Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
| Mayana Pereira | Scott Christiansen |
|---|---|
| Ciencia de datos de CELA | Seguridad y confianza del cliente |
| Microsoft | Microsoft |
Resumen : la identificación de informes de errores de seguridad (SBR) es un paso fundamental en el ciclo de vida del desarrollo de software. En los enfoques basados en el aprendizaje automático supervisado, es habitual suponer que todos los informes de errores están disponibles para el entrenamiento y que sus etiquetas son libres de ruido. A lo mejor de nuestro conocimiento, este es el primer estudio para mostrar que la predicción precisa de etiquetas es posible para los SBR incluso cuando solo el título está disponible y en presencia de ruido de etiqueta.
Términos de índice : Aprendizaje automático, etiquetado erróneo, ruido, informe de errores de seguridad, repositorios de errores
I. INTRODUCCIÓN
La identificación de problemas relacionados con la seguridad entre los errores reportados es una necesidad apremiante para los equipos de desarrollo de software, ya que estos problemas requieren soluciones más rápidas para cumplir con los requisitos normativos y garantizar la integridad del software y de los datos de los clientes.
Las herramientas de aprendizaje automático e inteligencia artificial prometen que el desarrollo de software sea más rápido, ágil y correcto. Varios investigadores han aplicado el aprendizaje automático al problema de identificar errores de seguridad [2], [7], [8], [18]. Los estudios publicados anteriores han supuesto que todo el informe de errores está disponible para el entrenamiento y la puntuación de un modelo de aprendizaje automático. Esto no es necesariamente el caso. Hay situaciones en las que no se puede hacer disponible todo el informe de errores. Por ejemplo, el informe de errores puede contener contraseñas, información de identificación personal (PII) u otros tipos de datos confidenciales: un caso al que nos enfrentamos actualmente en Microsoft. Por lo tanto, es importante establecer la forma en que se puede realizar la identificación de errores de seguridad con menos información, como cuando solo está disponible el título del informe de errores.
Además, los repositorios de errores suelen contener entradas con etiqueta incorrectas [7]: informes de errores que no son de seguridad clasificados como relacionados con la seguridad y viceversa. Hay varias razones para la aparición de errores de etiquetado, que van desde la falta de experiencia del equipo de desarrollo en la seguridad, hasta la desconcertación de ciertos problemas, por ejemplo, es posible que los errores que no sean de seguridad se aprovechen de forma indirecta a la hora de provocar una implicación de seguridad. Se trata de un problema grave, ya que la etiqueta incorrecta de los SBC da como resultado que los expertos en seguridad tengan que revisar manualmente la base de datos de errores en un esfuerzo costoso y lento. Comprender cómo afecta el ruido a diferentes clasificadores y cómo de robustas (o frágiles) son las diferentes técnicas de aprendizaje automático en presencia de conjuntos de datos que están contaminados con diferentes tipos de ruido es un problema que debe abordarse para llevar la clasificación automática a la práctica de la ingeniería de software.
El trabajo preliminar argumenta que los repositorios de errores son intrínsecamente ruidosos y que el ruido podría tener un efecto adverso en los clasificadores de aprendizaje automático de rendimiento [7]. Sin embargo, no hay ningún estudio sistemático y cuantitativo de cómo los distintos niveles y tipos de ruido afectan al rendimiento de diferentes algoritmos de aprendizaje automático supervisados para el problema de identificar informes de errores de seguridad (SRB).
En este estudio, demostramos que la clasificación de los informes de errores se puede realizar incluso cuando solo el título está disponible para el entrenamiento y la evaluación. Según nuestro mejor conocimiento, este es el primer trabajo en hacerlo. Además, proporcionamos el primer estudio sistemático del efecto del ruido en la clasificación del informe de errores. Hacemos un estudio comparativo de la solidez de tres técnicas de aprendizaje automático (regresión logística, bayes naïve y AdaBoost) frente al ruido independiente de la clase.
Aunque hay algunos modelos analíticos que capturan la influencia general del ruido para algunos clasificadores simples [5], [6], estos resultados no proporcionan límites estrictos sobre el efecto del ruido en la precisión y solo son válidos para una técnica de aprendizaje automático determinada. Normalmente, un análisis preciso del efecto del ruido en los modelos de aprendizaje automático se realiza mediante la ejecución de experimentos computacionales. Estos análisis se han realizado en varios escenarios que van desde los datos de medición de software [4], hasta la clasificación de imágenes satélite [13] y los datos médicos [12]. Sin embargo, estos resultados no se pueden traducir a nuestro problema específico, debido a su alta dependencia de la naturaleza de los conjuntos de datos y del problema de clasificación subyacente. Para lo mejor de nuestro conocimiento, no hay resultados publicados sobre el problema del efecto de los conjuntos de datos ruidosos en la clasificación de informes de errores de seguridad en particular.
