Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Las características de orquestación del agente en Agent Framework se encuentran en la fase experimental. Están en desarrollo activo y pueden cambiar significativamente antes de avanzar a la fase de versión preliminar o candidata para lanzamiento.
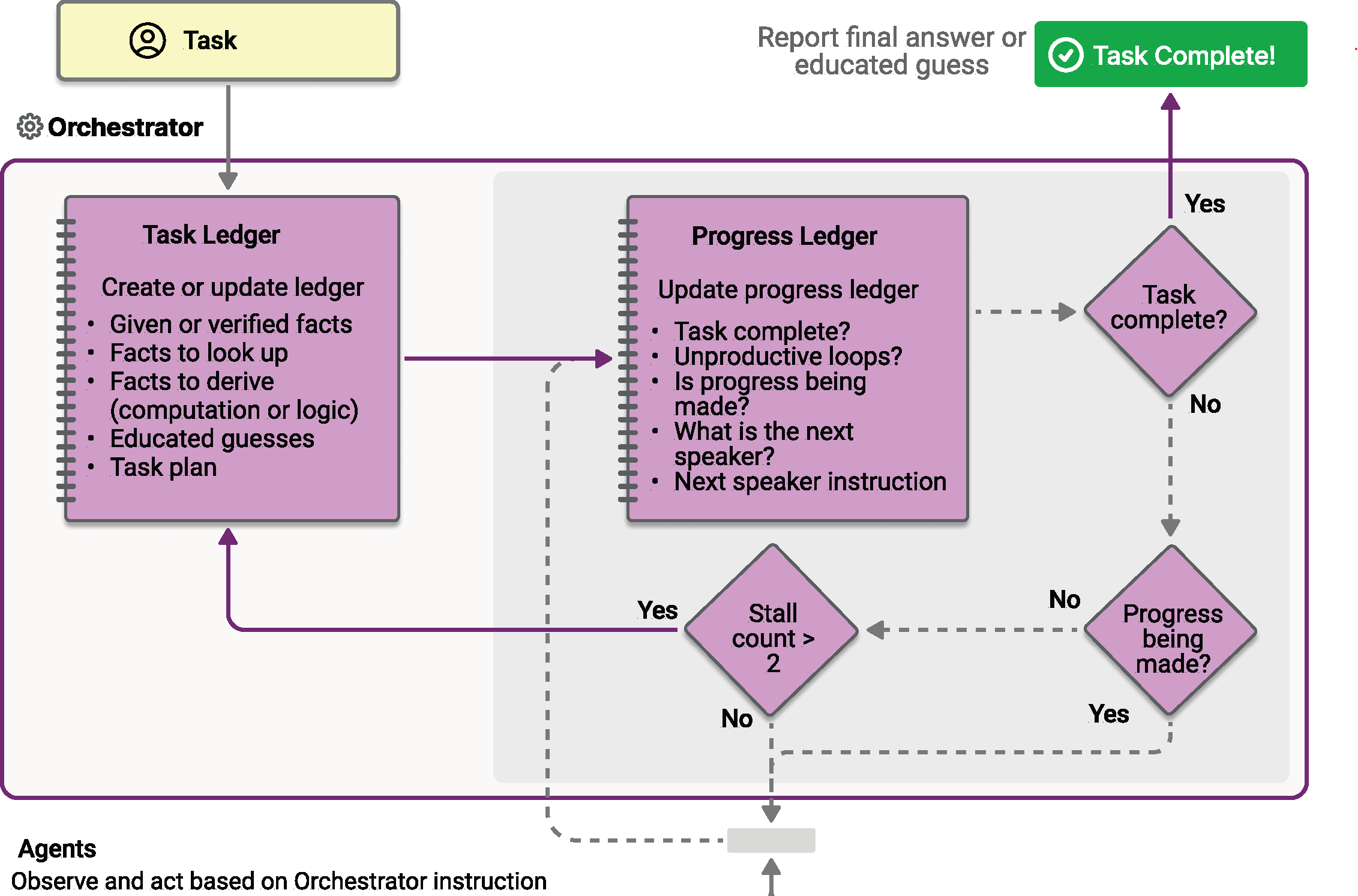
La orquestación magnética está diseñada a partir del sistema Magentic-One inventado por AutoGen. Es un patrón multiagente flexible y de uso general diseñado para tareas complejas y abiertas que requieren colaboración dinámica. En este patrón, un administrador de Magentic dedicado coordina un equipo de agentes especializados, seleccionando qué agente debe actuar a continuación en función del contexto en constante evolución, el progreso de las tareas y las funcionalidades del agente.
