PREGUNTAS Y RESPUESTAS DE SQL Copia de seguridad compresión, redirección de cliente con la creación de reflejos de bases de y mucho más
Paul S. Randal
P se va a ser actualizar la mayoría de nuestros servidores a SQL Server 2008, y uno de las características que estoy deseando poner en producción es la compresión de copia de seguridad. Sé que puede activar, de forma predeterminada para todos los bases de datos en cada servidor, pero también he oído que es posible que no deseo hacer eso. No estoy seguro de por qué no desea tener la característica habilitada de forma predeterminada, como parece tenemos nada para perder. ¿Puede ayudar a explicar los motivos de lo que he oído?
la respuesta es mi favorito linde : depende! Voy a dar a algunos fondo para explicar.
El punto clave que tener en cuenta es la razón de compresión que tendrá cada copia de seguridad de base de datos cuando se habilita la compresión copia de seguridad. La relación de compresión de todo lo que se comprimieron mediante cualquier algoritmo viene determinada por los datos reales que se va a comprimir.
¿Busca las sugerencias de SQL Server?
Para obtener sugerencias acerca de SQL Server, visite la Las sugerencias de TechNet Magazine SQL Server página.
Para obtener más sugerencias en otros productos, visite la Índice de TechNet Magazine sugerencias.
Datos aleatorios (entero pequeño valores, por ejemplo) no comprimirá muy bien, para el contenido de las tablas e índices en la base de datos se determina, en la mayor parte, la proporción de compresión que se puede conseguir.
Figuran algunos ejemplos de cuando la compresión de copia de seguridad no puede producir una razón de compresión alta:
- Si la base de datos tiene cifrado de datos transparente habilitado, a continuación, la razón de compresión será muy baja porque los datos se comprimen aleatoria de valores pequeña.
- Si la mayoría de los datos de la base de datos está cifrada en el nivel de columna, a continuación, la razón de compresión estarán baja, nuevo porque el cifrado de columna esencialmente aleatoriamente los datos.
- Si las tablas de la mayor parte de la base de datos tienen compresión de datos habilitada, a continuación, la razón de compresión será baja; compresión de datos que ya principalmente se comprimen normalmente tiene poco efecto.
En el caso cuando la razón de compresión es baja, el problema no es la proporción baja pero el hecho de que los recursos de CPU se utilizan para ejecutar el algoritmo de compresión para no ganancias. No importa lo bien un fragmento de datos puede estar comprimido, los recursos de CPU siempre se utilizan para ejecutar los algoritmos de compresión y descompresión.
Esto significa que es necesario comprobar el grado comprime cada base de datos en una copia de seguridad antes de decidir utilizar compresión de copia de seguridad para esa base de datos de todo el tiempo. En caso contrario, es posible que posiblemente se malgastar los recursos de CPU. Esto es la base de lo que ha oído.
En resumen, si la mayoría de las bases de datos se beneficiará de compresión de copia de seguridad, sentido para habilitar la compresión copia de seguridad en el nivel de servidor y cambiar manualmente unos trabajos de copia de seguridad a específicamente utilizar la opción WITH NO_COMPRESSION. O bien, si la mayoría de las bases de datos no se beneficiará de compresión de copia de seguridad, tiene sentido dejar la copia de seguridad compresión desactivada en el nivel de servidor y cambiar manualmente unos pocos trabajos de copia de seguridad a específicamente utilizar la opción WITH COMPRESSION.
P año anterior se actualizan nuestras bases de datos tienen la creación de reflejos de bases de datos para que si se produce un error, se puedan conmutación por error en el reflejo y la aplicación continúa. Mientras se estaban diseñar el sistema, hemos practicado realizando conmutaciones por error de la base de datos y todo funcionaba bien. Última semana hemos tenido un error real y se produjo la conmutación por error de base de datos, pero todas las transacciones de aplicación detenidas y la aplicación no conectar con el servidor de conmutación por error. ¿En el futuro, cómo puede configurar SQL Server para que no eliminar las conexiones de aplicación durante la conmutación por error para las transacciones que pueden continuar?
A Permitirme este dividir en dos partes, cómo las aplicaciones pueden resistir conmutaciones por error y cómo administrar la redirección de cliente con la creación de reflejos de base de datos.
Cuando una conmutación por error se produce mediante cualquiera de las tecnologías de alta disponibilidad disponibles con SQL Server, se descarta la conexión de cliente con el servidor con errores y las transacciones en curso se pierden. No es posible migrar una transacción en curso entre los servidores (en una situación de conmutación por error o de otro modo). Dependiendo de la tecnología de alta disponibilidad, la transacción en curso o bien no se exista en absoluto en el servidor de conmutación por error o que existirá como una transacción en curso pero se se deshacen como parte del proceso para abrir la base de datos en línea en el servidor de conmutación por error.
Con tener en cuenta en la creación de reflejos, base de datos que se continuamente incluye registros de transacciones desde el servidor principal en el servidor reflejado, suele ser el último caso, las transacciones en curso se deshacen como parte de poner la base de reflejo datos en línea como el nuevo principal.
Por tanto, son dos cosas que una aplicación debe ser capaz de hacer correctamente cuando ejecuta en un servidor con la posibilidad de tener que la conmutación por error a otro servidor:
- Debe ser capaz de tratar correctamente la conexión de servidor que está eliminando y, a continuación, intente conectarse de nuevo tras un intervalo de tiempo pequeño.
- Debe poder controlar correctamente una transacción se anula y, a continuación, reintentando la transacción después de una conexión se establece con el servidor de conmutación por error (posiblemente con un administrador de transacciones mid-tier).
La tecnología de sólo alta disponibilidad aquí que no requiere cambios de cliente en concreto en permitir la redirección de la conexión de cliente después de una conmutación por error es el clúster de conmutación por error. Los clientes conectarse a un nombre de servidor virtual y transparente se redireccionan a cualquier nodo de clúster físico está activo.
Con tecnologías de alta disponibilidad, tales como el trasvase de registros y la replicación, el servidor nombre del servidor de conmutación por error es diferente, lo que significa que manual es necesaria la redirección de las conexiones de cliente después de una conmutación por error. Esta redirección manual puede realizarse de varias maneras:
- Puede codificar el nombre del servidor de conmutación por error en el cliente para los intentos de reconexión se realizan en el servidor de conmutación por error.
- Puede utilizar el equilibrio de la carga en la red con un 0 y 100, configuración de 0 y 100, que, a continuación, se permitirá la conexión se cambió al servidor de conmutación por error.
- Puede usar algo como un alias de nombre de servidor o cambiar las entradas de una tabla DNS.
Con la creación de reflejos de bases de datos, cualquiera de estas opciones funcionará. Pero también la creación de reflejos de bases de datos tiene capacidades de dirección de cliente integrado. La cadena de conexión del cliente puede especificar explícitamente el nombre del servidor reflejado, y si no se establecer contacto con el servidor principal, el reflejo, a continuación, automáticamente se intentará usar. Este proceso se conoce como redireccionamiento explícito.
Si no se puede cambiar la cadena de conexión del cliente, a continuación, redirección implícita posible si ahora se está ejecutando el servidor con errores como el servidor reflejado. Las conexiones a la se redirigirá automáticamente a la entidad nueva, pero sólo funciona si el servidor reflejado está ejecutando.
Las notas del producto de SQL Server 2005" Implementación de la aplicación de conmutación por error con la creación de reflejos de base de datos"se explica estas opciones con más detalle.
hemos P cuando se actualizó a SQL Server 2005, rediseñado nuestras tablas grandes de se particiones para que se puede aprovechar las ventajas de mantenimiento de particiones y el mecanismo de ventana deslizante. Describe este en la entrega de 2008 de agosto " Creación de particiones, comprobaciones de coherencia y mucho más"). Pero se ha detectado un problema. En ocasiones, las consultas simultáneas de la aplicación experimenta bloqueo en la tabla completa cuando las consultas incluso no se tenga acceso a las particiones mismas. ¿He oído que SQL Server 2008 soluciona este problema, puede por favor, explique cómo puede detener este bloqueo?
