almacenamiento. Muchas organizaciones tienen problemas a la hora de conseguir el conjunto de habilidades necesarias para poner en funcionamiento una solución de alta disponibilidad, además de mantenerla.
La tecnología de clústeres ha mejorado a lo largo de los años, pero aún dejaba mucho que desear cuando Microsoft comenzó a trabajar en Windows Server® 2008. Por este motivo, el equipo comenzó a rediseñarla con el único objetivo de simplificarla. En Windows Server 2008, le han hecho un lavado de cara a los Servicios de Cluster Server de Microsoft® (MSCS), y ahora se conocen como Failover Clustering.
Esto no quiere decir que lo único que tiene que aportar la nueva implementación de Failover Clustering sea simplicidad. A lo largo de los años, Microsoft ha aprendido bastantes lecciones, ya que las organizaciones han proporcionado comentarios bastante valiosos acerca de lo que les gustaría ver en una solución de clústeres. La nueva funcionalidad de Failover Clustering trata la mayoría de los problemas más importantes y, asimismo, ofrecen algunas características nuevas e interesantes que lo convierten en una proposición muy atractiva. En este artículo, por lo tanto, me gustaría presentarle algunas de las nuevas e increíbles características de Windows Server 2008 Failover Clustering.
Nueva interfaz de administración
Después de instalar Failover Clustering, podrá obtener acceso a la interfaz de administración a través de las herramientas administrativas o con Cluadmin.msc. El complemento Administración del clúster de conmutación por error, al igual que otras interfaces de administración en Windows Server 2008, es una consola de Microsoft Management Console (MMC) 3.0. Aquellas personas que tengan experiencia con los clústeres se sentirán bastante desorientados la primera vez que abran el complemento Administración del clúster de conmutación por error.
La nueva interfaz se divide en tres paneles distintos, tal y como se muestra en la Figura 1. El panel izquierdo enumera todas las copias de Windows Server 2008 Failover Clustering que se encuentran en la organización. El panel central ofrece los detalles de la configuración de la sección del clúster que se haya seleccionado en el panel izquierdo. Por otro lado, el panel derecho muestra las acciones que se pueden ejecutar.
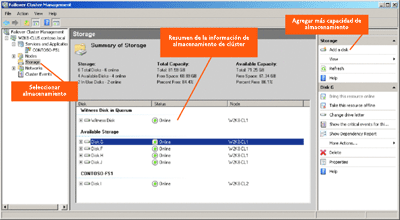
Figura 1 Complemento Administración del clúster de conmutación por error (haga clic en la imagen para ampliarla)
Supongamos, por ejemplo, que ha seleccionado Almacenamiento en el panel izquierdo. En el panel central, aparecerán los detalles del almacenamiento proporcionado por el clúster, así como su disponibilidad, en caso de que la hubiera. Como puede observar en la Figura 1, el clúster contiene una porción de almacenamiento compatible con un disco testigo, almacenamiento destinado a un servidor de archivos y algo de almacenamiento disponible. El panel derecho enumera acciones relevantes, como la de agregar más capacidad de almacenamiento. Tenga en cuenta que no se puede usar el complemento Administración del clúster de conmutación por error para administrar las versiones anteriores del Servicio de Microsoft Cluster Service.
Procesos de configuración mejorados
La configuración de un clúster de conmutación por error es bastante sencilla. La mayoría de las acciones para configurar, volver a configurar y mantener un clúster están respaldadas por asistentes. Gracias a ellos, el administrador ya no necesita preocuparse de si los recursos se han configurado correctamente o si aparecerán en línea en el orden correcto.
La Figura 2 muestra el asistente para alta disponibilidad. En este ejemplo en particular, se ha configurado un servidor de archivos. A la izquierda, podrá ver una lista de los pasos por los que el asistente guía al administrador. Una vez que se completa el proceso, se muestra una página de resumen y es posible ver un informe del mismo.
