Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Las diferencias de hardware, software y configuración del clúster, así como los distintos requisitos de aplicación para el tiempo de actividad y el rendimiento necesitan una configuración específica para los valores de tiempo de espera de concesión, clúster y comprobación de estado. Para determinadas aplicaciones y cargas de trabajo se necesita una supervisión más exigente que limite el tiempo de inactividad producido por errores graves. Para otras se necesita mayor tolerancia a problemas de red transitorios y esperas debido a un uso intensivo de los recursos, pero aceptan conmutaciones por error más lentas.
En cada nodo hay varios servicios que se dedican a detectar errores. El servicio de clúster podría detectar la pérdida del quórum, la DLL de recursos podría detectar un problema obtenido por la detección del estado de Always On o podría iniciarse una conmutación por error manual directamente en la instancia principal. El servicio de clúster, el host de recursos y la instancia de SQL Server se sincronizan entre sí a través de RPC, la memoria compartida y T-SQL. En la mayoría de los casos, estos servicios se comunican correctamente, aunque esta comunicación no es absolutamente confiable incluso entre servicios del mismo equipo. Además, el grupo de disponibilidad debe ser capaz de soportar eventos de todo el sistema, como errores de red y de disco, que podrían impedir la comunicación o interrumpir la funcionalidad. Con muchos casos de error y sin una comunicación totalmente confiable entre los servicios, el grupo de disponibilidad depende de diversos mecanismos de detección de conmutación por error para detectar y responder a errores de forma independiente entre ellos, para que el estado del clúster siempre sea coherente para todos los nodos.
Diagnósticos de tiempo de espera de comprobación de estado mejorados de SQL Server 2025
Las restricciones de recursos, como el uso elevado de CPU, latencia de disco o agotamiento de memoria, pueden desencadenar un tiempo de espera de concesión del grupo de disponibilidad AlwaysOn. Cuando se notifica un tiempo de espera de arrendamiento en el registro del clúster, los datos más recientes del monitor de rendimiento para el uso de CPU, el uso de memoria y la latencia de lectura y escritura en disco se registran en el registro del clúster de conmutación por error de Windows junto con el tiempo de espera de arrendamiento.
Del mismo modo, las restricciones de recursos también pueden desencadenar un tiempo de espera de comprobación de estado. A partir de SQL Server 2025 (17.x), los mismos contadores de monitor de rendimiento ahora se notifican en el registro de clústeres de conmutación por error de Windows cuando se detecta un tiempo de espera de comprobación de estado, similar a la salida de diagnóstico de tiempo de espera de concesión.
A continuación se muestra un ejemplo de la salida mejorada del registro de clúster de conmutación por error de Windows para un tiempo de espera de comprobación de estado:
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] AG health check failed, logging perf counter data collected so far
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:25.0, 21.857418, 3248349184.000000, 0.000000, 0.000253
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:35.0, 11.442071, 3255394304.000000, 0.000907, 0.000382
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:45.0, 9.979768, 3253981184.000000, 0.000415, 0.000549
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:55.0, 9.762850, 3251232768.000000, 0.001989, 0.000638
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:56:5.0, 9.827234, 3250462720.000000, 0.002250, 0.001418
Nodo de clúster y detección de recursos
Cada nodo de clúster ejecuta un servicio de clúster único, que pone en funcionamiento el clúster de conmutación por error y supervisa todos los recursos del clúster. El host de recursos funciona como un proceso independiente y es la interfaz entre el servicio de clúster y los recursos del clúster. El host de recursos realiza operaciones en recursos de clúster cuando así lo solicita el servicio de clúster. Las aplicaciones compatibles con clústeres como SQL Server proporcionan interfaces personalizadas para el monitor de recursos a través de la DLL de recursos. La DLL de recursos implementa operaciones en línea y sin conexión y la supervisión de estado para recursos personalizados. El host de recursos es un proceso secundario del servicio de clúster y se elimina cuando se elimina el servicio de clúster.
Para SQL Server, la DLL de recursos del grupo de disponibilidad determina el estado del grupo de disponibilidad según el mecanismo de concesión del grupo de disponibilidad y la detección de estado de Always On. La DLL de recursos del grupo de disponibilidad expone el estado de los recursos a través de la operación IsAlive. El monitor de recursos sondea IsAlive en el intervalo de latido del clúster, que se establece mediante los valores CrossSubnetDelay y SameSubnetDelay de todo el clúster. En un nodo principal, el servicio de clúster inicia las conmutaciones por error cada vez que la llamada de IsAlive a la DLL de recursos indica que el grupo de disponibilidad no tiene un estado correcto.
