Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Los clústeres de macrodatos de Microsoft SQL Server 2019 se retiran. La compatibilidad con clústeres de macrodatos de SQL Server 2019 finalizó a partir del 28 de febrero de 2025. Para obtener más información, consulte la entrada de blog del anuncio y las opciones de macrodatos en la plataforma de Microsoft SQL Server.
En este artículo se describe el rol de los grupos de datos de SQL Server en un clúster de macrodatos de SQL Server. En las secciones siguientes se describen la arquitectura, la funcionalidad y los escenarios de uso de un grupo de datos.
Este vídeo de 5 minutos presenta grupos de datos y muestra cómo consultar los datos de los grupos de datos:
Arquitectura de un grupo de datos
Un grupo de datos consta de una o varias instancias de grupo de datos de SQL Server que proporcionan almacenamiento persistente de SQL Server para el clúster. Permite consultas de alto rendimiento de los datos en caché sobre orígenes de datos externos y la descarga de trabajo. Los datos se ingieren en el grupo de datos mediante consultas T-SQL o desde trabajos de Spark. Con el fin de mejorar el rendimiento en conjuntos de datos grandes, los datos ingeridos se distribuyen en particiones y se almacenan entre todas las instancias de SQL Server del grupo. Los métodos de distribución admitidos son round robin y replicados. Para la optimización del acceso de lectura, se crea un índice de almacén de columnas en clúster en cada tabla de cada instancia del grupo de datos. Un grupo de datos sirve como data mart de escalado horizontal para Clústeres de macrodatos de SQL Server.
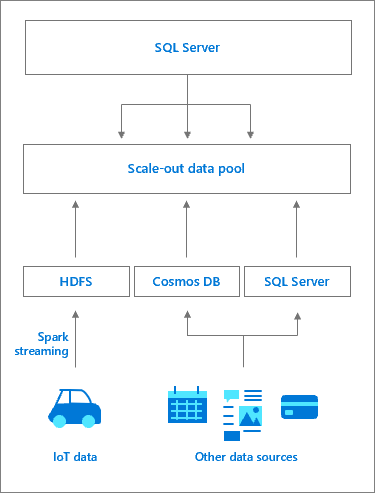
El acceso a las instancias de SQL Server del grupo de datos se administra desde la instancia maestra de SQL Server. Se crea un origen de datos externo al grupo de datos, junto con las tablas externas de PolyBase para almacenar la memoria caché de datos. En segundo plano, el controlador crea una base de datos en el grupo de datos con tablas que coinciden con las tablas externas. Desde la instancia maestra de SQL Server, el flujo de trabajo es transparente: el controlador redirige las solicitudes de tablas externas específicas a las instancias de SQL Server del grupo de datos (quizás mediante el grupo de proceso), ejecuta las consultas y devuelve el conjunto de resultados. Los datos del grupo de datos solo se pueden ingerir o consultar y no se pueden modificar. Por lo tanto, cualquier actualización de los datos requeriría una eliminación de la tabla, seguida de una nueva creación de la tabla y el rellenado de datos subsiguiente.
Escenarios del grupo de datos
La elaboración de informes es un escenario común del grupo de datos. Por ejemplo, se podría descargar en el grupo de datos una consulta compleja que combina varios orígenes de datos de PolyBase que se usan para un informe semanal. Los datos en caché proporcionan un proceso local rápido y eliminan la necesidad de volver a los conjuntos de datos originales. Del mismo modo, los datos de paneles que requieren una actualización periódica se pueden almacenar en caché en el grupo de datos para la elaboración de informes optimizada. La exploración repetitiva del aprendizaje automático también puede aprovechar las ventajas del almacenamiento en caché de conjuntos de datos en el grupo de datos.
Next steps
Para obtener más información sobre Clústeres de macrodatos de SQL Server, vea los recursos siguientes: