Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aprenda a construir consultas de búsqueda complejas para Buscar en SharePoint usando el lenguaje de consulta FAST (FQL). Esta referencia describe los elementos de una consulta FQL y enseña a usar las especificaciones de propiedades, las expresiones de token y los operadores en las consultas FQL.
Introducción a las subexpresiones y expresiones del lenguaje de consulta FQL en SharePoint
El lenguaje de consulta FAST (FQL) es un lenguaje potente que permite a los desarrolladores realizar búsquedas exactas y reducir el ámbito de la búsqueda a valores que pertenezcan a una propiedad administrada concreta o un índice de texto completo.
Una expresión de lenguaje de consulta puede contener subexpresiones anidadas que incluyan términos de consulta, especificaciones de propiedades y operadores, como se ve en la tabla 1.
Tabla 1. Subexpresiones en expresiones de lenguaje de consulta
| Elemento | Descripción |
|---|---|
| Expresiones de token | Uno o varios términos de consulta, frases o valores numéricos que se van a buscar en una consulta. |
| Especificación de propiedad | Una propiedad o índice de texto completo que coincide con la expresión afectada. |
| Operadores | Palabras clave que especifican operaciones booleanas (como AND, OR) u otras restricciones a los operandos (como FILTER). |
Ejemplo de consulta FQL
En el siguiente ejemplo de consulta FQL se buscan los términos "hello" y "world" en la propiedad administrada body de un elemento indizado:
body:string("hello world", mode="and")
En el ejemplo:
-
body:limita el ámbito de la consulta en la propiedad administrada de cuerpo del elemento. -
"hello world"es el operando del operador STRING, que indica los términos que se buscan. -
mode="and"indica que el operador lógico de consulta AND se aplicará a"hello world".
La longitud de las consultas del lenguaje de consulta FAST está limitado a 2.048 caracteres.
Especificación de propiedades en FQL
Una especificación de propiedad limita el ámbito de la expresión afectada a regiones determinadas del contenido indizado. Una región de este tipo se identifica por un índice de texto completo o una propiedad administrada.
Las propiedades administradas de tipo Text y YesNo se evalúan como texto. Todos los otros tipos de propiedades administradas, incluido el tipo Datetime, se evalúan como valores numéricos.
Si no incluye una especificación de propiedad para una expresión, el motor de búsqueda trata de buscar coincidencias con el índice de texto completo definido en el esquema de índices.
El nombre de la propiedad siempre debe ir antes de dos puntos (operador In) y los operadores numéricos deben incluir una especificación de propiedad.
Se puede aplicar una especificación de propiedad (el operador In) a las siguientes entidades de consulta:
Un término o una frase únicos, por ejemplo:
author:shakespeare title:"to be or not to be"Un operador, como el operador STRING en el ejemplo siguiente:
title:string("to be or not to be")En este caso, la especificación de propiedad se aplica a la expresión completa del operador.
Ejemplos
Cada una de las expresiones siguientes coincide con elementos que tienen "much" y "nothing" en la propiedad administrada title.
title:and(much, nothing)
and(title:much, title:nothing)
title:string("much nothing", mode="and")
Expresiones de token en FQL
Las expresiones de token son palabras, frases o valores numéricos que coinciden con el índice.
Una nueva expresión de token puede ser una sola palabra o una frase entre comillas dobles.
Una expresión de token numérica puede ser un valor único o una expresión de rango de valores.
Expresiones de caracteres comodín
Una expresión comodín indica un único término o frase que incluye el carácter asterisco ("*"). Asterisco implica una coincidencia de cero o más caracteres, excepto el espacio en blanco. FQL admite la búsqueda de prefijos para las propiedades administradas de texto individuales y los índices de texto completo.
Ejemplos de expresiones de caracteres comodín
La siguiente es una lista de usos válidos de expresiones de carácter comodín en FQL:
text*string("this examp*")
Expresiones de términos numéricos
Cada expresión de término numérico debe incluir una especificación de propiedad de un tipo de datos de esquema de índice compatible. En la tabla 2 se recogen los tipos de datos numéricos que se pueden usar en FQL.
Tabla 2. Tipos de datos numéricos que se pueden usar en FQL.
| Tipo FQL | Tipos de esquemas de índice compatibles | Descripción |
|---|---|---|
| Int | Integer | Entero de 64 bits. |
| Float | Double | Punto flotante de 64 bits (doble precisión). |
| Decimal | Decimal | Decimal de 128 bits. |
| Datetime | Datetime | Valor de fecha y hora. La compatibilidad de fecha y hora en FQL permite las mismas operaciones numéricas en los valores de fecha y hora que en otros valores numéricos. |
Expresiones de consulta de fecha y hora
FQL dispone del tipo de dato datetime para la fecha y la hora.
En las consultas se admiten los siguientes formatos de datetime compatibles con la norma ISO 8601:
- AAAA-MM-DD
- AAAA-MM-DDThh:mm:ss
- AAAA-MM-DDThh:mm:ssZ
- AAAA-MM-DDThh:mm:ssfrZ
En estos formatos de datetime:
AAAA especifica un año de cuatro dígitos.
Nota:
Solo se admiten años de cuatro dígitos.
MM especifica un mes de dos dígitos. Por ejemplo, 01 = enero.
DD especifica un día del mes de dos dígitos (de 01 a 31).
