Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Precaución
Microsoft retiró todas las experiencias clásicas de eDiscovery el 31 de agosto de 2025. Esta retirada incluye la búsqueda de contenido clásica, la exhibición de documentos electrónicos clásica (Standard) y la exhibición de documentos electrónicos clásica (Premium).
Las instrucciones de este artículo solo se aplican a las organizaciones hospedadas en Microsoft 365 operadas por 21Vianet (China). Si la organización no está hospedada por 21Vianet, use las instrucciones para la nueva experiencia de exhibición de documentos electrónicos en el portal de Microsoft Purview.
Después de crear un modelo de codificación predictiva en Microsoft Purview eDiscovery (Premium), el siguiente paso consiste en realizar la primera ronda de entrenamiento para entrenar el modelo sobre el contenido relevante y no relevante del conjunto de revisión. Después de completar la primera ronda de entrenamiento, puede realizar rondas de entrenamiento posteriores para mejorar la capacidad del modelo de predecir contenido relevante y no relevante.
Para revisar el flujo de trabajo de codificación predictiva, consulte Información sobre la codificación predictiva en eDiscovery (Premium)
Antes de entrenar un modelo
- Durante una ronda de entrenamiento, etiquete los elementos como Pertinentes o No pertinentes en función de la relevancia del contenido del documento. No base su decisión en los valores de los campos de metadatos. Por ejemplo, para mensajes de correo electrónico o conversaciones de Teams, no base la decisión de etiquetado en los participantes del mensaje.
Entrenamiento de un modelo por primera vez
En el portal de Microsoft Purview, abra un caso de exhibición de documentos electrónicos (Premium) y, a continuación, seleccione la pestaña Revisar conjuntos .
Abra un conjunto de revisión y, a continuación, seleccione Análisis>Administrar codificación predictiva (versión preliminar).
En la página Modelos de codificación predictiva (versión preliminar), seleccione el modelo que desea entrenar.
En la pestaña Información general , en Ronda 1, seleccione Iniciar siguiente ronda de entrenamiento.
Se muestra la pestaña Entrenamiento y contiene 50 elementos para etiquetar.
Revise cada documento y, a continuación, seleccione Relevante o No relevante en la parte inferior del panel de lectura para etiquetarlo.
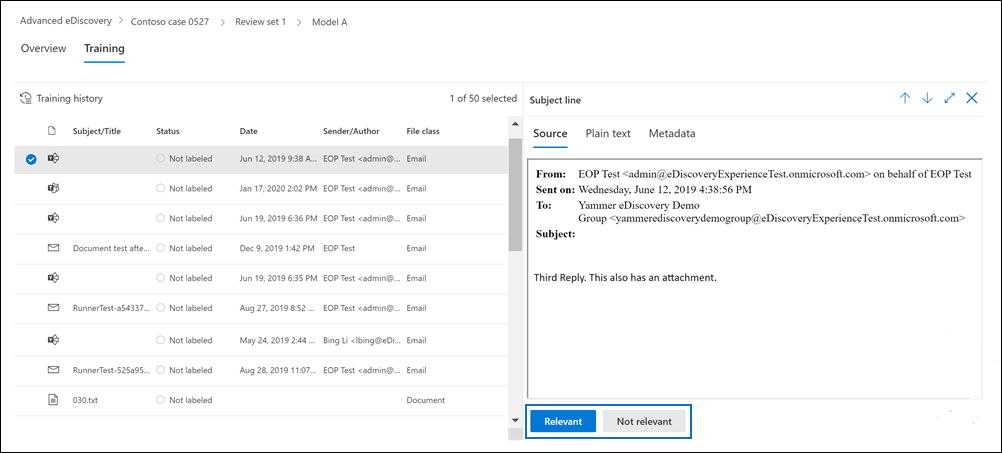
Después de etiquetar los 50 elementos, seleccione Finalizar.
El sistema tardará un par de minutos en "aprender" del etiquetado y actualizar el modelo. Una vez completado este proceso, se muestra un estado Listo para el modelo en la página Modelos de codificación predictiva (versión preliminar).
