Supervisión del rendimiento para grupos de disponibilidad Always On
Se aplica a: ![]() SQL Server
SQL Server
El rendimiento de los grupos de disponibilidad Always On es vital para mantener el contrato de nivel de servicio (SLA) de las bases de datos de críticas. La comprensión de cómo envían los registros los grupos de disponibilidad a las réplicas secundarias puede ayudar a estimar el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) de la implementación de disponibilidad y a identificar cuellos de botella en grupos de disponibilidad o réplicas con un mal rendimiento. En este artículo se explica el proceso de sincronización, se muestra cómo calcular algunas de las métricas clave y se proporcionan vínculos a algunos de los escenarios de solución de problemas de rendimiento comunes.
Proceso de sincronización de datos
Para estimar el tiempo necesario para una sincronización completa e identificar el cuello de botella, debe comprender el proceso de sincronización. Un cuello de botella de rendimiento puede estar en cualquier fase del proceso; su detección puede ayudar a profundizar en los problemas subyacentes. En la ilustración y la tabla siguientes se muestra el proceso de sincronización de datos:

| Secuencia | Descripción del paso | Comentarios | Métricas de utilidad |
|---|---|---|---|
| 1 | Generación de registro | Los datos del registro se vacían en el disco. Este registro se debe replicar en las réplicas secundarias. Las entradas del registro entran en la cola de envío. | SQL Server: Base de datos > Bytes de registro vaciados/s |
| 2 | Capturar | Los registros de cada base de datos se capturan y se envían a la cola de asociado correspondiente (uno por par de réplica de base de datos). Este proceso de captura se ejecuta de forma continua siempre que la réplica de disponibilidad esté conectada y no se suspenda el movimiento de datos por algún motivo; el par de réplica de base de datos se muestra como Sincronizando o Sincronizado. Si el proceso de captura no es capaz de examinar y poner en cola los mensajes con la suficiente rapidez, la cola de envío de registros se acumula. | SQL Server: Réplica de disponibilidad > Bytes enviados a la réplica\s, que es una agregación de la suma de todos los mensajes de la base de datos en cola para esa réplica de disponibilidad. log_send_queue_size (KB) y log_bytes_send_rate (KB/s) en la réplica principal. |
| 3 | Envío | Los mensajes de cada cola de réplica de base de datos se quitan de la cola y se envían a través de la conexión a la réplica secundaria correspondiente. | SQL Server: réplica de disponibilidad > Bytes enviados al transporte\s |
| 4 | Recepción y almacenamiento en caché | Cada réplica secundaria recibe y almacena en caché el mensaje. | Contador de rendimiento SQL Server: Réplica de disponibilidad > Bytes de registro recibidos/s |
| 5 | Protección | El registro se vacía en la réplica secundaria para su protección. Tras el vaciado del registro, se envía una confirmación a la réplica principal. Una vez protegido el registro, se evita la pérdida de datos. |
Contador de rendimiento SQL Server: Base de datos > Bytes de registro vaciados/s Tipo de espera HADR_LOGCAPTURE_SYNC |
| 6 | Rehacer | Las páginas vaciadas se ponen al día en la réplica secundaria. Las páginas se mantienen en la cola de puesta al día mientras esperan. | SQL Server: Réplica de base de datos > Bytes puestos al día/s redo_queue_size (KB) y redo_rate. Tipo de espera REDO_SYNC |
Puertas de control de flujo
Los grupos de disponibilidad se diseñan con puertas de control de flujo en la réplica principal para evitar un uso excesivo de recursos, por ejemplo de red y memoria, en todas las réplicas de disponibilidad. Estas puertas de control de flujo no afectan al estado de sincronización de las réplicas de disponibilidad, pero sí pueden hacerlo al rendimiento general de las bases de datos de disponibilidad, incluido el RPO.
Una vez capturados los registros en la réplica principal, están sujetos a dos niveles de control de flujo. Una vez que se alcanza el umbral de mensajes de cualquier puerta, los mensajes de registro ya no se envían a una réplica determinada ni para una base de datos concreta. Los mensajes pueden enviarse una vez que se reciben los mensajes de confirmación de los mensajes enviados, a fin de reducir el número de mensajes enviados por debajo del umbral.