NUESTRAS CONTRIBUCIONES DE INVESTIGACIÓN:
Entrenamos clasificadores para la identificación de informes de errores de seguridad (SBR) basándose únicamente en el título de los informes. Hasta donde sabemos, este es el primer trabajo en hacerlo. Los trabajos anteriores usaron el informe de errores completo o mejoraron el informe de errores con características complementarias adicionales. La clasificación de errores basándose únicamente en el icono es especialmente relevante cuando los informes de errores completos no se pueden poner a disposición debido a problemas de privacidad. Por ejemplo, es conocido el caso de informes de errores que contienen contraseñas y otros datos confidenciales.
También proporcionamos el primer estudio sistemático de la tolerancia al ruido de etiquetas de diferentes modelos y técnicas de aprendizaje automático que se usan para la clasificación automática de los SBR. Realizamos un estudio comparativo de la robustez de tres técnicas de aprendizaje automático distintas (regresión logística, Naïve Bayes y AdaBoost) frente al ruido dependiente de clase e independiente de clase.
El resto del documento se presenta de la siguiente manera: En la sección II presentamos algunas de las obras anteriores en la literatura. En la sección III se describe el conjunto de datos y cómo se procesan previamente los datos. La metodología se describe en la sección IV y los resultados de nuestros experimentos analizados en la sección V. Por último, nuestras conclusiones y futuros trabajos se presentan en VI.
II. TRABAJOS ANTERIORES
APLICACIONES DE MACHINE LEARNING PARA REPOSITORIOS DE ERRORES.
Existe una amplia documentación sobre cómo aplicar minería de texto, procesamiento de lenguaje natural y aprendizaje automático en repositorios de errores en un intento de automatizar tareas laboriosas, como la detección de errores de seguridad [2], [7], [8], [18], identificación de errores duplicados [3], evaluación de errores [1], [11], para nombrar algunas aplicaciones. Idealmente, la integración del aprendizaje automático (ML) y el procesamiento de lenguaje natural puede reducir el trabajo manual necesario para gestionar las bases de datos de errores, reducir el tiempo requerido para estas tareas y aumentar la confiabilidad de los resultados.
En [7] los autores proponen un modelo de lenguaje natural para automatizar la clasificación de los SBR en función de la descripción del error. Los autores extraen un vocabulario de toda la descripción de errores en el conjunto de datos de entrenamiento y lo organizan manualmente en tres listas de palabras: palabras relevantes, palabras irrelevantes (palabras comunes que parecen irrelevantes para la clasificación) y sinónimos. Comparan el rendimiento del clasificador de errores de seguridad entrenado en todos los datos evaluados por los ingenieros de seguridad y un clasificador de errores de seguridad entrenado en datos etiquetados por informantes de errores en general. Aunque el modelo es claramente más eficaz cuando se entrena sobre datos revisados por ingenieros de seguridad, el modelo propuesto se basa en un vocabulario derivado manualmente, lo que hace que dependa de la supervisión humana. Además, no hay ningún análisis de cómo afectan los distintos niveles de ruido a su modelo, cómo responden los clasificadores diferentes al ruido y si el ruido de cualquiera de las clases afecta al rendimiento de forma diferente.
Zou et. al [18] utilice varios tipos de información contenida en un informe de errores que implique los campos no textuales de un informe de errores (características meta, por ejemplo, tiempo, gravedad y prioridad) y el contenido textual de un informe de errores (características textuales, es decir, el texto en campos de resumen). En función de estas características, crean un modelo para identificar automáticamente los SBR a través del procesamiento de lenguaje natural y las técnicas de aprendizaje automático. En [8] los autores realizan un análisis similar, pero además comparan el rendimiento de las técnicas de aprendizaje automático supervisados y no supervisados, y analizan la cantidad de datos necesarios para entrenar sus modelos.
En [2] los autores también exploran diferentes técnicas de aprendizaje automático para clasificar errores como SBR o NSBR (informe de errores que no son de seguridad) en función de sus descripciones. Proponen un flujo de trabajo para el procesamiento de datos y el entrenamiento del modelo basado en TFIDF. Comparan la tubería propuesta con un modelo basado en la bolsa de palabras y naive Bayes. Wijayasekara et al. [16] también usó técnicas de minería de texto para generar el vector de características de cada informe de errores en función de palabras frecuentes para identificar errores de impacto ocultos (HIB). Yang et al. [17] afirmaron identificar informes de errores de alto impacto (por ejemplo, SBRs) con la ayuda de la frecuencia de términos (TF) y Naive Bayes. En [9] los autores proponen un modelo para predecir la gravedad de un error.