El administrador de Magentic mantiene un contexto compartido, realiza un seguimiento del progreso y adapta el flujo de trabajo en tiempo real. Esto permite al sistema desglosar problemas complejos, delegar subtareas y refinar soluciones de forma iterativa a través de la colaboración del agente. La orquestación es especialmente adecuada para escenarios en los que la ruta de solución no se conoce de antemano y puede requerir varias rondas de razonamiento, investigación y cálculo.
Sugerencia
Obtenga más información sobre el Magentic-One aquí.
Sugerencia
El nombre "Magentic" procede de "Magentic-One". "Magentic-One" es un sistema multiagente que incluye un conjunto de agentes, tales como el WebSurfer y el FileSurfer. La orquestación magnética del Kernel Semántico se inspira en el sistema Magentic-One, donde el Magentic administrador coordina un equipo de agentes especializados para resolver tareas complejas. Sin embargo, no es una implementación directa del sistema de Magentic-One y no incluye los agentes del sistema Magentic-One.
Para obtener más información sobre el patrón, como cuándo utilizarlo o cuándo evitarlo en su carga de trabajo, consulte Orquestación Magentic.
Casos de uso comunes
Un usuario solicita un informe completo que compare la eficiencia energética y las emisiones de CO₂ de diferentes modelos de aprendizaje automático. El administrador de Magentic asigna primero un agente de investigación para recopilar datos relevantes y, a continuación, delega el análisis y el cálculo en un agente de codificador. El administrador coordina varias rondas de investigación y cálculo, agrega los resultados y genera un informe detallado estructurado como salida final.
Temas que se abordarán
- Cómo definir y configurar agentes para la orquestación magnética
- Cómo configurar un administrador magentic para coordinar la colaboración del agente
- Funcionamiento del proceso de orquestación, incluida la planificación, el seguimiento de progreso y la síntesis de respuesta final
Definir los agentes
Cada agente del patrón Magentic tiene un rol especializado. En este ejemplo:
- ResearchAgent: busca y resume la información (por ejemplo, a través de la búsqueda web). En este ejemplo se usa
ChatCompletionAgentcon el modelogpt-4o-search-previewpara su funcionalidad de búsqueda web. - CoderAgent: escribe y ejecuta código para analizar o procesar datos. Aquí el ejemplo usa
AzureAIAgentya que tiene herramientas avanzadas como el intérprete de código.
Sugerencia
El ChatCompletionAgent y el AzureAIAgent se utilizan en este caso, pero también puedes usar cualquier tipo de agente.
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Agents;
using Microsoft.SemanticKernel.Agents.AzureAI;
using Microsoft.SemanticKernel.Agents.Magentic;
using Microsoft.SemanticKernel.Agents.Orchestration;
using Microsoft.SemanticKernel.Agents.Runtime.InProcess;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using Azure.AI.Agents.Persistent;
using Azure.Identity;
// Helper function to create a kernel with chat completion
public static Kernel CreateKernelWithChatCompletion(...)
{
...
}
// Create a kernel with OpenAI chat completion for the research agent
Kernel researchKernel = CreateKernelWithChatCompletion("gpt-4o-search-preview");
ChatCompletionAgent researchAgent = new ChatCompletionAgent {
Name = "ResearchAgent",
Description = "A helpful assistant with access to web search. Ask it to perform web searches.",
Instructions = "You are a Researcher. You find information without additional computation or quantitative analysis.",
Kernel = researchKernel,
};
// Create a persistent Azure AI agent for code execution
PersistentAgentsClient agentsClient = AzureAIAgent.CreateAgentsClient(endpoint, new AzureCliCredential());
PersistentAgent definition = await agentsClient.Administration.CreateAgentAsync(
modelId,
name: "CoderAgent",
description: "Write and executes code to process and analyze data.",
instructions: "You solve questions using code. Please provide detailed analysis and computation process.",
tools: [new CodeInterpreterToolDefinition()]);
AzureAIAgent coderAgent = new AzureAIAgent(definition, agentsClient);
Configurar el Administrador Magentic
El administrador de Magentic coordina los agentes, planea el flujo de trabajo, realiza un seguimiento del progreso y sintetiza la respuesta final. El administrador estándar (StandardMagenticManager) usa un modelo de finalización de chat que admite la salida estructurada.
