Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server
SQL Server
En este artículo se presentan los conceptos centrales de Grupos de disponibilidad AlwaysOn para configurar y administrar uno o varios grupos de disponibilidad en la edición Enterprise de SQL Server. Para la edición Standard, revise Grupos de disponibilidad Always On básicos con una base de datos única.
La característica Grupos de disponibilidad AlwaysOn es una solución de alta disponibilidad y de recuperación ante desastres que proporciona una alternativa empresarial a la creación de reflejo de la base de datos. Los grupos de disponibilidad Always On maximizan la disponibilidad de un conjunto de bases de datos de usuario para una empresa. Un grupo de disponibilidad admite un entorno de conmutación por error para un conjunto discreto de bases de datos de usuario, conocido como bases de datos de disponibilidad, que realizan la conmutación por error conjuntamente. Un grupo de disponibilidad admite un conjunto de bases de datos principales de lectura y escritura y de uno a ocho conjuntos de bases de datos secundarias correspondientes. Opcionalmente, las bases de datos secundarias pueden estar disponibles para el acceso de solo lectura o para algunas operaciones de copia de seguridad.
Con SQL Server habilitado por Azure Arc, puedes ver los grupos de disponibilidad en Azure Portal.
Información general
Un grupo de disponibilidad admite un entorno replicado de un conjunto discreto de bases de datos de usuario, conocido como bases de datos de disponibilidad. Un grupo de disponibilidad se puede crear para alta disponibilidad (HA) o para el escalado de lectura. Un grupo de disponibilidad para alta disponibilidad es un grupo de bases de datos que realizan la conmutación por error conjuntamente. Un grupo de disponibilidad para escalado de lectura es un grupo de bases de datos que se copian en otras instancias de SQL Server para cargas de trabajo de solo lectura. Un grupo de disponibilidad admite un conjunto de bases de datos principales y entre uno y ocho conjuntos de las bases de datos secundarias correspondientes. Las bases de datos secundarias no son no son copias de seguridad. Continúe haciendo copias de seguridad periódicas de las bases de datos y de sus registros de transacciones.
Sugerencia
Puede crear cualquier tipo de copia de seguridad de una base de datos principal. También puede crear copias de seguridad de registros y copias de seguridad completas de solo copia de las bases de datos secundarias. Para más información, vea Descarga de copias de seguridad admitidas a las réplicas secundarias de un grupo de disponibilidad.
Cada conjunto de bases de datos de disponibilidad es hospedado por una réplica de disponibilidad. Existen dos tipos de réplicas de disponibilidad: una única réplica principal, que alberga las bases de datos principales, y entre una y ocho réplicas secundarias, cada una de las cuales alberga un conjunto de bases de datos secundarias y que puede ser el destino en caso de una eventual conmutación por error del grupo de disponibilidad. Un grupo de disponibilidad realiza la conmutación por error en el nivel de réplica de disponibilidad. Una réplica de disponibilidad proporciona redundancia solo en el nivel de base de datos del conjunto de bases de datos de un grupo de disponibilidad. Las conmutaciones por error no se deben a problemas de bases de datos, como, por ejemplo, a que una base de datos pase a ser sospechosa debido a la pérdida de un archivo de datos o a los daños de un registro de transacciones.
La réplica principal hace que las bases de datos principales estén disponibles para las conexiones de lectura/escritura que tienen como origen los clientes. La réplica principal envía las entradas del registro de transacciones de cada base de datos principal a todas las bases de datos secundarias. Este proceso, conocido como sincronización de datos, tiene lugar en el nivel de la base de datos. Cada una de las réplicas secundarias almacena en memoria caché las entradas del registro de transacciones (refuerza el registro) y las aplica a la base de datos secundaria correspondiente. La sincronización de datos se produce entre la base de datos principal y cada una de las bases de datos secundarias conectadas, independientemente de las demás bases de datos. Por lo tanto, una base de datos secundaria puede producir un error o suspenderse sin afectar a otras bases de datos secundarias, y una base de datos principal puede producir un error o suspenderse sin afectar a otras bases de datos principales.
Opcionalmente, puede configurar una o varias réplicas secundarias para que admitan acceso de solo lectura a las bases de datos secundarias y puede configurar las réplicas secundarias para que permitan copias de seguridad de las bases de datos secundarias.