El servicio de clúster envía latidos a otros nodos del clúster y confirma latidos procedentes de ellos. Cuando un nodo detecta un error de comunicación de una serie de latidos no reconocidos, difunde un mensaje haciendo que todos los nodos accesibles reconcilien sus vistas del estado del nodo del clúster. Este evento, denominado un evento de reagrupación, mantiene la coherencia del estado del clúster entre nodos. Después de un evento de reagrupación, si se pierde el quórum, todos los recursos del clúster, incluidos los grupos de disponibilidad de esta partición, se quedan sin conexión. Se realiza la transición de todos los nodos de esta partición a un estado de resolución. Si existe una partición, que contiene un quórum, se asigna el grupo de disponibilidad a un nodo en la partición y se convierte en la réplica principal, mientras que los demás nodos se convierten en réplicas secundarias.
Detección de estado de Always On
La DLL de recursos de Always On supervisa el estado de los componentes internos de SQL Server.
sp_server_diagnostics notifica el estado de estos componentes de SQL Server en un intervalo controlado por HealthCheckTimeout.
sp_server_diagnostics informa del estado de cinco componentes de nivel de instancia: sistema, recursos, procesamiento de consultas, subsistema de E/S y eventos. También notifica el estado de cada grupo de disponibilidad. Tras cada actualización, la DLL de recursos actualiza el estado de mantenimiento del recurso del grupo de disponibilidad en función del nivel de error del grupo de disponibilidad. Cuando sp_server_diagnostics devuelve datos, muestra cada componente en un estado que puede ser correcto, de advertencia, de error o desconocido, con algunos datos XML que describen el estado del componente. Para la detección de estado, la DLL de recursos solo actúa si un componente se encuentra en estado de error.
Si la detección de estado no informa de una actualización a la DLL de recursos de varios intervalos, el grupo de disponibilidad se considerará incorrecto y notificará errores en llamadas IsAlive.
Mecanismo de concesión
A diferencia de otros mecanismos de conmutación por error, la instancia de SQL Server desempeña un rol activo en el mecanismo de concesión. El mecanismo de concesión se utiliza como una validación “Looks-Alive” entre el host del recurso de clúster y el proceso de SQL Server. El mecanismo se usa para garantizar que los dos lados (el Servicio de clúster y el servicio de SQL Server) están en contacto con frecuencia, comprobando el estado del otro y evitando en última instancia un escenario de cerebro dividido. Al volver a poner el grupo de disponibilidad en línea como la réplica principal, la instancia de SQL Server genera un subproceso de trabajo de concesión dedicado para el grupo de disponibilidad. El trabajo de concesión comparte una pequeña región de memoria con el host de recursos que contiene los eventos de renovación de concesión y de detención de concesión. El trabajo de concesión y el host de recursos funcionan de manera circular: primero señalan sus respectivos eventos de renovación de concesión y luego se ponen en espera, aguardando a que la otra parte indique su propio evento de renovación de concesión o evento de detención. Tanto el host de recursos como el subproceso de concesión de SQL Server mantienen un valor de período de vida, que se actualiza cada vez que el subproceso se activa después de ser señalado por el otro subproceso. Si se completa el período de vida mientras se espera la señal, la concesión expira y la réplica cambia al estado de resolución para ese grupo de disponibilidad específico. Si se señala el evento de detención de concesión, la réplica cambia a un rol de resolución.
