Virtualización de datos CSV del bloque de almacenamiento (clústeres de macrodatos)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
La característica Clústeres de macrodatos de SQL Server puede virtualizar datos de archivos CSV en HDFS. Este proceso permite que los datos permanezcan en su ubicación original, pero se pueden consultar desde una instancia de SQL Server como cualquier otra tabla. Esta característica usa conectores de PolyBase y minimiza la necesidad de procesos ETL. Para obtener más información sobre la virtualización de datos, vea Introducción a la virtualización de datos con PolyBase.
Prerrequisitos
Selección o carga de un archivo CSV para la virtualización de datos
En Azure Data Studio (ADS), conéctese a la instancia maestra de SQL Server del clúster de macrodatos. Una vez conectado, expanda los elementos HDFS en el Explorador de objetos para buscar los archivos CSV que quiere virtualizar.
Para los fines de este tutorial, cree un directorio llamado Datos.
- Haga clic con el botón derecho en el menú contextual del directorio raíz de HDFS.
- Seleccione Nuevo directorio.
- Asigne el nombre Datos al nuevo directorio.
Cargue datos de ejemplo. Para obtener un tutorial sencillo, puede usar un archivo de datos CSV de ejemplo. En este artículo se usan los datos de la causa del retraso de las líneas aéreas del Departamento de Transporte de EE. UU. Descargue los datos sin procesar y extraiga los datos en el equipo. Asigne el nombre airline_delay_causes.csv al archivo.
Para cargar el archivo de ejemplo después de extraerlo:
- En Azure Data Studio, haga clic con el botón derecho en el directorio que ha creado.
- Seleccione Upload files (Cargar archivos).
Azure Data Studio carga los archivos en HDFS en el clúster de macrodatos.
Creación del origen de datos externo del bloque de almacenamiento en la base de datos de destino
Los orígenes de datos externos del bloque de almacenamiento ya no se crean de forma predeterminada en el clúster de macrodatos. Para poder crear la tabla externa, cree el origen de datos externo predeterminado SqlStoragePool en la base de datos de destino con la siguiente consulta de Transact-SQL. Asegúrese de cambiar primero el contexto de la consulta a la base de datos de destino.
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
Creación de la tabla externa
En ADS, haga clic con el botón en el archivo CSV y seleccione Create External Table From CSV File (Crear tabla externa a partir del archivo CSV) en el menú contextual. También puede crear tablas externas a partir de archivos CSV en un directorio de HDFS si los archivos del directorio siguen el mismo esquema. Esto permitiría la virtualización de los datos en un nivel de directorio sin necesidad de procesar archivos individuales y obtener un conjunto de resultados combinados de los datos combinados. Azure Data Studio le guía por los pasos necesarios para crear la tabla externa.
Especifique la base de datos, el origen de datos, un nombre de tabla, el esquema y el nombre del formato de archivo externo de la tabla.
Seleccione Next (Siguiente).
Vista previa de los datos
Azure Data Studio ofrece una vista previa de los datos importados.