SQL Server 2017 (14.x) introdujo dos arquitecturas diferentes para los grupos de disponibilidad. Los grupos de disponibilidad Always On proporcionan alta disponibilidad, recuperación ante desastres y equilibrado del escalado de lectura. Estos grupos de disponibilidad requieren un administrador de clústeres. En Windows, la característica de clústeres de conmutación por error proporciona el administrador de clústeres. En Linux, puede usar Pacemaker. La otra arquitectura es un grupo de disponibilidad de escalado de lectura. Un grupo de disponibilidad de escalado de lectura proporciona réplicas para las cargas de trabajo de solo lectura, pero no alta disponibilidad. En un grupo de disponibilidad de escalado de lectura, no hay ningún administrador de clústeres, ya que la conmutación por error no puede ser automática.
La implementación de grupos de disponibilidad Always On para alta disponibilidad en Windows necesita un clúster de conmutación por error de Windows Server (WSFC). Cada réplica de disponibilidad de un determinado grupo de disponibilidad debe residir en otro nodo del mismo WSFC. La única excepción es que mientras se migra a otro clúster de WSFC, un grupo de disponibilidad puede ocupar temporalmente dos clústeres.
Nota
Para más información sobre los grupos de disponibilidad en Linux, véase Grupos de disponibilidad para SQL Server en Linux (
En una configuración de alta disponibilidad, se crea un rol de clúster por cada grupo de disponibilidad que cree. El clúster de WSFC supervisa este rol para evaluar el estado de la réplica principal. El quorum para Grupos de disponibilidad AlwaysOn se basa en todos los nodos del clúster de WSFC independientemente de si un nodo de clúster determinado hospeda alguna réplica de disponibilidad. A diferencia de la creación de reflejo de la base de datos, no hay ningún rol de testigo en los grupos de disponibilidad Always On.
Nota
Para obtener información sobre la relación de los componentes Always On de SQL Server con el clúster de WSFC, vea Clústeres de conmutación por error de Windows Server con SQL Server.
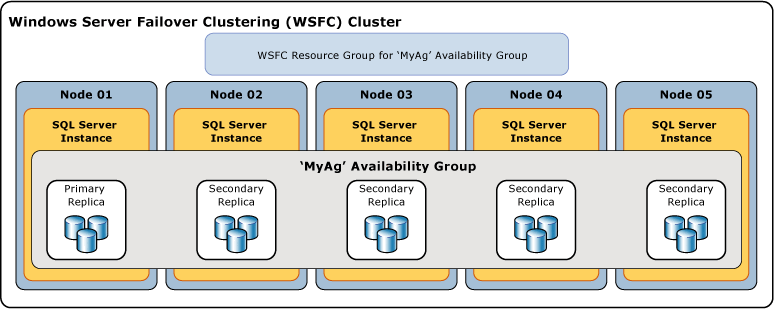
En la ilustración siguiente se muestra un grupo de disponibilidad que contiene solo una réplica principal y cuatro réplicas secundarias. Se admiten hasta ocho réplicas secundarias, incluidas una réplica principal y cuatro réplicas secundarias de confirmación sincrónica.
Configuración del cifrado TLS 1.3
SQL Server 2025 (17.x) introduce compatibilidad con Tabular Data Stream 8.0, lo que le permite aplicar el cifrado TLS 1.3 para la comunicación entre el clúster de conmutación por error de Windows Server y las réplicas del grupo de disponibilidad Always On.
Para obtener más información, vea Compatibilidad con TDS 8 en SQL Server 2025 más adelante en este artículo.
Para empezar, consulte Conexión con cifrado estricto.
