Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Uso de Azure Cognitive Services
Azure Cognitive Services es un conjunto de API basadas en la nube que puede usar en aplicaciones de inteligencia artificial y flujos de datos. Proporciona modelos previamente entrenados que están listos para usarse en las aplicaciones, sin necesidad de datos ni entrenamiento de modelos por su parte. Se pueden integrar fácilmente en las aplicaciones a través de interfaces REST HTTP.
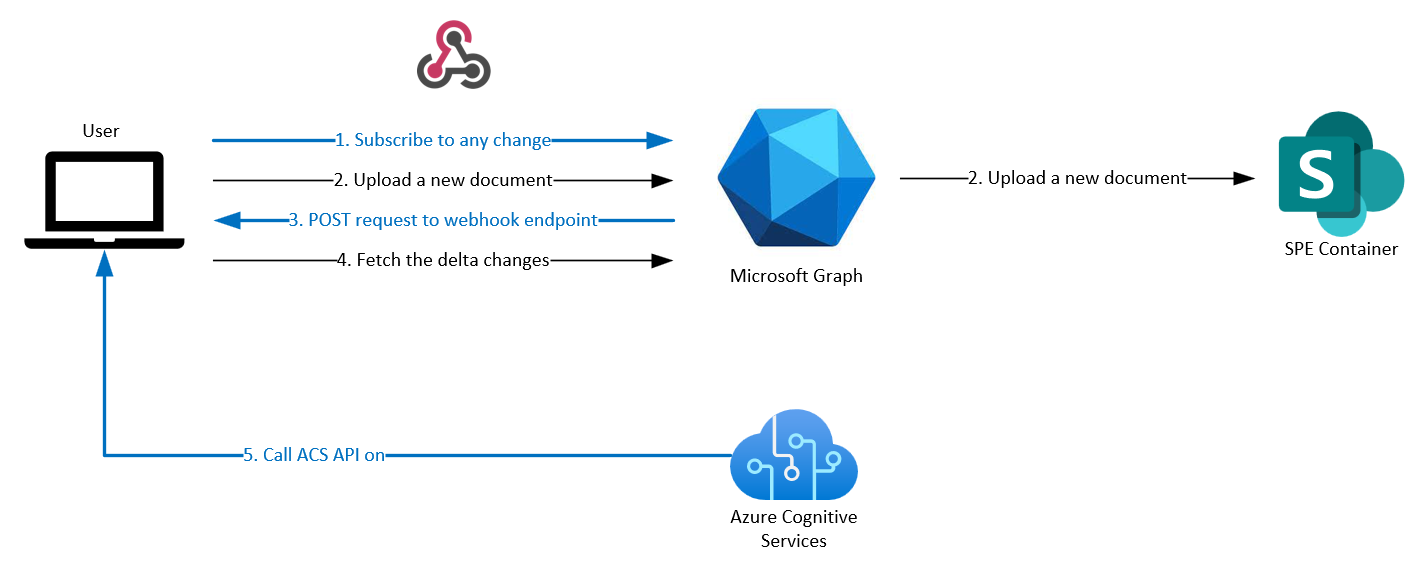
Ya ha aprendido a usar webhooks con la aplicación para obtener una notificación cada vez que se actualiza un archivo existente o se carga un nuevo archivo en el tutorial Uso de Webhooks. En este tutorial se explica cómo conectarlo con Azure Cognitive Services para extraer datos de facturas.
Para configurar el procesamiento automático de inteligencia artificial con la aplicación de SharePoint actual tras un cambio en el contenedor, debe seguir El uso de Webhooks y, a continuación,:
- Obtenga los cambios diferenciales del contenedor. Actualmente puede obtener la notificación siempre que haya algún cambio en el contenedor y ahora obtendrá los archivos que se agregan o actualizan.
- Llame a la API del servicio Document Intelligence de Azure Cognitive Services. Tendrá que crear un recurso de inteligencia artificial Azure para usar la API para extraer los campos de una imagen y obtener los archivos extraídos. Puede almacenarlos como se muestra en este tutorial o puede procesarlos como desee.
Sugerencia
Para obtener más información sobre las API de Microsoft Graph usadas en este tutorial, consulte Seguimiento de los cambios de una unidad, Obtención de un recurso DriveItem y Carga o sustitución del contenido de un objeto DriveItem.
Obtención de los cambios diferenciales de un contenedor
Abra GraphProvider.ts e implemente el método getDriveChanges para obtener la lista de elementos modificados:
public static async getDriveChanges(driveId: string): Promise<any[]> {
let changedItems: any[] = [];
const driveDeltaBasePath: string = `/drives/${driveId}/items/root/delta`;
let driveDeltaTokenParams: string = "";
let hasMoreChanges: boolean = true;
try{
do {
if (this.changeTokens.has(driveId)) {
driveDeltaTokenParams = `?token=${this.changeTokens.get(driveId)}`
}
const response = await this.graphClient.api(driveDeltaBasePath + driveDeltaTokenParams).get();
changedItems.push(...response.value);
if (response['@odata.nextLink']) {
const token = new URL(response['@odata.nextLink']).searchParams.get('token');
this.changeTokens.set(driveId, token);
} else {
hasMoreChanges = false;
const token = new URL(response['@odata.deltaLink']).searchParams.get('token');
this.changeTokens.set(driveId, token);
}
console.log(this.changeTokens.get(driveId));
} while (hasMoreChanges);
}
catch(err){
console.log(err);
}
return changedItems;
}
Implemente el método getDriveItem para capturar un archivo de un contenedor:
public static async getDriveItem(driveId: string, itemId: string): Promise<any> {
return await this.graphClient.api(`/drives/${driveId}/items/${itemId}`).get();
}
Cree un nuevo archivo ReceiptProcessor.ts e implemente un método processDrive:
export abstract class ReceiptProcessor {
public static async processDrive(driveId: string): Promise<void> {
const changedItems = await GraphProvider.getDriveChanges(driveId);
for (const changedItem of changedItems) {
try {
const item = await GraphProvider.getDriveItem(driveId, changedItem.id);
const extension = this.getFileExtension(item.name);
if (this.SUPPORTED_FILE_EXTENSIONS.includes(extension.toLowerCase())) {
console.log(item.name);
const url = item["@microsoft.graph.downloadUrl"];
const receipt = await this.analyzeReceiptStream(await this.getDriveItemStream(url));
const receiptString = JSON.stringify(receipt, null, 2)
const fileName = this.getFileDisplayName(item.name) + "-extracted-fields.json";
const parentId = item.parentReference.id;
await GraphProvider.addDriveItem(driveId, parentId, fileName, receiptString);
}
} catch (error) {
console.log(error);
}
}
}
}
En este momento, si reinicia la aplicación junto con la tunelización y la suscripción, debería ver los archivos agregados o actualizados recientemente en la consola.
Llamada a la API del servicio Document Intelligence de Azure Cognitive Services
Para usar las API de inteligencia de documentos de Azure Cognitive Services, debe crear un recurso multiservicio o document intelligence para Azure servicio de inteligencia artificial. Consulte los siguientes tutoriales para crear el recurso:
- Inicio rápido: Creación de un recurso de varios servicios para Azure servicios de inteligencia artificial
- Introducción a Document Intelligence
Después de este paso, debe tener un punto de conexión y una clave listos para usar.
Ahora abra ReceiptProcessor.ts para crear el método dac para almacenar las credenciales de Azure Cognitive Services:
private static dac = new DocumentAnalysisClient(
`${process.env["DAC_RESOURCE_ENDPOINT"]}`,
new AzureKeyCredential(`${process.env["DAC_RESOURCE_KEY"]}`)
);
Crear método getDriveItemStream.
private static async getDriveItemStream(url: string): Promise<Readable> {
const token = GraphProvider.graphAccessToken;
const config: AxiosRequestConfig = {
method: "get",
url: url,
headers: {
"Authorization": `Bearer ${token}`
},
responseType: 'stream'
};
const response = await axios.get<Readable>(url, config);
return response.data;
}
Cree un método analyzeReceiptStream para obtener los campos OCR a través de Azure procesamiento de Cognitive Services. Aquí vamos a tomar el prebuilt-invoice modelo, pero se pueden elegir otros modelos:
private static async analyzeReceiptStream(stream: Readable): Promise<any> {
const poller = await this.dac.beginAnalyzeDocument("prebuilt-invoice", stream, {
onProgress: ({ status }) => {
console.log(`status: ${status}`);
},
});
const {
documents: [result] = [],
} = await poller.pollUntilDone();
const fields = result?.fields;
this.removeUnwantedFields(fields);
return fields;
}
Cree un método removeUnwantedFields para quitar los campos no deseados en Azure respuesta de Cognitive Services:
private static removeUnwantedFields(fields: any) {
for (const prop in fields) {
if (prop === 'boundingRegions' || prop === 'content' || prop === 'spans') {
delete fields[prop];
}
if (typeof fields[prop] === 'object') {
this.removeUnwantedFields(fields[prop]);
}
}
}
Por último, abra GraphProvider.ts para agregar el addDriveItem método al final de la GraphProvider clase.
public static async addDriveItem(driveId: string, parentId: any, fileName: string, receiptString: string) {
await this.graphClient.api(`/drives/${driveId}/items/${parentId}:/${fileName}:/content`).put(receiptString);
}
Ahora, reinicie la aplicación de demostración y configure la tunelización con ngrok y la suscripción de cambio delta en el contenedor de nuevo.
Si agrega o actualiza cualquier archivo (formatos admitidos: JPEG, JPG, PNG, BMP, TIFF, PDF) en este contenedor, debería ver un nuevo archivo JSON creado y que contiene los campos extraídos del archivo.