Realizar rondas de entrenamiento adicionales
Después de realizar la primera ronda de entrenamiento, puede realizar rondas de entrenamiento posteriores siguiendo los pasos de la sección anterior. La única diferencia es que el número de la ronda de entrenamiento se actualizará en la pestaña Información general del modelo. Por ejemplo, después de realizar la primera ronda de entrenamiento, puede seleccionar Iniciar siguiente ronda de entrenamiento para iniciar la segunda ronda de entrenamiento. Y así sucesivamente.
Cada ronda de entrenamiento (tanto las que están en curso como las completadas) se muestra en la pestaña Entrenamiento del modelo. Al seleccionar una ronda de entrenamiento, se muestra una página de control flotante con información y métricas para la ronda.
¿Qué ocurre después de realizar una ronda de entrenamiento?
Después de realizar la primera ronda de entrenamiento, se inicia un trabajo que hace lo siguiente:
En función de cómo etiquete los 40 elementos del conjunto de entrenamiento, el modelo aprende de su etiquetado y se actualiza a sí mismo para que sea más preciso.
A continuación, el modelo procesa cada elemento de todo el conjunto de revisión y asigna una puntuación de predicción entre 0 (no relevante) y 1 (relevante).
El modelo asigna una puntuación de predicción a los 10 elementos del conjunto de controles que ha etiquetado durante la ronda de entrenamiento. El modelo compara la puntuación de predicción de estos 10 elementos con la etiqueta real que asignó al elemento durante la ronda de entrenamiento. En función de esta comparación, el modelo identifica la siguiente clasificación (denominada matriz de confusión del conjunto de control) para evaluar el rendimiento de predicción del modelo:
| Etiqueta | El modelo predice que el elemento es relevante | El modelo predice que el elemento no es relevante |
|---|---|---|
| Elemento de etiquetas de revisor según corresponda | Verdadero positivo | Falso positivo |
| El elemento de etiquetas del revisor no es relevante | Falso negativo | Verdadero negativo |
En función de estas comparaciones, el modelo deriva valores para las métricas de puntuación F, precisión y recuperación y el margen de error de cada una de ellas. Las puntuaciones de estas métricas de rendimiento del modelo se muestran en una página flotante para la ronda de entrenamiento. Para obtener una descripción de estas métricas, consulte Referencia de codificación predictiva.
- Por último, el modelo determina los siguientes 50 elementos que se usarán para la siguiente ronda de entrenamiento. Esta vez, el modelo podría seleccionar 20 elementos del conjunto de control y 30 nuevos elementos del conjunto de revisión y designarlos como el conjunto de entrenamiento para la siguiente ronda. El muestreo de la siguiente ronda de entrenamiento no se muestrea uniformemente. El modelo optimizará la selección de muestreo de elementos del conjunto de revisión para seleccionar los elementos donde la predicción es ambigua, lo que significa que la puntuación de predicción está en el intervalo 0,5. Este proceso se conoce como selección sesgada.
¿Qué ocurre después de realizar rondas de entrenamiento posteriores?
Después de realizar rondas de entrenamiento posteriores (después de la primera ronda de entrenamiento), el modelo hace lo siguiente:
- El modelo se actualiza en función de las etiquetas que aplicó al conjunto de entrenamiento en esa ronda de entrenamiento.
- El sistema evalúa la puntuación de predicción del modelo en los elementos del conjunto de controles y comprueba si la puntuación se alinea con la forma en que etiquetaste los elementos del conjunto de controles. La evaluación se realiza en todos los elementos etiquetados del conjunto de control para todas las rondas de entrenamiento. Los resultados de esta evaluación se incorporan en el panel de la pestaña Información general del modelo.
- El modelo actualizado vuelve a procesar todos los elementos del conjunto de revisión y asigna a cada elemento una puntuación de predicción actualizada.
Pasos siguientes
Después de realizar la primera ronda de entrenamiento, puede realizar más rondas de entrenamiento o aplicar el filtro de puntuación de predicción del modelo al conjunto de revisión para ver los elementos que el modelo ha predicho como pertinentes o no pertinentes. Para obtener más información, vea Aplicar un filtro de puntuación de predicción a un conjunto de revisión.