Presentación del bloque de almacenamiento en Clústeres de macrodatos de SQL Server
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
En este artículo se describe el papel del grupo de almacenamiento de SQL Server en un clúster de macrodatos de SQL Server. En las secciones siguientes se describen la arquitectura y la funcionalidad de un bloque de almacenamiento.
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
Arquitectura del bloque de almacenamiento
El bloque de almacenamiento es el clúster de HDFS (Hadoop) local en un clúster de macrodatos de SQL Server. Proporciona almacenamiento persistente para datos no estructurados y semiestructurados. Los archivos de datos, como texto delimitado o Parquet, se pueden almacenar en el bloque de almacenamiento. Para conservar el almacenamiento, cada pod del grupo tiene un volumen persistente asociado. Los archivos del grupo de almacenamiento son accesibles a través de PolyBase mediante SQL Server o directamente con una puerta de enlace de Apache Knox.
Una configuración de HDFS clásica se compone de un conjunto de equipos de hardware estándar con almacenamiento asociado. Los datos se distribuyen en bloques por los nodos para la tolerancia a errores y aprovechan el procesamiento paralelo. Uno de los nodos del clúster funciona como nodo de nombre y contiene la información de metadatos sobre los archivos ubicados en los nodos de datos.
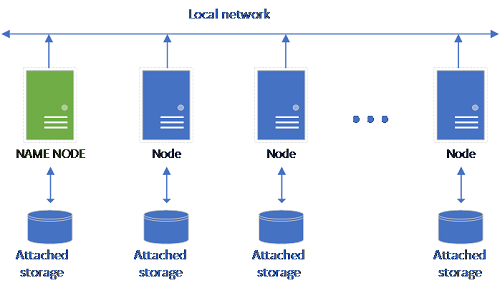
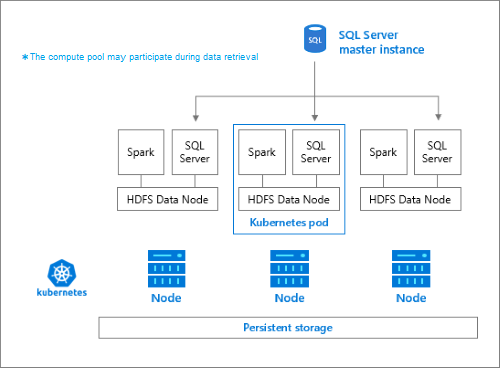
El bloque de almacenamiento está formado por nodos de almacenamiento que son miembros de un clúster de HDFS. Ejecuta uno o varios pods de Kubernetes, y cada pod hospeda los contenedores siguientes:
- Un contenedor de Hadoop vinculado a un volumen persistente (almacenamiento). Todos los contenedores de este tipo forman el clúster de Hadoop. Dentro del contenedor de Hadoop hay un proceso de administrador de nodos de YARN que puede crear procesos de trabajo de Apache Spark bajo petición. El nodo principal de Spark hospeda el metastore de Hive, el historial de Spark y los contenedores de historial de trabajos de YARN.
- Una instancia de SQL Server para leer datos de HDFS mediante la tecnología OpenRowSet.
collectdpara recopilar datos de métricas.fluentbitpara recopilar datos de registro.
Responsabilidades
Los nodos de almacenamiento se encargan de varios aspectos:
- Ingesta de datos a través de Apache Spark.
- Almacenamiento de datos en HDFS (formato de texto delimitado y Parquet). HDFS también proporciona persistencia de datos, ya que los datos de HDFS se reparten por todos los nodos de almacenamiento de BDC de SQL.
- Acceso a datos a través de los puntos de conexión de HDFS y SQL Server.
Acceso a datos
Estos son los métodos principales para acceder a los datos del bloque de almacenamiento:
- Trabajos de Spark.
- Uso de tablas externas de SQL Server para permitir la consulta de los datos mediante nodos de proceso de PolyBase y las instancias de SQL Server que se ejecutan en los nodos HDFS.
También puede interactuar con HDFS mediante:
- Azure Data Studio.
- CLI de datos de Azure (
azdata). - kubectl para emitir comandos al contenedor de Hadoop.
- Puerta de enlace HTTP de HDFS.
Pasos siguientes
Para obtener más información sobre Clústeres de macrodatos de SQL Server, vea los recursos siguientes: