Envío de trabajos de Spark en Clústeres de macrodatos de SQL Server en Azure Data Studio
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
Uno de los escenarios clave para clústeres de macrodatos es la capacidad de enviar trabajos de Spark para SQL Server. La característica de envío de trabajos de Spark permite enviar archivos Jar o Py locales con referencias a clústeres de macrodatos de SQL Server 2019. También permite ejecutar archivos Jar o Py, que ya se encuentran en el sistema de archivos HDFS.
Prerrequisitos
Herramientas de macrodatos de SQL Server 2019:
- Azure Data Studio
- Extensión de SQL Server 2019
- kubectl
Conexión de Azure Data Studio a la puerta de enlace de HDFS/Spark del clúster de macrodatos.
Apertura del cuadro de diálogo de envío de trabajos de Spark
Hay varias maneras de abrir el cuadro de diálogo de envío de trabajos de Spark. Las distintas formas incluyen el panel, el menú contextual del Explorador de objetos y la paleta de comandos.
Para abrir el cuadro de diálogo de envío de trabajos de Spark, haga clic en New Spark Job (Nuevo trabajo de Spark) en el panel.
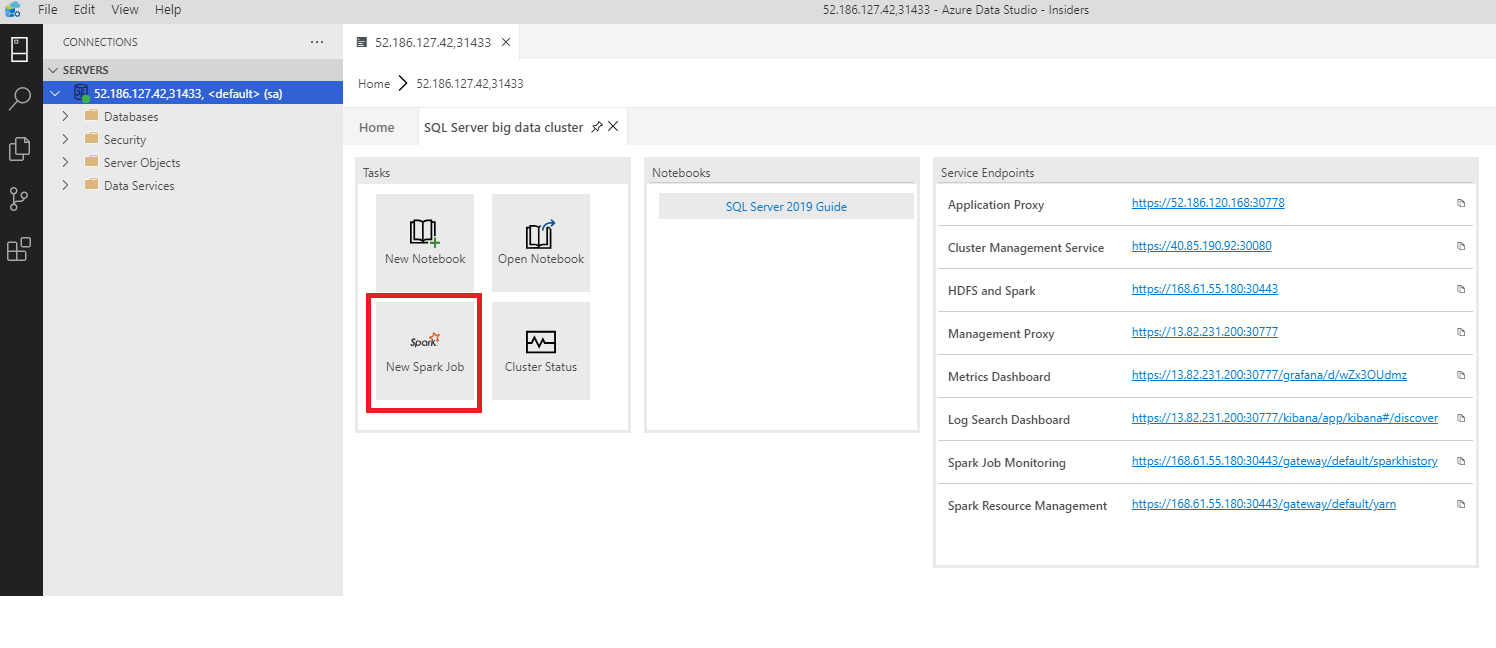
O bien, haga clic con el botón derecho en el Explorador de objetos y seleccione Submit Spark Job (Enviar trabajo de Spark) en el menú contextual.