Kernel managerKernel = CreateKernelWithChatCompletion("o3-mini");
StandardMagenticManager manager = new StandardMagenticManager(
managerKernel.GetRequiredService<IChatCompletionService>(),
new OpenAIPromptExecutionSettings())
{
MaximumInvocationCount = 5,
};
Opcional: Observar respuestas del agente
Puede crear una devolución de llamada a través de la ResponseCallback propiedad para capturar las respuestas del agente a medida que avanza la orquestación.
ChatHistory history = [];
ValueTask responseCallback(ChatMessageContent response)
{
history.Add(response);
return ValueTask.CompletedTask;
}
Crear la orquestación magnética
Combine los agentes y el administrador en un objeto MagenticOrchestration.
MagenticOrchestration orchestration = new MagenticOrchestration(
manager,
researchAgent,
coderAgent)
{
ResponseCallback = responseCallback,
};
Iniciar el entorno de ejecución
Se requiere un tiempo de ejecución para administrar la ejecución de agentes. Aquí, usamos InProcessRuntime e iniciamos antes de invocar la orquestación.
InProcessRuntime runtime = new InProcessRuntime();
await runtime.StartAsync();
Invocar la orquestación
Invoque la orquestación con la tarea compleja. El administrador planeará, delegará y coordinará los agentes para resolver el problema.
string input = @"I am preparing a report on the energy efficiency of different machine learning model architectures.\nCompare the estimated training and inference energy consumption of ResNet-50, BERT-base, and GPT-2 on standard datasets (e.g., ImageNet for ResNet, GLUE for BERT, WebText for GPT-2). Then, estimate the CO2 emissions associated with each, assuming training on an Azure Standard_NC6s_v3 VM for 24 hours. Provide tables for clarity, and recommend the most energy-efficient model per task type (image classification, text classification, and text generation).";
var result = await orchestration.InvokeAsync(input, runtime);
Recopilar resultados
Espere a que la orquestación se complete y recupere la salida final.
string output = await result.GetValueAsync(TimeSpan.FromSeconds(300));
Console.WriteLine($"\n# RESULT: {output}");
Console.WriteLine("\n\nORCHESTRATION HISTORY");
foreach (ChatMessageContent message in history)
{
// Print each message
Console.WriteLine($"# {message.Role} - {message.AuthorName}: {message.Content}");
}
Opcional: Detener el tiempo de ejecución
Una vez completado el procesamiento, detenga el tiempo de ejecución para limpiar los recursos.
await runtime.RunUntilIdleAsync();
Salida de ejemplo
# RESULT: ```markdown
# Report: Energy Efficiency of Machine Learning Model Architectures
This report assesses the energy consumption and related CO₂ emissions for three popular ...
ORCHESTRATION HISTORY
# Assistant - ResearchAgent: Comparing the energy efficiency of different machine learning ...
# assistant - CoderAgent: Below are tables summarizing the approximate energy consumption and ...
# assistant - CoderAgent: The estimates provided in our tables align with a general understanding ...
# assistant - CoderAgent: Here's the updated structure for the report integrating both the ...
Sugerencia
El código de ejemplo completo está disponible aquí.
Definir los agentes
Cada agente del patrón Magentic tiene un rol especializado. En este ejemplo:
- ResearchAgent: busca y resume la información (por ejemplo, a través de la búsqueda web). En este ejemplo se usa
ChatCompletionAgentcon el modelogpt-4o-search-previewpara su funcionalidad de búsqueda web. - CoderAgent: escribe y ejecuta código para analizar o procesar datos. Aquí el ejemplo usa
OpenAIAssistantAgentya que tiene herramientas avanzadas como el intérprete de código.