T especifica la letra "T".
hh especifica una hora de dos dígitos (de 00 a 23). No se permite la indicación a.m./p.m.
mm especifica un minuto de dos dígitos (de 00 a 59).
ss especifica a un segundo de dos dígitos (de 00 a 59).
fr especifica una fracción opcional de segundos, ss; entre 1 y 7 dígitos que siguen a . después de los segundos. Por ejemplo, 2012-09-27T11:57:34.1234567.
Todos los valores de fecha y hora deben especificarse según el formato UTC (hora universal coordinada), también conocido como zona horaria GMT (hora del meridiano de Greenwich). El identificador de zona horaria UTC (un carácter final "Z") es opcional.
Palabras reservadas, caracteres especiales y escape
Las siguientes son palabras reservadas en FQL.
and, or, any, andnot, count, decimal, rank, near, onear, int, in32, int64, float, double, datetime, max, min, range, phrase, scope, filter, not, string, starts-with, ends-with, equals, words, xrank.
Si quiere expresar una de estas palabras como término en una expresión de consulta, tiene que encerrarla entre comillas dobles, tal como se ve en los ejemplos siguientes:
or("any", "and", "xrank")string("any and xrank", mode="OR")phrase(this, is, a, "phrase")
Sugerencia
Las palabras y los caracteres reservados no distinguen mayúsculas de minúsculas, pero se recomienda usar caracteres en minúscula por cuestiones de compatibilidad futura.
FQL no siempre necesita que las cadenas se escriban entre comillas dobles. Por ejemplo, and(cat, dog) es un FQL válido aunque cat y dog no se encuentren entre comillas dobles. Sin embargo, se recomienda usar comillas dobles para evitar conflictos con las palabras reservadas.
Los términos de consulta se ajustan según el token de la configuración regional. El proceso de ajuste por token quita algunos caracteres especiales. Como se quitan estos caracteres, las siguientes expresiones FQL son equivalentes.
and("[king]", "<queen>")
and("king", "queen")
Cuando una consulta incluya términos de la entrada de usuario o de otra aplicación, use el operador string("<query terms>", mode="AND|OR|PHRASE") para evitar conflictos con las palabras reservadas en el lenguaje de consulta. También debe quitar las comillas dobles que pueda haber en la consulta introducida por el usuario.
Operadores de FQL
Los operadores del lenguaje de consulta FAST (FQL) son palabras clave que especifican operaciones booleanas u otras restricciones a los operandos. La sintaxis de operador FQL es la siguiente:
[property-spec:]operator(operand [,operand]* [, parameter="value"]*)
En la sintaxis:
- property-spec es una especificación de propiedad opcional seguida por el operador "in".
- operator es una palabra clave que especifica una operación que hay que realizar.
- operand es una expresión de término u otro operador.
- parameter es el nombre de un valor que cambia el comportamiento del operador.
- value es el valor que se usa para el nombre del parámetro.
Los nombres de los operadores y de los parámetros, así como los valores de texto de los parámetros, distinguen mayúsculas y minúsculas. Los espacios en blanco se permiten en el cuerpo del operador, pero se omiten a menos que estén entre comillas dobles. La longitud de las consultas del lenguaje de consulta FAST está limitado a 2.048 caracteres.
La tabla 3 recoge los tipos de operadores admitidos por FQL.
Tabla 3. Tipos de operadores admitidos por FQL
| Tipo | Descripción | Operadores |
|---|---|---|
| String | Le permite especificar operaciones de consulta en una cadena de términos. Este es el operador que más se usa en los términos de texto. | STRING |
| Booleano | Le permite combinar términos y subexpresiones en una consulta. | AND, OR, ANY, ANDNOT, NOT, COUNT, COUNT |
| Proximidad | Le permite especificar la proximidad de los términos de consulta en una secuencia coincidente de texto. | NEAR, ONEAR, PHRASE, STARTS-WITH, ENDS-WITH, EQUALS |
| Numérico | Le permite especificar condiciones numéricas en la consulta. | RANGE, INT, FLOAT, DATETIME, DECIMAL |
| Relevancia | Le permite ver el impacto de la evaluación de relevancia de una consulta. | XRANK y FILTER |
La tabla 4 contiene una lista de los operadores admitidos.