Además de las puertas de control de flujo, hay otro factor que puede evitar que los mensajes de registro se envíen. La sincronización de réplicas garantiza que los mensajes se envíen y se apliquen en el orden de los números de secuencia de registro (LSN). Antes de enviar un mensaje de registro, también se compara su LSN con el LSN confirmado más bajo para asegurarse de que es menor que uno de los umbrales (según el tipo de mensaje). Si la diferencia entre los dos LSN es mayor que el umbral, los mensajes no se envían. Una vez que la diferencia vuelve a estar por debajo del umbral, se envían los mensajes.
SQL Server 2022 aumenta los límites del número de mensajes que admite cada puerta. Con la marca de seguimiento 12310, el límite aumentado también está disponible para las siguientes versiones de SQL Server, a partir de: SQL Server 2019 CU9, SQL Server 2017 CU18 y SQL Server 2016 SP1 CU16.
En la tabla siguiente se comparan los límites de mensajes:
SQL Server 2022 y versiones compatibles de SQL Server (a partir de SQL Server 2019 CU9, SQL Server 2017 CU18 y SQL Server 2016 SP1 CU16) que habilitan la marca de seguimiento 12310; consulte los límites siguientes:
| Nivel | Número de puertas | Número de mensajes | Métricas de utilidad |
|---|---|---|---|
| Transporte | 1 por réplica de disponibilidad | 16384 | Evento extendido database_transport_flow_control_action |
| Base de datos | 1 por base de datos de disponibilidad | 7168 | DBMIRROR_SEND Evento extendido hadron_database_flow_control_action |
Dos útiles contadores de rendimiento, SQL Server: Réplica de disponibilidad > Control de flujo/s y SQL Server: Réplica de disponibilidad > Tiempo de control de flujo (ms/s), muestran, durante el último segundo, cuántas veces se ha activado el control de flujo y cuánto tiempo se ha esperado en el control de flujo. Un mayor tiempo de espera en el control de flujo se traduce en un RPO superior. Para más información sobre los tipos de problemas que pueden dar lugar a un tiempo de espera elevado en el control de flujo, vea Solución de problemas: el grupo de disponibilidad superó el RPO.
Estimación del tiempo de conmutación por error (RTO)
El RTO del SLA depende del tiempo de conmutación por error de la implementación de Always On en un momento dado, que se puede expresar en la siguiente fórmula:

Importante
Si un grupo de disponibilidad contiene más de una base de datos de disponibilidad, aquella con el valor Tfailover más alto se convierte en el valor límite para el cumplimiento del RTO.
El tiempo de detección de errores, Tdetection, es el tiempo que tarda el sistema en detectar el error. Este tiempo depende de la configuración del clúster y no de las réplicas de disponibilidad individuales. Según la condición de conmutación automática por error configurada, una conmutación por error se puede desencadenar como una respuesta inmediata a un error interno de SQL Server crítico, como un bloqueo por subproceso huérfano. En este caso, la detección puede ser tan rápida como tarda en enviarse el informe de error sp_server_diagnostics (Transact-SQL) al clúster WSFC (el intervalo predeterminado es 1/3 del tiempo de espera de comprobación de estado). Una conmutación por error también se puede desencadenar debido a un tiempo de espera, por ejemplo, cuando el tiempo de espera de comprobación de estado del clúster ha expirado (30 segundos de forma predeterminada) o la concesión entre la DLL del recurso y la instancia de SQL Server ha expirado (20 segundos de forma predeterminada). En este caso, el tiempo de detección es tan largo como el intervalo de tiempo de espera. Para obtener más información, vea Directiva de conmutación por error flexible para conmutación automática por error de un grupo de disponibilidad (SQL Server).
Lo único que la réplica secundaria tiene que hacer para prepararse para una conmutación por error es que la fase de puesta al día alcance el final del registro. El tiempo de fase de puesta al día, Tredo, se calcula mediante la siguiente fórmula:

donde redo_queue es el valor de redo_queue_size y redo_rate es el valor de redo_rate.
El tiempo de sobrecarga de conmutación por error, Toverhead, incluye el tiempo necesario para conmutar por error el clúster WSFC y poner en línea las bases de datos. Este tiempo suele ser breve y constante.