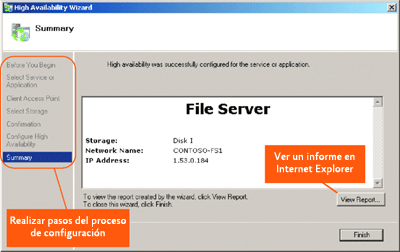
Figura 2 Asistente para alta disponibilidad (haga clic en la imagen para ampliarla)
Procedimiento de validación incrustado
En las versiones anteriores de Windows Server, si se deseaba el tratamiento de una configuración de hardware como solución de clúster admitida, debía enumerarse como solución de clúster en el Catálogo de Windows Server. Esto incluía los clústeres de varios sitios, que se enumeraban independientemente bajo la categoría Geográficamente dispersos. Para aparecer en el catálogo, los proveedores de hardware debían realizar una serie de pruebas del laboratorio de calidad de hardware de Windows (WHQL) y, a continuación, enviar los resultados a Microsoft. Esto era bastante costoso para los proveedores, por lo que el mantenimiento de la base de datos del Catálogo de Windows Server era una tarea complicada.
En Windows Server 2008, se incluye un proceso de validación integrado en Failover Clustering. Este proceso consiste en una serie de pruebas que se agrupan en cuatro categorías principales, tal y como se muestra en la Figura 3.
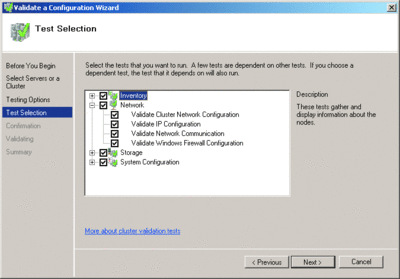
Figura 3 Categorías de la prueba de validación del clúster de conmutación por error (haga clic en la imagen para ampliarla)
Puede observar que se ha ampliado la categoría Red para mostrar las pruebas que se están ejecutando. Cada categoría, por su parte, contiene un grupo de pruebas. La categoría Almacenamiento, que es probablemente la más importante de las cuatro, incluye pruebas para garantizar que las soluciones de almacenamiento cumplen con los nuevos requisitos de Windows Server 2008 Failover Clustering.
Concretamente, los proveedores de hardware deben usar controladores basados en el propio controlador de Microsoft Storport, por lo que deben ser compatibles con las reservas persistentes de SCSI-3. Asimismo, cuando se use un módulo específico de dispositivo de múltiples rutas, este deberá estar basado en el estándar E/S de múltiples rutas de Microsoft.
Gracias a la inclusión del proceso de validación, el modelo de compatibilidad ha cambiado. Todos los tipos de hardware deben presentar el logotipo de Windows Server 2008 y deben pasar todas las pruebas de validación. Las únicas excepciones son los clústeres de varios sitios que tienen dos espacios de almacenamiento independientes y distintos (uno en cada lado), y la implementación de la replicación continua en clúster de Exchange Server 2007, ya que no tiene ninguna capacidad de almacenamiento compartido.
Nuevo modelo de quórum
También se ha cambiado el modelo de quórum en Windows Server 2008 Failover Clustering. En los sistemas antiguos, cuando un administrador oía la palabra quórum, se le venía a la cabeza un disco compartido que incluía la configuración del clúster y algunos archivos replicados. Este era el único punto de posibles errores del clúster. Si el disco de quórum producía errores, finalizaba el servicio del clúster y, por lo tanto, se perdía la alta disponibilidad.
Los clústeres de Windows Server 2003 proporcionaban un segundo tipo de quórum conocido como Conjunto de nodos mayoritario. Este tipo de quórum solía implementarse en los clústeres de varios sitios y no precisaba un almacenamiento compartido. El quórum Conjunto de nodos mayoritario consistía en un archivo compartido que se ubicaba en la unidad del sistema de cada nodo del clúster. Las conexiones a este quórum se realizaban mediante conexiones de bloque de mensajes del servidor (SMB). Una vez más, para que funcionara el clúster, era necesario que participaran la mayoría de los nodos.
Posteriormente, con la replicación continua en clúster (CCR) de Exchange Server 2007, se agregó a los clústeres de Windows Server 2003 la capacidad de testigo del recurso compartido de archivos (FSW). Esto permitía que un único nodo de clúster CRR de Exchange 2007 (o cualquier clúster de varios sitios) siguiera proporcionando servicios. Sólo era necesario que se alcanzara la mayoría mediante la conexión al FSW.
En Windows Server 2008 Failover Clustering, el concepto de quórum ahora equivale al de consenso. El quórum, o consenso, se alcanza mediante la obtención de los votos suficientes para poner en servicio el clúster. Estos votos se pueden obtener de diversos modos, según la configuración del quórum. Existen cuatro modos de quórum disponibles en un clúster de conmutación por error de Windows Server 2008, tal y como se muestra en la Figura 4. De los cuatro modos que aparecen en la lista, tan sólo los dos primeros (Mayoría de nodo y Mayoría de disco y nodo) se pueden seleccionar automáticamente durante el proceso de creación del clúster. Se debe usar la siguiente lógica:
- Si se va a configurar un número impar de nodos en el clúster, seleccione el modo Mayoría de nodo.