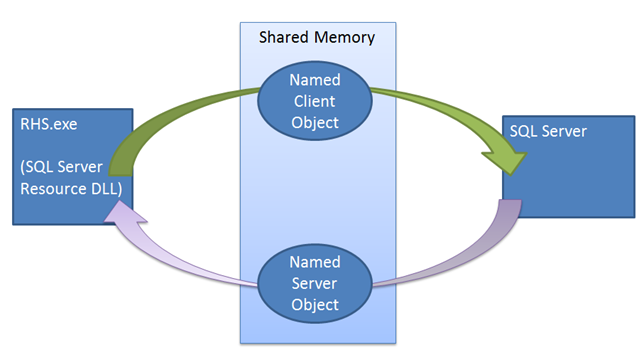
El mecanismo de concesión exige la sincronización entre SQL Server y el clúster de conmutación por error de Windows Server. Cuando se emite un comando de conmutación por error, el servicio de clúster realiza la llamada Offline sin conexión a la DLL de recursos de la réplica principal actual. La DLL de recursos primero intenta tomar el grupo de disponibilidad sin conexión mediante un procedimiento almacenado. Si este procedimiento almacenado produce un error o agota el tiempo de espera, el error se notifica al servicio de clúster, que luego emite un comando de finalización. La finalización intenta volver a ejecutar el mismo procedimiento almacenado, pero esta vez el clúster no espera a que la DLL de recursos notifique el estado correcto o de error antes de poner el grupo de disponibilidad en línea en una nueva réplica. Si se produce un error en esta segunda llamada de procedimiento, el host de recursos tiene que confiar en este mecanismo de concesión para poner la instancia sin conexión. Cuando se llama a la DLL de recursos para poner el grupo de disponibilidad sin conexión, la DLL de recursos señala el evento de detención de concesión y reactiva el subproceso de trabajo de concesión de SQL Server para poner el grupo de disponibilidad sin conexión. Incluso si no se señala a este evento de detención, la concesión expira y la réplica cambiará al estado de resolución.
La concesión es principalmente un mecanismo de sincronización entre la instancia principal y el clúster, pero también puede crear condiciones de error donde no había ninguna necesidad de conmutación por error. Por ejemplo, uso elevado de CPU, condiciones de memoria insuficiente (poca memoria virtual, paginación de procesos), falta de respuesta de los procesos de SQL al generar un volcado de memoria, falta de respuesta de todo el sistema, desconexión del clúster (WSFC) debido, por ejemplo, a la pérdida de cuórum, que pueden impedir la renovación de la concesión de la instancia de SQL y provocar un reinicio o una conmutación por error.
Directrices para valores de tiempo de espera del clúster
Sopese los pros y los contras y conozca las consecuencias de usar una supervisión menos intensa del clúster de SQL Server. Al aumentar los valores de tiempo de espera del clúster, aumenta la tolerancia a problemas de red transitorios pero se ralentizan las reacciones a errores graves. Al aumentar los tiempos de espera para tratar con una presión de recursos o una gran latencia geográfica, aumenta el tiempo para recuperarse de errores graves o irrecuperables. Aunque esto es aceptable para muchas aplicaciones, no es ideal en todos los casos.
La configuración predeterminada se optimiza para reaccionar rápidamente a los síntomas de errores graves y tiempo de inactividad limitador, pero esta configuración también puede ser excesivamente exigente para ciertas cargas de trabajo y configuraciones. No se recomienda para reducir cualquiera de los valores de LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThreshold o HealthCheckTimeout más allá de sus valores predeterminados. Las configuraciones correctas para cada implementación será distinta y es probable que tarde un mayor período de tiempo de ajuste para la detección. Al realizar cambios en cualquiera de estos valores, hágalo de manera gradual y teniendo en cuenta las relaciones y las dependencias entre estos valores.
Relación entre el tiempo de espera del clúster y el tiempo de espera de concesión
La función principal del mecanismo de concesión es desconectar el recurso de SQL Server en caso de que el servicio de clúster no pueda comunicarse con la instancia mientras se realiza una conmutación por error en otro nodo. Cuando el clúster realiza la operación sin conexión en el recurso del clúster del grupo de compatibilidad, el servicio de clúster realiza una llamada RPC a rhs.exe para poner el recurso sin conexión. La DLL de recursos usa procedimientos almacenados para indicar a SQL Server que ponga el grupo de compatibilidad sin conexión, pero podría producirse un error o un tiempo de espera en este procedimiento almacenado. El host de recursos también detiene su propio subproceso de renovación de concesión durante la llamada sin conexión. En el peor de los casos, SQL Server hace que la concesión caduque en ½ * LeaseTimeout y cambiará la instancia a un estado de resolución. Las conmutaciones por error pueden iniciarlas varias entidades diferentes, pero es sumamente importante que la vista del estado del clúster sea coherente en todo el clúster y en todas las instancias de SQL Server. Por ejemplo, imagine un caso en el que la instancia principal pierde la conexión con el resto del clúster. Cada nodo de clúster determina un error en momentos parecidos debido a los valores de tiempo de espera del clúster, pero solo el nodo principal puede interactuar con la instancia principal de SQL Server para obligarlo a abandonar el rol principal.
