Depuración y diagnóstico de aplicaciones Spark en clústeres de macrodatos de Clústeres de macrodatos de SQL Server con el servidor de historial de Spark
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
En este artículo se proporcionan instrucciones para usar el servidor de historial de Spark extendido para depurar y diagnosticar aplicaciones Spark en un clúster de macrodatos de SQL Server. Estas funcionalidades de depuración y diagnóstico están integradas en el servidor de historial de Spark y tienen tecnología de Microsoft. La extensión incluye la pestaña de datos, la pestaña de gráfico y la pestaña de diagnóstico. En la pestaña de datos, los usuarios pueden comprobar los datos de entrada y salida del trabajo de Spark. En la pestaña de gráfico, los usuarios pueden comprobar el flujo de datos y reproducir el gráfico de trabajo. En la pestaña de diagnóstico, el usuario puede hacer referencia a la asimetría de datos, el desfase horario y el análisis de uso del ejecutor.
Obtener acceso al servidor de historial de Spark
La experiencia del usuario del servidor de historial de Spark de código abierto se ha mejorado con información, como, por ejemplo, datos específicos del trabajo y visualización interactiva de los flujos de datos y del gráfico de trabajo para el clúster de macrodatos.
Apertura de la interfaz de usuario web del servidor de historial de Spark mediante URL
Para abrir el servidor de historial de Spark, vaya a la siguiente dirección URL, y reemplace <Ipaddress> y <Port> por la información específica del clúster de macrodatos. En los clústeres implementados antes de SQL Server 2019 CU5, con una configuración de clúster de macrodatos de autenticación básica (nombre de usuario/contraseña), debe proporcionar el usuario root (raíz) cuando se le pida que inicie sesión en los puntos de conexión de puerta de enlace (Knox). Vea Implementación del clúster de macrodatos de SQL Server. A partir de SQL Server 2019 (15.x) CU 5, al implementar un nuevo clúster con autenticación básica todos los puntos de conexión incluida la puerta de enlace utilizan AZDATA_USERNAME y AZDATA_PASSWORD. Los puntos de conexión de los clústeres que se actualizan a CU 5 continúan usando root como nombre de usuario para conectarse al punto de conexión de puerta de enlace. Este cambio no se aplica a las implementaciones que utilizan la autenticación de Active Directory. Consulte Credenciales para acceder a los servicios a través del punto de conexión de puerta de enlace en las notas de la versión.
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
La interfaz de usuario web del servidor de historial de Spark tiene el siguiente aspecto:

Pestaña de datos en el servidor de historial de Spark
Seleccione el id. de trabajo y haga clic en Datos en el menú de herramientas para obtener la vista de datos.
Seleccione cada pestaña para comprobar las entradas, las salidas y las operaciones de tabla.

Copie todas las filas con el botón Copiar.

Haga clic en el botón CSV para guardar todos los datos como un archivo CSV.

Para buscar, escriba palabras clave en el campo de búsqueda; el resultado de la búsqueda se mostrará inmediatamente.

Haga clic en el encabezado de columna para ordenar la tabla, haga clic en el signo más para expandir una fila y mostrar más detalles, o haga clic en el signo menos para contraer una fila.

Descargue un solo archivo con el botón Descarga parcial que se encuentra a la derecha. El archivo seleccionado se descargará en la ubicación local. Si el archivo ya no existe, se abrirá una nueva pestaña para mostrar los mensajes de error.

Para copiar la ruta de acceso completa o la ruta de acceso relativa, seleccione Copiar ruta de acceso completa, Copiar ruta de acceso relativa que se expande desde el menú de descarga. En el caso de los archivos de Azure Data Lake Storage, la opción Abrir en Explorador de Azure Storage iniciará el explorador de Azure Storage. Busque la carpeta exacta al iniciar sesión.

Haga clic en el número que aparece debajo de la tabla para desplazarse por las páginas cuando se muestren demasiadas filas en una página.

Mantenga el mouse sobre el signo de interrogación junto a Datos para mostrar la información sobre herramientas, o haga clic en el signo de interrogación para obtener más información.

Para enviar comentarios sobre problemas, haga clic en Enviarnos sus comentarios.