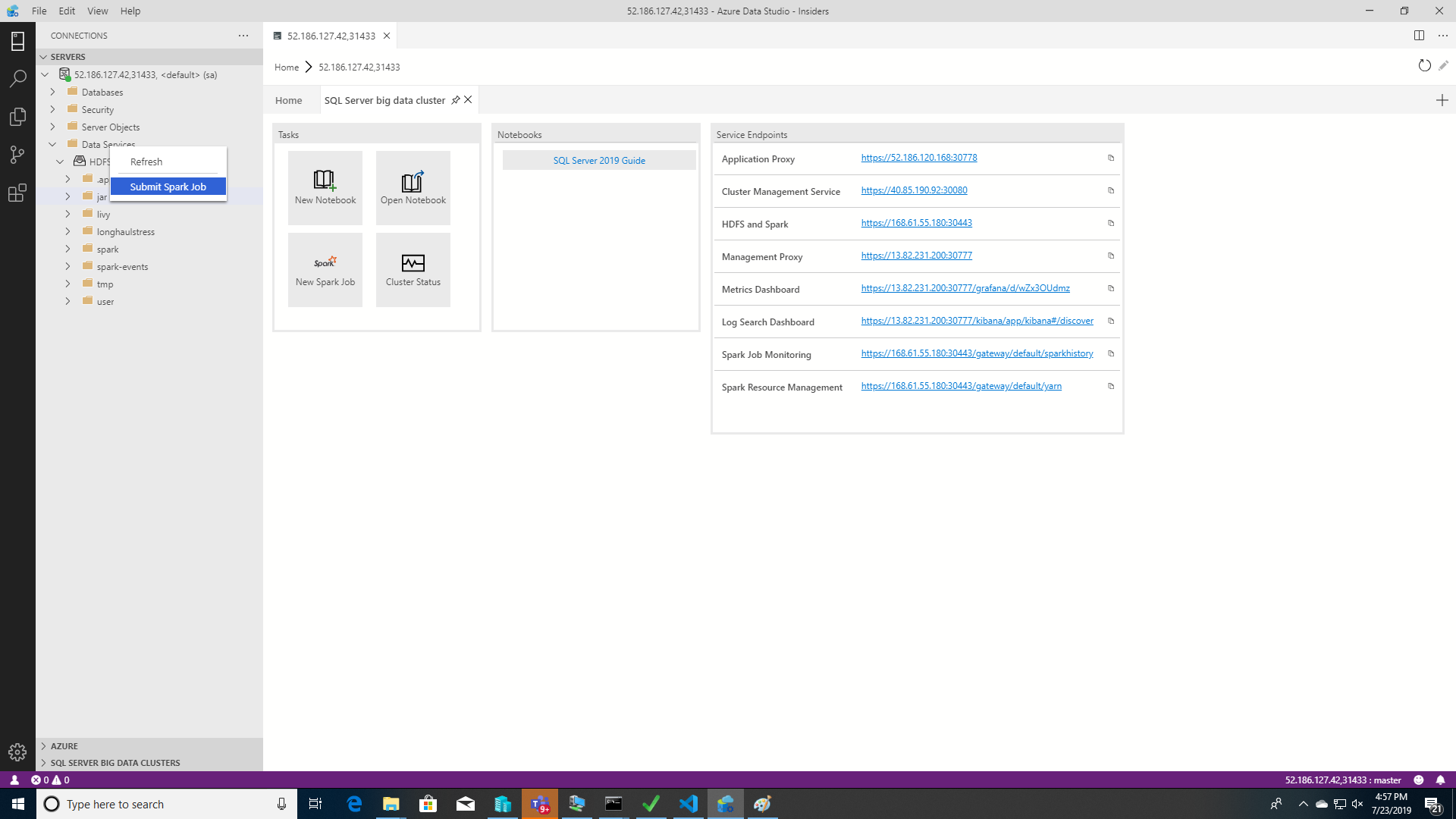
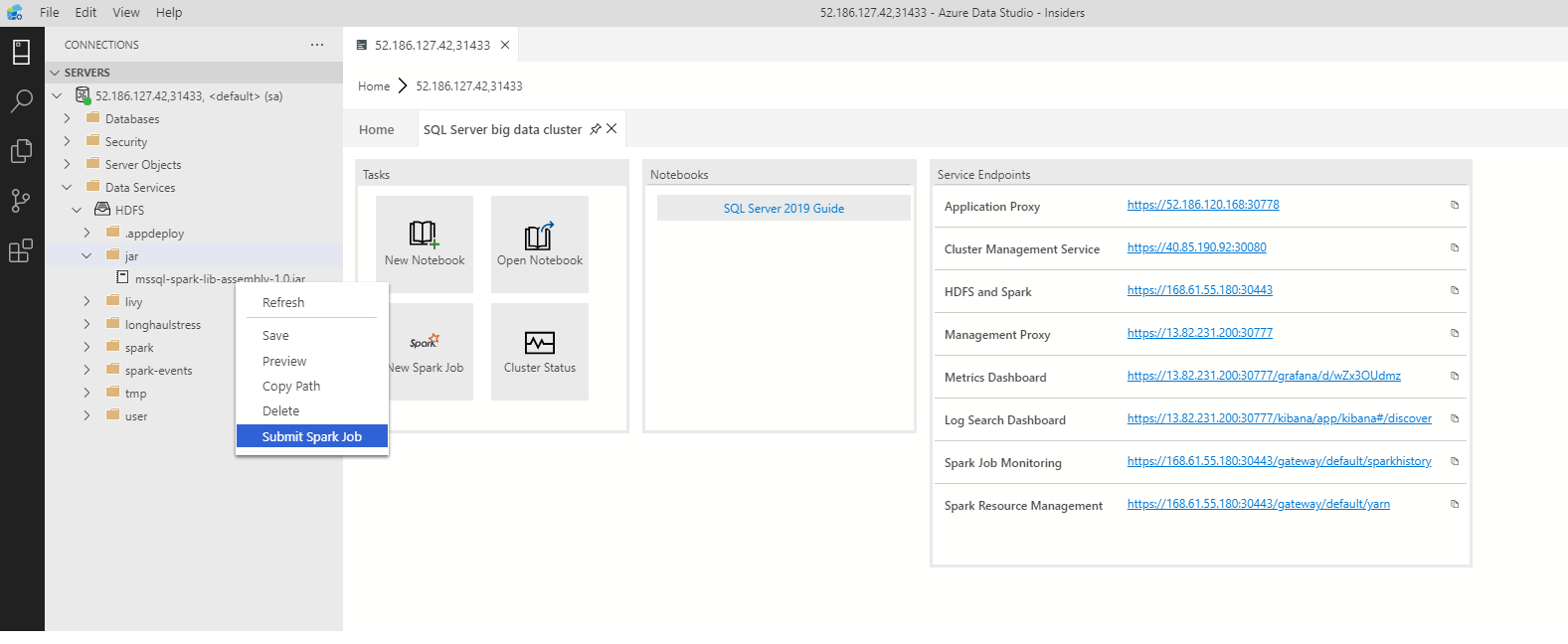
Para abrir el cuadro de diálogo de envío de trabajos de Spark con los campos Jar o Py rellenados previamente, haga clic con el botón derecho en un archivo Jar o Py en el Explorador de objetos y seleccione Submit Spark Job (Enviar trabajo de Spark) en el menú contextual.
Use Submit Spark Job (Enviar trabajo de Spark) en la paleta de comandos al escribir Ctrl + Mayús + P (en Windows) y Cmd + Mayús + P (en Mac).