Tabla 4. Operadores FQL compatibles
| Operador | Descripción | Tipo |
|---|---|---|
| AND | Solo devuelve elementos que coinciden con todos los operandos AND. | Booleano |
| ANDNOT | Solo devuelve elementos que coinciden con el primer operando y que no coinciden con los siguientes. | Booleano |
| ANY | Se parece al operador OR, pero la clasificación dinámica (la puntuación de relevancia del conjunto de resultados) no se ve afectada ni por el número de operandos que coinciden ni por la distancia que hay entre los términos del elemento. | Booleano |
| COUNT | Le permite especificar el número de repeticiones del término de consulta que un elemento debe incluir para que se devuelva como resultado. El operando puede ser un solo término de consulta, una frase o un término de consulta de carácter comodín. | Booleano |
| DATETIME | Ofrece una escritura explícita de valores numéricos. La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino. | Numérico |
| DECIMAL | Ofrece una escritura explícita de valores numéricos. La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino. | Numérico |
| ENDS-WITH | Especifica que una palabra o frase deben aparecer al final de una propiedad administrada. | Proximidad |
| EQUALS | Especifica que una palabra, un término de frase o una frase deben proporcionar una coincidencia de token exacta con la propiedad administrada. | Proximidad |
| FILTER | Se usa para consultar metadatos u otros datos estructurados. | Relevancia |
| FLOAT | Ofrece una escritura explícita de valores numéricos. La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino. | Numérico |
| INT | Ofrece una escritura explícita de valores numéricos. La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino. | Numérico |
| NEAR | Restringe el conjunto de resultados a los elementos que tienen N términos a cierta distancia unos de otros. |
Proximidad |
| NOT | Solo devuelve elementos que excluyen el operando. | Booleano |
| ONEAR | La variante ordenada de NEAR; requiere una coincidencia ordenada de los términos. El operador ONEAR se puede usar para restringir el conjunto de resultados a los elementos que tienen N términos a una distancia determinada de Devuelve solo los elementos que no coinciden con el operando. El operando puede ser cualquier expresión FQL válida. |
Proximidad |
| OR | Solo devuelve los elementos que coinciden, al menos, con uno de los operandos OR. Los elementos que coinciden tienen una clasificación dinámica más alta (puntuación de relevancia en el conjunto de resultados) si coinciden más operandos OR. | Booleano |
| PHRASE | Solo devuelve elementos que coinciden con una cadena exacta de tokens. | Proximidad |
| RANGE | Permite expresiones coincidentes de rango. El operador RANGE se usa para propiedades administradas numéricas y de fecha y hora. | Numérico |
| STARTS-WITH | Especifica que una palabra o frase deben aparecer al principio de una propiedad administrada. | Proximidad |
| STRING | Define una condición booleana coincidente para una cadena de texto. | String |
| XRANK | Le permite aumentar la clasificación dinámica de elementos basándose en las repeticiones de ciertos términos sin cambiar los elementos que coinciden con la consulta. Una expresión XRANK contiene un componente que se debe ofrecer como resultado y uno o varios componentes que contribuyen solo a la clasificación dinámica. | Relevancia |
Nota:
En SharePoint, el operador RANK está en desuso y ya no tiene efecto. Ahora debe usar XRANK.
AND
Solo devuelve elementos que coinciden con todos los operandos AND. Los operandos pueden ser un solo término o cualquier subexpresión FQL válida.
Sintaxis
and(operand, operand [, operand]*)
Parámetros
No procede.
Ejemplos
La siguiente expresión ofrece como resultados los elementos cuyo índice de texto completo predeterminado contiene "cat", "dog" y "fox".
and(cat, dog, fox)
ANDNOT
Solo devuelve elementos que coinciden con el primer operando y que no coinciden con los siguientes. Los operandos pueden ser un solo término o cualquier subexpresión FQL válida.
Sintaxis
andnot(operand, operand [,operand]*)
Parámetros
No procede.
Ejemplos
Ejemplo 1. La siguiente expresión ofrece como resultados los elementos cuyo índice de texto completo predeterminado contiene "cat" pero no "dog".
andnot(cat, dog)
Ejemplo 2. La siguiente expresión coincide con elementos para los que el índice de texto completo predeterminado contiene "dog" pero no contiene "beagle" ni "chihuahua".
andnot(dog, beagle, chihuahua)
ANY
Nota:
En SharePoint, el operador ANY está en desuso. Use el operador OR.
Se parece al operador OR, pero la clasificación dinámica (la puntuación de relevancia del conjunto de resultados) no se ve afectada ni por el número de operandos que coinciden ni por la distancia que hay entre los términos del elemento. Los operandos pueden ser un solo término o cualquier subexpresión FQL válida.
El componente de clasificación dinámica de esta parte de la consulta se basa en el mejor término coincidente de la expresión ANY.
Nota:
La diferencia de OR solo se relaciona con la clasificación dentro del conjunto de resultados. El mismo conjunto total de elementos coincidirá con la consulta.
Sintaxis
any(operand, operand [,operand]*)
Parámetros
No procede.
Ejemplos
La siguiente expresión ofrece como resultados los elementos cuyo índice de texto completo predeterminado contiene "cat" o "dog".
Si el índice contiene "cat" y "dog", pero "cat" se considera una coincidencia mejor, la clasificación dinámica del elemento se basará en "cat" sin tener en cuanto el término "dog".
any(cat, dog)
COUNT
Especifica el número de repeticiones del término de consulta que un elemento debe incluir para que el elemento se devuelva como resultado. El operando puede ser un solo término de consulta, una frase o un término de consulta de carácter comodín.
Sintaxis
property-spec:count(operand [,from=<numeric value>, to=<numeric value>])
Parámetros
| Parámetro | Valor | Descripción |
|---|---|---|
| From | <numeric_value> | El valor del parámetro from debe ser un entero positivo que especifique el número mínimo de veces que el operando especificado se debe mostrar como resultado. Si el parámetro from no se especifica, no existirá un límite inferior. |
| to | <numeric_value> | El valor del parámetro to debe ser un entero positivo que especifique el número máximo y no inclusivo de veces que el operando especificado se debe mostrar como resultado. Por ejemplo, un valor to de 11 indica 10 o menos veces. Si el parámetro to no se especifica, no existirá un límite superior. |
Ejemplos
Ejemplo 1. La siguiente expresión ofrece como resultado al menos 5 repeticiones de la palabra "cat".
count(cat, from=5)
Ejemplo 2. La siguiente expresión ofrece como resultado al menos 5 repeticiones de la palabra "cat", pero no 10 ni más de 10.
count(cat, from=5, to=10)
Ejemplo 3. Todas las expresiones siguientes ofrecen como resultado al menos 3 repeticiones de una palabra, que puede ser "cat" o "dog".
count(or(cat, dog), from=3)count(string("cat dog", mode="or"), from=3)
La tabla siguiente contiene ejemplos de valores de cadena de propiedades administradas; se indica si coinciden con las dos expresiones del ejemplo 3.
| ¿Coincide? | Texto |
|---|---|
| Sí | My cat likes my dog, but my dog hates my cat. |
| No | My bird likes my newt, but my dog hates my cat. |
DATETIME
Ofrece una escritura explícita de valores numéricos de fecha y hora. El operando es una cadena de fecha y hora cuyo formato se basa en la sintaxis especificada en las expresiones de token en FQL.
La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino.
Sintaxis
datetime(<date/time string>)
Parámetros
No procede.
DECIMAL
Ofrece una escritura explícita de valores decimales. El operando es un valor decimal según la sintaxis especificada en expresiones de token en FQL.
La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino.
Sintaxis
decimal(<decimal point value>)
Parámetros
No procede.
ENDS-WITH
Especifica que una palabra o frase deben aparecer al final de una propiedad administrada (coincidencia de límites).
La coincidencia de límites no se admite en las propiedades administradas numéricas. Estas propiedades siempre estarán sujetas a una coincidencia exacta o de rango de valores.
Algunas aplicaciones pueden necesitar que pueda realizar una coincidencia exacta de una propiedad administrada. Por ejemplo, puede tratarse de una propiedad administrada product name, donde el nombre completo de un producto es una subcadena de otro nombre de producto.
Sintaxis
ends-with(<term or phrase>)
Parámetros
No procede.
Ejemplos
La expresión siguiente ofrece elementos con los valores "Mr Adam Jones" y "Adam Jones" en la propiedad administrada "author". No coincidirá con elementos con el valor "Adam Jones Sr.".
author:ends-with("adam jones")
Comentarios
La coincidencia de límites se puede aplicar a todo el texto de la propiedad administrada o a cadenas individuales dentro de una propiedad administrada que contenga una lista de valores de cadena, por ejemplo, una lista de nombres. En este caso, convendría hacer coincidir el contenido exacto de cada cadena y evitar la coincidencia de consultas de un límite de cadena a otro.
Para aplicar las consultas de coincidencia de límites, hay que configurar la propiedad administrada correspondiente en el esquema de índice.
Al habilitar la función Coincidencia de límite en la propiedad administrada, puede hacer lo siguiente:
- Usar consultas de coincidencia de límites explícitas.
- Evitar que las frases coincidan de un límite de cadena a otro. Para las propiedades administradas que contienen varias cadenas, esta función asegura que una cadena no coincida con palabras antes o después de una indicación de límite.
EQUALS
Especifica que una palabra o frase debe ofrecer una coincidencia de token exacta con la propiedad administrada.
Sintaxis
equals(<term or phrase>)
Parámetros
No procede.
Ejemplos
El ejemplo siguiente ofrece elementos con los valores "Adam Jones" en la propiedad administrada "author". No coincidirá con elementos con los valores "Adam Jones Sr." o "Sr. Adam Jones".
author:equals("adam jones")
Comentarios
Vea también ENDS-WITH.
FILTER
Se usa para consultar metadatos u otros datos estructurados.
Usar el operador FILTER implica automáticamente lo siguiente para la consulta especificada:
La lingüística se establece en lingüística="OFF".
La clasificación de deshabilita.
No se usará ningún resaltado de consultas en el resumen de resultados resaltados del resultado de la consulta.
Sugerencia: Si usa el operador STRING dentro de una expresión FILTER, la lingüística estará deshabilitada de forma predeterminada. Puede habilitar el procesamiento de lingüística en cada expresión STRING dentro de FILTER usando el operando
linguistics="ON".
Sintaxis
filter(<any valid FQL operator expression>)
Parámetros
No procede.
Ejemplos
La expresión siguiente ofrece como resultados los elementos que tienen una propiedad administrada Title que contiene "sonata" y una propiedad administrada Doctype que contiene solo el token "audio". No se realiza ninguna coincidencia lingüística en "audio". Como el token FILTER se usará para mostrar "audio", ese texto no se resaltará en el resumen de resultados resaltados.
and(title:sonata, filter(doctype:equals("audio")))
Comentarios
Si tiene que restringir la consulta para que muestre al menos uno de un conjunto amplio de valores enteros en una propiedad numérica, puede expresar esto de dos formas equivalentes funcionalmente:
and(string("hello world"), filter(property-spec:or(1, 20, 453, ... , 3473)))and(string("hello world"), filter(property-spec:int("1 20 453 ... 3473", mode="or")))
En el segundo ejemplo se emplea el operador INT usando una cadena con el conjunto de valores numéricos entre comillas. Esto ofrece un rendimiento de la consulta bastante mejor al filtrar con un amplio conjunto de valores numéricos.
Si tiene que filtrar un conjunto grande de valores, puede usar valores numéricos en lugar de valores de cadena y expresar las consultas usando la sintaxis optimizada.
FLOAT
Ofrece una escritura explícita de valores numéricos de punto flotante. El operando es un valor de punto flotante según la sintaxis especificada en las expresiones de token en FQL.
La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino.
Sintaxis
float(<floating point value>)
Parámetros
No procede.
INT
Ofrece una escritura explícita de valores enteros. El operando es un valor entero según la sintaxis especificada en las expresiones de token en FQL.
La conversión de tipo explícito es opcional y no suele ser necesaria. El tipo del término de consulta se detecta según el tipo de la propiedad numérica administrada de destino.