Estimación de la posible pérdida de datos (RPO)
El RPO del SLA depende de la posible pérdida de datos de la implementación de Always On en un momento dado. Esta posible pérdida de datos se puede expresar en la siguiente fórmula:

donde log_send_queue es el valor de log_send_queue_size y log generation rate es el valor de SQL Server: Base de datos > Bytes de registro vaciados/s.
Advertencia
Si un grupo de disponibilidad contiene más de una base de datos de disponibilidad, aquella con el valor Tdata_loss más alto se convierte en el valor límite para el cumplimiento del RPO.
La cola de envío de registro representa todos los datos que se pueden perder a causa de un error irrecuperable. A primera vista, es curioso que se use la velocidad de generación de registro en lugar de la velocidad de envío de registro (vea log_send_rate). Pero recuerde que el uso de la velocidad de envío de registro solo proporciona el tiempo de sincronización, mientras que el RPO mide la pérdida de datos en función de la velocidad de generación, no la rapidez con que se sincroniza.
Una manera más sencilla de estimar Tdata_loss es usar last_commit_time. La DMV de la réplica principal notifica este valor para todas las réplicas. Puede calcular la diferencia entre el valor de la réplica principal y el de la réplica secundaria para estimar la velocidad con que el registro de la réplica secundaria alcanza a la réplica principal. Como se ha mencionado anteriormente, este cálculo no indica la posible pérdida de datos en función de la velocidad con que se genera el registro, aunque debería ser una buena aproximación.
Estimación de RTO y RPO con el panel SSMS
En los grupos de disponibilidad Always On, el RTO y RPO se calculan y se muestran para las bases de datos hospedadas en las réplicas secundarias. En el panel de la réplica principal, el RTO y RPO se agrupan por la réplica secundaria.
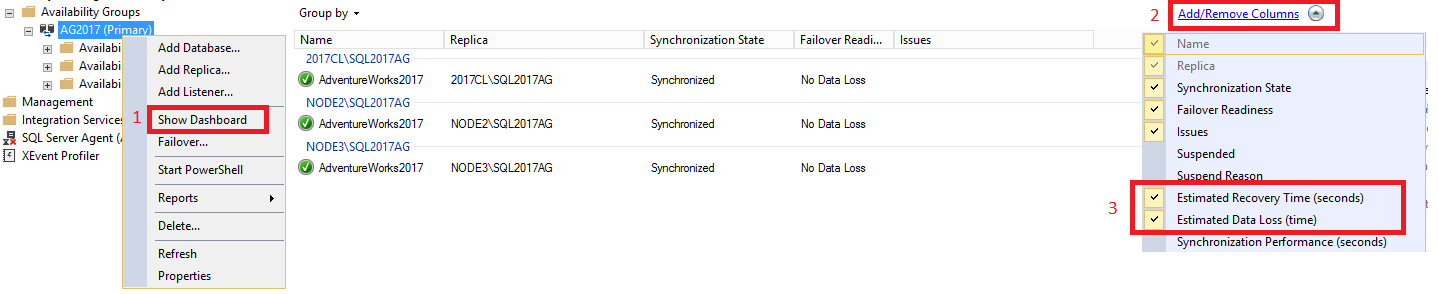
Para ver el RTO y RPO en el panel, siga estos pasos:
En SQL Server Management Studio, expanda el nodo Alta disponibilidad de Always On, haga clic con el botón derecho en el nombre del grupo de disponibilidad y seleccione Mostrar panel.
Seleccione Agregar o quitar columnas en la pestaña Agrupar por. Active Tiempo de recuperación calculado (segundos) [RTO] y Pérdida de datos calculada (tiempo) [RPO].
Cálculo del RTO de la base de datos secundaria
El cálculo del tiempo de recuperación determina cuánto tiempo se necesita para recuperar la base de datos secundaria después de que s e produzca una conmutación por error. El tiempo de conmutación por error suele ser breve y constante. El tiempo de detección depende de la configuración del clúster y no de las réplicas de disponibilidad individuales.