RUIDO DE ETIQUETA
El problema de manejar conjuntos de datos con ruido de etiquetas se ha estudiado ampliamente. Frenay y Verleysen proponen una taxonomía de ruido de etiqueta en [6], con el fin de distinguir diferentes tipos de etiqueta ruidosa. Los autores proponen tres tipos diferentes de ruido: ruido de etiqueta que se produce independientemente de la clase verdadera y de los valores de las características de la instancia; ruido de etiqueta que depende solo de la etiqueta verdadera; y ruido de etiqueta en el que la probabilidad de etiquetado erróneo también depende de los valores de las características. En nuestro trabajo estudiamos los dos primeros tipos de ruido. Desde una perspectiva teórica, el ruido de etiqueta normalmente disminuye el rendimiento de un modelo [10], excepto en algunos casos específicos [14]. En general, los métodos robustos dependen de evitar el sobreajuste para manejar el ruido en las etiquetas [15]. El estudio de los efectos de ruido en la clasificación se ha realizado antes en muchas áreas, como la clasificación de imágenes satélite [13], la clasificación de calidad de software [4] y la clasificación de dominios médicos [12]. A lo mejor de nuestro conocimiento, no hay trabajos publicados que estudien la cuantificación precisa de los efectos de las etiquetas ruidosas en el problema de la clasificación de los SBR. En este escenario, no se ha establecido la relación precisa entre los niveles de ruido, los tipos de ruido y la degradación del rendimiento. Además, vale la pena comprender cómo se comportan diferentes clasificadores en presencia de ruido. Por lo general, no somos conscientes de ningún trabajo que estudia sistemáticamente el efecto de los conjuntos de datos ruidosos en el rendimiento de diferentes algoritmos de aprendizaje automático en el contexto de los informes de errores de software.
III. DESCRIPCIÓN DEL CONJUNTO DE DATOS
Nuestro conjunto de datos consta de 1.073.149 títulos de errores, 552.073 de los cuales corresponden a SBR y 521.076 a NSBR. Los datos se recopilaron de varios equipos de Microsoft en los años 2015, 2016, 2017 y 2018. Todas las etiquetas se obtuvieron mediante sistemas de comprobación de errores basados en firmas o con etiquetas humanas. Los títulos de errores de nuestro conjunto de datos son textos muy cortos, que contienen alrededor de 10 palabras, con una visión general del problema.
A. Procesamiento previo de datos Analizamos cada título de error por sus espacios en blanco, lo que da lugar a una lista de tokens. Procesamos cada lista de tokens de la siguiente manera:
Eliminación de todos los tokens que son rutas de acceso de archivo
Dividir tokens en los que están presentes los símbolos siguientes: { , (, ), -, }, {, [, ], }
Quite las palabras vacías, tokens compuestos solo por caracteres numéricos y tokens que aparecen menos de 5 veces en todo el corpus.
IV. METODOLOGÍA
El proceso de entrenamiento de nuestros modelos de aprendizaje automático consta de dos pasos principales: codificar los datos en vectores de características y entrenar clasificadores de aprendizaje automático supervisados.
A. Vectores de características y técnicas de aprendizaje automático
La primera parte implica la codificación de datos en vectores de características mediante el término frequencyinverse document frequency algorithm (TF-IDF), tal como se usa en [2]. TF-IDF es una técnica de recuperación de información que pondera la frecuencia de términos (TF) y su frecuencia inversa de documentos (IDF). Cada palabra o término tiene su puntuación de TF y IDF correspondientes. El algoritmo TF-IDF asigna la importancia a esa palabra en función del número de veces que aparece en el documento y, lo que es más importante, comprueba la importancia de la palabra clave en toda la colección de títulos del conjunto de datos. Hemos entrenado y comparado tres técnicas de clasificación: Bayes naïve (NB), árboles de decisión ampliados (AdaBoost) y regresión logística (LR). Hemos elegido estas técnicas porque se han demostrado que funcionan bien para la tarea relacionada de identificar informes de errores de seguridad basados en todo el informe de la literatura. Estos resultados se confirmaron en un análisis preliminar en el que estos tres clasificadores superaron el rendimiento de las máquinas de vectores de soporte y los bosques aleatorios. En nuestros experimentos utilizamos la biblioteca scikit-learn para codificar y entrenar modelos.
B. Tipos de ruido
El ruido estudiado en este trabajo hace referencia al ruido presente en la etiqueta de clase en los datos utilizados para el entrenamiento. En presencia de este ruido, como consecuencia, el proceso de aprendizaje y el modelo resultante se ven afectados por ejemplos mal etiquetados. Analizamos el impacto de diferentes niveles de ruido aplicados a la información de clase. Los tipos de ruido de etiquetas se han analizado anteriormente en la literatura usando diversas terminologías. En nuestro trabajo, analizamos los efectos de dos tipos diferentes de ruido de etiqueta en nuestros clasificadores: ruido de etiqueta independiente de la clase, que se introduce al seleccionar instancias aleatoriamente y cambiar su etiqueta; y ruido de etiqueta dependiente de la clase, donde las clases tienen diferentes probabilidades de ser ruidosa.
a) Ruido independiente de clase: el ruido independiente de clase hace referencia al ruido que se produce independientemente de la clase verdadera de las instancias. En este tipo de ruido, la probabilidad de etiquetar erróneamente pbr es la misma para todas las instancias del conjunto de datos. Introducimos ruido independiente de la clase en nuestros conjuntos de datos al cambiar cada etiqueta de nuestro conjunto de datos de manera aleatoria con una probabilidad pbr.
b) Ruido dependiente de la clase: el ruido dependiente de la clase hace referencia al ruido que depende de la clase verdadera de las instancias. En este tipo de ruido, la probabilidad de etiquetar erróneamente en la clase SBR es psbr y la probabilidad de etiquetar erróneamente en la clase NSBR es pnsbr. Presentamos ruido dependiente de la clase en nuestro conjunto de datos al cambiar cada entrada para la que la etiqueta verdadera es SBR con probabilidad de psbr. De forma análoga, se invierte la etiqueta de clase de las instancias de NSBR con probabilidad pnsbr.
c) Ruido de clase única: ruido de clase única es un caso especial de ruido dependiente de la clase, donde pnsbr = 0 y psbr> 0. Tenga en cuenta que para el ruido independiente de clase tenemos psbr = pnsbr = pbr.
C. Generación de ruido
Nuestros experimentos investigan el impacto de diferentes tipos de ruido y niveles en el entrenamiento de clasificadores SBR. En nuestros experimentos, establecemos 25% del conjunto de datos como datos de prueba, 10% como validación y 65% como datos de entrenamiento.
Agregamos ruido a los conjuntos de datos de entrenamiento y validación para diferentes niveles de pbr, psbr y pnsbr . No se realizan modificaciones en el conjunto de datos de prueba. Los distintos niveles de ruido utilizados son P = {0,05 × i|0 < i < 10}.
En experimentos de ruido independientes de clase, para pbr ∈ P hacemos lo siguiente:
Generar ruido para conjuntos de datos de entrenamiento y validación;
Entrenar la regresión logística, los modelos Bayes y AdaBoost naïve mediante el conjunto de datos de entrenamiento (con ruido); * Optimizar modelos mediante el conjunto de datos de validación (con ruido);
Probar modelos mediante el conjunto de datos de prueba (sin ruido).
En experimentos de ruido dependientes de clase, para psbr ∈ P y pnsbr ∈ P hacemos lo siguiente para todas las combinaciones de psbr y pnsbr:
Generar ruido para conjuntos de datos de entrenamiento y validación;
Entrenar modelos de regresión logística, de Bayes ingenuo y de AdaBoost utilizando el conjunto de datos de entrenamiento (con ruido);
Ajuste de modelos mediante el conjunto de datos de validación (con ruido);
Probar modelos mediante el conjunto de datos de prueba (sin ruido).
V. RESULTADOS EXPERIMENTALES
En esta sección se analizan los resultados de los experimentos realizados según la metodología descrita en la sección IV.
a) Rendimiento del modelo sin ruido en el conjunto de datos de entrenamiento: una de las contribuciones de este documento es la propuesta de un modelo de aprendizaje automático para identificar errores de seguridad usando solo el título del error como datos para la toma de decisiones. Esto permite el entrenamiento de modelos de aprendizaje automático incluso cuando los equipos de desarrollo no desean compartir informes de errores en su totalidad debido a la presencia de datos confidenciales. Comparamos el rendimiento de tres modelos de aprendizaje automático cuando se entrenan con solo títulos de errores.
El modelo de regresión logística es el clasificador de mejor rendimiento. Es el clasificador con el valor de AUC más alto, de 0,9826, con un recall de 0,9353 para un valor de FPR de 0,0735. El clasificador bayes naïve presenta un rendimiento ligeramente menor que el clasificador de regresión logística, con una AUC de 0,9779 y una recuperación de 0,9189 para un FPR de 0,0769. El clasificador AdaBoost tiene un rendimiento inferior en comparación con los dos clasificadores mencionados anteriormente. Logra una AUC de 0,9143 y una recuperación de 0,7018 para un FPR 0,0774. El área bajo la curva ROC (AUC) es una buena métrica para comparar el rendimiento de varios modelos, ya que resume en un solo valor la relación de TPR frente a FPR. En el análisis posterior, restringiremos nuestro análisis comparativo a los valores de AUC.
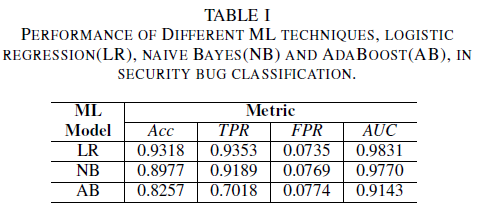
A. Ruido de clase: clase única
Se puede imaginar un escenario en el que todos los errores se asignan a la clase NSBR de forma predeterminada y un error solo se asignará a la clase SBR si hay un experto en seguridad que revisa el repositorio de errores. Este escenario se representa en la configuración experimental de clase única, donde se supone que pnsbr = 0 y 0 < psbr< 0,5.
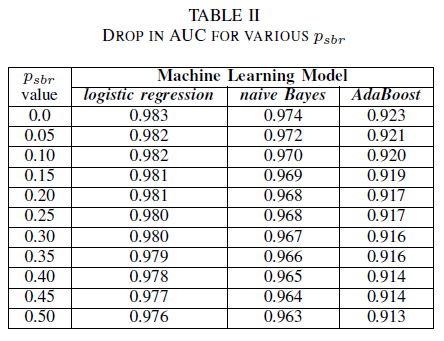
En la tabla II observamos un impacto muy pequeño en la AUC para los tres clasificadores. El AUC-ROC de un modelo entrenado en psbr = 0, en comparación con el AUC-ROC de otro modelo donde psbr = 0,25, difiere en 0,003 para la regresión logística, 0,006 para Naive Bayes, y 0,006 para AdaBoost. En el caso de psbr = 0,50, la AUC medida para cada uno de los modelos difiere del modelo entrenado con psbr = 0 en 0,007 para la regresión logística, 0,011 para Bayes naïve y 0,010 para AdaBoost. el clasificador de regresión logística entrenado en presencia de ruido de clase única presenta la variación más pequeña en su métrica de AUC, es decir, un comportamiento más sólido, en comparación con nuestros clasificadores bayes y AdaBoost naïve.
B. Ruido de clase: independiente de la clase
Comparamos el rendimiento de nuestros tres clasificadores para el caso en el que el conjunto de entrenamiento está alterado por un ruido independiente de la clase. Medimos la AUC para cada modelo entrenado con diferentes niveles de pbr en los datos de entrenamiento.
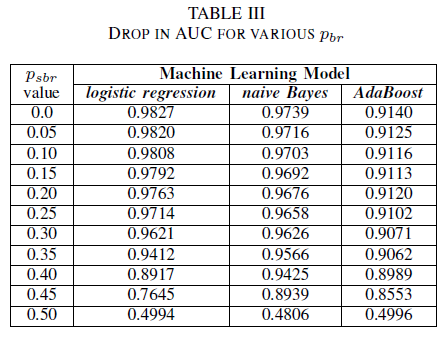
En la tabla III observamos una disminución en el AUC-ROC para cada incremento de ruido en el experimento. El AUC-ROC medido a partir de un modelo entrenado en datos sin ruido en comparación con el AUC-ROC del modelo entrenado con ruido independiente de clase con pbr = 0,25, difiere en 0,011 para la regresión logística, 0,008 para naive Bayes y 0,0038 para AdaBoost. Observamos que el ruido de etiqueta no afecta significativamente a la AUC del Naive Bayes y los clasificadores AdaBoost cuando los niveles de ruido son inferiores a 40%. Por otro lado, el clasificador de regresión logística experimenta un impacto en la medida de AUC para niveles de ruido de etiquetas por encima del 30%.