Desde la perspectiva del nodo principal, el servicio de clúster perdió el quórum y el propio servicio empieza el proceso de finalización. El servicio de clúster emite una llamada RPC al host de recursos para finalizar el proceso. Esta llamada de finalización se encarga de poner el grupo de disponibilidad sin conexión en la instancia de SQL Server. Esta llamada sin conexión se realiza a través de T-SQL, pero no es posible garantizar que se establecerá correctamente la conexión entre SQL y la DLL de recursos.
Desde la perspectiva del resto del clúster, actualmente no hay ninguna réplica principal y se vota y establece un nuevo elemento principal único en el resto de los nodos del clúster. Si se produce un error o un tiempo de espera en el procedimiento almacenado llamado por la DLL de recursos, el clúster podría ser susceptible de caer en un escenario de cerebro dividido.
El tiempo de espera de concesión evita los casos de cerebro dividido frente a errores de comunicación. Incluso si se produce un error en todas las comunicaciones, el proceso de la DLL de recursos finalizará y no podrá actualizar la concesión. Una vez que expire la concesión, pone al grupo de disponibilidad sin conexión por su cuenta. La instancia de SQL Server debe tener en cuenta que ya no hospeda la réplica principal antes de que el clúster establezca una nueva. Como el resto del clúster, que es responsable de elegir una nueva réplica principal, no tiene ningún medio para coordinarse con la réplica principal actual, los valores de tiempo de espera garantizan que no se establecerá una nueva réplica principal antes de que la réplica principal actual se ponga a sí misma sin conexión.
Cuando se produce una conmutación por error en el clúster, la instancia de SQL Server que hospeda la réplica principal anterior debe realizar la transición a un estado de resolución antes de que la nueva réplica principal se ponga en línea. El subproceso de concesión de SQL Server en cualquier punto tiene un período de vida de ½ * LeaseTimeout, porque cada vez que se renueva la concesión, el nuevo período de vida se actualiza a LeaseInterval o ½ * LeaseTimeout. Si el servicio de clúster o el host de recursos se detiene o se cierra sin señalar el evento de detención de concesión, el clúster declarará que el nodo principal está inactivo después de SameSubnetThreshold\ SameSubnetDelay milisegundos. Durante este intervalo de tiempo, la concesión debe expirar para garantizar que el nodo principal esté sin conexión. Como el período de vida máximo para el tiempo de expiración de concesión es de ½ * LeaseTimeout, ½ * LeaseTimeout debe ser menor que SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold \<= CrossSubnetThreshold y SameSubnetDelay \<= CrossSubnetDelay deben ser true en todos los clústeres de SQL Server.
Operación de tiempo de espera de comprobación de estado
El tiempo de espera de comprobación de estado es más flexible porque ningún otro mecanismo de conmutación por error depende directamente de él. El valor predeterminado de 30 segundos establece el intervalo de sp_server_diagnostics en 10 segundos, con un valor mínimo de 15 segundos para el tiempo de espera y un intervalo de 5 segundos. Por lo general, el intervalo de actualización sp_server_diagnostics siempre es de 1/3 * HealthCheckTimeout. Cuando la DLL de recursos no recibe un nuevo conjunto de datos de mantenimiento en un intervalo, sigue usando los datos de mantenimiento del intervalo anterior para determinar el estado de la instancia y el grupo de disponibilidad actuales. Si se aumenta el valor de tiempo de espera de comprobación de mantenimiento, el nodo principal es más tolerante a la presión de la CPU, lo que puede impedir a sp_server_diagnostics proporcionar nuevos datos en cada intervalo, aunque depende de comprobaciones de estado de datos no actualizados durante más tiempo. Independientemente del valor de tiempo de espera, una vez que se reciben los datos que indican que la réplica no es correcta, la siguiente llamada a IsAlive devolverá que la instancia es incorrecta y el servicio de clúster iniciará una conmutación por error.