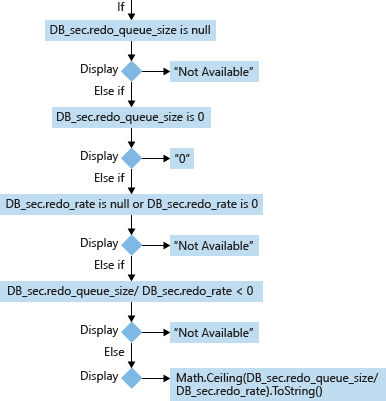
Para una base de datos secundaria (DB_sec), el cálculo y la presentación de su RTO se basan en sus valores redo_queue_size y redo_rate:
Salvo en casos excepcionales, la fórmula para calcular el RTO de la base de datos secundaria es la siguiente:
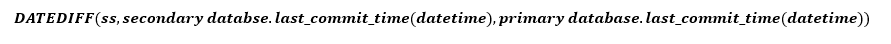
Cálculo del RPO de la base de datos secundaria
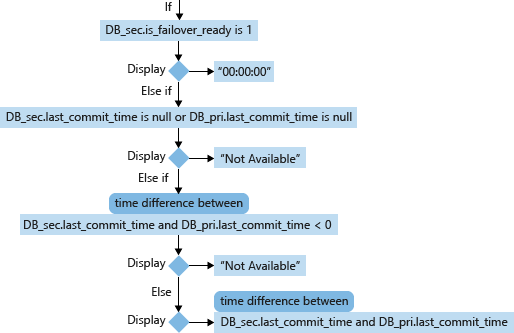
Para una base de datos secundaria (DB_sec), el cálculo y la presentación de su RPO se basa en los valores is_failover_ready, last_commit_time y last_commit_time de su base de datos principal correlacionada (DB_pri). Cuando en la base de datos secundaria is_failover_ready = 1, se sincroniza daa y no se produce pérdida de datos tras la conmutación por error. Pero si este valor es 0, hay una diferencia entre el valor last_commit_time de la base de datos principal y el valor last_commit_time de la base de datos secundaria.
Para la base de datos principal, el valor last_commit_time es la hora de confirmación de la transacción más reciente. Para la base de datos secundaria, el valor last_commit_time es la hora de confirmación más reciente de la transacción en la base de datos principal que también se ha protegido correctamente en la base de datos secundaria. Este número debe ser el mismo para la base de datos principal y la secundaria. Una diferencia entre estos dos valores es la duración en la que las transacciones pendientes no se han protegido en la base de datos secundaria y se perderán si se produce una conmutación por error.
Contadores de rendimiento que se usan en las fórmulas de RTO/RPO
- redo_queue_size (KB) [se usa en el RTO]: el tamaño de cola de fase de puesta al día es el tamaño de los registros de transacciones entre sus valores last_received_lsn y last_redone_lsn. last_received_lsn es el identificador de bloque de registro que identifica el punto en el que todos los bloques de registro han sido recibidos por la réplica secundaria en la que se hospeda esta base de datos secundaria. Last_redone_lsn es el número de secuencia de registro real de la última entrada de registro que se rehízo en la base de datos secundaria. En función de estos dos valores, se pueden encontrar los identificadores del bloque de registro inicial (last_received_lsn) y el bloque de registro final (last_redone_lsn). El espacio entre estos dos bloques de registro puede representar la cantidad de bloques de registro de transacciones que todavía no se han puesto al día. Esto se mide en kilobytes (KB).
- redo_rate (KB/s) [se usa en el RTO]: un valor acumulativo que representa, en un período de tiempo transcurrido, qué cantidad del registro de transacciones (KB) se ha puesto al día en la base de datos secundaria, expresada en kilobytes (KB)/segundo.
- last_commit_time (Datetime) [se usa en el RPO]: para la base de datos principal, last_commit_time es la hora de confirmación de la transacción más reciente. Para la base de datos secundaria, el valor last_commit_time es la hora de confirmación más reciente de la transacción en la base de datos principal que también se ha protegido correctamente en la base de datos secundaria. Como en la base de datos secundaria este valor se debe sincronizar con el mismo valor de la principal, cualquier diferencia entre estos dos valores es la estimación de la pérdida de datos (RPO).
Estimación de RTO y RPO mediante DMV
Se pueden consultar las DMV sys.dm_hadr_database_replica_states y sys.dm_hadr_database_replica_cluster_states para calcular el RPO y RTO de una base de datos. Las consultas siguientes crean procedimientos almacenados que realizan las dos operaciones.
Nota
Asegúrese de crear y ejecutar el procedimiento almacenado para estimar el RTO en primer lugar, ya que los valores que genera son necesarios para ejecutar el procedimiento almacenado para calcular el RPO.