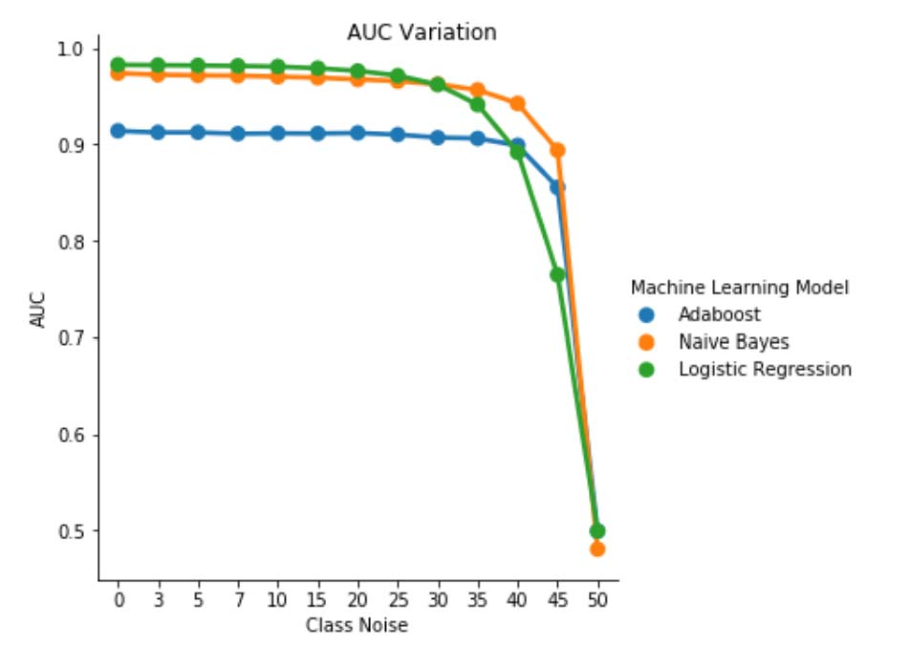
Fig. 1. Variación de AUC-ROC en ruido independiente de clase. Para un nivel de ruido pbr =0,5, el clasificador actúa como un clasificador aleatorio, es decir, AUC≈0.5. Pero podemos observar que para niveles de ruido inferiores (pbr ≤0.30), el aprendiz de regresión logística presenta un mejor rendimiento en comparación con los otros dos modelos. Sin embargo, para 0.35≤ pbr ≤0.45 naïve Bayes learner presenta mejores métricas de AUCROC.
C. Ruido de clase: dependiente de la clase
En el conjunto final de experimentos, consideramos un escenario en el que diferentes clases contienen diferentes niveles de ruido, es decir, psbr ≠ pnsbr. Incrementamos sistemáticamente psbr y pnsbr independientemente en 0,05 en los datos de entrenamiento y observamos el cambio en el comportamiento de los tres clasificadores.
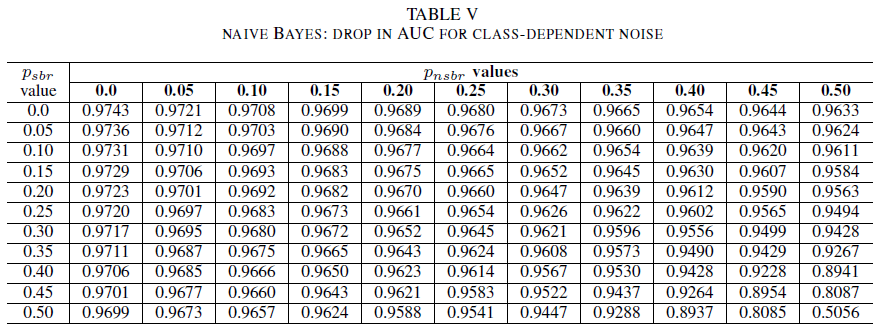
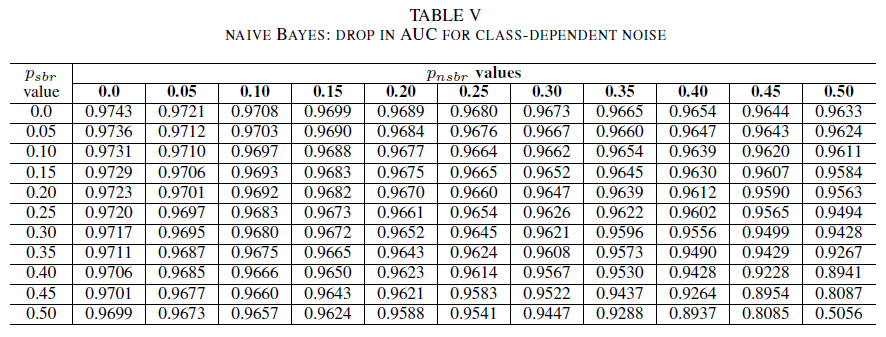
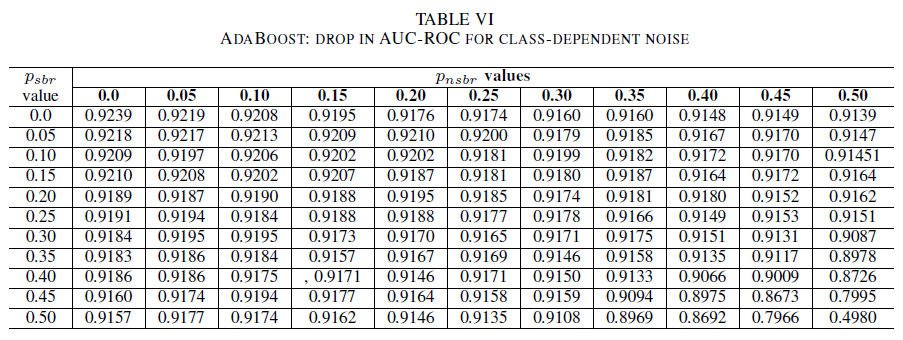
Las tablas IV, V, VI muestran la variación de AUC a medida que el ruido aumenta en distintos niveles de cada clase, para la regresión logística en la tabla IV, para Naive Bayes en la tabla V, y para AdaBoost en la tabla VI. Para todos los clasificadores, observamos un impacto en la métrica de AUC cuando ambas clases contienen un nivel de ruido superior a 30%. El modelo naive Bayes se comporta de manera más robusta. El impacto en AUC es muy pequeño incluso cuando se voltean el 50% de las etiquetas de la clase positiva, siempre que la clase negativa contenga 30% de etiquetas ruidosas o menos. En este caso, la caída en AUC es de 0,03. AdaBoost presentó el comportamiento más sólido de los tres clasificadores. Un cambio significativo en AUC solo se producirá para los niveles de ruido mayores que 45% en ambas clases. En ese caso, empezamos a observar una disminución de AUC mayor que 0,02.