Términos y definiciones
| Término | Descripción |
|---|---|
| grupo de disponibilidad | Contenedor para un conjunto de bases de datos, las bases de datos de disponibilidad, que conmutan por error juntas. |
| base de datos de disponibilidad | Base de datos que pertenece a un grupo de disponibilidad. Para cada base de datos de disponibilidad, el grupo de disponibilidad mantiene una sola copia de lectura y escritura (la base de datos principal) y de una a ocho copias de solo lectura (bases de datos secundarias). |
| base de datos principal. | Copia de lectura y escritura de una base de datos de disponibilidad. |
| base de datos secundaria | Una copia de solo lectura de una base de datos de disponibilidad. |
| réplica de disponibilidad | Una instancia de un grupo de disponibilidad que una instancia específica de SQL Server hospeda y que mantiene una copia local de cada base de datos de disponibilidad que pertenece al grupo de disponibilidad. Existen dos tipos de réplicas de disponibilidad: una sola réplica principal y de una a ocho réplicas secundarias. |
| réplica principal | La réplica de disponibilidad que hace que las bases de datos principales estén disponibles para las conexiones de lectura y escritura de clientes y, además, envía las entradas del registro de transacciones para cada base de datos principal a cada réplica secundaria. |
| réplica secundaria | Réplica de disponibilidad que mantiene una copia secundaria de cada base de datos de disponibilidad y actúa como posible destino de conmutación por error para el grupo de disponibilidad. Opcionalmente, una réplica secundaria puede admitir acceso de solo lectura a bases de datos secundarias y la creación de copias de seguridad de bases de datos secundarias. |
| escucha de grupo de disponibilidad | Nombre del servidor al que los clientes pueden conectarse para tener acceso a una base de datos en una réplica principal o secundaria de un grupo de disponibilidad. Los clientes de escucha del grupo de disponibilidad dirigen las conexiones entrantes a la réplica principal o una réplica secundaria de solo lectura. |
Bases de datos de disponibilidad
Para agregar una base de datos a un grupo de disponibilidad, la base de datos debe ser una base de datos de lectura/escritura en línea que exista en la instancia del servidor que hospeda la réplica principal. Al agregar una base de datos, se une al grupo de disponibilidad como base de datos principal, mientras permanece disponible para los clientes. No existe ninguna base de datos secundaria correspondiente hasta que restaure las copias de seguridad de la nueva base de datos principal en la instancia del servidor que hospeda la réplica secundaria (mediante RESTORE WITH NORECOVERY). La nueva base de datos secundaria se encuentra en el estado RESTORING hasta que se une al grupo de disponibilidad. Para más información, consulte Iniciar el movimiento de datos en una base de datos secundaria AlwaysOn (SQL Server).
La unión coloca la base de datos secundaria en el ONLINE estado e inicia la sincronización de datos con la base de datos principal correspondiente. La sincronización de datos es el proceso mediante el cual los cambios en una base de datos principal son copiados en una base de datos secundaria. La sincronización de datos implica que la base de datos principal envía entradas del registro de transacciones a la base de datos secundaria.
Importante
Una base de datos de disponibilidad a veces se denomina réplica de base de datos en los nombres de Objetos de administración de SQL Server (SMO), Transact-SQL y PowerShell. Por ejemplo, el término "réplica de base de datos" se usa en los nombres de las vistas de administración dinámicas de AlwaysOn que devuelven información sobre las bases de datos de disponibilidad: sys.dm_hadr_database_replica_states y sys.dm_hadr_database_replica_cluster_states. Pero en Libros en pantalla de SQL Server, el término "réplica" suele hacer referencia a las réplicas de disponibilidad. Por ejemplo, “replicación primaria” y “replicación secundaria” siempre hacen referencia a la disponibilidad de las réplicas.
Réplicas de disponibilidad
Cada grupo de disponibilidad define un conjunto de dos o más asociados de conmutación por error conocidos como réplicas de disponibilidad. Las réplicas de disponibilidad son componentes del grupo de disponibilidad. Cada réplica de disponibilidad hospeda una copia de las bases de datos de disponibilidad en el grupo de disponibilidad. Para un grupo de disponibilidad determinado, las instancias independientes de SQL Server que residen en distintos nodos de un clúster de WSFC deben hospedar las réplicas de disponibilidad. Cada una de estas instancias del servidor debe estar habilitada para AlwaysOn.
SQL Server 2019 (15.x) aumenta el número máximo de réplicas sincrónicas a 5, de las 3 que eran en SQL Server 2017 (14.x). Puede configurar este grupo de cinco réplicas para que tengan conmutación automática por error dentro del grupo. Hay una réplica principal, además de cuatro réplicas secundarias sincrónicas.
Una instancia determinada solo puede hospedar una única réplica de disponibilidad por grupo de disponibilidad. No obstante, puede usar cada instancia para muchos grupos de disponibilidad. Una instancia determinada puede ser una instancia independiente o una instancia de clúster de conmutación por error (FCI) de SQL Server. Si necesita redundancia de nivel de servidor, utilice instancias de clúster de conmutación por error.