Pestaña de gráfico en el servidor de historial de Spark
Seleccione el id. de trabajo y haga clic en Gráfico en el menú de herramientas para obtener la vista de gráfico del trabajo.
Revise la información general del trabajo mediante el gráfico de trabajo generado.
De forma predeterminada, se mostrarán todos los trabajos, pero pueden filtrarse por id. de trabajo.

Se deja Progreso como valor predeterminado. El usuario puede comprobar el flujo de datos seleccionando Leído o Escrito en la lista desplegable Mostrar.

El nodo del gráfico se muestra en el color que muestra el mapa térmico.

Para reproducir el trabajo, haga clic en el botón Reproducir y, para detenerse en cualquier momento, haga clic en el botón Detener. La tarea se muestra en color para mostrar un estado diferente al reproducirse:
- Verde para correcto: el trabajo se ha completado correctamente.
- Naranja para intentado de nuevo: las instancias de tareas que no se han realizado correctamente, pero que no afectan al resultado final del trabajo. Estas tareas tenían instancias duplicadas o de reintentos que pueden realizarse correctamente más tarde.
- Azul para ejecutar: la tarea se está ejecutando.
- Blanco para esperar u omitir: la tarea está esperando para ejecutarse o la fase se ha omitido.
- Rojo para error: error en la tarea.

La fase omitida se muestra en blanco.


Nota
Se permite la reproducción de cada trabajo. Los trabajos incompletos no se pueden reproducir.
El mouse se desplaza para acercar o alejar el gráfico del trabajo. También puede hacer clic en Ampliar para ajustar a la pantalla.

Mantenga el mouse sobre el nodo del gráfico para ver la información sobre herramientas cuando haya tareas con errores y haga clic en fase para abrir la página de la fase.

En la pestaña del gráfico de trabajo, las fases tendrán información sobre herramientas y se mostrará el icono pequeño si tienen tareas que cumplen las condiciones siguientes:
- Asimetría de datos: tamaño de lectura de datos > tamaño promedio de lectura de datos de todas las tareas dentro de esta fase * 2 y tamaño de lectura de datos > 10 MB
- Sesgo horario: tiempo de ejecución > tiempo promedio de ejecución de todas las tareas dentro de esta fase * 2 y tiempo de ejecución > 2 minutos
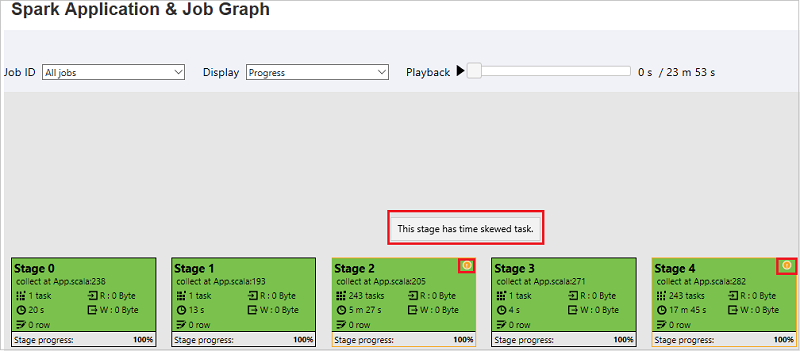
El nodo de gráfico de trabajo mostrará la siguiente información de cada fase:
- Id.
- Nombre o descripción.
- Número de tarea total.
- Lectura de datos: las sumas de tamaño de entrada y de tamaño de lectura aleatoria.
- Escritura de datos: las sumas de tamaño de salida y de tamaño de escritura aleatoria.
- Tiempo de ejecución: el tiempo entre la hora de inicio del primer intento y la hora de finalización del último intento.
- Recuento de filas: la suma de los registros de entrada, los registros de salida, los registros de lectura aleatoria y los registros de escritura aleatoria.
- Progreso.
Nota
De forma predeterminada, el nodo del gráfico de trabajo mostrará información del último intento de cada fase (excepto en el tiempo de ejecución de la fase), pero durante la reproducción el nodo del gráfico mostrará información de cada intento.
Nota:
Para el tamaño de los datos de lectura y escritura, usamos 1 MB = 1000 KB = 1000 * 1000 bytes.
Para enviar comentarios sobre problemas, haga clic en Enviarnos sus comentarios.
Pestaña de diagnóstico en el servidor de historial de Spark
Seleccione el id. de trabajo y haga clic Diagnóstico en el menú de herramientas para obtener la vista de diagnóstico del trabajo. La pestaña de diagnóstico incluye Asimetría de datos, Desfase horario y Análisis de uso del ejecutor.
Para comprobar la Asimetría de datos, el Desfase horario y el Análisis de uso del ejecutor, seleccione las pestañas respectivamente.