Envío de trabajo de Spark
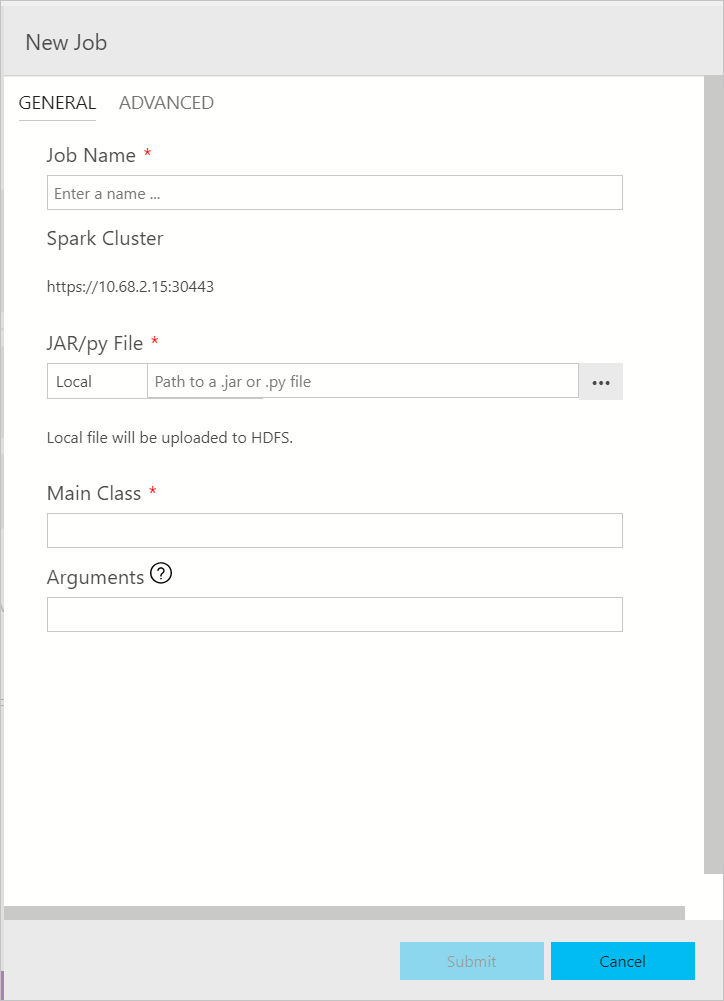
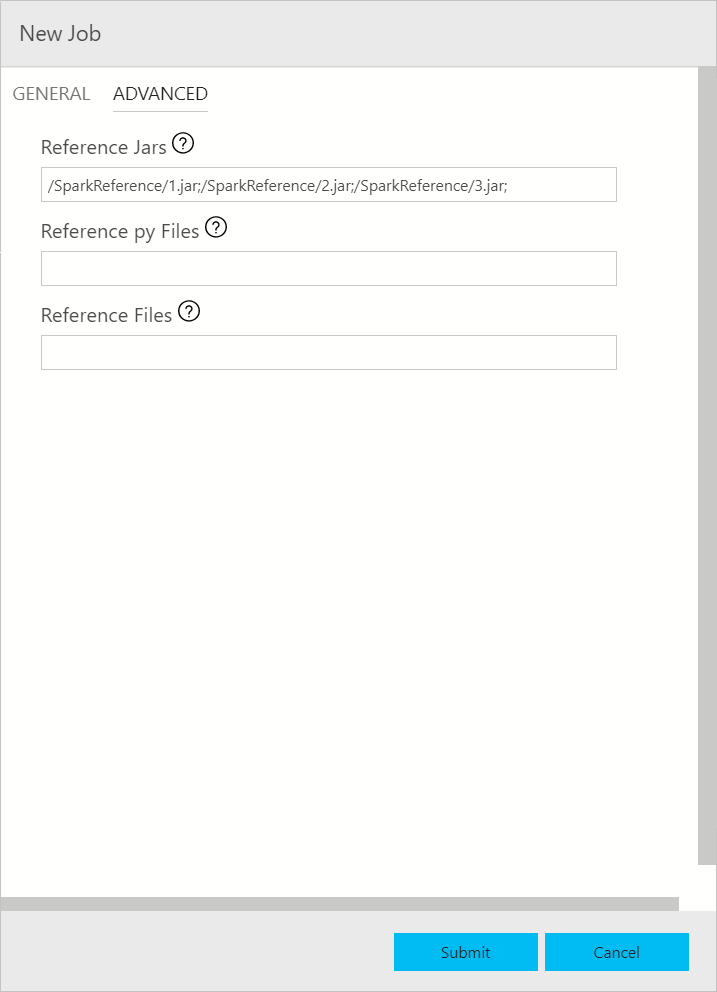
El cuadro de diálogo de envío de trabajos de Spark se muestra así. Escriba el nombre del trabajo, la ruta de acceso del archivo JAR o Py, la clase principal y otros campos. El origen del archivo Jar o Py puede ser Local o HDFS. Si el trabajo de Spark tiene archivos de referencia Jar, Py u otros, haga clic en la pestaña OPCIONES AVANZADAS y escriba las rutas de acceso de archivo correspondientes. Haga clic en Enviar para enviar el trabajo de Spark.