D. En la presencia de ruido residual en el conjunto de datos original
Nuestro conjunto de datos se etiquetó mediante sistemas automatizados basados en firmas y por expertos humanos. Además, todos los informes de errores han sido revisados y cerrados por expertos humanos. Aunque esperamos que la cantidad de ruido en nuestro conjunto de datos sea mínima y no estadísticamente significativa, la presencia de ruido residual no invalida nuestras conclusiones. En efecto, a modo de ilustración, supongamos que el conjunto de datos original está dañado por un ruido independiente de clase igual a 0 < p < 1/2 independiente e idénticamente distribuido (i.i.d) para cada entrada.
Si, encima del ruido original, agregamos un ruido independiente de clase con probabilidad pbr i.i.d, el ruido resultante por entrada será p∗ = p(1 − pbr )+(1 − p)pbr . Para 0 < p,pbr< 1/2, tenemos que el ruido real por etiqueta p∗ es estrictamente mayor que el ruido que agregamos artificialmente al conjunto de datos pbr . Por lo tanto, el rendimiento de nuestros clasificadores sería aún mejor si estuvieran entrenados con un conjunto de datos completamente sin ruido (p = 0) en primer lugar. En resumen, la existencia de ruido residual en el conjunto de datos real significa que la resistencia frente al ruido de nuestros clasificadores es mejor que los resultados aquí presentados. Además, si el ruido residual de nuestro conjunto de datos fuera estadísticamente relevante, la AUC de nuestros clasificadores se convertiría en 0,5 (una estimación aleatoria) para un nivel de ruido estrictamente inferior a 0,5. No observamos este comportamiento en nuestros resultados.
VI. CONCLUSIONES Y TRABAJOS FUTUROS
Nuestra contribución en este artículo es doble.
En primer lugar, hemos mostrado la viabilidad de la clasificación de informes de errores de seguridad basada únicamente en el título del informe de errores. Esto es especialmente relevante en escenarios en los que el informe de errores completo no está disponible debido a restricciones de privacidad. Por ejemplo, en nuestro caso, los informes de errores contenían información privada, como contraseñas y claves criptográficas, y no estaban disponibles para entrenar a los clasificadores. Nuestro resultado muestra que la identificación de SBR se puede realizar con alta precisión incluso cuando solo hay títulos de informe disponibles. Nuestro modelo de clasificación que utiliza una combinación de TF-IDF y regresión logística alcanza un valor AUC de 0,9831.
En segundo lugar, hemos analizado el efecto de los datos de entrenamiento y validación mal etiquetados. Comparamos tres técnicas conocidas de clasificación de aprendizaje automático (bayes naïve, regresión logística y AdaBoost) en términos de su solidez frente a diferentes tipos de ruido y niveles de ruido. Los tres clasificadores son resistentes al ruido de una sola clase. El ruido de los datos de entrenamiento no tiene ningún efecto significativo en el clasificador resultante. La disminución en AUC es muy pequeña ( 0,01) para un nivel de ruido de 50%. Para el ruido presente en ambas clases e independiente de la clase, los modelos de naive Bayes y AdaBoost presentan variaciones significativas en el área bajo la curva (AUC) solo cuando se entrenan con un conjunto de datos con niveles de ruido superiores al 40%.