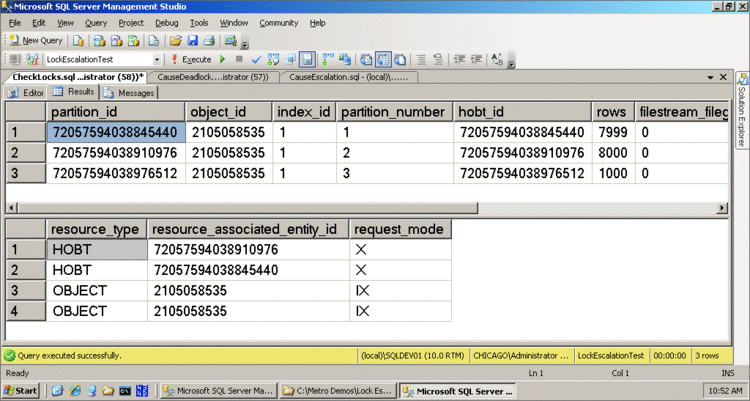
Figura 1 Examinar bloqueos en una tabla con particiones
una el problema que está viendo está causado por un mecanismo denominado escalada del bloqueo. SQL Server adquiere bloqueos en los datos para protegerlos mientras se leer o escribir los datos de una consulta. Pueden adquirir bloqueos en tablas completas, las páginas del archivo de datos o filas de tabla o índice individual, y cada bloqueo se ocupa de memoria un poco.
Si una consulta hace que se adquirió demasiados bloqueos, SQL Server puede optar por reemplazar todos los bloqueos en filas o páginas de una tabla con un bloqueo único en toda la tabla (el umbral, cuando éste tiene lugar, es aproximadamente 5000 bloqueos, pero el algoritmo exacto es complicado y configurable). Este proceso se denomina escalada del bloqueo.
En SQL Server 2005, si una consulta está funcionando en una sola partición de una tabla y hace que suficiente bloqueos que pueden tomar para desencadenar la escalada del bloqueo, a continuación, toda la tabla se convierte en bloqueado. Esto puede impedir consulta B poder funcionar en una partición diferente de la misma tabla. Por lo tanto, consulta B se bloquea hasta que finaliza una consulta y se quitan sus bloqueos.
En SQL Server 2008, el mecanismo de asignación de bloqueo se ha mejorado para permitir una tabla que escalada del bloqueo de nivel de partición. Utilizando el ejemplo anterior, esto significa que la escalada del bloqueo causado por un sólo podría bloquear la consulta de partición única A se mediante, en vez de toda la tabla de consulta.
Consulta B podrán funcionar en otra partición sin que se está bloqueado. Consulta B puede incluso desencadenar escalada del bloqueo, que podría bloquear, a continuación, sólo la partición que B está funcionando, en vez de toda la tabla de consulta.
Este modelo de escalada del bloqueo se puede establecer utilizando la sintaxis siguiente:
ALTER TABLE MyTable SET (LOCK_ESCALATION = AUTO);
GO
Esta sintaxis indica que el administrador de bloqueo de SQL Server para utilizar escalada del bloqueo de nivel de la partición si está dividida en la tabla y escalada del bloqueo de nivel de tabla normal si no está dividida en la tabla. El comportamiento predeterminado es utilizar escalada del bloqueo de nivel de tabla. Debe tener cuidado cuando esta opción, tal como se puede provocar interbloqueos función en el comportamiento de las consultas.
Por ejemplo, si las consultas A y B tanto producirán escalada del bloqueo en las diferentes particiones de una tabla, pero, a continuación, cada intentan obtener acceso a la partición que ha bloqueado la otra consulta, el proceso de monitor de bloqueo se anulará una de las consultas.