Sugerencia
El ChatCompletionAgent y el OpenAIAssistantAgent se utilizan en este caso, pero también puedes usar cualquier tipo de agente.
from semantic_kernel.agents import ChatCompletionAgent, OpenAIAssistantAgent
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
research_agent = ChatCompletionAgent(
name="ResearchAgent",
description="A helpful assistant with access to web search. Ask it to perform web searches.",
instructions="You are a Researcher. You find information without additional computation or quantitative analysis.",
service=OpenAIChatCompletion(ai_model_id="gpt-4o-search-preview"),
)
# Create an OpenAI Assistant agent with code interpreter capability
client, model = OpenAIAssistantAgent.setup_resources()
code_interpreter_tool, code_interpreter_tool_resources = OpenAIAssistantAgent.configure_code_interpreter_tool()
definition = await client.beta.assistants.create(
model=model,
name="CoderAgent",
description="A helpful assistant that writes and executes code to process and analyze data.",
instructions="You solve questions using code. Please provide detailed analysis and computation process.",
tools=code_interpreter_tool,
tool_resources=code_interpreter_tool_resources,
)
coder_agent = OpenAIAssistantAgent(
client=client,
definition=definition,
)
Configurar el Administrador Magentic
El administrador de Magentic coordina los agentes, planea el flujo de trabajo, realiza un seguimiento del progreso y sintetiza la respuesta final. El administrador estándar (StandardMagenticManager) usa avisos cuidadosamente diseñados y requiere un modelo de finalización de chat que admita la salida estructurada.
from semantic_kernel.agents import StandardMagenticManager
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
manager = StandardMagenticManager(chat_completion_service=OpenAIChatCompletion())
Opcional: Observar respuestas del agente
Puede definir un callback para mostrar el mensaje de cada agente a medida que avanza la orquestación.
from semantic_kernel.contents import ChatMessageContent
def agent_response_callback(message: ChatMessageContent) -> None:
print(f"**{message.name}**\n{message.content}")
Crear la orquestación magnética
Combine los agentes y el administrador en un objeto MagenticOrchestration.
from semantic_kernel.agents import MagenticOrchestration
magentic_orchestration = MagenticOrchestration(
members=[research_agent, coder_agent],
manager=manager,
agent_response_callback=agent_response_callback,
)
Iniciar el entorno de ejecución
Inicie el entorno de ejecución para gestionar la ejecución del agente.
from semantic_kernel.agents.runtime import InProcessRuntime
runtime = InProcessRuntime()
runtime.start()
Invocar la orquestación
Invoque la orquestación con la tarea compleja. El administrador planeará, delegará y coordinará los agentes para resolver el problema.
orchestration_result = await magentic_orchestration.invoke(
task=(
"I am preparing a report on the energy efficiency of different machine learning model architectures. "
"Compare the estimated training and inference energy consumption of ResNet-50, BERT-base, and GPT-2 "
"on standard datasets (e.g., ImageNet for ResNet, GLUE for BERT, WebText for GPT-2). "
"Then, estimate the CO2 emissions associated with each, assuming training on an Azure Standard_NC6s_v3 VM "
"for 24 hours. Provide tables for clarity, and recommend the most energy-efficient model "
"per task type (image classification, text classification, and text generation)."
),
runtime=runtime,
)
Recopilar resultados
Espere hasta que la orquestación se complete e imprima el resultado final.
value = await orchestration_result.get()
print(f"\nFinal result:\n{value}")
Opcional: Detener el tiempo de ejecución
Una vez completado el procesamiento, detenga el tiempo de ejecución para limpiar los recursos.
await runtime.stop_when_idle()
Salida de ejemplo
**ResearchAgent**
Estimating the energy consumption and associated CO₂ emissions for training and inference of ResNet-50, BERT-base...
**CoderAgent**
Here is the comparison of energy consumption and CO₂ emissions for each model (ResNet-50, BERT-base, and GPT-2)
over a 24-hour period:
| Model | Training Energy (kWh) | Inference Energy (kWh) | Total Energy (kWh) | CO₂ Emissions (kg) |
|-----------|------------------------|------------------------|---------------------|---------------------|
| ResNet-50 | 21.11 | 0.08232 | 21.19232 | 19.50 |
| BERT-base | 0.048 | 0.23736 | 0.28536 | 0.26 |
| GPT-2 | 42.22 | 0.35604 | 42.57604 | 39.17 |
...
Final result:
Here is the comprehensive report on energy efficiency and CO₂ emissions for ResNet-50, BERT-base, and GPT-2 models...
Sugerencia
El código de ejemplo completo está disponible aquí.
Nota:
La orquestación del agente aún no está disponible en el SDK de Java.