El operador INT también se puede usar para expresar un conjunto de valores enteros como argumentos de los operadores booleanos FQL. Esto supone un modo muy eficiente de ofrecer un conjunto de valores enteros en una consulta, ya que los valores que se pasan usando el operador INT no los analiza el analizar de consultas FQL, sino que pasan directamente al componente de coincidencias de consulta.
Sintaxis
int(<integer value>)
int("value, value, ??? , value")
La primera sintaxis especifica un solo entero. La segunda sintaxis especifica una lista de valores enteros separados por comas y encerrados entre comillas dobles.
Parámetros
No procede.
Ejemplos
Si tiene que restringir la consulta para que muestre al menos uno de un conjunto amplio de valores enteros en una propiedad numérica, puede expresar esto usando el operador INT:
and(string("hello world"), filter(id:int("1 20 49 124 453 985 3473", mode="or")))
NEAR
Restringe el conjunto de resultados a los elementos que tienen N términos a cierta distancia unos de otros.
El orden de los términos de consulta no es importante para la búsqueda de resultados, solo importa la distancia.
Puede combinar todos los términos que quiera con los operadores NEAR.
Los operandos NEAR pueden ser términos únicos, frases o las expresiones de operador booleano OR o ANY. Se pueden usar caracteres comodín.
Si hay varios operandos del operador NEAR que coinciden con el mismo token indizado, se considera que están cerca.
Sintaxis
near(arg, arg [, arg]* [, N=<numeric value>])
Parámetros
| Parámetro | Valor | Descripción |
|---|---|---|
| N | <numeric_value> | Especifica el número máximo de palabras que pueden aparecer entre los términos (proximidad explícita). Si NEAR incluye más de dos operandos, el número máximo de palabras permitidas entre los términos ( N) se cuenta dentro de la expresión completa. Valor predeterminado: 4 |
Ejemplos
Ejemplo 1. La expresión siguiente muestra como resultados las cadenas que contienen "cat" y "dog" si no están separadas por más de cuatro tokens indizados (valor predeterminado).
near(cat, dog)
Ejemplo 2. La expresión siguiente muestra como resultados las cadenas que contienen "cat", "dog", "fox" y "wolf" si no están separadas por más de cuatro tokens indizados.
near(cat, dog, fox, wolf)
La tabla siguiente contiene ejemplos de valores de cadena de propiedades administradas; se indica si coinciden con la expresión anterior del ejemplo 2.
| ¿Coincide? | Texto |
|---|---|
| Sí | La imagen muestra un gato, un perro, un zorro y un lobo. |
| Sí (con lematización) | Los perros, los zorros y los lobos son cánidos, pero los gatos son felinos. |
| No | La imagen muestra un gato con un perro, un zorro y un lobo. |
La expresión siguiente muestra como resultados todas las cadenas de la tabla anterior.
near(cat, dog, fox, wolf, N=5)
Comentarios
Consideraciones sobre la distancia entre términos de NEAR/ONEAR
N indica el número máximo de palabras que pueden aparecer entre los términos de consulta dentro del segmento coincidente del elemento. Si NEAR u ONEAR incluyen más de dos operandos, el número máximo de palabras permitidas entre los términos de consulta ( N) se cuenta dentro del segmento del elemento que coincide con todos los términos de NEAR u ONEAR.
NEAR y ONEAR funcionan en texto ajustado por token. Esto significa que caracteres especiales como coma (" , "), punto (" . "), dos puntos (" : "), o punto y coma (" ; ") se tratarán como espacios en blanco. El término "distancia" se refiere a los tokens que hay en el texto indizado.
Si usa ONEAR o NEAR con operandos iguales, el operador funcionará así:
near(a, a, n=x)
Esta consulta siempre devolverá true si aparece al menos una instancia de " a" dentro del contexto. Esto también significa que NEAR no se puede usar como operador COUNT. Para más información sobre cómo contar repeticiones de términos, vea el operador COUNT.
NEAR aplicado a frases también ofrecerá como resultado frases superpuestas en el texto.
Si un token del segmento coincidente coincide con más de un operando de la expresión NEAR u ONEAR, la consulta puede coincidir aunque el número de tokens no coincidentes que hay en el segmento coincidente supere el valor de ' N' en la expresión del operador NEAR u ONEAR. Por ejemplo, una superposición puede ser frases superpuestas. Si el número de coincidencias de superposición de token es ' O', la consulta coincidirá si no aparecen más de ' N+O' tokens no coincidentes dentro del segmento coincidente del elemento.
NEAR u ONEAR con NOT
El operador NOT no se puede usar dentro del operador NEAR u ONEAR. La siguiente sintaxis de FQL es incorrecta:
near(audi,not(bmw),n=2)
NOT
Solo devuelve los elementos que no coinciden con el operando. Este puede ser cualquier expresión FQL válida.
Sintaxis
not(operand)
Parámetros
No procede.
ONEAR
La variante ordenada de NEAR; requiere una coincidencia ordenada de los términos. El operador ONEAR se puede usar para restringir el conjunto de resultados a los elementos que tienen N términos a cierta distancia unos de otros.
Sintaxis
onear(arg, arg [, arg]* [, N=<numeric value>])
Parámetros
| Parámetro | Valor | Descripción |
|---|---|---|
| N | <numeric_value> | Especifica el número máximo de palabras que pueden aparecer entre los términos (proximidad explícita). Si ONEAR incluye más de dos operandos, el número máximo de palabras permitidas entre los términos ( N) se cuenta dentro de la expresión completa. Valor predeterminado: 4 |
Ejemplos
Ejemplo 1. La expresión siguiente muestra como resultados todas las repeticiones de las palabras "cat", "dog", "fox" y "wolf" que aparecen en orden si no están separadas por más de cuatro tokens indizados.
onear(cat, dog, fox, wolf)
La tabla siguiente contiene ejemplos de valores de cadena de propiedades administradas; se indica si coinciden con la expresión anterior.
| ¿Coincide? | Texto |
|---|---|
| Sí | The picture shows a cat, a dog, a fox, and a wolf. |
| No | Dogs, foxes, and wolves are canines, but cats are felines. |
| No | La imagen muestra un gato con un perro, un zorro y un lobo. |
Ejemplo 2. La expresión siguiente ofrece como resultados (con lematización) el texto de la segunda fila de la tabla anterior.
onear(dog, fox, wolf, cat, N=5)
Ejemplo 3. La siguiente expresión coincide con el texto de la primera y tercera fila de la tabla anterior.
onear(cat, dog, fox, wolf, N=5)
Comentarios
Vea también NEAR.
OR
Solo devuelve los elementos que coinciden, al menos, con uno de los operandos OR. Los elementos que coinciden tienen una clasificación dinámica más alta (puntuación de relevancia en el conjunto de resultados) si coinciden más operandos OR. Los operandos pueden ser un solo término o cualquier subexpresión FQL válida.
Sintaxis
or(operand, operand [,operand]*)
Parámetros
No procede.
Ejemplos
La siguiente expresión ofrece como resultados todos los elementos cuyo índice de texto completo predeterminado contiene "cat" o "dog". Si el índice de texto completo predeterminado de un elemento contiene "cat" y "dog", coincidirá y tendrá un mayor rango dinámico que el que tendría si contuviera sólo uno de los tokens.
or(cat, dog)
PHRASE
Busca una cadena exacta de tokens.
Los operandos PHRASE pueden ser términos únicos. Se pueden usar caracteres comodín.
Sintaxis
phrase(term [, term]*)
Parámetros
No procede.
Comentarios
Vea también STRING.
RANGE
Use el operador RANGE para propiedades administradas numéricas y de fecha y hora. El operador permite usar expresiones de coincidencia de rango.
Sintaxis
range(start, stop [,from="GE"|"GT"] [,to="LE"|"LT"])
Parámetros
| Parámetro | Valor | Valor | Descripción |
|---|---|---|---|
| start | _<numeric_value>\ | <date/time_value>_ | Valor de inicio del intervalo. Para especificar que el rango no tiene límite inferior, use la palabra reservada min. |
| stop | _<numeric_value>\ | <date/time_value>_ | Valor final del intervalo. Para especificar que el rango no tiene límite superior, use la palabra reservada max. |
| from | **GE\ | GT** | Parámetro opcional que indica el intervalo de inicio de apertura o cierre. Valores válidos:
|
| to | **LE\ | LT** | Parámetro opcional que indica el intervalo de finalización de apertura o cierre. Valores válidos:
|
Ejemplos
La expresión siguiente ofrece resultados que coinciden con una propiedad de descripción que empieza por la frase "big accomplishments" y que aparece en elementos que tienen 10.000 bytes como mínimo.
and(size:range(10000, max), description:starts-with("big accomplishments"))
STARTS-WITH
Especifica una palabra o frase que deben aparecer al principio de una propiedad administrada.
Sintaxis
starts-with(<term or phrase>)
Parámetros
No procede.
Ejemplos
La expresión siguiente ofrece elementos con los valores "Adam Jones sr" y "Adam Jones" en la propiedad administrada author. No mostrará resultados con el valor "Mr Adam Jones".
author:starts-with("adam jones")
Comentarios
Para obtener notas adicionales sobre la coincidencia de límite, vea ENDS-WITH.
STRING
Define una condición booleana coincidente para una cadena de texto.
El operando es una cadena de texto (uno o varios términos) que hay que encontrar. La cadena está seguida por cero o más parámetros.
El operador STRING también se puede usar como conversión de tipo. La consulta string("24.5"), por ejemplo, tratará el valor numérico "24.5" como cadena de texto.
Sintaxis
string("<text string>"
[, mode=<mode>]
[, n=<near>]
[, weight=<n>]
[, linguistics=<on|off>]
[, wildcard=<on|off>])
Parámetros
| Parámetro | Valor | Descripción | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mode | <mode> | El parámetro mode especifica cómo evaluar el valor <text string>. En la siguiente lista se muestran los valores válidos.
"PHRASE" - phrase(term [,term]*)
|
||||||||||||||
| n | <numeric_value> | Este parámetro indica la distancia máxima entre términos para el modo= "NEAR" o el modo= "ONEAR". Las siguientes expresiones son equivalentes: string("hello world", mode="NEAR", n=5)near(hello, world, n=5) Valor predeterminado: 4 |
||||||||||||||
| weight | <numeric_value> | Este parámetro es un valor numérico positivo que indica el peso del término para la clasificación dinámica. Un valor pequeño indica que un término debe contribuir menos a la clasificación. Un valor mayor indica que debe contribuir más a la clasificación. Un valor de cero en el parámetro del peso especifica que un término no debe afectar a la clasificación dinámica. El parámetro weight se aplica a todos los términos de la expresión STRING. SUGERENCIA: El parámetro del peso afecta solo a las consultas de índice de texto completo. Valor predeterminado: 100. | ||||||||||||||
| linguistics | on|off | Habilita o deshabilita todas las características lingüísticas de la cadena (lematización, sinónimos, comprobación de la ortografía) si están habilitadas para la consulta. Puede usar este parámetro para desactivar el procesamiento lingüístico en un término o una cadena concretos y que estos sigan contribuyendo a la clasificación. Valor predeterminado: "ON" | ||||||||||||||
| wildcard | on|off | Este parámetro controla la expansión de caracteres comodín de los términos dentro de <text string>. Esta opción invalida las opciones de caracteres comodín que hay en los parámetros de consulta y permite que se habiliten o deshabiliten los caracteres comodín en ciertas partes de la consulta. Los valores válidos son los siguientes:
|
Nota:
En SharePoint, los parámetros minexpansion, maxexpansion y annotation_class del operador STRING están obsoletos.