La figura muestra un ejemplo de consultar la vista de catálogo de sistema de sys.partitions (el primer conjunto de resultados) y el sys.dm_os_locks DMV (el segundo conjunto de resultados) para examinar los bloqueos se mantenidos para las consultas en una tabla con particiones donde escalada del bloqueo de nivel de partición ha tenido lugar. En este caso, hay dos nivel de partición bloqueos exclusivos (los bloqueos HOBT en los resultados), pero los bloqueos de tabla (los bloqueos de objeto en la salida) no son exclusivos, por lo que varias consultas tener acceso a las particiones, aunque escalada del bloqueo ha tenido lugar. Observe que los identificadores de recursos para estos bloqueos de dos particiones coinciden con la partición de los identificadores de las dos primeras particiones de la tabla en la salida de sys.partitions.
Al principio de este año se blogged acerca de una muestra de la secuencia de comandos en el ejemplo se cómo funciona de escalado de bloqueo de nivel de particióny la posibilidad de interbloqueos. El tema de Libros en pantalla de SQL Server 2008 denominada" Bloqueo en el motor de base de datos"tiene una explicación detallada de todos los aspectos de bloqueo de SQL Server 2008.
P uno de nuestros servidores tenía algunos problemas con el disco que contiene el registro de transacciones de una base de datos y sospechosos se convirtió en la base de datos. La copia de seguridad completa más reciente fue de cinco semanas hace y se iba a lleve demasiado tiempo para restaurar todas las copias de seguridad del registro, demasiado. Es fuera de horas cuando se produjo el problema, por lo que se reconstruye el registro de transacciones rotos para evitar el tiempo de inactividad. En algunas circunstancias, esto puede causar problemas. Pero si no hay nada acceso a los datos, a continuación, creo que estamos seguros. ¿Se ha hacemos lo correcto?
A la respuesta sencilla que es el tiempo sólo que considerarían reconstrucción de un registro de transacciones es cuando no es posible para recuperarse de copias de seguridad. Aunque es conscientes de los peligros de regeneración de un registro de transacciones (para los lectores que son no, consulte mi blog contabilizar " Última utiliza que las personas intenten en primer lugar..." el hecho de que la base de datos fue sospechoso significa que no pudo durante la recuperación, al ejecutar recuperación de bloqueo o al deshacer una transacción. Esto significa que es la posibilidad real de daños en los datos de la base de datos.
¿Aunque el problema ocurrió durante el período no interactivo, tuvo cuenta trabajos programados y tareas en segundo plano? Podría haber sido un trabajo de mantenimiento se ejecutar que reconstruir o reorganizando un índice agrupado cuando el registro se convirtió dañado. Una tarea en segundo plano es posible que haya lleva ejecutándose limpieza fantasma en las páginas de una pila o un índice agrupado. Cualquiera de estos métodos, por ejemplo, podría ha ha realizar cambios en estructuras de índices agrupados que, si no correctamente deshecho, podrían provocar daños en la base de datos y la posible pérdida de datos.
La conclusión es que la reconstrucción de un registro de transacciones siempre debe ser el último recurso absoluto en cualquier escenario de recuperación ante desastres debido a la posibilidad enorme para causar más daños y pérdida de datos. Como mínimo, debe ejecutar un completo DBCC CHECKDB en esa base de datos para comprobar si existe cualquier daño.
Más adelante, se debe cambiar la estrategia de copia de seguridad para que es capaz de realizar restauraciones oportunas y no tiene que recurrir a medidas drásticas, como la reconstrucción del registro de transacciones. Los pasos para diseñar una estrategia de copia de seguridad sobrepasa el ámbito de esta columna, pero piensa que cubren este tema en un artículo de característica full-length en algún momento en el año siguiente. Por lo que vuelva permanecer ajustado!
S. Paul Randal es el director de administración de SQLskills.comy un MVP de SQL Server. HeHe trabajado en el equipo de motor de almacenamiento de SQL Server en Microsoft desde 1999 a 2007. Paul escribió DBCC CHECKDB y reparar para SQL Server 2005 y era responsable del motor de almacenamiento principal durante el desarrollo de SQL Server 2008. Paul es un experto en recuperación ante desastres, una alta disponibilidad y mantenimiento de la base de datos y un moderador habitual en conferencias de todo el mundo. Blogs en SQLskills.com/blogs/paul.