Supervisar el envío de trabajos de Spark
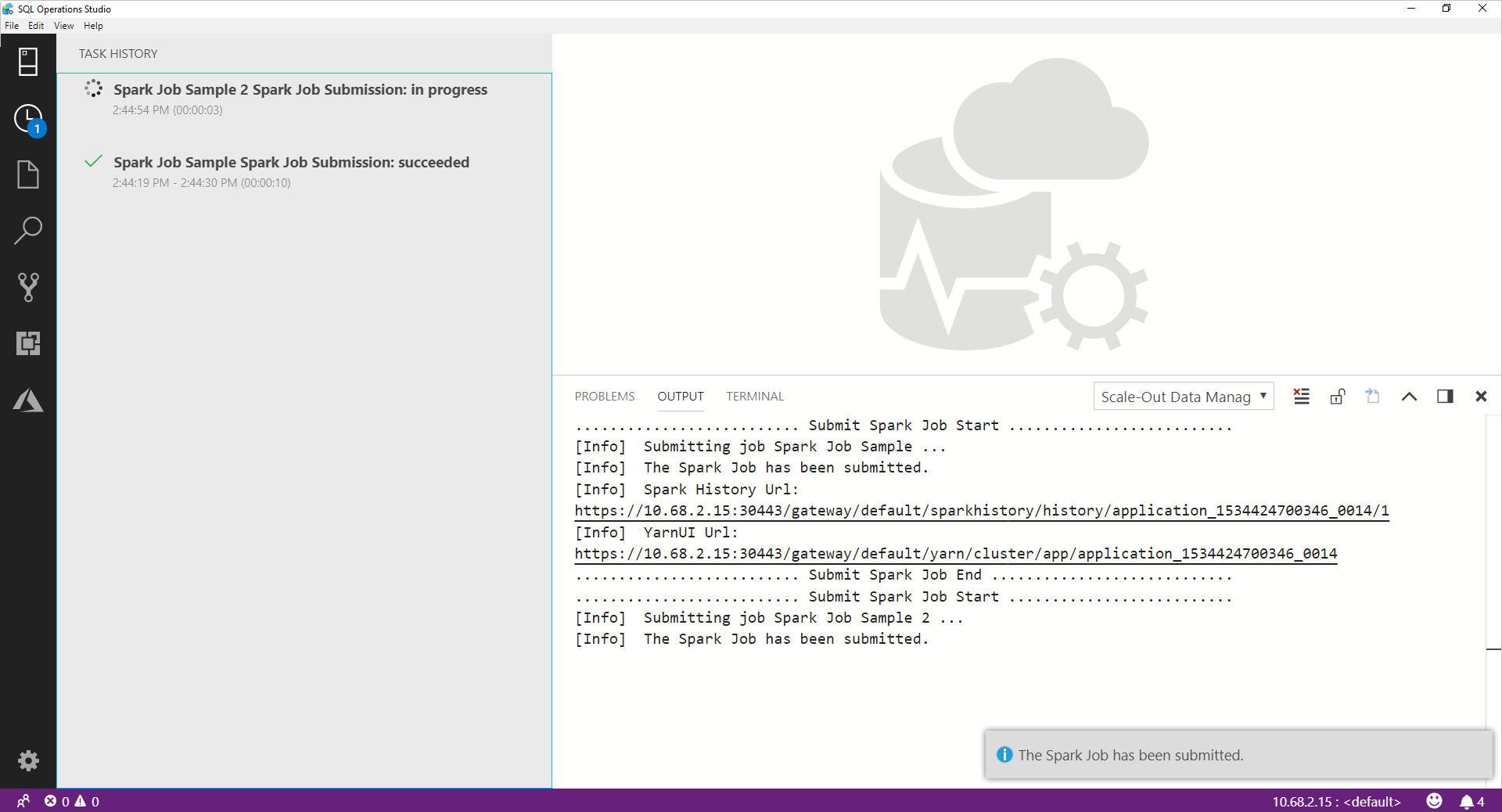
Una vez enviado el trabajo de Spark, la información de estado del envío y la ejecución de Spark se muestra en el historial de tareas de la izquierda. Los detalles sobre el progreso y los registros también se muestran en la ventana SALIDA de la parte inferior.
Cuando el trabajo de Spark está en curso, el panel Historial de tareas y la ventana SALIDA se actualizan con el progreso.