A cada réplica de disponibilidad se le asigna un rol inicial, ya sea el rol principal o el rol secundario, que heredan las bases de datos de disponibilidad de esa réplica. El rol de una réplica dada determina si hospeda bases de datos de lectura/escritura o bases de datos de solo lectura. A una réplica, conocida como réplica principal, se le asigna el rol principal y hospeda bases de datos de lectura/escritura, que se denominan bases de datos principales. Como mínimo, a otra réplica denominada réplica secundariase le asigna el rol secundario. Una réplica secundaria hospeda bases de datos de solo lectura, conocidas como bases de datos secundarias.
Nota
Cuando el rol de una réplica de disponibilidad es indeterminado, como durante una conmutación por error, sus bases de datos se encuentran temporalmente en un NOT SYNCHRONIZING estado. Su función se establece en RESOLVING hasta que se resuelva la función de la réplica de disponibilidad. Si una réplica de disponibilidad se resuelve en el rol principal, sus bases de datos se convierten en las bases de datos principales. Si una réplica de disponibilidad se resuelve en el rol secundario, sus bases de datos se convierten en bases de datos secundarias.
Modos de disponibilidad
Cada réplica de disponibilidad tiene una propiedad de modo de disponibilidad. El modo de disponibilidad determina si la réplica principal espera a confirmar transacciones en una base de datos hasta que una réplica secundaria determinada escribe los registros de registro de transacciones en el disco (protege el registro). Los grupos de disponibilidad AlwaysOn admiten dos modos de disponibilidad: modo de confirmación asíncrona y modo de confirmación síncrona.
Modo de confirmación asíncrona.
Una réplica de disponibilidad que usa este modo de disponibilidad se conoce como réplica de confirmación asincrónica. En modo de confirmación asincrónica, la réplica principal confirma las transacciones sin esperar la confirmación de que las réplicas secundarias de confirmación asincrónica han protegido los registros de transacciones. El modo de confirmación asincrónica minimiza la latencia de las transacciones en las bases de datos secundarias pero permite que se retrasen detrás de las bases de datos principales, haciendo posible alguna pérdida de datos.
Modo de confirmación sincrónica
Una réplica de disponibilidad que usa este modo de disponibilidad se denomina réplica de confirmación sincrónica. En modo de confirmación síncrona, antes de confirmar transacciones, una réplica principal de este tipo espera a que una réplica secundaria con confirmación síncrona confirme que ha terminado de consolidar el registro. El modo de confirmación sincrónica asegura que, una vez que una base de datos secundaria se sincroniza con la base de datos principal, las transacciones confirmadas queden totalmente protegidas. Esta protección se produce a costa de que aumente la latencia de las transacciones. Opcionalmente, SQL Server 2017 (14.x) introdujo una característica de secundarias sincronizadas requeridas para aumentar aún más la seguridad a costa de la latencia cuando se desee. La
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITcaracterística se puede habilitar para requerir un número especificado de réplicas sincrónicas para confirmar una transacción antes de que se permita la confirmación de una réplica principal.
Para más información, véase Diferencias entre los modos de disponibilidad para un grupo de disponibilidad Always On.
Tipos de conmutación por error
Dentro del contexto de una sesión entre la réplica principal y una réplica secundaria, los roles principales y secundarios pueden cambiar en un proceso conocido como conmutación por error. Durante una conmutación por error, la réplica secundaria de destino pasa al rol principal y se convierte en la nueva réplica principal. La nueva réplica principal pone sus bases de datos en línea como bases de datos principales y las aplicaciones cliente pueden conectarse a ellas. Cuando la réplica principal anterior está disponible, cambia al rol secundario y se convierte en una réplica secundaria. Las bases de datos principales anteriores se convierten en bases de datos secundaria y se reanuda la sincronización de datos.
Un grupo de disponibilidad realiza la conmutación por error en el nivel de réplica de disponibilidad. Las conmutaciones por error no se producen debido a problemas de base de datos, como que una base de datos se vuelva sospechosa debido a la pérdida de un archivo de datos, la eliminación de una base de datos o la corrupción de un log de transacciones.
Existen tres formas de conmutación por error: automática, manual y forzada (con posible pérdida de datos). La forma o formas de conmutación por error que admite una réplica secundaria determinada depende de su modo de disponibilidad. Para el modo de confirmación sincrónica, también depende del modo de conmutación por error de la réplica principal y de la réplica secundaria de destino, como se indica a continuación.