Ejemplos
Ejemplo 1. Como el modo de cadena predeterminado es " PHRASE ", todas las expresiones siguientes devuelven los mismos resultados.
"what light through yonder window breaks"string("what light through yonder window breaks")string("what light through yonder window breaks", mode="phrase")phrase(what, light, through, yonder, window, breaks)
Ejemplo 2. La siguiente expresión de token de cadena y la expresión del operador AND devuelven los mismos resultados.
string("cat dog fox", mode="and")and(cat, dog, fox)
Ejemplo 3. La siguiente expresión de token de cadena y la expresión del operador OR devuelven los mismos resultados.
string("coyote saguaro", mode="or")or(coyote, saguaro)
Ejemplo 4. La siguiente expresión de token de cadena y la expresión del operador ANY devuelven los mismos resultados.
string("coyote saguaro", mode="any")any(coyote, saguaro)
Ejemplo 5. La siguiente expresión de token de cadena y la expresión del operador NEAR devuelven los mismos resultados.
string("coyote saguaro", mode="near")near(coyote, saguaro)
Ejemplo 6. La siguiente expresión de token de cadena y la expresión del operador NEAR devuelven los mismos resultados.
string("cat dog fox wolf", mode="near", N=4)near(cat, dog, fox, wolf, N=4)
Ejemplo 7. La siguiente expresión de token de cadena y la expresión del operador ONEAR devuelven los mismos resultados.
string("cat dog fox wolf", mode="onear")onear(cat, dog, fox, wolf)
Ejemplo 8. La siguiente expresión de token de cadena ofrece como resultado la palabra "nobler" con las funciones lingüísticas deshabilitadas para que no se muestren otras formas de la palabra (como "ennobling") por la lematización.
string("nobler", linguistics="off")
Ejemplo 9. La expresión siguiente ofrece como resultado elementos que contienen "cat" o "dog ", pero la expresión aumenta la clasificación dinámica de elementos que contiene "dog" más que los elementos que contienen "cat".
or(string("cat", weight="200"), string("dog", weight="500"))
Comentarios
Peso de relevancia en la clasificación dinámica
El principal efecto del parámetro weight es en las consultas OR. También puede tener algún efecto en las consultas AND. El algoritmo de rango dinámico puede implicar que diferentes términos proporcionen una contribución de rango diferente en función del lugar del elemento donde se produce la coincidencia.
La diferencia en la contribución de clasificación también se puede basar en la frecuencia del término y en la frecuencia inversa del elemento. A continuación puede ver un ejemplo:
- Consulta:
and(string("a"), string("b", weight=200)) - Esquema de índice: la propiedad administrada title tiene más peso que la propiedad administrada body.
- El elemento de índice 1 incluye el término "a" en el título y el término "b" en el cuerpo.
- El elemento de índice 2 incluye el término "a" en el cuerpo y el término "b" en el título.
En este ejemplo, el elemento 2 tiene la clasificación total más alta, ya que los elementos con mayor contribución de clasificación dinámica se incrementarán todavía más.
Sugerencia: El aumento del término relativo (positivo o negativo) se aplica al componente de clasificación dinámica de la clasificación total, pero los cálculos de clasificación del aumento de proximidad (la distancia entre palabras) no se ven afectados por la ponderación de términos. La ponderación relativa no siempre implica que se modifique la clasificación total del elemento según el porcentaje indicado. > La siguiente consulta buscará los términos "peter", "paul" o "mary", donde "peter" tendrá el doble de contribución de clasificación que los otros dos términos. >
or(peter, string("paul mary", mode="OR", weight=50))
Control de cadenas con caracteres especiales
Los caracteres especiales como la coma (","), el punto y coma (";"), los dos puntos (":"), el punto ("."), el menos ("-"), el subrayado ("_") o la barra diagonal ("/") se tratan como espacios en blanco dentro de una expresión de cadena encerrada entre comillas dobles. Esto está relacionado con el proceso de tokenización. Estos caracteres también implican una formulación implícita de los tokens separados por estos caracteres.
Las expresiones de consulta siguientes son equivalentes:
title:string("animals birds", mode="phrase")title:"animals/birds"title:string("animals/birds", mode="and")title:string("animals/birds", mode="or")
Las expresiones de consulta siguientes son equivalentes:
title:or(string("animals birds", mode="phrase"), string("animals insects", mode="phrase"))title:string("animals/birds animals/insects", mode="or")
Las expresiones de consulta siguientes son equivalentes:
body:string("help contoso com", mode="phrase")body:string("help@contoso.com")
Coincidencia de frases con ajuste por token
Puede buscar una cadena de tokens exacta usando el operador STRING con mode="phrase" o con el operador PHRASE.
Todas estas operaciones de frase implican una coincidencia de frase con tokens. Esto significa que los caracteres especiales como la coma (" , "), el punto y coma (" ; "), los dos puntos (" : "), el subrayado (" _ "), el menos (" - ") y la barra diagonal (" / ") se tratan como espacios en blanco. Esto está relacionado con el proceso de tokenización.