El nivel de condición de error del grupo de disponibilidad cambia las condiciones de error para la comprobación de estado. Para cualquier nivel de error, si sp_server_diagnostics notifica que el elemento del grupo de disponibilidad es incorrecto, se produce un error en la comprobación de estado. Cada nivel hereda todas las condiciones de error de los niveles inferiores.
| Nivel | Condición en la que la instancia se considera inactiva |
|---|---|
| 1: OnServerDown | La comprobación de estado no realiza ninguna acción si se produce un error en algún recurso además del grupo de disponibilidad. Si los datos del grupo de disponibilidad no se reciben en intervalos de 5 o 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | Si no se reciben datos de sp_server_diagnostics para HealthCheckTimeout |
| 3: OnCriticalServerError | (Valor predeterminado) Si el componente del sistema informa de un error |
| 4: OnModerateServerError | Si el componente de recurso informa de un error |
| 5: En Cualquier Condición de Fallo Calificada | Si el componente de procesamiento de consultas informa de un error |
Actualización de valores de tiempo de espera del clúster y siempre activa
Valores del clúster
Hay cuatro valores de la configuración de WSFC que son responsables de determinar los valores de tiempo de espera del clúster:
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
Los valores de retraso determinan el tiempo de espera entre los latidos del servicio de clúster y los valores de umbral establecen el número de latidos que no pueden recibir ninguna confirmación del nodo de destino o el recurso antes de que el clúster declare el objeto como inactivo. Si no hay ningún latido correcto entre los nodos de la misma subred durante más de SameSubnetDelay \* SameSubnetThreshold milisegundos, se determina que el nodo está inactivo. Ocurre lo mismo con la comunicación entre varias subredes que usa valores entre varias subredes.
Para obtener una lista de todos los valores del clúster actual, en cualquier nodo de clúster de destino, abra un terminal de PowerShell con privilegios elevados. Ejecute el siguiente comando:
Get-Cluster | fl *
Para actualizar cualquiera de estos valores, ejecute este comando en un terminal de PowerShell con privilegios elevados:
(Get-Cluster).<ValueName> = <NewValue>
Al aumentar el producto de Delay * Threshold para que el tiempo de espera del clúster sea más tolerante, es más eficaz aumentar en primer lugar el valor de retraso antes de aumentar el umbral. Al aumentar el retraso, se aumenta el tiempo entre cada latido. Cuanto más tiempo haya entre latidos, más tiempo habrá para que los problemas de red transitorios se resuelvan por sí mismos y se reduzca la congestión de la red en relación con el envío de más latidos en el mismo período.
Tiempo de espera de concesión
El mecanismo de concesión se controla mediante un único valor específico para cada grupo de disponibilidad en un clúster de WSFC. Un tiempo de espera de concesión puede dar lugar a los errores siguientes:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
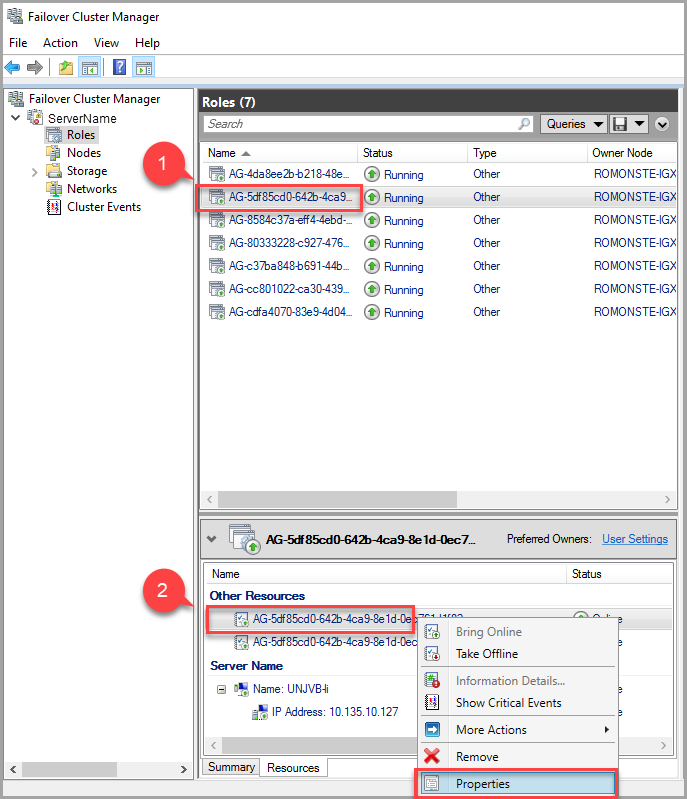
Para modificar el valor de tiempo de espera de concesión, use el Administrador de clústeres de conmutación por error y siga estos pasos:
En la pestaña Roles, busque el rol del grupo de disponibilidad de destino. Seleccione el rol del grupo de disponibilidad de destino.