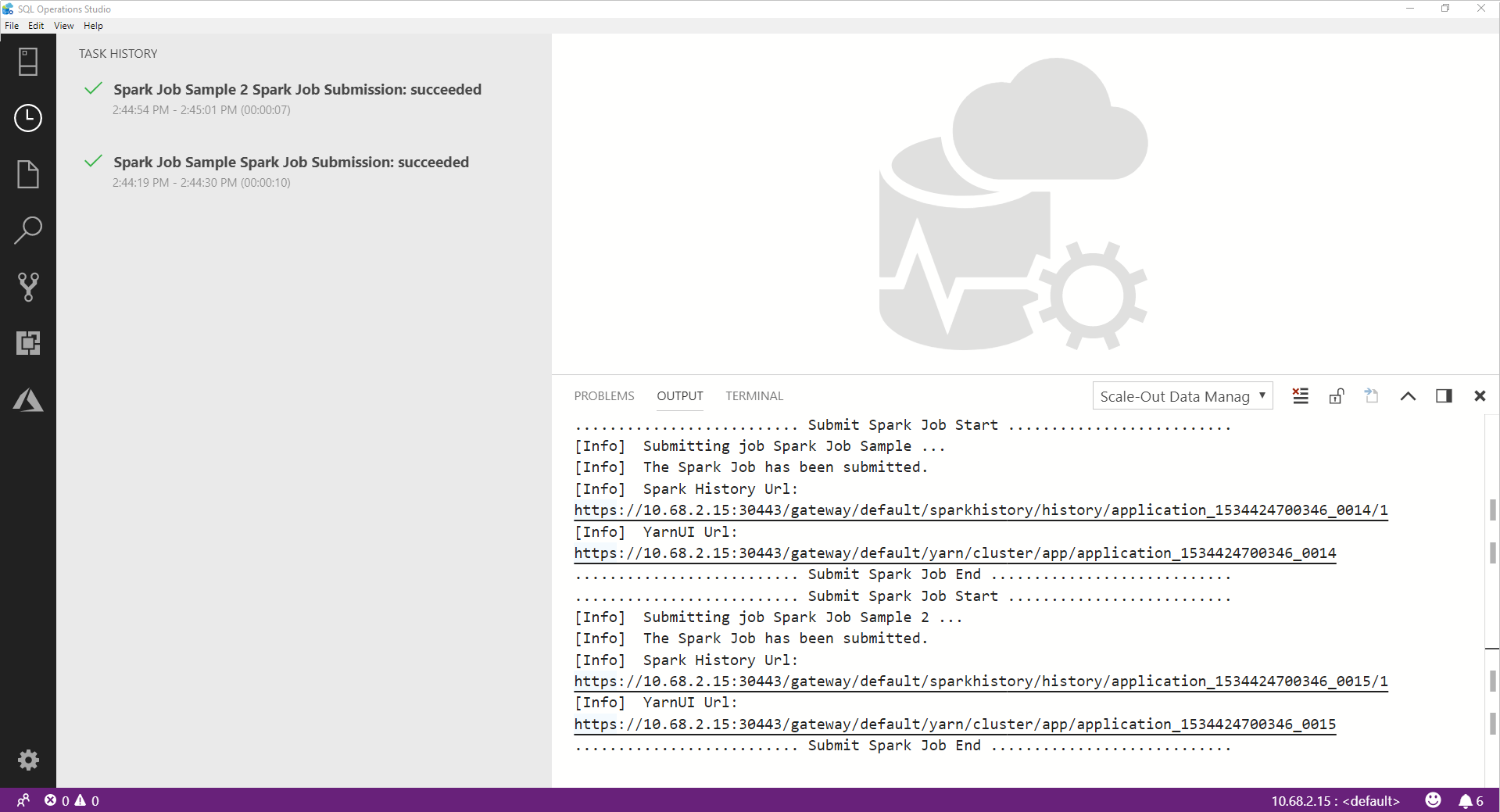
Cuando el trabajo de Spark se completa correctamente, los vínculos de la interfaz de usuario de Spark y de Yarn aparecen en la ventana SALIDA. Haga clic en los vínculos para obtener más información.
Pasos siguientes
Para obtener más información sobre los clústeres de macrodatos de SQL Server y escenarios relacionados, vea Presentación de Clústeres de macrodatos de SQL Server.