XRANK
Aumenta el rango dinámico de los elementos basándose en ciertas repeticiones del término en la match expression (expresión de coincidencia), sin cambiar los elementos que coinciden con la consulta. Una expresión XRANK consta de un componente con el que debe establecerse una coincidencia, la match expression, y uno o más componentes que solo contribuyen a la clasificación dinámica, la rank expression (expresión de clasificación). Al menos uno de los parámetros, excepto n, debe especificar una expresión XRANK válida.
Las Match expressions pueden ser cualquier expresión FQL válida, incluidas las expresiones XRANK anidadas. Las Rank expressions pueden ser cualquier expresión FQL válida sin expresiones XRANK. Si sus consultas FQL tienen varios operadores XRANK, el valor de la clasificación dinámica final se calcula como una suma de aumentos entre todos los operadores XRANK.
Nota:
En SharePoint Server 2010, el operador XRANK tenía dos parámetros: boost y boostall, además de la siguiente sintaxis: xrank(operand, rank-operand [, rank-operand]* [,boost=n] [,boostall=yes]). Esta sintaxis y sus parámetros están en desuso en SharePoint. Le recomendamos que use la sintaxis y los parámetros nuevos.
Sintaxis
xrank(<match expression> [, <rank-expression>]*, rank-parameter[, rank-parameter]*)
Fórmula
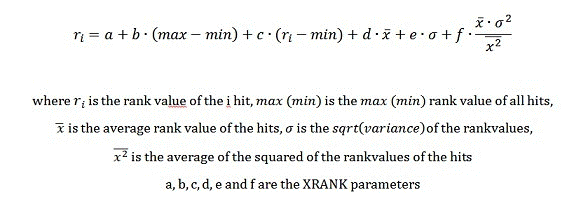
Parámetros
| Parámetro | Valor | Descripción |
|---|---|---|
| N | <integer_value> | Especifica el número de resultados de los que se deben calcular las estadísticas. Este parámetro no afecta el número de resultados al que contribuye la clasificación dinámica; es solo un medio de excluir elementos irrelevantes de los cálculos de estadísticas. Valor predeterminado: 0. Un valor cero significa todos los documentos . |
| Nb | <float_value> | El parámetro nb se refiere al aumento normalizado. Este parámetro especifica el factor que se multiplica con el producto de la puntuación promedio y de variación de los valores de clasificación del conjunto de resultados. f en la fórmula XRANK. |
Normalmente, el aumento normalizado, nb, es el único parámetro que se modifica. Este parámetro proporciona el control necesario para promover o degradar a un elemento determinado, sin tener en cuenta la desviación estándar.
Parámetros avanzados
También están disponibles los siguientes parámetros avanzados. Sin embargo, normalmente no se usan.
| Parámetro | Valor | Descripción |
|---|---|---|
| cb | <float_value> | El parámetro cb se refiere al aumento constante. Valor predeterminado: 0. a en la fórmula XRANK. |
| stdb | <float_value> | El parámetro stdb se refiere al aumento de desviación estándar. Valor predeterminado: 0. e en la fórmula XRANK. |
| avgb | <float_value> | El parámetro avgb se refiere al aumento promedio. Este factor se multiplica por el valor de clasificación promedio del conjunto de resultados. Valor predeterminado: 0. d en la fórmula XRANK. |
| rb | <float_value> | El parámetro rb se refiere al aumento de rango. Este factor se multiplica con el rango de valores de clasificación en el conjunto de resultados. Valor predeterminado: 0. b en la fórmula XRANK. |
| pb | <float_value> | El parámetro pb se refiere al aumento de porcentaje. Este factor se multiplica con la propia clasificación del elemento en comparación con el valor mínimo del corpus. Valor predeterminado: 0. c en la fórmula XRANK. |
Ejemplos
Ejemplo 1. La siguiente expresión ofrece como resultados los elementos cuyo índice de texto completo predeterminado contiene "cat" o "dog". La expresión incrementa la clasificación dinámica de aquellos elementos con un incremento constante de 100 para elementos que también contienen "thoroughbred".
xrank(or(cat, dog), thoroughbred, cb=100)
Ejemplo 2. La siguiente expresión ofrece como resultados los elementos cuyo índice de texto completo predeterminado contiene "cat" o "dog". La expresión incrementa la clasificación dinámica de aquellos elementos con un incremento normalizado de 1,5 para elementos que también contienen "thoroughbred".
xrank(or(cat, dog), thoroughbred, nb=1.5)
Ejemplo 3. La siguiente expresión ofrece como resultados los elementos cuyo índice de texto completo predeterminado contiene "cat" o "dog". La expresión incrementa la clasificación dinámica de aquellos elementos con un incremento constante de 100 y un incremento normalizado de 1,5 para elementos que también contienen "thoroughbred".
xrank(or(cat, dog), thoroughbred, cb=100, nb=1.5)
Ejemplo 4. La siguiente expresión ofrece como resultados todos los elementos que contienen el término "animals" y aumenta la clasificación dinámica de la siguiente manera:
La clasificación dinámica de los elementos que contienen el término "dogs" aumenta 100 puntos.
La clasificación dinámica de los elementos que contienen el término "cats" aumenta 200 puntos.
La clasificación dinámica de los elementos que contienen tanto "dogs" como "cats" aumenta 300 puntos.
xrank(xrank(animals, dogs, cb=100), cats, cb=200)