El modo de confirmación sincrónica admite dos formas de conmutación por error: conmutación por error manual planeada y conmutación automática por error, si la réplica secundaria de destino está sincronizada actualmente con la réplica principal. El valor de la propiedad del modo de conmutación por error en los asociados de conmutación por error determina la compatibilidad con estas formas de conmutación por error. Si establece el modo de conmutación por error en manual en la réplica principal o secundaria, la réplica secundaria solo admite la conmutación por error manual. Si se establece el modo de conmutación por error en automático tanto en la réplica principal como en la secundaria, la réplica secundaria admite la conmutación por error tanto automática como manual.
Conmutación por error manual planificada (sin pérdida de datos)
Una conmutación por error manual se produce después de que un administrador de base de datos emite un comando de conmutación por error. Hace que una réplica secundaria sincronizada pase al rol principal (con protección de datos garantizada) y la réplica principal cambie al rol secundario. Una conmutación por error manual requiere que tanto la réplica principal como la réplica secundaria de destino se ejecuten en modo de confirmación sincrónica y la réplica secundaria ya debe estar sincronizada.
Conmutación automática por error (sin pérdida de datos)
Una conmutación automática por error se produce en respuesta a un error. Hace que una réplica secundaria sincronizada pase al rol principal (con protección de datos garantizada). Cuando la antigua réplica principal está disponible, cambia al rol secundario. La conmutación por error automática requiere que tanto la réplica primaria como la réplica secundaria de destino funcionen en modo de confirmación sincrónica, con el modo de conmutación por error configurado en Automático. Además, la réplica secundaria ya debe estar sincronizada, tener cuórum de WSFC y cumplir las condiciones especificadas por la directiva de conmutación por error flexible del grupo de disponibilidad.
En el modo de confirmación asincrónica, la única forma de conmutación por error es la conmutación por error manual forzada (con posible pérdida de datos), denominada normalmente conmutación por error forzada. La conmutación por error forzada es una forma de conmutación por error manual porque debe iniciarla manualmente. La conmutación por error forzada es una opción de recuperación ante desastres. Es la única forma de conmutación por error que es posible cuando la réplica secundaria de destino no está sincronizada con la réplica principal.
Para obtener más información, consulte Conmutación por error y modos de conmutación por error (grupos de disponibilidad Always On).
Importante
- Las instancias de clúster de conmutación por error (FCI) de SQL Server no admiten la conmutación automática por error por grupos de disponibilidad, por lo que solo puede configurar la conmutación por error manual para cualquier réplica de disponibilidad que hospede una FCI.
- Si emite un comando de conmutación por error forzada en una réplica secundaria sincronizada, la réplica secundaria se comportará igual que en el caso de una conmutación por error manual planeada.
Ventajas
Los grupos de disponibilidad Always On proporcionan un rico conjunto de opciones que mejoran la disponibilidad de la base de datos y el uso de los recursos. Los componentes clave son los siguientes:
Admite hasta nueve réplicas de disponibilidad. Una réplica de disponibilidad es una instancia de un grupo de disponibilidad que aloja una instancia específica de SQL Server. Mantiene una copia local de cada base de datos de disponibilidad que pertenece al grupo de disponibilidad. Cada grupo de disponibilidad admite una réplica principal y hasta ocho réplicas secundarias. Para más información, véase ¿Qué es un grupo de disponibilidad AlwaysOn?
Importante
Cada réplica de disponibilidad debe residir en otro nodo de un único clúster de clústeres de conmutación por error de Windows Server (WSFC). Para más información sobre los requisitos previos, las restricciones y las recomendaciones para los grupos de disponibilidad, consulte Requisitos previos, restricciones y recomendaciones para grupos de disponibilidad AlwaysOn.
Admite modos de disponibilidad alternativos como los siguientes:
Modo de confirmación asíncrona. Este modo de disponibilidad es una solución de recuperación de desastres que funciona bien cuando las réplicas de disponibilidad se distribuyen sobre distancias considerables.
Modo de confirmación síncrona Este modo de disponibilidad resalta alta disponibilidad y protección de datos del rendimiento, a costa de aumentar la latencia de las transacciones. Un grupo de disponibilidad determinado puede admitir hasta cinco réplicas de disponibilidad de confirmación sincrónica, incluida la réplica principal actual.
Para más información, véase Diferencias entre los modos de disponibilidad para un grupo de disponibilidad Always On.
Admite varias formas de conmutación por error de grupo de disponibilidad: conmutación por error automática, conmutación manual por error planeada (también conocida como conmutación por error manual) y conmutación manual por error forzada (también conocida como conmutación por error forzada). Para obtener más información, consulte Conmutación por error y modos de conmutación por error (grupos de disponibilidad Always On).