Haga clic con el botón derecho en el recurso del grupo de disponibilidad en la parte inferior de la ventana y seleccione Propiedades.
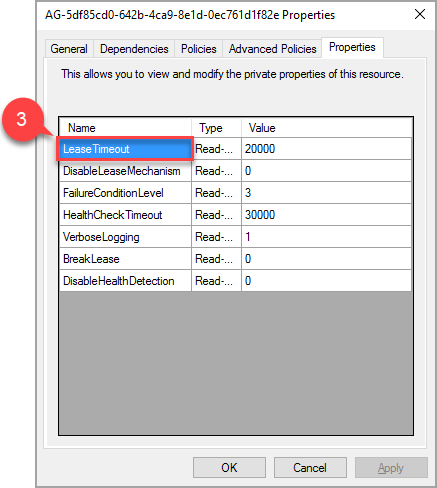
En la ventana emergente, vaya a la pestaña Propiedades para visualizar una lista de valores específicos de este grupo de disponibilidad. Seleccione el valor de LeaseTimeout para cambiarlo.
Según la configuración del grupo de disponibilidad, es posible que haya recursos adicionales para los agentes de escucha, los discos compartidos, los recursos compartidos de archivos, etc., ya que estos recursos no requieren ninguna configuración adicional.
Nota:
El nuevo valor de la propiedad "LeaseTimeout" se aplicará después de que el recurso se desconecte y vuelva a conectarse.
Valores de comprobación de mantenimiento
Dos valores controlan la comprobación de estado de Always On: FailureConditionLevel y HealthCheckTimeout. FailureConditionLevel indica el nivel de tolerancia a determinadas condiciones de error indicado por sp_server_diagnostics y HealthCheckTimeout configura el tiempo que la DLL de recursos puede estar sin recibir una actualización de sp_server_diagnostics. El intervalo de actualización de sp_server_diagnostics siempre es HealthCheckTimeout/3.
Para configurar el nivel de condición de conmutación por error, use la opción FAILURE_CONDITION_LEVEL = <n> de la instrucción CREATE o ALTERAVAILABILITY GROUP, donde <n> es un entero entre 1 y 5. El siguiente comando establece el nivel de condición de error en 1 para el grupo de disponibilidad “AG1”:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Para configurar el tiempo de expiración de comprobación de estado, use la opción HEALTH_CHECK_TIMEOUT de las instrucciones CREATE o ALTERAVAILABILITY GROUP. El siguiente comando establece el tiempo de espera de comprobación de estado en 60 000 milisegundos para el grupo de disponibilidad AG1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Resumen de las instrucciones de tiempo de espera
No se recomienda reducir los valores de tiempo de espera por debajo de sus valores predeterminados.
El intervalo de concesión (½ * LeaseTimeout) debe ser inferior a SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold < = CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Configuración de tiempo de espera | Propósito | Entre las | Usos | IsAlive y LooksAlive | Causas | Resultado |
|---|---|---|---|---|---|---|
| Tiempo de espera de concesión Valor predeterminado: 20000 |
Evita la división de cerebro | Principal a clúster (HADR) |
Objetos de eventos de Windows | Usado en ambas | Falta de respuesta del sistema operativo, memoria virtual baja, paginación del espacio de trabajo, generación de volcado de memoria, CPU fijado, WSFC fuera de servicio (pérdida de cuórum) | Recurso de grupo de disponibilidad sin conexión-en línea, conmutación por error |
| Tiempo de espera de sesión Valor predeterminado: 10000 |
Informar de problema de comunicación entre réplica principal y secundaria | Secundaria a principal (HADR) |
Sockets de TCP (mensajes enviados a través del extremo DBM) | No se usa en ninguna | Comunicación de red, Problemas en la réplica secundaria: fuera de servicio, falta de respuesta del SO, contención de recursos |
Secundaria - DESCONECTADA |
| Tiempo de espera de HealthCheck Valor predeterminado: 30000 |
Indicar el tiempo de espera al intentar determinar el estado de la réplica principal | Clúster a principal (FCI & HADR) |
Sp_server_diagnostics de T-SQL | Usado en ambas | Cumple las condiciones de error, falta de respuesta del sistema operativo, memoria virtual baja, reducción de espacio de trabajo, generación de volcado de memoria, WSFC (pérdida de cuórum), problemas del programador (programadores bloqueados) | Recursos de grupo de disponibilidad sin conexión y en línea o conmutación por error, reinicio o conmutación por error de FCI |