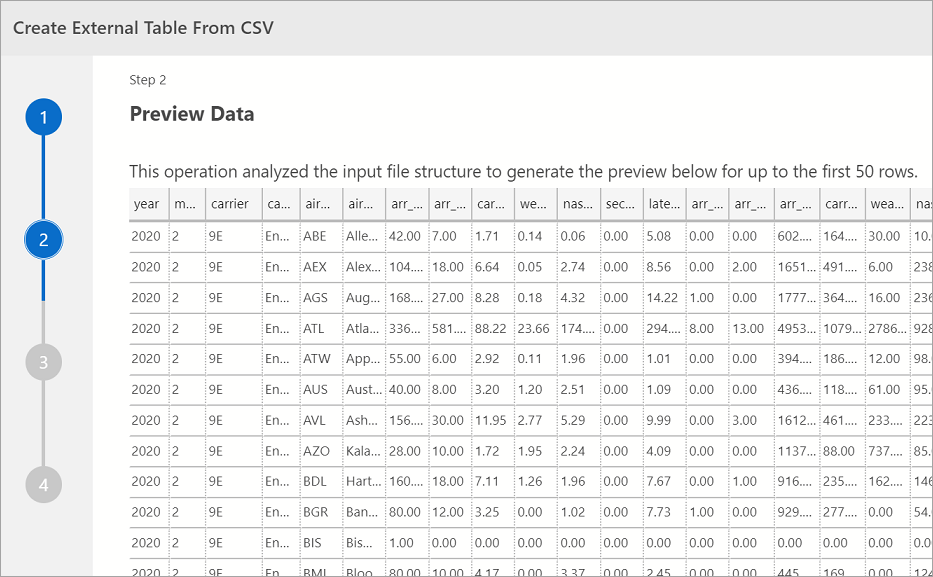
Cuando haya terminado de consultar la vista previa, seleccione Siguiente para continuar
Modificación de columnas
En la ventana siguiente, puede modificar las columnas de la tabla externa que quiere crear. Puede modificar el nombre de columna, cambiar el tipo de datos y permitir filas que admitan valores NULL.
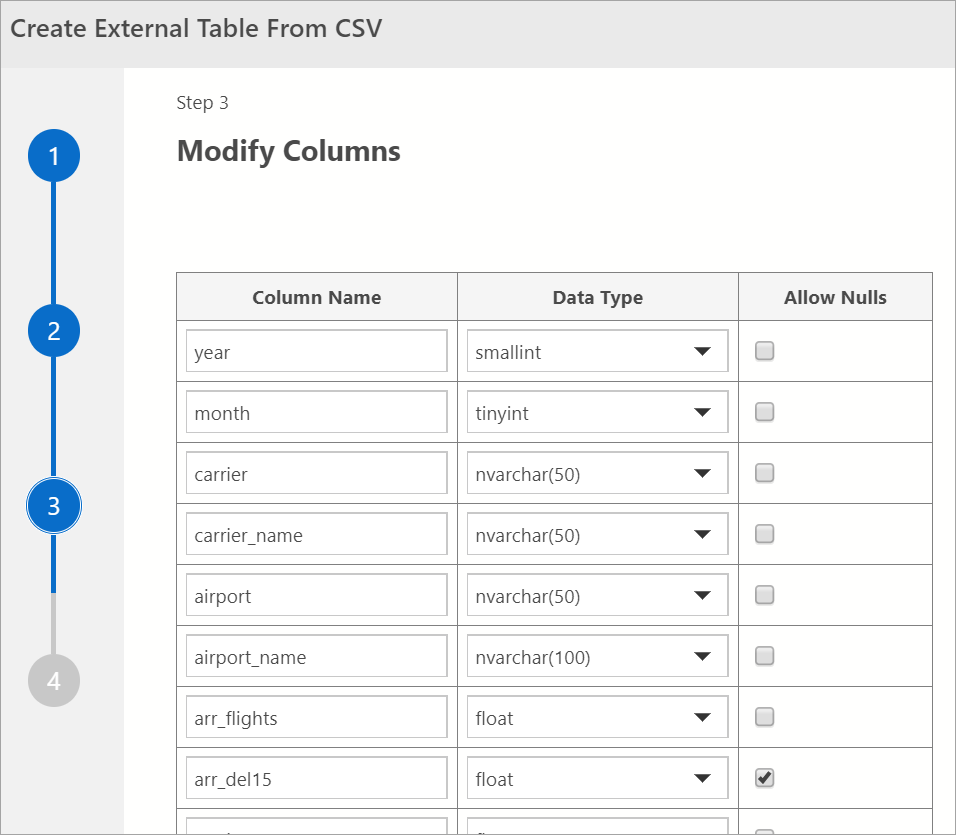
Después de comprobar las columnas de destino, seleccione Siguiente.