- Si se va a configurar un número par de nodos en el clúster y el almacenamiento compartido está activado y accesible, seleccione Mayoría de disco y nodo.
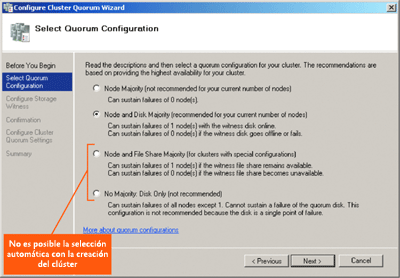
Figura 4 Modos de quórum en el Asistente para configurar quórum de clúster (haga clic en la imagen para ampliarla)
Si desea seleccionar un disco testigo del almacenamiento disponible, seleccione el primer disco que tenga como mínimo un tamaño de 500 megabytes y que tenga configurada una partición NTFS. Los modos de quórum restantes sólo se pueden seleccionar de forma manual, por lo que deberá ejecutar el asistente para configurar quórum de clúster. La opción de Mayoría de recurso compartido de archivos y nodo se usa normalmente durante la configuración de un clúster de varios sitios o en un clúster CCR de Exchange 2007. La última opción es el modo Sin mayoría: sólo disco, que equivale al modelo de quórum compartido de los clústeres heredados. Es un único punto de posibles errores y, por lo general, no se recomienda su uso.
Sólo hay dos tipos de recursos testigo, un disco físico y un archivo compartido que se pueden configurar en el clúster para alcanzar el consenso.
Un disco testigo es una porción de almacenamiento que el servicio de clúster puede activar. Este disco está ubicado en el grupo de recursos principal del clúster, junto a los recursos del nombre de la red y de las direcciones IP asociadas. Cuando se configura el disco testigo, se coloca en él una carpeta del clúster y una copia completa de la configuración del clúster (sección del clúster o réplica).
Un FSW es un recurso compartido de red que, en una situación ideal, está ubicado en un servidor de la red que no forma parte del clúster. Se realiza una conexión SMB al FSW, y este mantiene una copia del archivo de registro testigo, que contiene información acerca del control de versiones de la configuración del clúster.
Sólo se puede configurar un recurso testigo en un clúster. Este recurso proporciona un voto extra en caso de que el clúster deba alcanzar el quórum. Es decir, si le hace falta al clúster un único voto (y, por lo tanto, un nodo) para alcanzar el consenso, el recurso testigo entra en línea para que esto sea posible. Si al clúster le hace falta más de un voto para conseguir el quórum, se omite el recurso testigo y el clúster permanece en un estado latente a la espera de que se una otro nodo de clúster.
Características de seguridad mejoradas
Los clústeres de conmutación por error incluyen varias mejoras en cuanto a seguridad. Probablemente la más significativa tenga que ver con la eliminación del requisito referente a la existencia de una cuenta de servicios de clúster (CSA). En versiones anteriores del Servicio de Microsoft Cluster Service, se necesitaba una cuenta de usuario del dominio durante el proceso de configuración. Esta cuenta, que se usaba para iniciar el servicio de clúster, se agregaba al grupo de administradores locales de cada nodo del clúster. Del mismo modo, se proporcionaban los derechos de usuario local requeridos para que el servicio de clúster funcionara correctamente. Como cuenta de usuario del dominio, la CSA estaba sujeta a un número de directivas de nivel de dominio que se podían aplicar a los nodos del clúster. Estas directivas podían impactar de manera negativa en la alta disponibilidad, lo que provocaba errores en el servicio del clúster.
Actualmente, el servicio de clúster se ejecuta con una cuenta de sistema local que posee un conjunto de derechos determinados sobre el nodo del clúster local. De este modo, puede funcionar correctamente. El contexto de seguridad para el clúster ha cambiado al objeto de nombre de clúster (CNO), que es el objeto del equipo que se crea de forma predeterminada en el contenedor Computers de Active Directory® cuando se crea por primera vez el clúster. Cuando el clúster se ha creado correctamente y hay un CNO en Active Directory, ya no hace falta la cuenta de usuario que se creó para instalar y configurar el clúster.