Creación de un procedimiento almacenado para calcular el RTO
- En la réplica secundaria de destino, cree el procedimiento almacenado proc_calculate_RTO. Si este procedimiento almacenado ya existe, primero debe eliminarlo y después volver a crearlo.
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- Ejecute proc_calculate_RTO con el nombre de la base de datos secundaria de destino:
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
En la salida se muestra el valor de RTO de la base de datos de réplica secundaria de destino. Guarde los valores group_id, replica_id y group_database_id para usarlos con el procedimiento almacenado de estimación del RPO.
Salida del ejemplo:
RTO of Database DB_sec' is 0
group_id of Database DB4 is F176DD65-C3EE-4240-BA23-EA615F965C9B
replica_id of Database DB4 is 405554F6-3FDC-4593-A650-2067F5FABFFD
group_database_id of Database DB4 is 39F7942F-7B5E-42C5-977D-02E7FFA6C392
Creación de un procedimiento almacenado para calcular el RPO
- En la réplica principal, cree el procedimiento almacenado proc_calculate_RPO. Si ya existe, primero debe eliminarlo y, después, volver a crearlo.
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- Ejecute proc_calculate_RPO con los valores group_id, replica_id y group_database_id de la base secundaria de destino.
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- En la salida se muestra el valor de RPO de la base de datos de réplica secundaria de destino.
Supervisión de RTO y RPO
En esta sección se muestra cómo supervisar las métricas RTO y RPO de los grupos de disponibilidad. Esta demostración es similar al tutorial de GUI proporcionado en The Always On health model, part 2: Extending the health model (El modelo de estado de Always On, parte 2: extensión del modelo de estado).
Se proporcionan elementos de los cálculos de tiempo de conmutación por error y de posible pérdida de datos de Estimación del tiempo de conmutación por error (RTO) y Estimación de la posible pérdida de datos (RPO) como métricas de rendimiento de la faceta de administración de directivas Estado de réplica de base de datos (vea Ver las facetas de administración basada en directivas en un objeto de SQL Server). Puede supervisar estas dos métricas según una programación y recibir alertas cuando superen el RTO y el RPO, respectivamente.
Los scripts que se muestran crean dos directivas del sistema que se ejecutan según sus respectivas programaciones, con las siguientes características:
Una directiva de RTO que da error cuando el tiempo estimado de conmutación por error supera los 10 minutos, evaluado cada 5 minutos
Una directiva de RPO que da error cuando la pérdida de datos estimada supera 1 hora, evaluada cada 30 minutos
Las dos directivas tienen una configuración idéntica en todas las réplicas de disponibilidad
Las directivas se evalúan en todos los servidores, pero solo en los grupos de disponibilidad cuya réplica de disponibilidad local es la réplica principal. Si la réplica de disponibilidad local no es la réplica principal, las directivas no se evalúan.
Los errores de las directivas se muestran en el panel Always On cuando se abre en la réplica principal.
Para crear las directivas, siga las instrucciones siguientes en todas las instancias de servidor que participen en el grupo de disponibilidad:
Inicie el servicio Agente SQL Server si aún no se ha iniciado.
En SQL Server Management Studio, en el menú Herramientas, haga clic en Opciones.
En la pestaña SQL Server Always On, seleccione Habilitar directiva Always On definida por el usuario y haga clic en Aceptar.
Esta configuración permite mostrar las directivas personalizadas configuradas correctamente en el panel Always On.
Cree una condición de administración basada en directivas con las especificaciones siguientes:
Nombre:
RTOFaceta:Estado de la réplica de base de datos
Campo:
Add(@EstimatedRecoveryTime, 60)Operador: <=
Valor:
600
Se produce un error en esta condición cuando el tiempo de conmutación por error posible supera los 10 minutos, incluida una sobrecarga de 60 segundos para la detección de errores y la conmutación por error.
Cree una segunda condición de administración basada en directivas con las especificaciones siguientes:
Nombre:
RPOFaceta:Estado de la réplica de base de datos
Campo:
@EstimatedDataLossOperador: <=
Valor:
3600
Se produce un error en esta condición cuando la posible pérdida de datos supera 1 hora.