Resumen
Este paso proporciona un resumen de las selecciones. Proporciona el nombre del servidor SQL Server, el nombre de la base de datos, el nombre de la tabla, el esquema de la tabla e información de la tabla externa. En este paso, tiene la opción de generar un script o crear una tabla. Generar script crea un script en T-SQL para crear el origen de datos externo. Crear tabla crea el origen de datos externo.
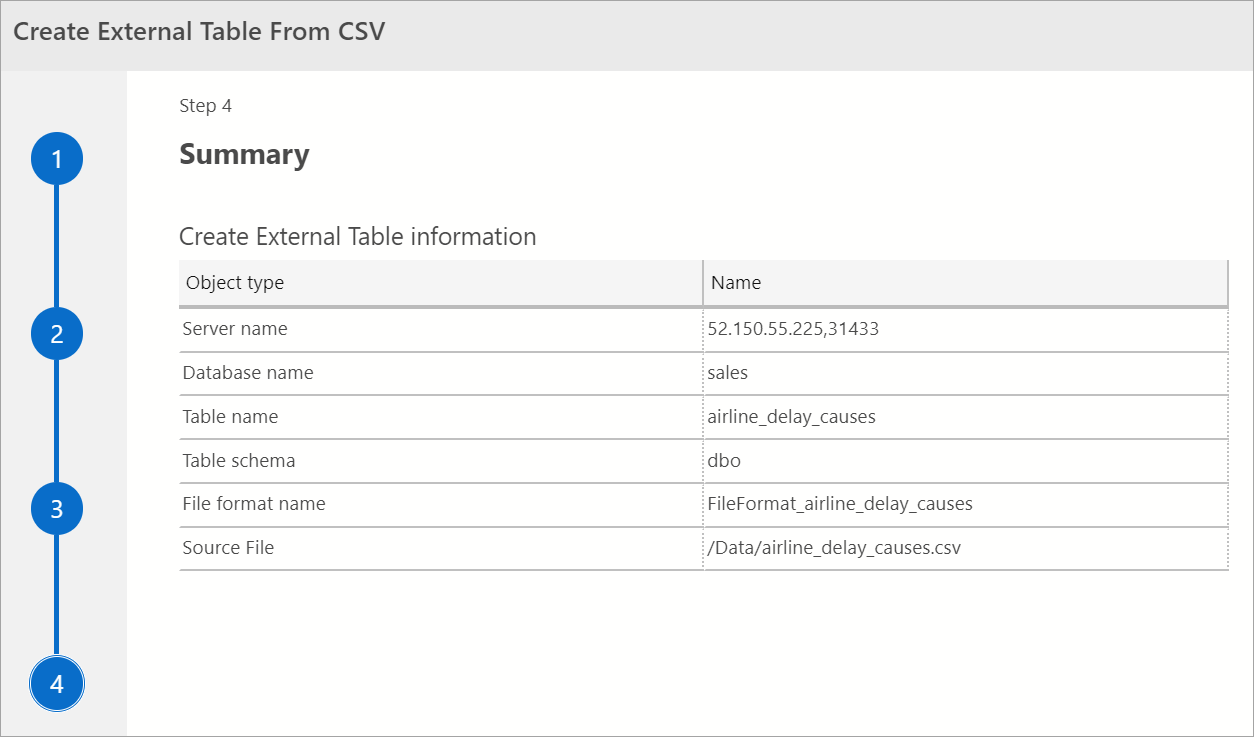
Si selecciona Crear tabla, SQL Server crea la tabla externa en la base de datos de destino.
Si selecciona Generar script, Azure Data Studio crea la consulta de T-SQL para crear la tabla externa.
Una vez creada la tabla, ahora se puede realizar consultas directamente con T-SQL a partir de la instancia de SQL Server.
Pasos siguientes
Para obtener más información sobre los clústeres de macrodatos de SQL Server y escenarios relacionados, vea Presentación de Clústeres de macrodatos de SQL Server.