Los objetos de equipo adicionales que se hayan creado en el contenedor Computers de Active Directory se asocian a un clúster de conmutación por error. Estos objetos, denominados objetos de equipo virtual (VCO) se corresponden con los recursos de nombre de red que se crearon como parte de los puntos de acceso cliente (CAP) en el clúster. El CNO, que se responsabiliza de crear todos los VCO de un clúster, se agrega a la lista de control de acceso del sistema (SACL) del objeto en Active Directory (consulte la Figura 5).
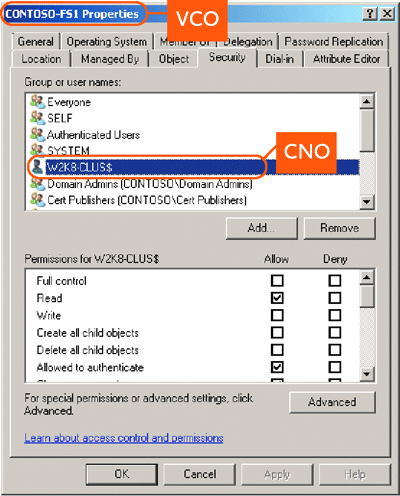
Figura 5 Seguridad de un VCO en Active Directory (haga clic en la imagen para ampliarla)
El CNO también se responsabiliza de sincronizar las contraseñas de dominio para todos los VCO que haya creado. Este proceso se realiza de acuerdo con la directiva de dominio que se haya configurado para la rotación de contraseñas. De modo adicional, dado que el CNO se responsabiliza de crear en un clúster todos los objetos de equipo asociados al VCO, el CNO (cuenta de equipo) debe tener el derecho de nivel de dominio para crear objetos de equipo en el contenedor en el que se hayan creado los VCO (de forma predeterminada, el contenedor Computers).
Otro cambio a tener en cuenta es que ahora se usa Kerberos como método de autenticación predeterminado. El hecho de que existan cuentas de equipo en Active Directory ha permitido la mejora de esta característica de seguridad. Si una aplicación que no puede usar Kerberos para autenticarse precisa en algún momento el acceso a los recursos del clúster, este puede usar la autenticación de NT LAN Manager (NTLM).
También es más segura la comunicación entre los nodos de clúster que están directamente relacionados con el proceso del clúster. Todas las comunicaciones entre clústeres están firmadas de forma predeterminada. Mediante la interfaz de lenguaje común (CLI) de cluster.exe, se puede modificar esta propiedad del clúster para cifrar la comunicación entre los nodos. De este modo, se proporciona un mayor nivel de seguridad.
Ampliación de la funcionalidad de la red
Las nuevas capacidades de red de los clústeres de conmutación por error permiten una mayor flexibilidad a la hora de diseñar soluciones de alta disponibilidad y para la recuperación ante desastres. Al mismo tiempo, las mejoras de red proporcionan una conectividad más confiable entre los nodos del clúster.
La característica que más han solicitado los clientes es la capacidad de ubicar nodos del clúster en redes independientes. Ahora es posible hacerlo. Se ha vuelto a escribir completamente el controlador de red del clúster para que pueda proporcionar una comunicación entre nodos altamente confiable y tolerante a errores. Esto es posible siempre que cada nodo esté conectado con, al menos, dos redes independientes y que se hayan enrutado de manera diferente.
El controlador de red del clúster construye su propia tabla interna de enrutamiento, basada en la información acerca de la conectividad que se proporciona durante el proceso de inicio del clúster. Incluye información acerca de la conectividad local, así como la que se proporciona en la base de datos de la configuración del clúster (subárbol del registro de clúster).
Parte del proceso de validación del clúster incluye un proceso de detección de la conectividad de la red. La capacidad de ubicar nodos de clúster en diversas redes conectadas ha suavizado los requisitos de red para los clústeres de varios sitios. Esto facilita y abarata su implementación por parte de las organizaciones. También convierte el almacenamiento iSDCS en una solución más atractiva para el uso con clústeres de conmutación por error.
Los nodos del clúster también pueden obtener la información de direcciones IP mediante DHCP (Protocolo de configuración dinámica de host). Esto puede aligerar la carga de administración de la red si se asignan direcciones dinámicas a los servidores del entorno.
La configuración de las interfaces de red del nodo de un clúster determina las redes que usarán direcciones IP estáticas o dinámicas. Incluso si un recurso de dirección IP de un clúster se obtiene a partir de un servidor DHCP, se puede cambiar a una dirección IP estática mediante el complemento Administración del clúster de conmutación por error.
Antiguamente, todas las comunicaciones de los clústeres usaban la difusión por el Protocolo de datagramas de usuario (UDP) y, en ocasiones, recurrían a la multidifusión. La funcionalidad de la multidifusión se ha dejado de usar y las comunicaciones entre clústeres usan actualmente la unidifusión UDP. El puerto que suelen usar más a menudo los clústeres de Microsoft sigue siendo el 3343. A muchos administradores de red les complacerá descubrir que ya no se usa la difusión. Sin embargo, lo que merece más la pena de un clúster es el nuevo proceso de mensajería interno del propio servicio de clúster. Este tema no se tratará en este artículo. La comunicación entre clústeres está actualmente relacionada con la comunicación TCP, que es mucho más confiable, a pesar de que se sigue usando UDP como mecanismo de transporte.
Aumento de la confiabilidad al interactuar con el almacenamiento
El modo que tienen los clústeres de conmutación por error de interactuar con el almacenamiento ha cambiado radicalmente. Se ha vuelto a escribir por completo el controlador de disco del clúster (clusdisk.sys), y ahora es un controlador Plug and Play (PnP). También ha cambiado su modo de interactuar con el almacenamiento.
En Windows Server 2003, el controlador de disco del clúster se encontraba en una ruta directa al almacenamiento. Sin embargo, en Windows Server 2008, se comunica con el controlador del administrador de la partición (partmgr.sus) para la interacción con el almacenamiento. Ambos enfoques se ilustran en la Figura 6.
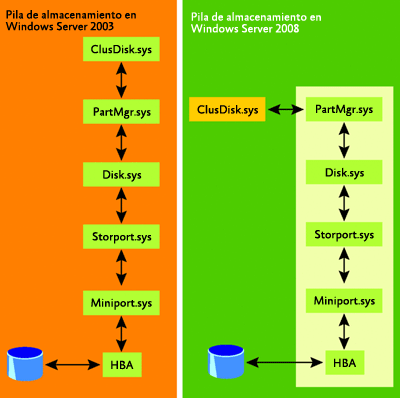
Figura 6 Cambios en la pila de almacenamiento en Windows Server 2008 (haga clic en la imagen para ampliarla)
El administrador de la partición se responsabiliza principalmente de proteger los recursos de disco del clúster. Todos los discos que se encuentran en un bus de almacenamiento compartido permanecen automáticamente sin conexión cuando se les asigna por primera vez un nodo del clúster. Esto permite que el almacenamiento se asigne simultáneamente a todos los nodos de un clúster incluso antes de la creación del mismo. Ya no es necesario iniciar los nodos uno por uno, preparar los discos en uno de ellos y, a continuación, apagar el nodo para iniciar otro, comprobar la configuración del disco, etc.
Sin embargo, aún se deben ejecutar las pruebas de almacenamiento como parte del proceso de validación del clúster. Por lo tanto, es necesario que se inicien todos los discos. Esto se puede realizar en uno de los nodos del clúster antes de ejecutar el proceso de validación. Una vez que se haya agregado el almacenamiento a un clúster, los discos muestran el estado Reservado en la interfaz Administración de discos y nunca se dejan en estado desprotegido.
Otro cambio tiene que ver con los comandos SCSI. En Windows Server 2003, los comandos Reserve\Release de SCSI-2 se usaban con el controlador de disco del clúster durante la escritura de los sectores del propio disco. En Windows Server 2008, se precisan los comandos PR (Reserva persistente) de SCSI-3. Conviene registrar los nodos del clúster antes de que puedan realizar una reserva para el almacenamiento. Del mismo modo, los nodos del clúster defienden periódicamente sus reservas mediante el protocolo de Reserva y Defensa.
Una de las pruebas de almacenamiento del proceso de validación comprueba esta funcionalidad. Si una solución de almacenamiento no es compatible con los comandos (PR) de SCSI-3, no será compatible con un clúster de conmutación por error.
Muchas organizaciones usan para conectarse con el almacenamiento un software de múltiples rutas para la redundancia. Esto es compatible e, incluso, se promueve como práctica recomendada. Sin embargo, es necesario volver a escribir las soluciones de software de múltiples rutas de terceros o los módulos específicos de dispositivos. Para ello, debe usarse el estándar de E/S de múltiples rutas de Microsoft. De este modo, las soluciones y los módulos serán compatibles con un clúster de conmutación por error. Esto garantiza que todos los comandos PR de SCSI-3 se envían de manera simultánea por todas las rutas hacia el almacenamiento, independientemente de si la ruta está activa o no. Esta funcionalidad también se comprueba como parte del proceso de validación.
Las mejoras adicionales del almacenamiento incluyen un proceso mejorado de comprobación de disco (chkdsk.exe), una funcionalidad integrada de reparación de disco que anteriormente formaba parte de la utilidad de recuperación del servidor del clúster, así como discos de recuperación automática. En los clústeres de conmutación por error, se usan tanto la firma de disco como el identificador de LUN durante la identificación de un recurso de disco del clúster. Si se ha modificado alguno de los dos, se actualiza la configuración del clúster. Esto se traduce en una reducción del número de errores, debido a que se ha modificado un atributo del recurso de un disco físico, lo cual resulta en una mayor disponibilidad.
Procesos de recuperación integrados
La reparación del disco que se ha mencionado anteriormente es, evidentemente, una de las capacidades de recuperación integradas. Otra de ellas es la capacidad de reparación de Active Directory. Si se elimina un objeto de equipo que representa al CNO, ya no tendrá que crear los objetos de equipo asociados a los CAP del clúster. Sin embargo, el primer problema con el que seguramente se encontrará tendrá lugar cuando las aplicaciones o los usuarios altamente disponibles no puedan obtener acceso a los recursos que se encuentren fuera del clúster, debido a que no pueden obtener un símbolo (token) de seguridad.
El proceso de recuperación de un CNO eliminado consiste en dos pasos. En primer lugar, un administrador de dominio debe ocuparse de recuperar el objeto de equipo eliminado que se encuentra en el contenedor DeletedObjects de ActiveDirectory. A continuación, una vez que se haya restaurado y rehabilitado el objeto, debe ejecutar el proceso de reparación del objeto de Active Directory. Para ello, use el complemento Administración del clúster de conmutación por error.
En los clústeres de Windows Server 2003, cabía la posibilidad de que el archivo de configuración del clúster ubicado en el subdirectorio %systemroot%\cluster pudiera corromperse y, por lo tanto, necesitara reemplazarse. En este caso, es bastante útil la capacidad de recuperación automática de los clústeres de conmutación por error. Si el servicio de clúster se inicia en un nodo y la base de datos de la configuración se corrompe, se cargará una plantilla de configuración mínima a partir de la información contenida en la clave del Registro HKLM\System\CCS\Services\ClusSvc\Parameters. El nodo tratará de unirse a un clúster que ya esté formado y, si lo consigue, se insertará en el nodo una copia nueva del subárbol del registro del clúster. En caso de que un nodo no pueda unirse a un clúster, finalizará el servicio.
Nuevas funciones de copia de seguridad y restauración
Windows Server 2008 Failover Clustering se presenta con su propio escritor del Servicio de instantáneas de volumen. Este escritor desempeña un papel fundamental a la hora de realizar copias de seguridad y de restaurar una base de datos de un clúster, así como de los datos que se encuentran en los recursos del disco físico. La tarea de realizar copias de seguridad de la configuración del clúster es bastante sencilla. Mientras el estado del sistema forme parte de una copia de seguridad, la configuración del clúster se puede restaurar. Sin embargo, tenga en cuenta que sólo se debe hacer una copia de seguridad de un clúster si este tiene quórum. Esto garantiza que se va a realizar una copia de seguridad de la configuración del clúster más reciente.
Existen dos tipos diferentes de restauraciones de clústeres: autoritativa y no autoritativa. Una restauración no autoritativa usa Copias de seguridad de Windows Server o una aplicación de copias de seguridad de terceros para ejecutar la restauración a partir de una copia de seguridad seleccionada. Por otro lado, sólo se puede realizar una restauración autoritativa de un nodo de clúster mediante el CLI de Copias de seguridad de Windows Server (wbadmin.exe).
En resumidas cuentas, una restauración autoritativa lleva la configuración del clúster "hacia atrás en el tiempo", hasta el momento en que se realizó la copia de seguridad. Para realizar una restauración autoritativa, se detiene el servicio de clúster en todos los nodos, excepto en el nodo en que se esté ejecutando la restauración. Cuando se haya completado la restauración y se haya iniciado el servicio de clúster en el nodo restaurado, la configuración restaurada del clúster se convierte en la configuración definitiva del nuevo clúster. A continuación, cuando se haya reiniciado el servicio en los nodos restantes del clúster, se inserta la configuración restaurada durante el proceso de unión.