Permite configurar una réplica de disponibilidad determinada que admite una o dos de las funciones secundarias activas siguientes:
Acceso de conexión de solo lectura, que permite conexiones de solo lectura a la réplica para obtener acceso y leer sus bases de datos cuando se ejecuta como una réplica secundaria. Para obtener más información, consulte Descarga de cargas de trabajo de solo lectura a la réplica secundaria de un grupo de disponibilidad Always On.
Realizar operaciones de copia de seguridad en sus bases de datos cuando se ejecuta como una réplica secundaria. Para más información, vea Descarga de copias de seguridad admitidas a las réplicas secundarias de un grupo de disponibilidad.
Con capacidades secundarias activas se mejora la eficiencia de los procesos de TI y se reducen los costos mediante la mejor utilización de los recursos del hardware secundario. Además, la descarga de aplicaciones de lectura y trabajos de copia de seguridad en réplicas secundarias ayuda a mejorar el rendimiento de la réplica principal.
Admite una escucha de grupo de disponibilidad para cada grupo de disponibilidad. Una escucha de grupo de disponibilidad es un nombre de servidor al que los clientes se pueden conectar para acceder a una base de datos en una réplica principal o secundaria de un grupo de disponibilidad Always On. Los clientes de escucha del grupo de disponibilidad dirigen las conexiones entrantes a la réplica principal o una réplica secundaria de solo lectura. El cliente de escucha proporciona conmutación por error rápida de aplicaciones después de que se produzca la conmutación por error del grupo de disponibilidad. Para más información, vea Conexión a un agente de escucha de grupo de disponibilidad Always On.
Admite una directiva flexible de conmutación por error para un mayor control sobre una conmutación por error del grupo de disponibilidad. Para obtener más información, consulte Conmutación por error y modos de conmutación por error (grupos de disponibilidad Always On).
Admite la reparación automática de páginas para ofrecer protección frente al daño en las páginas. Para más información, vea Reparación de página automática (grupos de disponibilidad: creación de reflejo de la base de datos).
Admite el cifrado y compresión, que proporcionan un transporte seguro y de alto rendimiento.
Proporciona un conjunto integrado de herramientas para simplificar la implementación y administración de los grupos de disponibilidad, como:
Instrucciones DDL de Transact-SQL para crear y administrar grupos de disponibilidad. Para más información, véase Declaraciones Transact-SQL para grupos de disponibilidad Always On.
SQL Server Management Studio son las siguientes:
El Asistente para nuevo grupo de disponibilidad crea y configura un grupo de disponibilidad. En algunos entornos, este asistente puede también preparar automáticamente las bases de datos secundarias e iniciar la sincronización de datos de cada una de ellas. Para más información, vea Uso del cuadro de diálogo Nuevo grupo de disponibilidad (SQL Server Management Studio).
Agregar base de datos al asistente para grupo de disponibilidad agrega una o más bases de datos principales a un grupo de disponibilidad. En algunos entornos, este asistente puede también preparar automáticamente las bases de datos secundarias e iniciar la sincronización de datos de cada una de ellas. Para obtener más información, vea Agregar una base de datos a un grupo de disponibilidad AlwaysOn con el Asistente para grupos de disponibilidad.
Agregar réplica al asistente para grupo de disponibilidad agrega una o varias réplicas secundarias a un grupo de disponibilidad. En algunos entornos, este asistente puede también preparar automáticamente las bases de datos secundarias e iniciar la sincronización de datos de cada una de ellas. Para obtener más información, vea Agregar una réplica al grupo de disponibilidad AlwaysOn mediante el Asistente para grupos de disponibilidad en SQL Server Management Studio.
El Asistente para grupos de disponibilidad de conmutación por error inicia una conmutación manual en un grupo de disponibilidad. En función de la configuración y el estado de la réplica secundaria que especifique como destino de la conmutación por error, el asistente puede realizar una conmutación por error manual planeada o forzada. Para más información, consulte Usar el Asistente para grupo de disponibilidad de conmutación por error (SQL Server Management Studio).
En el panel Always On se supervisan los grupos de disponibilidad Always On, las réplicas de disponibilidad y las bases de datos de disponibilidad y se evalúan los resultados de las directivas de Always On. Para más información, véase Uso del panel de grupos de disponibilidad AlwaysOn (SQL Server Management Studio).