Por último, el ruido dependiente de la clase afecta significativamente a la AUC solo cuando hay más de 35% ruido en ambas clases. AdaBoost mostró la mayor robustez. El impacto en AUC es muy pequeño incluso cuando la clase positiva tiene el 50% de sus etiquetas ruidosas, siempre y cuando la clase negativa contenga el 45% de etiquetas ruidosas o menos. En este caso, la caída en AUC es inferior a 0,03. A lo mejor de nuestro conocimiento, este es el primer estudio sistemático sobre el efecto de los conjuntos de datos ruidosos para la identificación del informe de errores de seguridad.
FUTUROS TRABAJOS
En este documento hemos iniciado el estudio sistemático de los efectos del ruido en el rendimiento de clasificadores de aprendizaje automático para la identificación de errores de seguridad. Hay varias secuelas interesantes para este trabajo, entre las que se incluyen: examinar el efecto de los conjuntos de datos ruidosos al determinar el nivel de gravedad de un error de seguridad; comprender el efecto del desequilibrio de clases sobre la resistencia de los modelos entrenados contra el ruido; comprender el efecto del ruido que se introduce de forma adversa en el conjunto de datos.
REFERENCIAS
[1] John Anvik, Lyndon Hiew y Gail C Murphy. ¿Quién debe corregir este error? En Actas de la 28ª conferencia internacional sobre ingeniería de software, páginas 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa y Anuja Arora. Una herramienta de minería de errores para identificar y analizar fallos de seguridad mediante naive bayes y tf-idf. En Optimización, Fiabilidad e Informática (ICROIT), en la Conferencia Internacional de 2014, páginas 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann y Sunghun Kim. ¿Los informes de errores duplicados se consideran realmente perjudiciales? En Mantenimiento de Software, 2008. ICSM 2008. IEEE Conferencia Internacional sobre, páginas 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse y Lofton Bullard. Identificación de aprendices robustos con datos de baja calidad. En Reutilización e integración de la información, 2008. IRI 2008. Conferencia Internacional IEEE sobre, páginas 190–195. IEEE, 2008.
[5] Benoˆît Frenay. Incertidumbre y ruido en las etiquetas en el aprendizaje automático. Tesis de doctorado, Universidad Católica de Louvain, Louvain-la-Neuve, Bélgica, 2013.
[6] Benoˆıt Frenay y Michel Verleysen. Clasificación en presencia de ruido en las etiquetas: un análisis. Transacciones IEEE en redes neuronales y sistemas de aprendizaje, 25(5):845–869, 2014.
[7] Michael Gegick, Pete Rotella y Tao Xie. Identificación de informes de errores de seguridad a través de minería de texto: un caso práctico industrial. En minería de repositorios de software (MSR), 2010 la 7ª conferencia de trabajo de IEEE sobre, páginas 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova y Jacob Tyo. Identificación de los informes de errores relacionados con la seguridad a través de la minería de texto mediante la clasificación supervisada y no supervisada. En 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), páginas 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger y Bart Goethals. Predicción de la gravedad de un error notificado. En Repositorios de software de minería de datos (MSR), 2010 7th IEEE Working Conference on, páginas 1–10. IEEE, 2010.
[10] Naresh Manwani y PS Sastry. Tolerancia al ruido bajo minimización de riesgos. Transacciones IEEE en cibernéticas, 43(3):1146–1151, 2013.
[11] G Murphy y D Cubranic. Evaluación automática de errores mediante categorización de texto. En Actas de la Decimosexta Conferencia Internacional sobre Ingeniería de Software e Ingeniería de Conocimiento. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen y Oleksandr Pechenizkiy. Ruido de clase y aprendizaje supervisado en dominios médicos: el efecto de la extracción de características. En null, páginas 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre y Gerard Dedieu. Efecto del ruido de la etiqueta de clase de entrenamiento en el rendimiento de clasificación para el mapeo de cobertura terrestre con series temporales de imágenes de satélite. Detección remota, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra y Naresh Manwani. Un equipo de autómatas de aprendizaje de acción continua para el aprendizaje tolerante al ruido de los mediaespacios. Transacciones IEEE en sistemas, hombre y cibernéticas, parte B (cibernéticas), 40(1):19–28, 2010.
[15] Choh-Man Teng. Comparación de técnicas de control de ruido. En la Conferencia FLAIRS, páginas 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic y Miles McQueen. Identificación y clasificación de vulnerabilidades mediante bases de datos de errores de minería de texto. En Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, páginas 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia y Jiangling Sun. Identificación automatizada de informes de errores de alto impacto que utilizan las estrategias de aprendizaje desbalanceado. En Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual, volumen 1, páginas 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li y Hai Jin. Identificar automáticamente los informes de errores de seguridad a través del análisis de características de varios tipos. En la Conferencia Australiana sobre Seguridad y Privacidad, páginas 619–633. Springer, 2018.