Esto puede ahorrar bastante tiempo y dinero en circunstancias determinadas. Supongamos que tiene un clúster de impresión que hospeda varios recursos del administrador de trabajos de impresión, que cada uno de ellos admite 1500 impresoras y que, accidentalmente, elimina uno de los recursos. Un gran número de usuarios ya no podrán imprimir documentos. En lugar de volver a agregar manualmente todas las impresoras en la configuración del clúster, es mucho más rápido realizar una restauración autoritativa de la configuración del clúster. Por supuesto, esto depende de si tiene una copia de seguridad y una estrategia de restauración lo suficientemente sólidas.
Migración desde los clústeres de Windows Server 2003
Debido a todos los cambios en la arquitectura de Windows Server 2008 Failover Clustering, no se admiten las actualizaciones locales o graduales desde Windows Server 2003. Al actualizar los clústeres de Windows Server 2000 a Windows Server 2003, muchas organizaciones expulsaban todos los nodos del clúster de forma sistemática. A continuación, realizaban una instalación limpia del sistema operativo y, finalmente, volvían a insertar el nodo en el clúster. No se puede usar este enfoque para migrar a Windows Server 2008, ya que los nodos de clúster de Windows Server 2003 y Windows Server 2008 no pueden formar parte del mismo clúster.
Afortunadamente, se ha incluido un asistente para ayudarle en el proceso de migración. No obstante, una migración a un clúster de conmutación por error de Windows Server 2008 precisará algo de planeación previa. Existen tres situaciones básicas de migración:
- Uso de los mismos servidores y almacenamiento.
- Uso de los mismos servidores pero con un nuevo almacenamiento.
- Uso de nuevos servidores y almacenamiento.
Cualquiera de estos escenarios conlleva asegurarse de que el hardware está certificado por el programa de logotipo de Windows Server 2008 y, además, que se ha ejecutado correctamente el proceso de validación del clúster de conmutación por error. Una vez que se hayan completado estos pasos, se puede continuar con el proceso de migración.
No se pueden migrar todos los recursos de un clúster de Windows Server 2003. Se pueden migrar los nombres de red, las direcciones IP, los discos físicos, los archivos compartidos, las raíces del sistema de archivos distribuidos (DFS), DHCP y WINS. También puede migrar, hasta cierto punto, los servicios, aplicaciones y recursos de scripts genéricos.
Mientras tanto, aplicaciones como Microsoft Exchange y SQL Server® tienen sus propios procedimientos de migración a un clúster de conmutación por error. Se pueden migrar las impresoras a Windows Server 2008 mediante el complemento Administración de impresión (que se instala con la función del servidor de impresión) para, en primer lugar, exportar las impresoras y, a continuación, importarlas a un nuevo servidor de impresión de alta disponibilidad. No se puede migrar ningún tipo de recurso de terceros.
El proceso de migración no se aplica a ningún tipo de datos. Implica la migración de los parámetros de configuración del clúster de Windows Server 2003 a los de Windows Server 2008.
Al principio, todos los recursos migrados permanecerán sin conexión hasta que se complete el proceso de migración. Esto se debe a que puede que deba llevar a cabo algunos pasos adicionales. Por lo tanto, es importante revisar el informe que se elabora una vez que ha finalizado el proceso de migración para comprobar los pasos adicionales (propios de la migración de datos, en caso de que se vaya a realizar la migración a nuevo almacenamiento) que se deben llevar a cabo antes de activar el clúster. Por ejemplo, si se está migrando un servidor DHCP, la función del servidor DHCP debe estar instalada en todos los nodos del clúster. Si la migración se está realizando a un servidor WINS, la función del servidor WINS también debe estar instalada en todos los nodos del clúster.
Chuck Timon es un ingeniero de soporte técnico en Microsoft y se ocupa de las tecnologías de clústeres e instalación. Escribió el manual de aprendizaje sobre Windows Server 2008 Failover Clustering y actualmente está desarrollando el material de aprendizaje de Hyper-V.
© 2008 Microsoft Corporation y CMP Media, LLC. Reservados todos los derechos. Queda prohibida la reproducción parcial o total sin previa autorización.