Cree una tercera condición de administración basada en directivas con las especificaciones siguientes:
Nombre:
IsPrimaryReplicaFaceta:Grupo de disponibilidad
Campo:
@LocalReplicaRoleOperador: =
Valor:
Primary
Esta condición comprueba si la réplica de disponibilidad local de un grupo de disponibilidad determinado es la réplica principal.
Cree una directiva de administración basada en directivas con las especificaciones siguientes:
Página General:
Nombre:
CustomSecondaryDatabaseRTOCondición de comprobación:
RTOPara destinos:Cada DatabaseReplicaState en IsPrimaryReplica AvailabilityGroup
Esta configuración garantiza que la directiva se evalúe solo en los grupos de disponibilidad cuya réplica de disponibilidad local es la réplica principal.
Modo de evaluación:Al programar
Programación: CollectorSchedule_Every_5min
Habilitado: seleccionado
Página Descripción:
Categoría: Advertencias de base de datos de disponibilidad
Esta configuración permite que los resultados de evaluación de directivas se muestren en el panel Always On.
Descripción: La réplica actual tiene un RTO que supera los 10 minutos, asumiendo una sobrecarga de 1 minuto para la detección y la conmutación por error. Debe investigar los problemas de rendimiento en la instancia de servidor respectiva inmediatamente.
Texto para mostrar: RTO superado
Cree una segunda directiva de administración basada en directivas con las especificaciones siguientes:
Página General:
Nombre:
CustomAvailabilityDatabaseRPOCondición de comprobación:
RPOPara destinos:Cada DatabaseReplicaState en IsPrimaryReplica AvailabilityGroup
Modo de evaluación:Al programar
Programación: CollectorSchedule_Every_30min
Habilitado: seleccionado
Página Descripción:
Categoría: Advertencias de base de datos de disponibilidad
Descripción: La base de datos de disponibilidad ha superado el RPO de 1 hora. Debe investigar los problemas de rendimiento en las réplicas de disponibilidad inmediatamente.
Texto para mostrar: RPO superado
Al terminar se crean dos nuevos trabajos del Agente SQL Server, uno por programación de evaluación de directivas. Estos trabajos deben tener nombres que comiencen por syspolicy_check_schedule.
Puede ver el historial de trabajos para inspeccionar los resultados de la evaluación. Los errores de evaluación también se registran en el registro de aplicaciones de Windows (en el Visor de eventos) con el Id. de evento 34052. También puede configurar el Agente SQL Server para enviar alertas sobre los errores de directiva. Para obtener más información, vea Configurar alertas para notificar los errores de directiva a los administradores de directivas.
Escenarios de solución de problemas de rendimiento
En la tabla siguiente se enumeran los escenarios de solución de problemas relacionados con el rendimiento comunes.
| Escenario | Descripción |
|---|---|
| Solución de problemas: el grupo de disponibilidad superó el RTO | Después de una conmutación por error automática o una manual planeada sin pérdida de datos, el tiempo de conmutación por error supera el RTO. O bien, al estimar el tiempo de conmutación por error de una réplica secundaria de confirmación sincrónica (por ejemplo, un asociado de conmutación automática por error), descubre que supera el RTO. |
| Solución de problemas: el grupo de disponibilidad superó el RPO | Después de realizar una conmutación por error manual forzada, la pérdida de datos supera la RPO. O bien, al calcular la posible pérdida de datos de una réplica secundaria de confirmación asincrónica, descubre que supera la RPO. |
| Solución de problemas: cambios en la réplica principal que no se reflejan en la réplica secundaria | La aplicación cliente finaliza una actualización en la réplica principal correctamente, pero una consulta a la réplica secundaria muestra que el cambio no se ha reflejado. |
Eventos extendidos de utilidad
Los siguientes eventos extendidos son útiles al solucionar problemas de réplicas en estado Sincronizando.
| Nombre del evento | Category | Canal | réplica de disponibilidad |
|---|---|---|---|
| redo_caught_up | transacciones | Depurar | Secundario |
| redo_worker_entry | transacciones | Depurar | Secundario |
| hadr_transport_dump_message | alwayson |
Depurar | Principal |
| hadr_worker_pool_task | alwayson |
Depurar | Principal |
| hadr_dump_primary_progress | alwayson |
Depurar | Principal |
| hadr_dump_log_progress | alwayson |
Depurar | Principal |
| hadr_undo_of_redo_log_scan | alwayson |
Analíticos | Secundario |