El panel Detalles del Explorador de objetos muestra información básica acerca de los grupos de disponibilidad existentes. Para más información, véase Usar la información del explorador de objetos para supervisar grupos de disponibilidad.
Cmdlets de PowerShell. Para más información, véase Información general sobre los cmdlets de PowerShell para grupos de disponibilidad AlwaysOn.
Conexiones de cliente
Puede proporcionar conectividad de cliente a la réplica principal de un grupo de disponibilidad determinado mediante la creación de una escucha de grupo de disponibilidad. Una escucha de grupo de disponibilidad proporciona un conjunto de recursos que se adjunta a un grupo de disponibilidad determinado para dirigir las conexiones de cliente a la réplica de disponibilidad adecuada.
Una escucha de grupo de disponibilidad está asociada a un nombre DNS único que actúa como un nombre de red virtual (VNN), una o más direcciones IP virtuales (VIP) y un número de puerto TCP. Para más información, vea Conexión a un agente de escucha de grupo de disponibilidad Always On.
Si un grupo de disponibilidad tiene solo dos réplicas de disponibilidad y no está configurado para permitir el acceso de lectura a la réplica secundaria, los clientes pueden conectarse a la réplica principal mediante una cadena de conexión de reflejo de base de datos
Compatibilidad con TDS 8 en SQL Server 2025
SQL Server 2025 (17.x) presenta compatibilidad con TDS 8.0, que permite aplicar cifrado TLS 1.3 estricto para las conexiones a las réplicas y el agente de escucha del grupo de disponibilidad AlwaysOn.
Requisitos de configuración:
-
Nuevos grupos de disponibilidad: Cree el AG con
Encrypt=Stricten la cláusulaCLUSTER_CONNECTION_OPTIONSy conmute para aplicar la configuración. -
Grupos de disponibilidad existentes: modifique el grupo de disponibilidad con
CLUSTER_CONNECTION_OPTIONSla cláusula para establecerEncrypt=Stricty la conmutación por error para aplicar la configuración. - Forzar cifrado estricto: establezca esta opción en Sí en el Administrador de configuración de SQL Server para cada réplica y reinicie las réplicas de SQL Server.
-
Requisitos de certificado: cuando
Encrypt=Strictse establece,TrustServerCertificatese omite.
Para empezar, consulte Conexión con cifrado estricto.
Réplicas secundarias activas
Los grupos de disponibilidad Always On admiten réplicas secundarias activas. Entre las funciones secundarias activas se incluye la compatibilidad con:
Realización de copias de seguridad en las réplicas secundarias
Las réplicas secundarias admiten la realización de copias de seguridad de registros y de solo copia de toda una base de datos, un archivo o un grupo de archivos. Puede configurar el grupo de disponibilidad para que se especifique la preferencia por la que las copias de seguridad deben realizarse. Es importante comprender que SQL Server no aplica la preferencia, por lo que no tiene ningún efecto en las copias de seguridad ad hoc. La interpretación de esta preferencia depende de la lógica, si existe, del script con los trabajos de copia de seguridad para cada una de las bases de datos de un grupo de disponibilidad dado. En el caso de una réplica de disponibilidad individual, puede especificar la prioridad para realizar copias de seguridad en esta réplica en relación con las otras réplicas del mismo grupo de disponibilidad. Para más información, vea Descarga de copias de seguridad admitidas a las réplicas secundarias de un grupo de disponibilidad.
Acceso de solo lectura a una o varias réplicas secundarias (réplicas secundarias legibles)
Puede configurar cualquier réplica de disponibilidad secundaria para permitir únicamente el acceso de lectura a sus bases de datos locales, aunque algunas operaciones no son totalmente compatibles. Esta configuración impide los intentos de conexión de lectura y escritura a la réplica secundaria. También es posible evitar cargas de trabajo de solo lectura en la réplica principal al permitir solo el acceso de lectura y escritura. Esta configuración impide que se realicen conexiones de solo lectura a la réplica principal. Para obtener más información, consulte Descarga de cargas de trabajo de solo lectura a la réplica secundaria de un grupo de disponibilidad Always On.
Si un grupo de disponibilidad tiene actualmente un escucha de grupo de disponibilidad y una o varias réplicas secundarias legibles, SQL Server puede enrutar las solicitudes de conexión con intención de lectura a una de ellas (enrutamiento de lectura solamente). Para más información, vea Conexión a un agente de escucha de grupo de disponibilidad Always On.
