Configuración de Kubernetes en varios equipos para implementaciones de clústeres de macrodatos de SQL Server
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
En este artículo se proporciona un ejemplo del empleo de kubeadm para configurar Kubernetes en varios equipos para implementaciones de Clústeres de macrodatos de SQL Server. En este ejemplo, el destino son varios equipos Ubuntu 16.04 o 18.04 LTS (físicos o virtuales). Si va a implementar en otra plataforma de Linux, debe modificar algunos de los comandos para que coincidan con el sistema.
Sugerencia
Para obtener scripts de ejemplo que configuran Kubernetes, vea Creación de un clúster de Kubernetes con Kubeadm en Ubuntu 20.04 LTS.
Para obtener un script de ejemplo que automatiza una implementación de kubeadm de un solo nodo en una máquina virtual y luego implementa una configuración predeterminada del clúster de macrodatos, vea Implementación con un script de bash en un clúster de kubeadm de un solo nodo.
Prerrequisitos
- Un mínimo de tres máquinas físicas o virtuales Linux
- Configuración recomendada por máquina:
- 8 CPU
- 64 GB de memoria
- 100 GB de almacenamiento
Importante
Antes de iniciar la implementación del clúster de macrodatos, asegúrese de que los relojes estén sincronizados en todos los nodos de Kubernetes a los que se destina la implementación. El clúster de macrodatos tiene propiedades de estado integradas para varios servicios que son sensibles al tiempo y los sesgos de reloj pueden dar lugar a un estado incorrecto.
Preparar los equipos
En cada equipo hay varios requisitos previos imprescindibles. En un terminal de Bash, ejecute los siguientes comandos en cada equipo:
Agregue el equipo actual al archivo
/etc/hosts:echo $(hostname -i) $(hostname) | sudo tee -a /etc/hostsDeshabilite el intercambio en todos los dispositivos.
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -aImporte las claves y registre el repositorio de Kubernetes.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.listConfigure los requisitos previos de Docker y Kubernetes en el equipo.
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bashEstablezca
net.bridge.bridge-nf-call-iptables=1. En Ubuntu 18.04, los siguientes comandos primero habilitanbr_netfilter.. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
Configurar el maestro de Kubernetes
Después de ejecutar los comandos anteriores en cada equipo, elija uno de ellos como maestro de Kubernetes. Luego ejecute los siguientes comandos en cada equipo.
En primer lugar, cree un archivo rbac.yaml en el directorio actual con el siguiente comando.
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOFInicialice el maestro de Kubernetes en este equipo. El siguiente script de ejemplo especifica la versión de Kubernetes
1.15.0. La versión que use dependerá de su clúster de Kubernetes.KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSIONDebería ver en la salida que el maestro de Kubernetes se ha inicializado correctamente.
Anote el comando
kubeadm joinque debe usar en los otros servidores para unirse al clúster de Kubernetes. Cópielo para su uso posterior.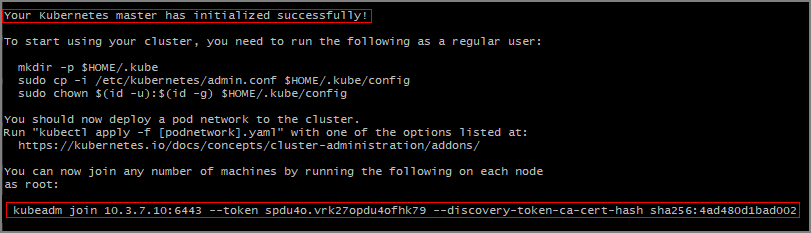
Defina un archivo de configuración de Kubernetes en el directorio particular.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configConfigure el clúster y el panel de Kubernetes.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
Configurar los agentes de Kubernetes
Los demás equipos actúan como agentes de Kubernetes en el clúster.
En cada uno de los otros equipos, ejecute el comando kubeadm join que ha copiado en la sección anterior.

Ver el estado del clúster
Para comprobar la conexión al clúster, use el comando kubectl get para devolver una lista de los nodos del clúster.
kubectl get nodes
Pasos siguientes
En los pasos de este artículo se ha configurado un clúster de Kubernetes en varios equipos Ubuntu. El siguiente paso es implementar un clúster de macrodatos de SQL Server 2019. Para obtener instrucciones, vea el siguiente artículo:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de