Asimetría de datos
Haga clic en Asimetría de datos. Las tareas sesgadas correspondientes se mostrarán en función de los parámetros especificados.
Especificar parámetros: la primera sección muestra los parámetros que se usan para detectar la Asimetría de datos. La regla integrada es: La lectura de datos de tarea es tres veces mayor que la lectura de datos de tarea promedio y la lectura de datos de tarea es mayor que 10 MB. Si desea definir su propia regla para las tareas sesgadas, puede elegir los parámetros; la fase sesgada y la sección Char de sesgo se actualizarán en consecuencia.
Fase sesgada: la segunda sección muestra las fases que tienen tareas con desfase que cumplen los criterios especificados anteriormente. Si hay más de una tarea sesgada en una fase, la tabla de fase sesgada solo muestra la tarea más sesgada (por ejemplo, los datos más grandes para la asimetría de datos).

Gráfico de sesgo: cuando se selecciona una fila de la tabla de fase sesgada, el gráfico de sesgo muestra más detalles de distribuciones de tareas en función de la lectura de datos y el tiempo de ejecución. Las tareas sesgadas se marcan en rojo y las tareas normales se marcan en azul. Por motivos de rendimiento, el gráfico solo muestra hasta 100 tareas de ejemplo. Los detalles de la tarea se muestran en el panel inferior derecho.

Desfase horario
En la pestaña Desfase horario se muestran las tareas sesgadas en función del tiempo de ejecución de la tarea.
Especificar parámetros: la primera sección muestra los parámetros que se usan para detectar el desfase horario. Los criterios predeterminados para detectar el desfase horario son: el tiempo de ejecución de la tarea es mayor que tres veces el tiempo de ejecución promedio y el tiempo de ejecución de la tarea es superior a 30 segundos. Puede cambiar los parámetros en función de sus necesidades. La fase sesgada y el gráfico de sesgo muestran información sobre las fases y las tareas correspondientes del mismo modo que la pestaña Asimetría de datos.
Haga clic en Desfase horario y el resultado filtrado se mostrará en la sección Fase sesgada según los parámetros establecidos en la sección Especificar parámetros. Haga clic en un elemento en la sección Fase sesgada. A continuación, el gráfico correspondiente se creará en la sección 3 y los detalles de la tarea se mostrarán en el panel inferior derecho.

Análisis de uso del ejecutor
El gráfico de uso del ejecutor visualiza el estado de ejecución y la asignación del ejecutor real del trabajo de Spark.
Haga clic en Análisis de uso del ejecutor y crearemos cuatro curvas de tipos sobre el uso del ejecutor. Estas incluyen ejecutores asignados, ejecutores en ejecución, ejecutores inactivos e instancias del ejecutor máximo. En lo que respecta a los ejecutores asignados, cada evento "Ejecutor agregado" o "Ejecutor eliminado" aumentará o disminuirá los ejecutores asignados. Puede comprobar la "escala de tiempo del evento" en la pestaña "Trabajos" para obtener más comparaciones.

Haga clic en el icono de color para seleccionar o anular la selección del contenido correspondiente en todos los borradores.

Registros de Spark / Yarn
Además del Servidor de historial de Spark, aquí puede encontrar los registros de Spark y Yarn, respectivamente:
- Registros de eventos de Spark: hdfs:///system/spark-events
- Registros de Yarn: hdfs:///tmp/logs/root/logs-tfile
Nota: Los dos registros tienen un período de retención predeterminado de siete días. Si quiere cambiar el período de retención, vea la página Configuración de Apache Spark y Apache Hadoop. La ubicación no se puede cambiar.
Problemas conocidos
El servidor de historial de Spark tiene los siguientes problemas conocidos:
Actualmente, solo funciona para el clúster de Spark 3.1 (CU13+) y Spark 2.4 (CU12-).
Los datos de entrada y salida con RDD no se mostrarán en la pestaña Datos.
Pasos siguientes
- Introducción a los clústeres de macrodatos de SQL Server
- Configuración de las opciones de Spark
- Configurar las opciones de Spark