Período de tiempo de expiración de sesión
El período de tiempo de espera de sesión es una propiedad de réplica de disponibilidad que determina cuánto tiempo puede permanecer inactiva una conexión con otra réplica de disponibilidad antes de que se cierre la conexión. Las réplicas principales y secundarias hacen ping entre sí para indicar que siguen estando activas. Si se recibe un ping de otra réplica durante el tiempo de espera, significa que la conexión todavía está abierta y que las instancias del servidor se están comunicando. Al recibir un ping, una réplica de disponibilidad restablece el contador de tiempo de espera de la sesión de esa conexión.
El tiempo de espera de la sesión impide que una réplica espere indefinidamente a recibir un ping de la otra réplica. Si no se recibe ningún ping de la otra réplica dentro del período de tiempo de espera de la sesión, la réplica se agota. Su conexión se cierra y la réplica agotada entra en el estado DISCONNECTED. Aunque una replicación desconectada esté configurada en modo de confirmación síncrona, las transacciones no esperarán a que esa réplica vuelva a conectarse y sincronizarse.
El tiempo de expiración predeterminado de la sesión de cada réplica de disponibilidad es de 10 segundos. Puede configurar este valor, con un mínimo de 5 segundos. Por lo general, mantenga el período de tiempo de espera en 10 segundos o superior. Si establece el valor en menos de 10 segundos, existe la posibilidad de que un sistema sobrecargado declare un error falso.
Nota
En el rol de resolución, el tiempo de expiración de la sesión no se aplica, porque no se hace ping.
Reparación de página automática
Cada réplica de disponibilidad intenta la recuperación automática de las páginas dañadas en una base de datos local resolviendo ciertos tipos de errores que impiden la lectura de una página de datos. Si una réplica secundaria no puede leer una página, la réplica solicita una nueva copia de la página de la réplica principal. Si la réplica principal no puede leer una página, la réplica propaga una solicitud de una nueva copia a todas las réplicas secundarias y obtiene la página de la primera que responda. Si la solicitud se realiza correctamente, la copia sustituirá a la página que no se puede leer, de forma que se resuelve el error en la mayoría de los casos.
Para más información, vea Reparación de página automática (grupos de disponibilidad: creación de reflejo de la base de datos).
Interoperabilidad y coexistencia con otras funcionalidades del motor de base de datos
Los grupos de disponibilidad AlwaysOn funcionan con las siguientes características o componentes de SQL Server:
- ¿Qué es la captura de datos modificados (CDC)?
- Acerca del seguimiento de cambios (SQL Server)
- Bases de datos independientes
- Cifrado de datos transparente (TDE)
- Instantáneas de base de datos con grupos de disponibilidad AlwaysOn (SQL Server)
- FILESTREAM (SQL Server)
- FileTables (SQL Server)
- Acerca del trasvase de registros (SQL Server)
- Almacén remoto de blobs (RBS) (SQL Server)
- Replicación de SQL Server
- Service Broker
- Agente SQL Server
- Reporting Services con grupos de disponibilidad AlwaysOn (SQL Server)
- Gobernador de Recursos
- TDS 8.0, a partir de SQL Server 2025 (17.x)
Tareas relacionadas
- Requisitos previos, restricciones y recomendaciones para grupos de disponibilidad Always On
- Referencia para la creación y configuración de grupos de disponibilidad Always On
- Administración de un grupo de disponibilidad
- Herramientas para supervisar grupos de disponibilidad Always On
- Descarga de cargas de trabajo de solo lectura a la réplica secundaria de un grupo de disponibilidad Always On
- Descarga de copias de seguridad a las réplicas secundarias de un grupo de disponibilidad.
- Conexión a un agente de escucha del grupo de disponibilidad Always On
- Instrucciones Transact-SQL para grupos de disponibilidad AlwaysOn
- Información general sobre los cmdlets de PowerShell para grupos de disponibilidad AlwaysOn
- Blog de SQL Server: alta disponibilidad
- Blog de SQL Server
- Archivo: Blogs del equipo Always On de SQL Server: blog oficial del equipo de Always On de SQL Server
- Archivo: Blogs de los ingenieros de SQL Server CSS
- Guía de soluciones AlwaysOn de Microsoft SQL Server para lograr alta disponibilidad y recuperación ante desastres